python3爬虫——下载unsplash美图到本地
最近发现一个网站www.unsplash.com ( 没有广告费哈,纯粹觉得不错 ),网页做得很美观,上面也都是一些免费的摄影照片,觉得很好看,就决定利用蹩脚的技能写个爬虫下载图片。
先随意感受一下这个网站:
接下来开始对网页进行解析:
在该网页检查元素,选择其中一张图片查看它的代码
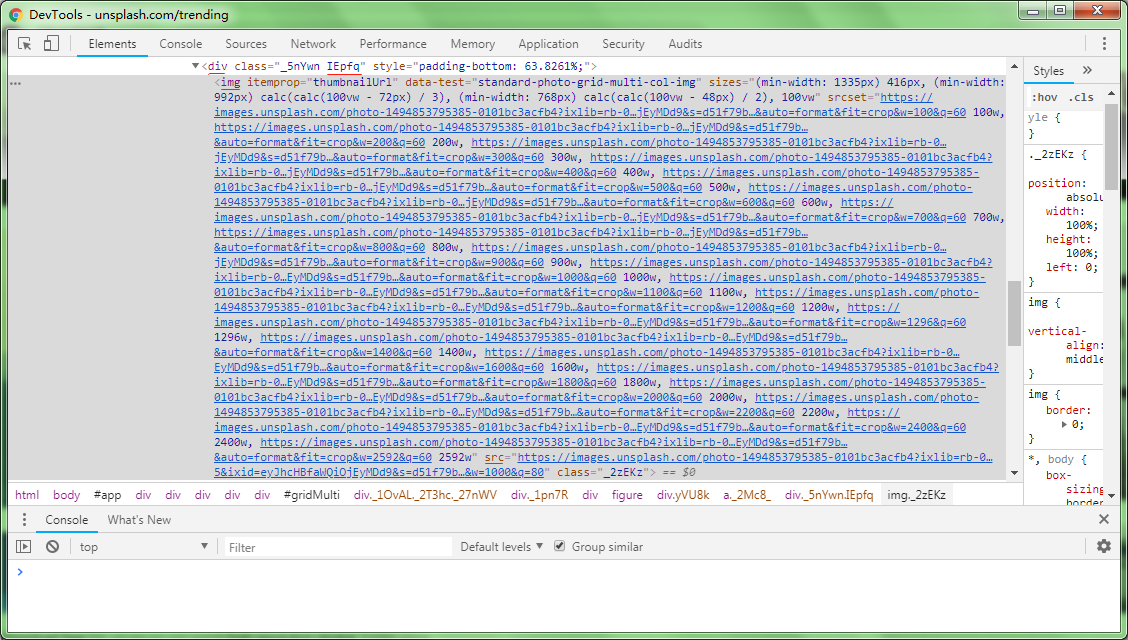
可以看到,图片 img 在一个 div 的 tag 里面,而且 class = ”IEpfq“,不过那么多内容,虽然有点乱,但其实看 src = ” “ 就行了。
但这只是一张图片的内容,得再看看其他的图片是不是一样。检查一下发现都是这样。这样子就算解析完成了。可以开始写代码了
#!/usr/bin/env python
# _*_ coding utf-8 _*_
from bs4 import BeautifulSoup
import requests i = 0
url = 'https://unsplash.com/'
html = requests.get(url)
soup = BeautifulSoup(html.text, 'lxml') img_class = soup.find_all('div', {"class": "IEpfq"}) # 找到div里面有class = "IEpfq"的内容 for img_list in img_class:
imgs = img_list.find_all('img') # 接着往下找到 img 标签
for img in imgs:
src = img['src'] # 以"src"为 key,找到 value
r = requests.get(src, stream=True)
image_name = 'unsplash_' + str(i) + '.jpg' # 图片命名
i += 1
with open('./img/%s' % image_name, 'wb') as file: # 打开文件
for chunk in r.iter_content(chunk_size=1024): # 以chunk_size = 1024的长度进行遍历
file.write(chunk)
print('Saved %s' % image_name)
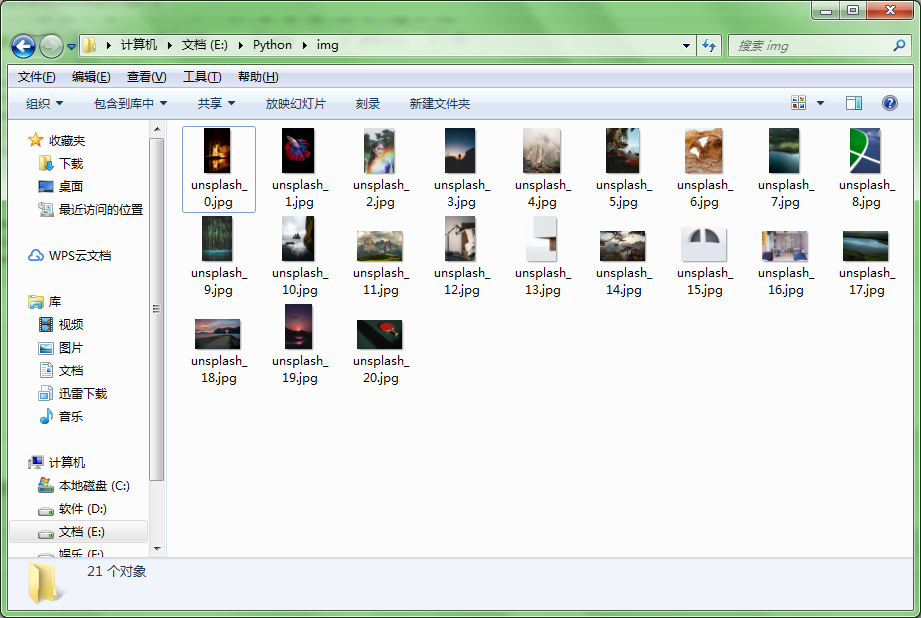
运行结果:
Saved unsplash_0.jpg
Saved unsplash_1.jpg
......
Saved unsplash_19.jpg
Saved unsplash_20.jpg
python3爬虫——下载unsplash美图到本地的更多相关文章
- 自学Python九 爬虫实战二(美图福利)
作为一个新世纪有思想有文化有道德时刻准备着的屌丝男青年,在现在这样一个社会中,心疼我大慢播抵制大百度的前提下,没事儿上上网逛逛YY看看斗鱼翻翻美女图片那是必不可少的,可是美图虽多翻页费劲!今天我们就搞 ...
- python 站点爬虫 下载在线盗墓笔记小说到本地的脚本
近期闲着没事想看小说,找到一个全是南派三叔的小说的站点,决定都下载下来看看,于是动手,在非常多QQ群里高手的帮助下(本人正則表達式非常烂.程序复杂的正则都是一些高手指导的),花了三四天写了一个脚本 须 ...
- 【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图【华为云技术分享】
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 【Python3网络爬虫开发实战】 分析Ajax爬取今日头条街拍美图
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:haoxuan10 本节中,我们以今日头条为例来尝试通过分析Ajax请求 ...
- 转:【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- Python3爬虫系列:理论+实验+爬取妹子图实战
Github: https://github.com/wangy8961/python3-concurrency-pics-02 ,欢迎star 爬虫系列: (1) 理论 Python3爬虫系列01 ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- Qt Quick 图像处理实例之美图秀秀(附源代码下载)
在<Qt Quick 之 QML 与 C++ 混合编程具体解释>一文中我们解说了 QML 与 C++ 混合编程的方方面面的内容,这次我们通过一个图像处理应用.再来看一下 QML 与 C++ ...
- python3爬虫(4)各种网站视频下载方法
python3爬虫(4)各种网站视频下载方法原创H-KING 最后发布于2019-01-09 11:06:23 阅读数 13608 收藏展开理论上来讲只要是网上(浏览器)能看到图片,音频,视频,都能够 ...
随机推荐
- 3U - 算菜价
妈妈每天都要出去买菜,但是回来后,兜里的钱也懒得数一数,到底花了多少钱真是一笔糊涂帐.现在好了,作为好儿子(女儿)的你可以给她用程序算一下了,呵呵. Input 输入含有一些数据组,每组数据包括菜种( ...
- Mad Libs游戏1
简单的输入输出 输入代码 name1=input('请输入姓名:') name2=input('请输入一个句子:') name3=input('请输入一个地点:') name4=input('请输入一 ...
- cookie方法封装
将cookie封装主要是为了方便使用,可通过修改参数直接引用在其他需要的地方,不用重新写. 1.添加,删除,修改cookie /** * @param name name:cookie的name * ...
- SpringMVC学习 十三 拦截器栈
拦截器栈:就是有多个拦截器同时拦截相同的控制器(controller)请求,这写拦截器就构成了拦截器栈. 栈的特点是先进后出,在拦截器栈中也是如此,如果先执行了preHandle方法,也就是意味着先进 ...
- ubuntu16.04 下安装 visual studio code 以及利用 g++ 运行 c++程序
参考链接:1. http://www.linuxidc.com/Linux/2016-07/132798.htm(安装vs code) 2.https://blog.csdn.net/qq_28598 ...
- 网站日志流量分析采集(LuaJIT系统环境部署-node03,相关jar包自己手动上传)
注:/usr/local/src 是源码包路径,可以自己更改 服务器中安装依赖 yum -y install gcc perl pcre-devel openssl openssl-devel 上传 ...
- selenium之生成html测试报告--testng.xsl
自制版制作步骤: 1.首先下载一个文件名为testng.xslt-1.1.zip testng.xslt-1.1我在印象笔记里面备份了一份 打开testng.xslt中lib文件夹,找到saxon-8 ...
- MySQL之二 yum安装及初识
安装 yum install mysql-server chkconfig -list mysqld 查看mysqld服务是否为开机启动 chkconfig mysqld on 设为开机启动 ...
- windows更改命令行cmd的字体为conlosas+微软雅黑
windows更改命令行cmd的字体为conlosas+微软雅黑 动力来源于对美孜孜不倦的追求~ 下载conlosas+微软雅黑字体 谢谢支持. 将解压后的YaHei.Consolas.1.12.tt ...
- 六.使用python操作mysql数据库
数据库的安装和连接 pymysql的安装 pip install PyMySQL python连接数据库 import pymysql db = pymysql.connec ...