TCP/IP 笔记 - Internet协议
IP是TCP/IP协议族中的核心协议,TCP、UDP、ICMP、IGMP数据都通过IP数据报传输。IP提供了一种"尽力而为、无连接"的数据交付服务:尽力而为表示不保证IP数据报能成功到达目的地;无连接意味着IP不维护网络单元中数据报相关的任何链接状态信息,每个数据报独立于其他数据报来处理,这也意味着IP数据报的可不按顺序交付。
IPv4头部
如下是IPv4的数据报结构图:
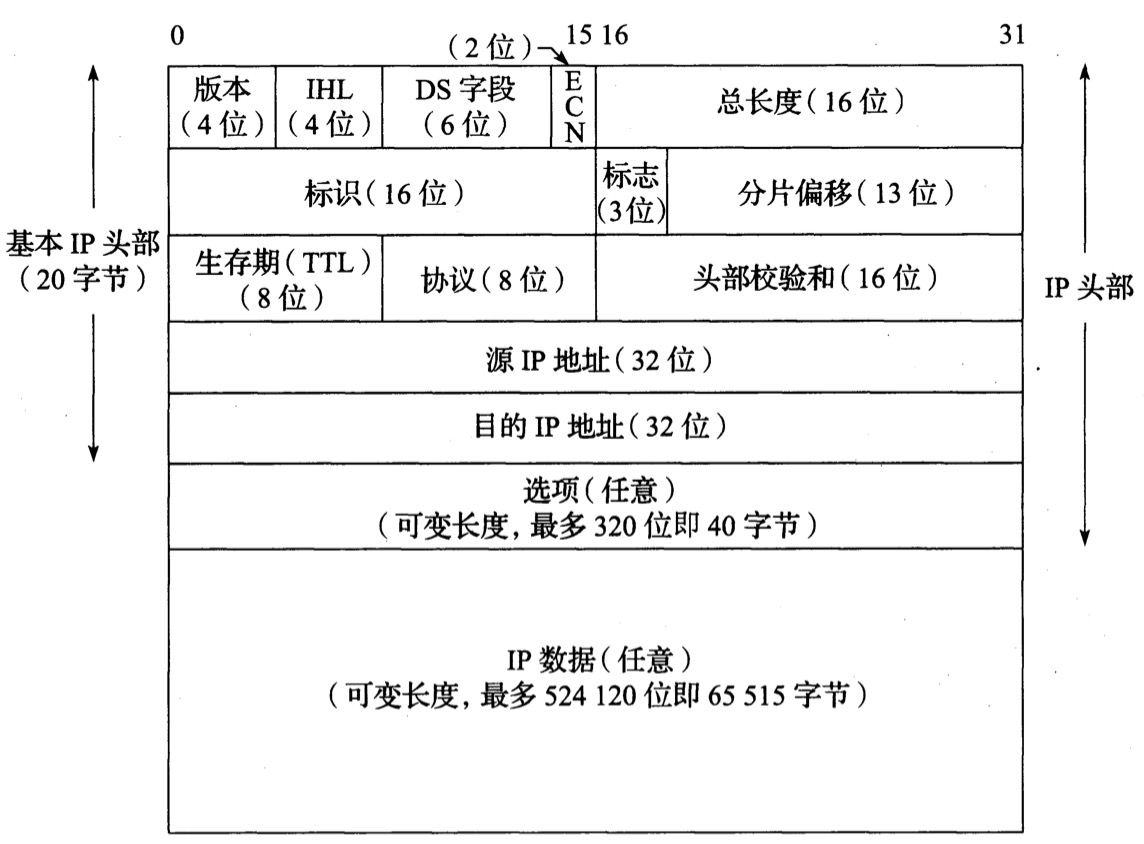
这里主要关注IPv4的头部信息,一个典型的IPv4基本头部(指不包括IP选项)包含20字节。包含:
1. 版本标识(IPv4为4,IPv6为6);
2. IHL(Internet头部长度);
3. DC字段(服务类型字段),指定一个等效的通信类型字段,前6位是区分服务字段,后2位(ECN)是显式拥塞通知字段或指示位;
4. 总长度,IPv4数据报的总长度,由于它是一个16位字段,所以可以算出IPv4数据报的最大长度是65535字节(理想化的最大,实际通信由多方因素计算后取最小值);
5. 标识字段,帮助标识由IPv4主机发送的数据报,避免数据报分片混淆;标志是一个3位的控制字段,表示是否允许数据分片、该数据报是否是末尾的数据报;分片偏移字段给出该分片负载字节中的第一个字节在原始IPv4数据中的偏移量;
6. TTL(生存期)用于设置一个数据报可经过的路由器数量上限,每经过一台路由器,该值减1,直至0,用于防止由于出现路由环路而导致的数据报循环;
7. 协议字段表示数据报有效载荷部分的数据类型,最常用值为17(UDP)和6(TCP);
8. 头部校验和字段仅计算IPv4头部,不检查数据报有效载荷的正确性;
9. 源IP地址和目标IP地址,数据通信的两端地址。
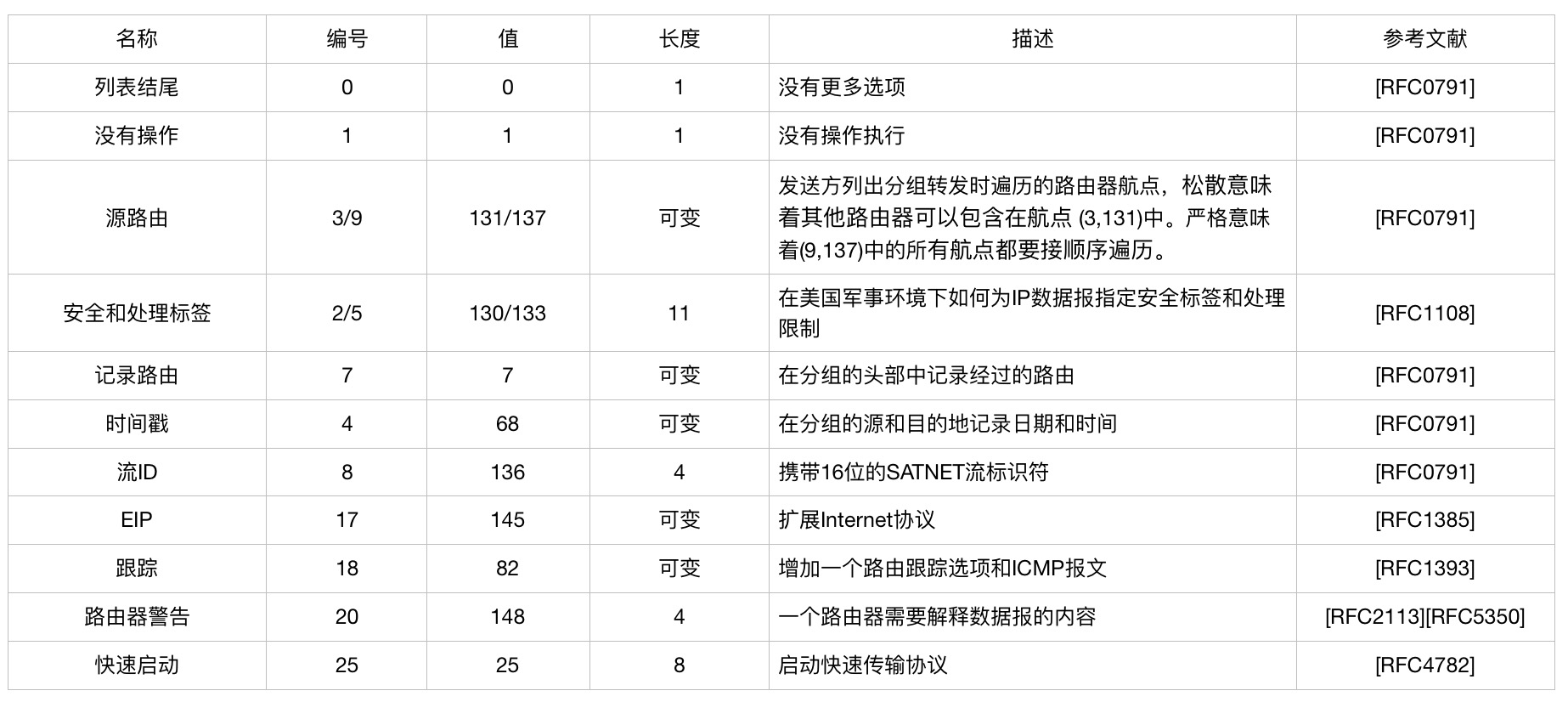
IPv4支持一些可供数据报选择的选项,填充在选项字段,选项有一个8位的类型字段标识:复制(1位)、类别(2位)、编号(5位)。
IPv4选项如下表:
IPv6头部
如下是IPv6的头部信息图:
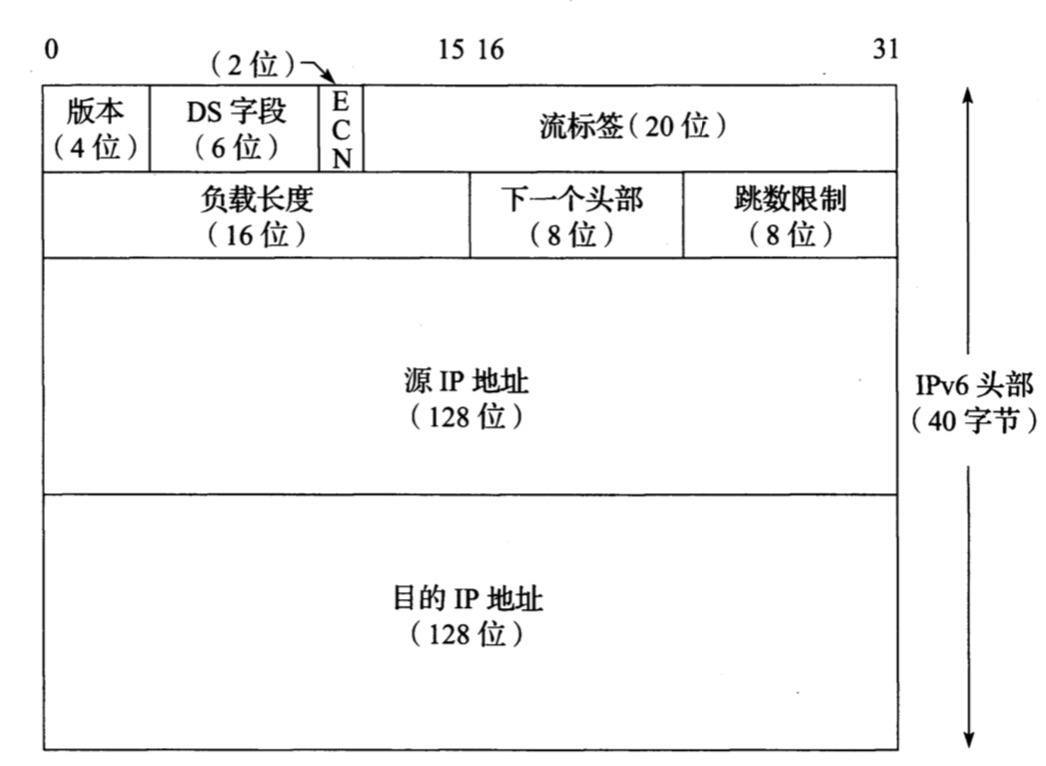
相对于IPv4头部,少了一些信息,也多了一些信息,多了的信息包括:
1. 流标签以标识同一个流里面的报文;
2. 负载长度(对比标识字段)字段提供IPv6数据报的长度,不包括头部长度,但包括IPv6扩展头部;、
3. 下一个头部字段用来指明报头后接的报文头部的类型,若存在扩展头,表示第一个扩展头的类型,否则表示其上层协议的类型,它是IPv6各种功能的核心实现方法;
4. 跳数限制(对比IPv4的TTL)
IPv6扩展头部
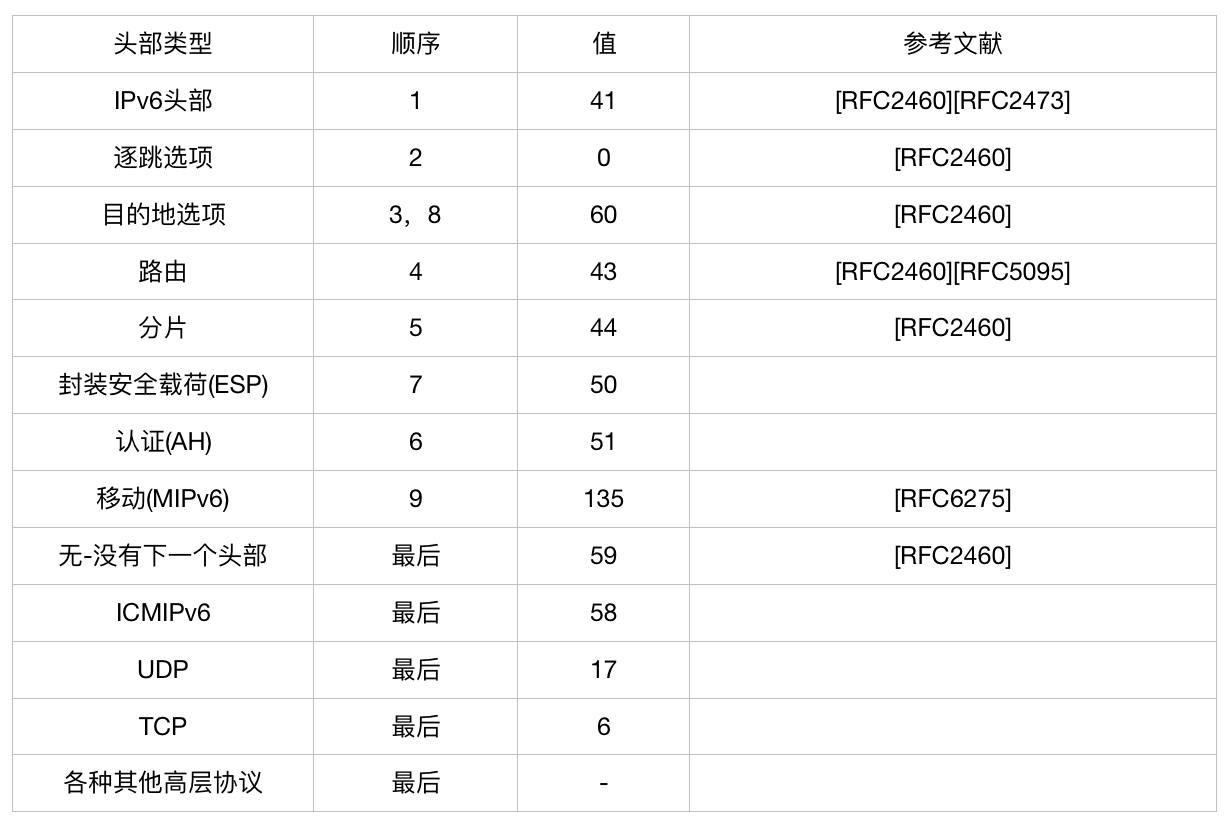
扩展头部和更高协议头部与IPv6头部链接起来构成级联的头部,每个头部的下一个头部字段标识紧跟着的头部类型,类型值有:
如果存在扩展协议,则IPv6数据报看起来是这样的:

IPv6选项
由于IPv4头部空间的限制,那些来自IPv4的选项已停止使用,而IPv6可变长度的扩展头部或编码在特殊扩展头部中的选项可适应当前更大的Internet。如果选项存在,可放入逐跳选项或目的地选项。
1. 填充1和填充N:填充1选项(类型0)是唯一缺少长度字段和值字段的选项。它仅有1字节长,取值为0。填充N选项(类型1)向头部的选项区域填充2字节或更多字节,对于n个填充字节,选项数据长度字段包含的值为(n-2)。
2. IPv6超大有效载荷:IPv6超大有效载荷选项指定了一种有效载荷大于65535字节的IPv6数据报,称为超大报文。超大有效载荷选项提供了一个32位的字段,用于携带有效载荷在65535~4294967295字节直接的数据报,当使用超大报文时,正常的敷在长度字段被设置位0。
3. 隧道封装限制:路由器想要将IPv6数据封装在一条隧道中,它首先检查隧道封装限制选项是否存在并置位,如果不为0,则可进行隧道封装,且新封装的IPv6数据报必须包括这个选项,其值相对之前的封装限制值减1,依次封装递减。
4. 路由器警告:与IPv4的该选项一样,指出包含需要路由器处理的信息。
5. 快速启动:适用于IPv4和IPv6,但目前建议仅用于专用网络。选项包括发送者需要的以比特/秒为单位的传输速率的编码值、QS TTL值和一些额外信息。
6. CALIPSO:于在某些专用网络中支持通用体系结构标签IPv6安全选项。它提供了一种为数据报做标记的方法,包括一个安全级别标识符和一些额外的信息。
7. 家乡地址:当使用IPV6移动选项时,这个选项保存发送数据报的IPv6节点的"家乡"地址。当远离"家乡"(典型位置的地址前缀)漫游时,通常为该节点分配一个不同的IP地址。该选项允许这个节点提供自已正常的家乡地址,以及它在漫游时的新地址(通常是临时分配)。当其他IPv6节点需要与移动节点通信时,它可以使用该节点的家乡地址。如果家乡地址选项存在,包含它的目的地选项头部必须出现在路由头部之后,并在分片和ESP头部之前。
"家乡"的概念来自典型位置的地址前缀,其设计目的是为了让移动设备用户,能够从一个网上系统中,移动到另一个网上系统,但是设备的IP地址保持不变。这能够使移动节点在移动中保持其连接性,实现跨越不同网段的漫游功能。
Internet校验和
Intenret校验和是一个被校验数据(如果被计算的字节数为奇数,用0填充)的16位反码和的反码,它能以相当高的概率确定接收的消息或其中的部内容是否与发送的相匹配。如果被计算数据包括一个校验和字段,该字段在进行校验和运算之前被设置为0,然后将计算出的校验和填充到该字段。为了检查一个包含校验和字段(头部、有效载荷等)的数据输入是否有效,需要对整个数据块(包括校验和字段)同样计算校验和。由于校验和字段本质上是其余数据校验和的反码,对正确接收的数据计算校验和应产生一个值0。
发送的行为:
为了给输出的数据报计算IPv4头部校验和,首先将数据报的校验和字段值设置为0。然后,对头部(整个头部被认为是一个16位字的序列)计算16位二进制反码和。这个16位二进制反码和被存储在校验和字段中。二进制反码加法可通过“循环进位加法”实现:当使用传统(二进制补码)加法产生一个进位时,这个进位以二进制值1加在高位。
接收的行为:
当一个IPv4数据报被接收时,对整个头部计算出一个校验和,包括校验和字段自身的值。假设数据报没有错误,计算出的校验和值为0(值FFFF的反码)。对于任何不正常的分组或头部,分组中的校验和字段值不为FFFF。
案例:
# 发送
消息: E3 4F F3 [ ] ← 校验和字段 =
二进制补码和: 1E4FF
二进制反码和: E4FF + = E500
二进制反码: ~(E500)=~( ) = = 1AFF (校验和) # 接收
消息 + 校验和 = E34F + + + 99F3 + 1AFF = E500 + 1AFF = FFFF
~(消息 + 校验和) =
路由头部
IPv6路由头部位发送方提供一种IPv6数据报控制机制,以控制数据报通过网络的路径。路由头部包含一个8位的路由类型标识符和一个8位的剩余部分字段。路由类型标识符为0或者2,分别代表类型0(RH0)和类型2(RH2)。剩余部分字段指出还有多少段路由需要处理,也就是在到达最终目的地之前仍需访问的中间节点数。
如下图的路由转发过程:
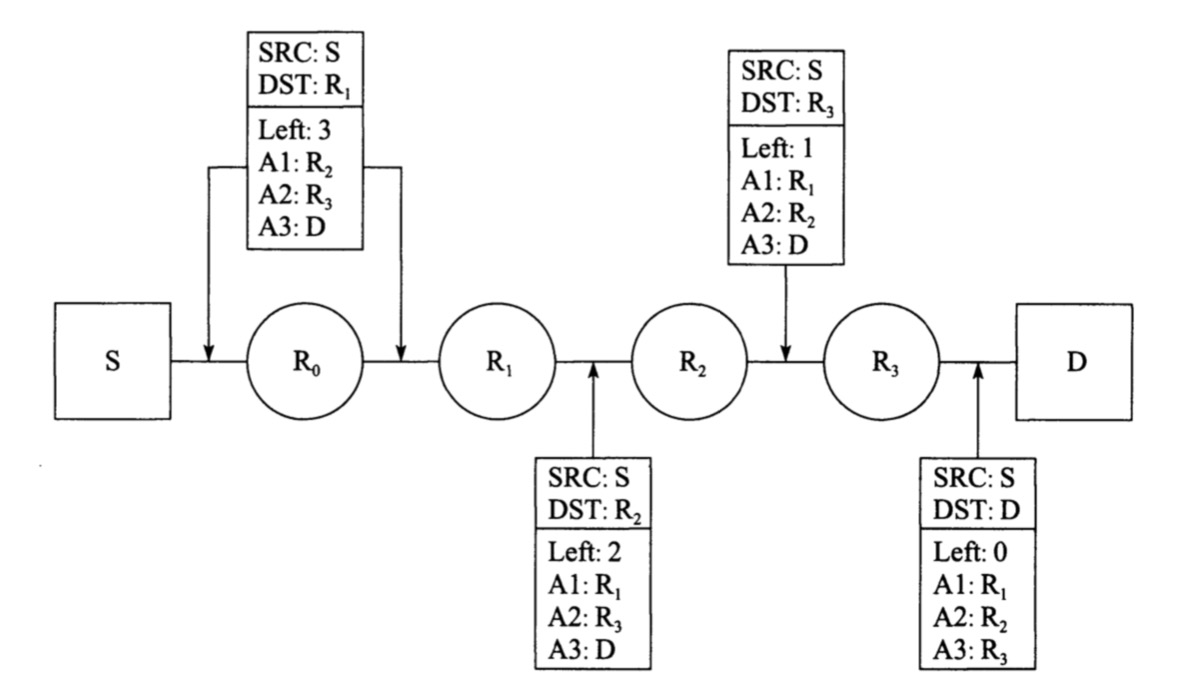
路由头部指定了经过的路由路径:R1、R2、R3、D;Left字段位剩余部分字段。由于R0的地址在数据报中不存在,因此R0没有修改路由头部或地址。当数据报到达R1时,将基本头部的目的地址和路由头部的第一个地址交换,并将剩余部分字段递减1。
分片头部
分片头部用于IPv6源节点向目的地发送一个大于路径MTU的数据报,1280字节是整个网络中针对IPv6定义的链路层最小MTU。
在IPv4中,如果数据报大小超过下一跳MTU,任何主机或路由器都可以将该数据分片,而在IPv6中仅数据报的发送者可以执行分片操作,这种情况下就需要添加一个分片头部。
在分片过程中,输入的数据报称为“原始数据报”,它由两部分组成: “不可分片部分”和“可分片部分”。
不可分片部分包括IPv6头部和任何在到达目的地之前需由中间节点处理的扩展头部(即包括路由头部之前的所有头部,如果有逐跳选项扩展头部,则是该头部之前的所有头部);可分片部分包括数据报的其余部分(即目的选项头部、上层头部和有效载荷数据)。当原始数据报被分片后,将会产生多个分片,其中每个分片都包含一个原始数据报中不可分片部分的副本,但是需要修改每个IPv6头部的负栽长度字段,以反映它所描述的分片的大小。在不可分片部分之后,每个新的分片都包含一个分片头部,其中包含一个分片相应的分片偏移字段(例如第一个分片的偏移量为0),以及一个原始分组的标识符字段的副本。最后一个分片的M(更多分片)位字段设置为0。
数据报分片过程如图:

1个3960字节的有效载荷被分为3个1448字节或更小的分片,每个分片包含一个带相同的标识符字段的分片头部,除了最后一个分片,所有分片的更多分片(M)字段设置为1。偏移量以8字节为单位,例如最后一个分片包含的数据是从原始数据开始处偏移(362*8)=2896字节。
IP转发
主机和路由器处理IP数据报的区别在于:主机不转发那些不是由它生成的数据报,但路由器会。
IP转发表包含以下信息:
1. 目的地:32位字段,,用于与一个掩码操作结果相匹配。用于发送到所有目的地的默认路由情况下,地址全设为0。
2. 掩码:32位字段,用作数据报目的IP地址按位与操作的掩码。
3. 下一跳:下一个IP实体的32位IPv4地址或者128位的IPv6地址,数据报将被转发到这。
4. 接口:它包含一个由IP层使用的标识符,以确定将数据报发送到下一跳的网络接口。
IP转发逐跳进行,当一台主机或路由器中的IP层需要向下一跳的路由器或主机发送一个数据报时,它首先检查数据报中的目的IP地址(D)。在转发表中使用该值D来执行最长前缀匹配算法:在表中搜索具有以下属性的所有条目:(D^mj)=dj。
1. 其中mj是索引为j的转发条目ej的掩码字段值,dj是转发条目ej的目的字段值。
2. 这意味着目的IP地址D与每个转发表条目中的掩码mj执行按位与,并将该结果与同一个条目中的目的地dj比较。
3. 如果满足这个属性,该条目ej与目的IP地址进行"匹配"。
4. 当进行匹配时,该算法查看这个条目的索引j,以及在掩码mj中有多少位设置为1。设置为1的位数越多,说明匹配的越好。
5. 选择最匹配的条目ek(即掩码mk中最多位为1的条目),将其下一跳字段nk作为转发数据报的下一跳IP地址。
如果转发表中没有发现匹配的条目,这个数据报则无法交付。
移动IP
基于上文中提到的"家乡"的概念,移动IP的实现方案依赖于一种特殊类型的路由器,被称为"家乡代理",用于为移动节点提供路由。MIPv6的复杂性主要涉及信令消息以及如何保证它们的安全,这些消息使用各种形式的移动扩展头部,因此移动IP自身实际上是一种特殊协议。
下图显示了MIPv6运行中涉及的实体,大部分适用于MIPv4。
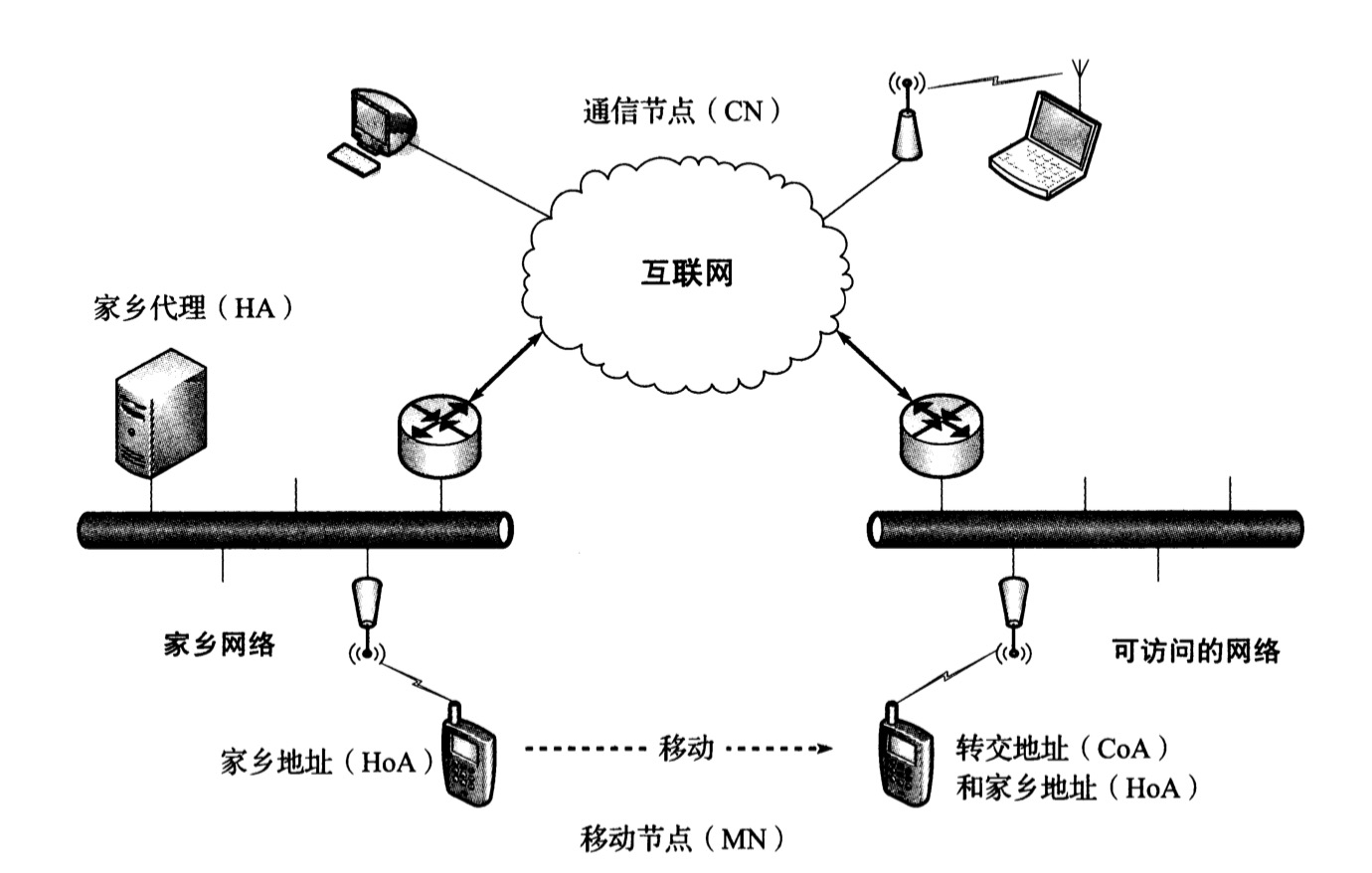
1. 一台可能移动的主句称为移动节点(MN),与它通信的主句称为通信节点(CN)。
2. MN被赋予一个由家乡网络的网络前缀获得的IP地址,被称为家乡地址HoA。
3. 当它漫游到一个可访问的网络时,它被赋予另外一个地址,称为转交地址CoA。
4. 当一个CN与一个MN通信时,该流量需要通过MN的家乡代理HA来路由,并使用一种双向的IPv6分组隧道,称为双向隧道。
这些消息通常由IPsec的封装安全有效负载(ESP)来保护。
基于双向隧道的MIPv6可能出现低效的路由,可使用路由优化(RO)方法来处理,这需要被涉及的各个节点都支持该功能。
路由优化涉及到一个通信注册过程,一个MN将当前的CoA通知给相应的CN,允许它们执行无须HA协助的路由。操作分为两部分:一部分涉及注册绑定的建立和维护;一部分涉及所有绑定建立后的数据报交换方法。
为了与CN建议绑定,MN必须向每个CN证明自己的"真实身份",通过返回路由程序RRP完成这些。
RRP中,MN和CN通过家乡代理HA进行信息转发,以达到身份认证。如图所示:
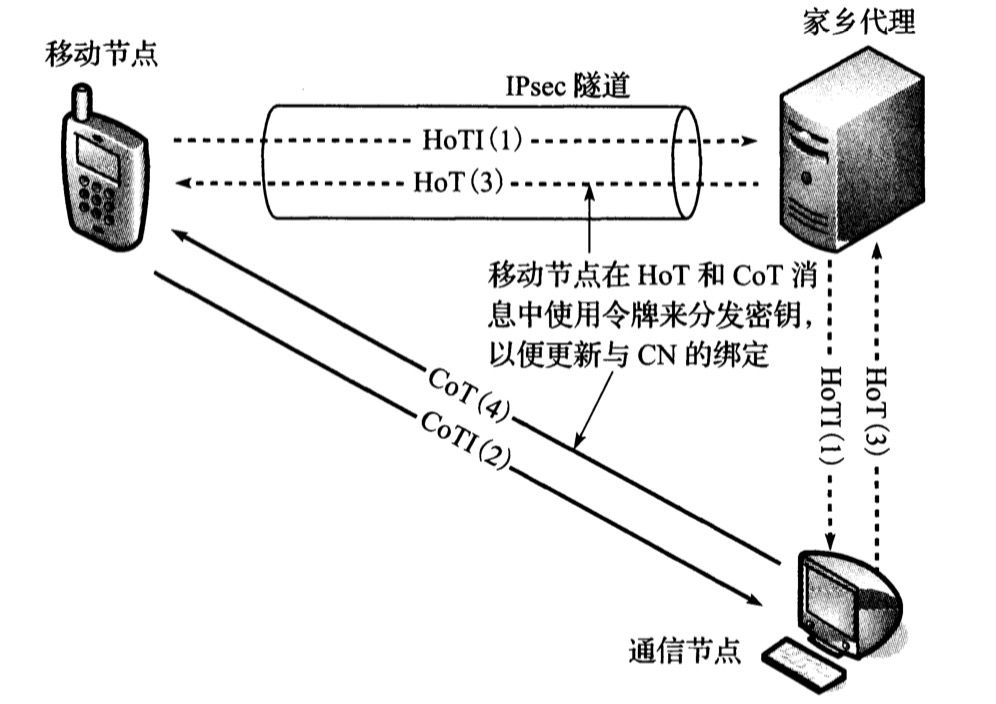
家乡测试初始化(HoTI)、家乡测试(HoT)、转交测试初始化(CoTI)和转交测试(CoT),数字表示顺序。
HoT消息经由HA发送到MN,消息中包含称为令牌的随机字符串, MN使用它形成一个加密密钥,这个密钥被用于生成发送给CN的经过认证的绑定更新。
IP数据报的主机处理
对于主机如何处理接收或发送的数据报,存在两种模式:强主机模式和弱主机模式。
对于接收行为:
强主机模式中,只有当"目的IP地址字段中包含的IP地址"与"数据报到达的接口配置的IP地址"匹配时,才同意把将数据报交付本地协议栈。
弱主机模式中,"数据报携带的目的地址"与"它到达的任何接口的任何本地地址"匹配,无论它到达哪个网络接口,它都会被接收的协议栈处理。
对于发送行为:
强主机模式中,只有在"数据报的源IP地址"所对应的网络接口才可以发送数据报。
弱主机模式中,无论哪个网络接口都可以发送数据报。
在Windows系统中,强主机模式是IPv4和IPv6发送和接收的默认模式;Linux中默认采用弱主机模式;BSD(含 Mac OS X)采用强主机模式。
当一台主机发送一个IP数据报时,它必须将自已的IP地址写入数据报的源IP地址字段,在它已知多个地址的情况下,数据报的目的地址确定一台特定的目的主机。
当前IP实现中,数据报的源IP地址和目的IP地址是通过"源地址选择程序和目的地址选择程序"获得的。
源地址选择程序
算法说明:
1. 该算法定义了一个源地址的候选集合CS(D),基于一个特点的目的地址D(除去任播、组播和未指定地址)。
2. 符号R(A)表示地址A在集合CS(D)中的等级,A比B的等级高,则R(A)>R(B),意味着优先选用A作为到达地址D的源地址。
3. R(A)*>R(B)表示在CS(D)中为A分配一个比B更高的等级。
4. I(D)表示选择到达目的D的接口(通过最长匹配前缀转发算法获取)。
5. @i是分配给接口i的地址集合。
6. 如果A是一个临时地址,T(A)为布尔值true,否则为false。
7. Q(D)表示目的地D选择一个最高等级的源地址,如果Q(D)=φ(空),可能无法为目的地D确定源地址。
算法规则如下:
1. 优先选择相同地址:if A = D, R(A) *> R(B);if B = D, R(B) *> R(A).
2. 优先选择适当范围:if S(A) < S(B) and S(A) < S(D), R(B) *> R(A) else R(A) *> R(B);if S(B) < S(A) and S(B) < S(D), R(A) *> R(B) else R(B) *> R(A).
3. 避免过期地址:if S(A)=S(B), {if ∧(A)<∧(B), R(B)*>R(A) else R(A)*>R(B)}.
4. 优先选择家乡地址:if H(A) and C(A) and ┐(C(B) and H(B)), R(A) *> R(B);if H(B) and C(B) and ┐(C(B) and H(A)), R(B) *> R(A);if (H(A) and ┐C(A)) and (┐H(B) and C(B)), R(A) *> R(B);if (H(B) and ┐C(B)) and (┐H(A) and C(A)), R(B) *> R(A).
5. 优先选择输出接口:if A ∈ @(I(D)) and B ∈ @(I(D)), R(A) *> R(B);if B ∈ @(I(D)) and A ∈ @(I(D)), R(B) *> R(A).
6. 优先选择匹配标签:if L(A) = L(D) and L(B) ≠ L(D), R(A) *> R(B);if L(B) = L(D) and L(A) ≠ L(D), R(B) *> R(A).
7. 优先选则非临时地址:if T(B) and ┐T(A), R(A) *> R(B);if T(A) and ┐T(B), R(B) *> R(A).
8. 使用最长匹配前缀:if CPL(A,D) > CPL(B,D), R(A) *> R(B);if CPL(B,D) > CPL(A,D), R(B) *> R(A).
目的地址选择程序
算法说明:
1. Q(D)是为目的地D选择的源地址
2. 如果目的地B不可到达,则U(B)为布尔值true
3. E(A)表示采用某些"封装传输"可到达目的地A
4. 集合SD(S)采用与前面的成对元素A和B相同的结构
算法规则如下:
1. 避免不可用的目的地:if U(B) or Q(B) = φ, R(A) *> R(B);if U(A) or Q(A) = φ, R(B) *> R(A).
2. 优先选择匹配范围:if S(A) = S(Q(A)) and S(B) ≠ S(Q(B)), R(A) *> R(B);if S(B) = S(Q(B)) and S(A) ≠ S(Q(A)), R(B) *> R(A).
3. 避免过期地址:if ∧(Q(A)) < ∧(Q(B)), R(B) *> R(A);if ∧(Q(B)) < ∧(Q(A)), R(A) *> R(B).
4. 优先选择家乡地址:if H(Q(A)) and C(Q(A)) and ┐(C(Q(B)) and H(Q(B))), R(A) *> R(B);if (Q(B)) and C(Q(B)) and ┐(C(Q(A)) and H(Q(A))), R(B) *> R(A);if (H(Q(A)) and ┐C(Q(A))) and (┐H(Q(B)) and C(Q(B))), R(A) *> R(B);if (H(Q(B)) and ┐C(Q(B))) and (┐H(Q(A)) and C(Q(A))), R(B) *> R(A).
5. 优先选择匹配标签:if L(Q(A)) = L(A) and L(Q(B)) ≠ L(B), R(A) *> R(B);if L(Q(A)) ≠ L(A) and L(Q(B)) = L(B), R(B) *> R(A).
6. 优先选择更高优先级:if P(A) > P(B), R(A) *> R(B);if P(A) < P(B), R(B) *> R(A).
7. 优先选择本地传输:if E(A) and ┐E(B), R(B) *> R(A);if E(B) and ┐E(A), R(A) *> R(B).
8. 优先选择更小范围:if S(A) < S(B), R(A) *> R(B) else R(B) *> R(A).
9. 使用最长匹配前缀:if CPL(A,Q(A)) > CPL(B,Q(B)), R(A) *> R(B);if CPL(A,Q(A)) < CPL(B,Q(B)), R(B) *> R(A).
10. 否则,保持等级顺序不变
这些算法(源地址和目的地址选择)倾向于选择范围有限、永久性的地址。
参考:
《TCP IP 详解卷1:协议》
TCP/IP 笔记 - Internet协议的更多相关文章
- TCP/IP 笔记 - 地址解析协议
地址解析协议(ARP)提供了一种在IPv4地址和各种网络技术使用的硬件地址之间的映射.ARP仅用于IPv4,IPv6使用邻居发现协议,它被合并入ICMPv6.地址解析是发现两个地址之间的映射关系的过程 ...
- TCP/IP 笔记 - Internet地址结构
连接到Internet中的每台设备至少都有一个IP地址,IP地址表示了流量的来源(好比别人要找你玩,需要知道你家的地址:网络中别人需要和你通信,也需要知道IP地址),且Internet中的IP地址必须 ...
- TCP/IP 和HTTP 协议基础知识
来源:http://www.myhack58.com/Article/60/63/2014/50072.htm 相信不少初学手机联网开发的朋友都想知道Http与Socket连接究竟有什么区别,希望通过 ...
- TCP/IP笔记(1)
TCP/IP 背景和介绍 上世纪 70 年代,随着计算机技术的发展,计算机使用者意识到:要想发挥计算机更大的作用,就要将世界各地的计算机连接起来.但是简单的连接是远远不够的,因为计算机之间无法沟通.因 ...
- http与https与socket tcp/IP与UDP 协议等
网络由下往上分为: 物理层-- 数据链路层-- 网络层-- IP协议 传输层-- ...
- TCP/IP及http协议 SOAP REST
TCP/IP及http协议: TCP/IP协议主要解决数据如何在网络中传输, 而HTTP是应用层协议,主要解决如何包装数据 SOAP:简单对象访问协议(Simple Object Access Pro ...
- TCP/IP 5层协议簇/协议栈
TCP/IP 5层协议簇/协议栈 数据/PDU 应用层 PC.防火墙 数据段/段Fragment 传输层 防火墙 报文/包/IP包packet 网络层 路由器 帧Frame 数据链路层 交换机.网卡 ...
- TCP/IP 笔记 - ICMPv4和ICMPv6 : Internet控制报文协议
ICMP是一种面向无连接的协议,负责传递可能需要注意的差错和控制报文,差错指示通信网络是否存在错误(如目的主机无法到达.IP路由器无法正常传输数据包等.注意,路由器缓冲区溢出导致的丢包不包括在ICMP ...
- TCP/IP笔记(四)IP协议
前言 IP相当于OSI参考模型的第3层--网络层:主要作用是"实现终端节点之间的通信"又称"点对点通信". IP作为整个TCP/IP中至关重要的协议,主要负责将 ...
随机推荐
- js学习(5)语法专题
Js是一种动态类型语言,变量没有类型限制,可以随时赋值 强制转换: 主要指使用Number(),String()和Boolean()三个函数,手动将各个类型的值,分别转换为数字,字符串或布尔值 Num ...
- Solidity合约间的调用 -Solidity通过合约转ERC20代币
Solidity通过合约转ERC20代币 ERC20代币并不能像Ether一样使用sendTo.transfer(amt)来转账,ERC20代币只能通过token中定义的transfer方法来转账 ...
- django.core.exceptions.ImproperlyConfigured: Requested setting DEFAULT_INDEX_TABLESPACE, but settings are not configured. You must either define the environment variable DJANGO_SETTINGS_MODULE or call
Error info: django.core.exceptions.ImproperlyConfigured: Requested setting DEFAULT_INDEX_TABLESPACE, ...
- mybatis的Sql语句打印
我们在使用mybatis的时候,有时候,希望可以在eclipse的控制台下打印出来sql语句,但是有时候却不希望相关的语句打印.这个时候,需要我们进行一些配置. 在mybatis中,他通过调用一些接 ...
- mybatis电子商务平台b2b2c
技术解决方案 开发语言: java.j2ee 数据库:mysql JDK支持版本: JDK1.6.JDK1.7.JDK1.8版本 核心技术:分布式.云服务.微服务.服务编排等. 核心架构: 使用Spr ...
- php 高效日志记录扩展seaslog 的使用
群里交流,听说seaslog不错,此文旨在记录使用. $ wget https://github.com/Neeke/SeasLog/archive/master.zip $ unzip master ...
- RDS MySQL InnoDB 锁等待和锁等待超时的处理
https://help.aliyun.com/knowledge_detail/41705.html 1. Innodb 引擎表行锁等待和等待超时发生的场景 2.Innodb 引擎行锁等待情况的处理 ...
- tensorflow学习之(一)预测一条直线y = 0.1x + 0.3
#预测一条y = 0.1x + 0.3的直线 import tensorflow as tf import numpy as np #科学计算模块 ''' tf.random_normal([784, ...
- suse下修改主机名
export HOSTNAME=主机名 echo $HOSTNAME>/etc/HOSTNAME /etc/rc.d/boot.localnet stop /etc/rc.d/boot.loca ...
- HDMI EDID 处理过程
DDC的参数 EDID是一种VESA 标准数据格式,其中包含有关监视器及其性能的参数,包括供应商信息.最大图像大小.颜色设置.厂商预设置.频率范围的限制以及显示器名和序列号的字符串.EDID数据标准: ...