Adaboost 算法实例解析
Adaboost 算法实例解析
1 Adaboost的原理
1.1 Adaboost基本介绍
AdaBoost,是英文"Adaptive Boosting"(自适应增强)的缩写,由Yoav Freund和Robert Schapire在1995年提出。Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这 Adaboost 些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器。使用adaboost分类器可以排除一些不必要的训练数据特徵,并将关键放在关键的训练数据上面。
主要解决的问题
目前,对adaBoost算法的研究以及应用大多集中于分类问题,同时近年也出现了一些在回归问题上的应用。就其应用adaBoost系列主要解决了: 两类问题、多类单标签问题、多类多标签问题、大类单标签问题,回归问题。它用全部的训练样本进行学习。
1.2 Adaboost算法介绍
算法分析
该算法其实是一个简单的弱分类算法提升过程,这个过程通过不断的训练,可以提高对数据的分类能 Adaboost
力。整个过程如下所示:
1. 先通过对N个训练样本的学习得到第一个弱分类器;
2. 将分错的样本和其他的新数据一起构成一个新的N个的训练样本,通过对这个样本的学习得到第二个弱分类器 ;
3. 将1和2都分错了的样本加上其他的新样本构成另一个新的N个的训练样本,通过对这个样本的学习得到第三个弱分类器;
4. 最终经过提升的强分类器 。即某个数据被分为哪一类要通过 , ……的多数表决。
Adaboost的自适应在于:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。
具体说来,整个Adaboost 迭代算法就3步:
- 初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权重:1/N。
- 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权重就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。然后,权重更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
Adaboost算法流程


对于这个算法需要介绍的是:
1. 算法开始前,需要将每个样本的权重初始化为1/m,这样一开始每个样本都是等概率的分布,每个分类器都会公正对待。
2. 开始迭代后,需要计算每个弱分类器的分类错误的误差,误差等于各个分错样本的权重和,这里就体现了样本权重的作用。如果一个分类器正确分类了一个权重大的样本,那么这个分类器的误差就会小,否则就会大。这样就对分类错误的样本更大的关注。
3. 获取最优分类器后,需要计算这个分类器的权重,然后再更新各个样本的权重,然后再归一化
4. 算法迭代的次数一般不超过弱分类器的个数,如果弱分类器的个数非常之多,那么可以权衡自己性价比来折中选择。
5. 迭代完成后,最后的分类器是由迭代过程中选择的弱分类器线性加权得到的。
1.3 Adaboost实例解析
例1. 下面,给定下列训练样本,请用AdaBoost算法学习一个强分类器。

求解过程:初始化训练数据的权值分布,令每个权值W1i = 1/N = 0.1,其中,N = 10,i = 1,2, ..., 10,然后分别对于m = 1,2,3, ...等值进行迭代。
拿到这10个数据的训练样本后,根据 X 和 Y 的对应关系,要把这10个数据分为两类,一类是“1”,一类是“-1”,根据数据的特点发现:“0 1 2”这3个数据对应的类是“1”,“3 4 5”这3个数据对应的类是“-1”,“6 7 8”这3个数据对应的类是“1”,9是比较孤独的,对应类“-1”。抛开孤独的9不讲,“0 1 2”、“3 4 5”、“6 7 8”这是3类不同的数据,分别对应的类是1、-1、1,直观上推测可知,可以找到对应的数据分界点,比如2.5、5.5、8.5 将那几类数据分成两类。当然,这只是主观臆测,下面实际计算下这个过程。
迭代过程1
对于m=1,在权值分布为D1(10个数据,每个数据的权值皆初始化为0.1)的训练数据上,经过计算可得:
- 阈值v取2.5时误差率为0.3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.3),
- 阈值v取5.5时误差率最低为0.4(x < 5.5时取1,x > 5.5时取-1,则3 4 5 6 7 8皆分错,误差率0.6大于0.5,不可取。故令x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.4),
- 阈值v取8.5时误差率为0.3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.3)。
所以无论阈值v取2.5,还是8.5,总得分错3个样本,故可任取其中任意一个如2.5,弄成第一个基本分类器为:

上面说阈值v取2.5时则6 7 8分错,所以误差率为0.3,更加详细的解释是:因为样本集中
- 0 1 2对应的类(Y)是1,因它们本身都小于2.5,所以被G1(x)分在了相应的类“1”中,分对了。
- 3 4 5本身对应的类(Y)是-1,因它们本身都大于2.5,所以被G1(x)分在了相应的类“-1”中,分对了。
- 但6 7 8本身对应类(Y)是1,却因它们本身大于2.5而被G1(x)分在了类"-1"中,所以这3个样本被分错了。
- 9本身对应的类(Y)是-1,因它本身大于2.5,所以被G1(x)分在了相应的类“-1”中,分对了。
从而得到G1(x)在训练数据集上的误差率(被G1(x)误分类样本“6 7 8”的权值之和)e1=P(G1(xi)≠yi) = 3*0.1 = 0.3。
然后根据误差率e1计算G1的系数:

这个a1代表G1(x)在最终的分类函数中所占的权重,为0.4236。
接着更新训练数据的权值分布,用于下一轮迭代:

值得一提的是,由权值更新的公式可知,每个样本的新权值是变大还是变小,取决于它是被分错还是被分正确。
即如果某个样本被分错了,则yi * Gm(xi)为负,负负等正,结果使得整个式子变大(样本权值变大),否则变小。
第一轮迭代后,最后得到各个数据新的权值分布D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)。由此可以看出,因为样本中是数据“6 7 8”被G1(x)分错了,所以它们的权值由之前的0.1增大到0.1666,反之,其它数据皆被分正确,所以它们的权值皆由之前的0.1减小到0.0715。
分类函数f1(x)= a1*G1(x) = 0.4236G1(x)。
此时,得到的第一个基本分类器sign(f1(x))在训练数据集上有3个误分类点(即6 7 8)。
从上述第一轮的整个迭代过程可以看出:被误分类样本的权值之和影响误差率,误差率影响基本分类器在最终分类器中所占的权重。
迭代过程2
对于m=2,在权值分布为D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)的训练数据上,经过计算可得:
- 阈值v取2.5时误差率为0.1666*3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.1666*3),
- 阈值v取5.5时误差率最低为0.0715*4(x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.0715*3 + 0.0715),
- 阈值v取8.5时误差率为0.0715*3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.0715*3)。
所以,阈值v取8.5时误差率最低,故第二个基本分类器为:

面对的还是下述样本:

很明显,G2(x)把样本“3 4 5”分错了,根据D2可知它们的权值为0.0715, 0.0715, 0.0715,所以G2(x)在训练数据集上的误差率e2=P(G2(xi)≠yi) = 0.0715 * 3 = 0.2143。
计算G2的系数:

更新训练数据的权值分布:

D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455)。被分错的样本“3 4 5”的权值变大,其它被分对的样本的权值变小。
f2(x)=0.4236G1(x) + 0.6496G2(x)
此时,得到的第二个基本分类器sign(f2(x))在训练数据集上有3个误分类点(即3 4 5)。
迭代过程3
对于m=3,在权值分布为D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455)的训练数据上,经过计算可得:
- 阈值v取2.5时误差率为0.1060*3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.1060*3),
- 阈值v取5.5时误差率最低为0.0455*4(x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.0455*3 + 0.0715),
- 阈值v取8.5时误差率为0.1667*3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.1667*3)。
所以阈值v取5.5时误差率最低,故第三个基本分类器为(下图画反了,待后续修正):

依然还是原样本:

此时,被误分类的样本是:0 1 2 9,这4个样本所对应的权值皆为0.0455,
所以G3(x)在训练数据集上的误差率e3= P(G3(xi)≠yi) = 0.0455*4 = 0.1820。
计算G3的系数:

更新训练数据的权值分布:

D4 = (0.125, 0.125, 0.125, 0.102, 0.102, 0.102, 0.065, 0.065, 0.065, 0.125)。被分错的样本“0 1 2 9”的权值变大,其它被分对的样本的权值变小。
f3(x)=0.4236G1(x) + 0.6496G2(x)+0.7514G3(x)
此时,得到的第三个基本分类器sign(f3(x))在训练数据集上有0个误分类点。至此,整个训练过程结束。
G(x) = sign[f3(x)] = sign[ a1 * G1(x) + a2 * G2(x) + a3 * G3(x) ],将上面计算得到的a1、a2、a3各值代入G(x)中,得到最终的分类器为:G(x) = sign[f3(x)] = sign[ 0.4236G1(x) + 0.6496G2(x)+0.7514G3(x) ]。
------- ---- 用图解深入浅出的解释adaboost ---—————
也许你看了上面的介绍或许还是对adaboost算法云里雾里的,没关系,百度大牛举了一个很简单的例子,你看了就会对这个算法整体上很清晰了。
下面我们举一个简单的例子来看看adaboost的实现过程:

图中,“+”和“-”分别表示两种类别,在这个过程中,我们使用水平或者垂直的直线作为分类器,来进行分类。
第一步:

根据分类的正确率,得到一个新的样本分布D2,一个子分类器h1
其中划圈的样本表示被分错的。在右边的途中,比较大的“+”表示对该样本做了加权。
也许你对上面的ɛ1,ɑ1怎么算的也不是很理解。下面我们算一下,不要嫌我啰嗦,我最开始就是这样思考的,只有自己把算法演算一遍,你才会真正的懂这个算法的核心,后面我会再次提到这个。
算法最开始给了一个均匀分布 D 。所以h1 里的每个点的值是0.1。ok,当划分后,有三个点划分错了,根据算法误差表达式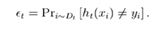 得到 误差为分错了的三个点的值之和,所以ɛ1=(0.1+0.1+0.1)=0.3,而ɑ1 根据表达式
得到 误差为分错了的三个点的值之和,所以ɛ1=(0.1+0.1+0.1)=0.3,而ɑ1 根据表达式 的可以算出来为0.42. 然后就根据算法 把分错的点权值变大。如此迭代,最终完成adaboost算法。
的可以算出来为0.42. 然后就根据算法 把分错的点权值变大。如此迭代,最终完成adaboost算法。
第二步:

根据分类的正确率,得到一个新的样本分布D3,一个子分类器h2
第三步:

得到一个子分类器h3
整合所有子分类器:

因此可以得到整合的结果,从结果中看,及时简单的分类器,组合起来也能获得很好的分类效果,在例子中所有的。
五 Adaboost 疑惑和思考
到这里,也许你已经对adaboost算法有了大致的理解。但是也许你会有个问题,为什么每次迭代都要把分错的点的权值变大呢?这样有什么好处呢?不这样不行吗? 这就是我当时的想法,为什么呢?我看了好几篇介绍adaboost 的博客,都没有解答我的疑惑,也许大牛认为太简单了,不值一提,或者他们并没有意识到这个问题而一笔带过了。然后我仔细一想,也许提高错误点可以让后面的分类器权值更高。然后看了adaboost算法,和我最初的想法很接近,但不全是。 注意到算法最后的表到式为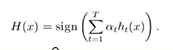 ,这里面的a 表示的权值,是由
,这里面的a 表示的权值,是由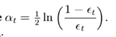 得到的。而a是关于误差的表达式,到这里就可以得到比较清晰的答案了,所有的一切都指向了误差。提高错误点的权值,当下一次分类器再次分错了这些点之后,会提高整体的错误率,这样就导致 a 变的很小,最终导致这个分类器在整个混合分类器的权值变低。也就是说,这个算法让优秀的分类器占整体的权值更高,而挫的分类器权值更低。这个就很符合常理了。到此,我认为对adaboost已经有了一个透彻的理解了。
得到的。而a是关于误差的表达式,到这里就可以得到比较清晰的答案了,所有的一切都指向了误差。提高错误点的权值,当下一次分类器再次分错了这些点之后,会提高整体的错误率,这样就导致 a 变的很小,最终导致这个分类器在整个混合分类器的权值变低。也就是说,这个算法让优秀的分类器占整体的权值更高,而挫的分类器权值更低。这个就很符合常理了。到此,我认为对adaboost已经有了一个透彻的理解了。
六 总结
最后,我们可以总结下adaboost算法的一些实际可以使用的场景:
1)用于二分类或多分类的应用场景
2)用于做分类任务的baseline
无脑化,简单,不会overfitting,不用调分类器
3)用于特征选择(feature selection)
4)Boosting框架用于对badcase的修正
只需要增加新的分类器,不需要变动原有分类器
由于adaboost算法是一种实现简单,应用也很简单的算法。Adaboost算法通过组合弱分类器而得到强分类器,同时具有分类错误率上界随着训练增加而稳定下降,不会过拟合等的性质,应该说是一种很适合于在各种分类场景下应用的算法。
这个是我看过对adaboost写的比较容易懂的文章了,等有空的时候我自己运行下adaboost的python代码,到时候再把这篇文章修改下。
对了,如果看到我的博客后,有意愿和我技术沟通的,可以加我QQ 340217138 讨论。
参考:
http://blog.csdn.net/tiandijun/article/details/48036025
http://blog.csdn.net/haidao2009/article/details/7514787
Adaboost 算法实例解析的更多相关文章
- 图像算法研究---Adaboost算法具体解释
本篇文章先介绍了提升放法和AdaBoost算法.已经了解的可以直接跳过.后面给出了AdaBoost算法的两个样例.附有详细计算过程. 1.提升方法(来源于统计学习方法) 提升方法是一种经常使用的统计学 ...
- AdaBoost算法原理及OpenCV实例
备注:OpenCV版本 2.4.10 在数据的挖掘和分析中,最基本和首要的任务是对数据进行分类,解决这个问题的常用方法是机器学习技术.通过使用已知实例集合中所有样本的属性值作为机器学习算法的训练集,导 ...
- CRC校验算法的实例解析
概念 CRC校验算法,说白了,就是把需要校验的数据与多项式进行循环异或(XOR), 进行XOR的方式与实际中数据传输时,是高位先传.还是低位先传有关.对于数据 高位先传的方式,XOR从数据的高位开 ...
- adaboost算法
三 Adaboost 算法 AdaBoost 是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,即弱分类器,然后把这些弱分类器集合起来,构造一个更强的最终分类器.(很多博客里说的三个臭皮匠 ...
- Adaboost 算法的原理与推导
0 引言 一直想写Adaboost来着,但迟迟未能动笔.其算法思想虽然简单“听取多人意见,最后综合决策”,但一般书上对其算法的流程描述实在是过于晦涩.昨日11月1日下午,邹博在我组织的机器学习班第8次 ...
- JavaWeb实现文件上传下载功能实例解析
转:http://www.cnblogs.com/xdp-gacl/p/4200090.html JavaWeb实现文件上传下载功能实例解析 在Web应用系统开发中,文件上传和下载功能是非常常用的功能 ...
- 前向分步算法 && AdaBoost算法 && 提升树(GBDT)算法 && XGBoost算法
1. 提升方法 提升(boosting)方法是一种常用的统计学方法,在分类问题中,它通过逐轮不断改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能 0x1: 提升方法的基本 ...
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- 机器学习--boosting家族之Adaboost算法
最近在系统研究集成学习,到Adaboost算法这块,一直不能理解,直到看到一篇博文,才有种豁然开朗的感觉,真的讲得特别好,原文地址是(http://blog.csdn.net/guyuealian/a ...
随机推荐
- bzoj2908
题解: 我的做法好像跟网上不太一样.. 首先分位讨论 我的做法是先观察出了一个性质 这个答案只跟最后一个0出现的位置有关(这个随便yy一下很容易出来因为运算有0则1) 然后问题就变成了 给出一棵树,支 ...
- Docker 启动tomcat
docker run -d --name jinrong_beijingbank -p 8081:8081 -v /application/docker_hub/java/pypaltform2018 ...
- Mysql my.cnf配置文件记录
一.参数 1.max_binlog_size = 1G #binlog大小 2. #slave不需要同步数据库 binlog-ignore-db=information_schema bin ...
- BZOJ3172 [Tjoi2013]单词 字符串 SA ST表
原文链接http://www.cnblogs.com/zhouzhendong/p/9026543.html 题目传送门 - BZOJ3172 题意 输入$n(n\leq 200)$个字符串,保证长度 ...
- js设置元素不能编辑
js设置元素不能编辑 $("#startLocation").attr("readOnly",true); js设置元素可以编辑 $("#startL ...
- 框架MyBatis
ByBatis MyBatis是Apache的一个开源项目iBatis,iBatis3.x 正式更名为MyBatis ,代码于2013年11月迁移到Github.它是一个基于Java的持久层框架(连数 ...
- js读取cookie,并利用encrypt和decrypt加密和解密方法
以下为支持encrypt和decrypt加密和解密方法 eval(function(p,a,c,k,e,r){e=function(c){return(c<a?'':e(parseInt(c/a ...
- Redis闪退解决办法
复杂办法! cmd 进入命令,cd进入redis文件 输入:redis-server.exe redis.windows.conf,手动开启! 简单办法,删除重新下载! 不确定办法如下 1.在解压的r ...
- 爬虫3 requests基础2 代理 证书 重定向 响应时间
import requests # 代理 # proxy = { # 'http':'http://182.61.29.114.6868' # } # res = requests.get('http ...
- Square Destroyer-POJ 1084 (IDA*)
Description The left figure below shows a complete 3*3 grid made with 2*(3*4) (=24) matchsticks. The ...