网站每日PV/IP统计/总带宽/URL统计脚本分享(依据网站访问日志)
在平时的运维工作中,我们运维人员需要清楚自己网站每天的总访问量、总带宽、ip统计和url统计等。
虽然网站已经在服务商那里做了CDN加速,所以网站流量压力都在前方CDN层了
像每日PV,带宽,ip统计等数据也都可以在他们后台里查看到的。
======================================================================
通过下面的方法,可以快速根据子网掩码算出它的掩码位:
子网掩码 掩码位
255.255.255.0 24位 (最后一个数是0,则256-0=256=2^8,一共32位,则该掩码位是32-8=24)
255.255.255.248 29位 (256-248=8=2^3,则该掩码位是32-3=29)
255.255.255.224 27位 (256-224=32=2^5,则该掩码位是32-5=27)
255.255.252.0 22位 (256-0=256=2^8,256-252=4=2^2,则该掩码位是32-8-2=22位)
255.255.224.0 19位 (256-0=256=2^8,256-224=32=2^5,则该掩码位是32-8-5=19位) 也可以根据掩码位快速算出它的子网掩码
掩码位 子网掩码
28位 255.255.255.240 (32-28=4,2^4=16,256-16=240,则该子网掩码为255.255.255.240)
30位 255.255.255.252 (32-30=2,2^2=4,256-4=252,则该子网掩码为255.255.255.252)
21位 255.255.248.0 (32-21=11=3+8,2^3=8,256-8=248,2^8=256,256-256=0,则该子网掩码为255.255.248.0)
18位 255.255.192.0 (32-18=14=6+8,2^6=64,256-64=192,2^8=256,256-256=0,则该子网掩码为255.255.192.0)
11位 255.224.0.0 (32-11=21=5+8+8,2^5=32,256-32=224,2^8=256,256-256=0,2^8=256,256-256=0,则该子网掩码为255.224.0.0)
------------------------------------------------------------------------------------------------------------------------
192.168.10.8/16
192.168.8./16 172.16.50.5/24
172.16.51.7/24 以上两组ip,其中:
第一组是同网段ip,因为子网掩码是16,即255.255.0.0,前两个是网络地址,后两个机器地址,只要前两个数字相同就是同网段ip。
第一组不是同网段ip,因为子网掩码是24,即255.255.255.0,前三个是网络地址,后两个机器地址,只要前三个数字不相同就不是同网段ip。 简单来说:
不同网段的ip相互通信,需要经过三层网络。即三层网络可以跨多个冲突域,可以组大型的网络。
相同网段的ip相互通信,经过大二层网络。即二层网络仅仅是同一个冲突域内,组网能力非常有限,一般只是小局域网
---------------------------------------------------------------------------------------------------------------------
在这里,还是分享一个很早前用到过的shell统计脚本,可以结合crontab计划任务,每天给你的邮箱发送一个统计报告~【前提是本机已安装sendmail并启动】
脚本统计了:
1)总访问量
2)总带宽
3)独立访客量
4)访问IP统计
5)访问url统计
6)来源统计
7)404统计
8)搜索引擎访问统计(谷歌,百度)
9)搜索引擎来源统计(谷歌,百度)
[root@115r ~]# cat tongji.sh //脚本如下
#!/bin/bash
log_path=/Data/logs/nginx/www.huanqiu.com/access.log
domain="huanqiu.com"
email="wangshibo@huanqiuc.com"
maketime=`date +%Y-%m-%d" "%H":"%M`
logdate=`date -d "yesterday" +%Y-%m-%d`
total_visit=`wc -l ${log_path} | awk '{print $1}'`
total_bandwidth=`awk -v total=0 '{total+=$10}END{print total/1024/1024}' ${log_path}`
total_unique=`awk '{ip[$1]++}END{print asort(ip)}' ${log_path}`
ip_pv=`awk '{ip[$1]++}END{for (k in ip){print ip[k],k}}' ${log_path} | sort -rn | head -20`
url_num=`awk '{url[$7]++}END{for (k in url){print url[k],k}}' ${log_path} | sort -rn | head -20`
referer=`awk -v domain=$domain '$11 !~ /http:\/\/[^/]*'"$domain"'/{url[$11]++}END{for (k in url){print url[k],k}}' ${log_path} | sort -rn | head -20`
notfound=`awk '$9 == 404 {url[$7]++}END{for (k in url){print url[k],k}}' ${log_path} | sort -rn | head -20`
spider=`awk -F'"' '$6 ~ /Baiduspider/ {spider["baiduspider"]++} $6 ~ /Googlebot/ {spider["googlebot"]++}END{for (k in spider){print k,spider[k]}}' ${log_path}`
search=`awk -F'"' '$4 ~ /http:\/\/www\.baidu\.com/ {search["baidu_search"]++} $4 ~ /http:\/\/www\.google\.com/ {search["google_search"]++}END{for (k in search){print k,search[k]}}' ${log_path}`
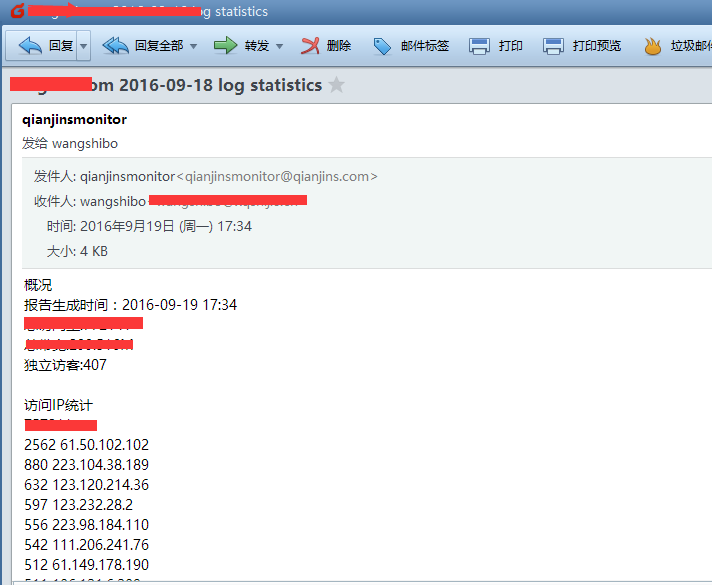
echo -e "概况\n报告生成时间:${maketime}\n总访问量:${total_visit}\n总带宽:${total_bandwidth}M\n独立访客:${total_unique}\n\n访问IP统计\n${ip_pv}\n\n访问url统计\n${url_num}\n\n来源页面统计\n${referer}\n\n404统计\n${notfound}\n\n蜘蛛统计\n${spider}\n\n搜索引擎来源统计\n${search}" | mail -s "$domain $logdate log statistics" ${email}
上述脚本可适用于其他网站的统计。只需要修改上面脚本中的三个变量即可:
log_path
domain
email
把此脚本添加到计划任务,就可以每天接收到统计的数据了。
执行上面的脚本,去wangshibo@huanqiu.com邮箱里查看统计报告:
[root@115r ~]# sh tongji.sh
[root@115r ~]#crontab -e
#每天凌晨按时统计一次
59 23 * * * /bin/bash -x /root/tongji.sh >/dev/null 2>&1
------------------------------------------------------------------------------------------------------------------------------
上面是单个url的统计情况,如果时多个网站的访问情况(使用for do done语句做shell脚本),则脚本如下: [root@web ~]# cat all_wang_access.sh
#!/bin/bash
for log_path in /data/nginx/logs/athena_access.log /data/nginx/logs/ehr_access.log /data/nginx/logs/im_access.log /data/nginx/logs/www_access.log /data/nginx/logs/zrx_access.log do domain=`echo $(echo ${log_path}|cut -d"_" -f1|awk -F"/" '{print $5}').wang.com`
email="shibo.wang@wang.com daiying.qi@wang.com nan.li@wang.com"
maketime=`date +%Y-%m-%d" "%H":"%M`
logdate=`date -d "yesterday" +%Y-%m-%d`
total_visit=`wc -l ${log_path} | awk '{print $1}'`
total_bandwidth=`awk -v total=0 '{total+=$10}END{print total/1024/1024}' ${log_path}`
total_unique=`awk '{ip[$1]++}END{print asort(ip)}' ${log_path}`
ip_pv=`awk '{ip[$1]++}END{for (k in ip){print ip[k],k}}' ${log_path} | sort -rn | head -20`
url_num=`awk '{url[$7]++}END{for (k in url){print url[k],k}}' ${log_path} | sort -rn | head -20`
referer=`awk -v domain=$domain '$11 !~ /http:\/\/[^/]*'"$domain"'/{url[$11]++}END{for (k in url){print url[k],k}}' ${log_path} | sort -rn | head -20`
notfound=`awk '$9 == 404 {url[$7]++}END{for (k in url){print url[k],k}}' ${log_path} | sort -rn | head -20`
spider=`awk -F'"' '$6 ~ /Baiduspider/ {spider["baiduspider"]++} $6 ~ /Googlebot/ {spider["googlebot"]++}END{for (k in spider){print k,spider[k]}}' ${log_path}`
search=`awk -F'"' '$4 ~ /http:\/\/www\.baidu\.com/ {search["baidu_search"]++} $4 ~ /http:\/\/www\.google\.com/ {search["google_search"]++}END{for (k in search){print k,search[k]}}' ${log_path}` echo -e "-----------------------------------$domain访问概况-----------------------------------\n报告生成时间:${maketime}\n总访问量:${total_visit}\n总带宽:${total_bandwidth}M\n独立访客:${total_unique}\n\n访问IP统计\n${ip_pv}\n\n访问url统计\n${url_num}\n\n来源页面统计\n${referer}\n\n404统计\n${notfound}\n\n蜘蛛统计\n${spider}\n\n搜索引擎来源统计\n${search}" | mail -s "$domain $logdate log statistics" ${email} done 使用crontab做定时任务
[root@web ~]# crontab -l
#网站访问情况统计
50 23 * * * /bin/bash -x /opt/wang.com_access/all_wang_access.sh > /dev/null 2>&1
网站每日PV/IP统计/总带宽/URL统计脚本分享(依据网站访问日志)的更多相关文章
- 通过Nginx统计网站的PV、UV、IP
转载:通过Nginx统计网站的PV.UV.IP 概念 UV:独立访客:以cookie为依据,假设一台电脑装有3个不同的浏览器,分别打开同一个页面,将会产生3个UV.PV:访问量:页面每访问或刷新一次, ...
- 日志文件 统计 网站PV IP
1. 安装rrdtool yum install rrdtool 2. 创建 rrdtool 数据库 rrdtool create /opt/local/rrdtool/jicki.rrd -s 30 ...
- [100]awk运算-解决企业统计pv/ip问题
awk运算 awk以脚本方式运行 #!/bin/awk BEGIN{ arr[1]="maotai"; arr[2]="maotai" for(k in arr ...
- 浅谈千万级PV/IP规模高性能高并发网站架构(转自老男孩)
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://oldboy.blog.51cto.com/2561410/736710 如果把来 ...
- (转)浅谈千万级PV/IP规模高性能高并发网站架构
浅谈千万级PV/IP规模高性能高并发网站架构 原文:http://blog.51cto.com/oldboy/736710 文章架构简图: 高并发访问的核心原则其实就一句话“把所有的用户访问请求都 ...
- PV IP UV的概念介绍
IP(独立IP):指独立IP数,不同的IP地址的计算机访问网站的总次数,这个是网站流量分析的一个重要指标.00:00-24:00内相同的IP地址只被计算一次 假如说:赶集网的日独立IP300W,则至少 ...
- 反击黑客之对网站攻击者的IP追踪
ip追踪是一件比较难实现的,因为我只有一个ip,而且在没有任何技术支持下对该ip追踪,同时我在公司也没有服务器权限,仅有后台,一般的ip追踪技术分类,反应式ip追踪,主动式的追踪,分享的只是一个过程, ...
- 网站性能测试PV到TPS的转换以及TPS的波动和淘宝性能测试要点
<淘宝性能测试白皮书V0.3> 性能测试的难点不在于测,在于测出的数据和实际的对照关系,以及测试出来的数据对性能的评估(到底是好,还是不好). 淘宝性能测试白皮书,解决了我的4个问题:1. ...
- 一种基于自定义代码的asp.net网站首页根据IP自动跳转指定页面的方法!
一种基于自定义代码的asp.net网站首页根据IP自动跳转指定页面的方法! 对于大中型网站,为了增强用户体验,往往需要根据不同城市站点的用户推送或展现相应个性化的内容,如对于一些大型门户网站的新闻会有 ...
随机推荐
- 解决关于phpstorm打开速度很慢的问题
我的电脑是GTX950M , 8G 内存的 ,配置不算低但是打开phpstorm的速度非常的慢.基本上每次打开都要花一分钟以上,虽然打开sublime text3 只需要三四秒,但是phpstorm功 ...
- Paramiko和堡垒机实现
一.Paramiko paramiko模块,基于SSH用于连接远程服务器并执行相关操作. 1.安装:pip install paramiko 2.SSHClient:用于连接远程服务器并执行基本命令 ...
- 基于LNMP(fastcgi协议)环境部署、原理介绍以及fastcgi_cache配置以及upstream模块负载均衡讲解
ngx_http_proxy_module只能反向代理后端使用HTTP协议的主机.而ngx_http_fastcgi_module只能反向代理后端使用FPM或者使用FastCGI协议的客户端. 一.部 ...
- Centos7系统特性之systemd
1.centos系列的系统启动流程(内核级别的启动流程): POST(加电自检)---> Boot Sequence(BIOS)---> Boot loader (MBR)---> ...
- PHP实现一个简陋的注册登录页面
PHP实现一个简陋的注册登录页面 今天来水一篇没有**用的 /滑稽脸,代码简陋臃肿考虑不全,各位大佬轻喷,还望不吝赐教. 首先考虑了一下需要至少四个页面:register.html.register. ...
- 基础数据类型之AbstractStringBuilder
String内部是一个private final char value[]; 也就意味着每次调用的各种处理方法,返回的字符串都是一个新的,性能上,显然.... 所以,对于可变字符序列的需求是很明确的 ...
- 深入探究JFreeChart
1 简介 JFreeChart 是 SourceForge.net 上的一个开源项目,它的源码和 API 都可以免费获得. JFreeChart 的功能非常强大,可以实现饼图 ( 二维和三维 ) , ...
- WPFのBorder的用法
border介绍: 下面是StackPanel中,一个简单的,具有轻微圆角的边框,围绕在一组按钮外面: <Border Margin="5" Padding="5& ...
- 浅谈js之闭包
1.什么是闭包??? "官方"的解释是指一个拥有许多变量和绑定了这些变量的环境的表达式(通常是一个函数),因而这些变量也是该表达式的一部分: 红皮书是这样说的,闭包是指有权访问另一 ...
- go标准库的学习-encoding/xml
参考:https://studygolang.com/pkgdoc 导入方式: import "encoding/xml" 实现的简单的理解XML命名空间的XML 1.0编译器 f ...