MapReduce原理
MapReduce原理
WordCount例子
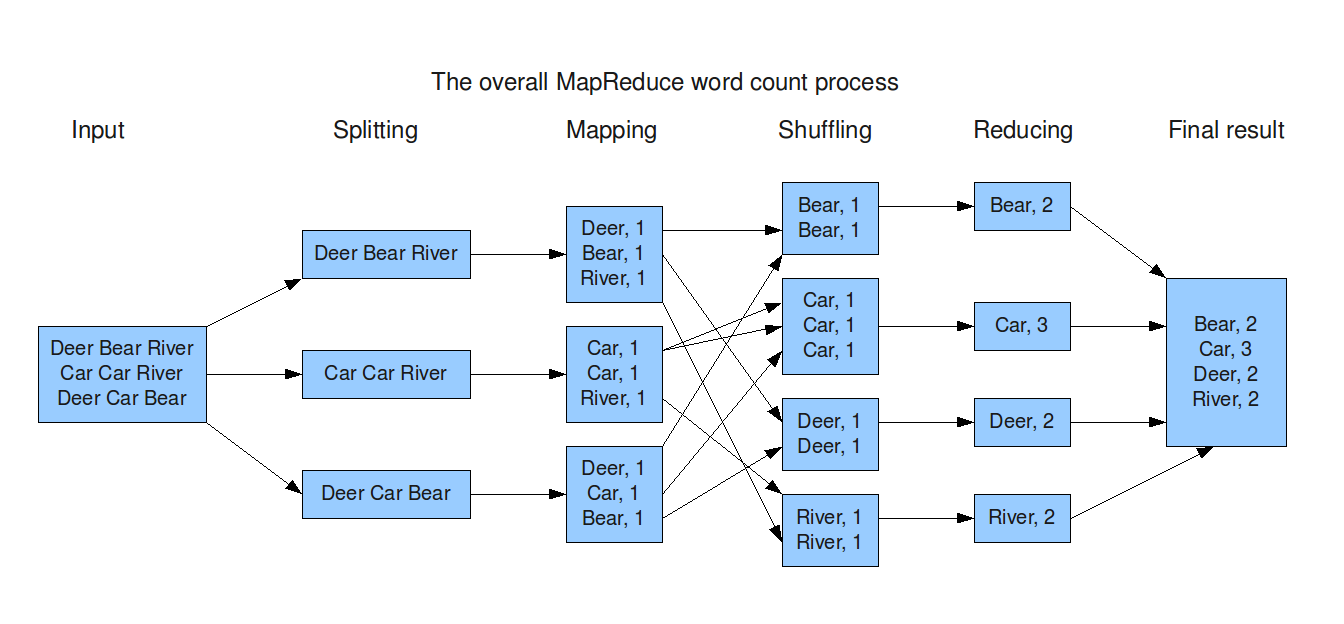
用mapreduce计算wordcount的例子:
package org.apache.hadoop.examples; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
先看main函数:
Configuration conf = new Configuration();
程序员开发mapreduce时候只是在填空,在map函数和reduce函数里编写实际进行的业务逻辑,其它的工作都是交给mapreduce框架自己操作的,但是至少我们要告诉它怎么操作啊,比如hdfs在哪里啊,mapreduce的jobstracker在哪里啊,而这些信息就在conf包下的配置文件里。因此,运行mapreduce程序前都要初始化Configuration,该类主要是读取mapreduce系统配置信息,这些信息包括hdfs还有mapreduce,也就是安装hadoop时候的配置文件例如:core-site.xml、hdfs-site.xml和mapred-site.xml等等文件里的信息。
接下来的代码是:
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
第一行就是在构建一个job,在mapreduce框架里一个mapreduce任务也叫mapreduce作业也叫做一个mapreduce的job,而具体的map和reduce运算就是task了,这里我们构建一个job,构建时候有两个参数,一个是conf这个就不累述了,一个是这个job的名称。
第二行就是装载程序员编写好的计算程序,例如我们的程序类名就是WordCount了。这里我要做下纠正,虽然我们编写mapreduce程序只需要实现map函数和reduce函数,但是实际开发我们要实现三个类,第三个类是为了配置mapreduce如何运行map和reduce函数,准确的说就是构建一个mapreduce能执行的job了,例如WordCount类。
第三行和第五行就是装载map函数和reduce函数实现类了,这里多了个第四行,这个是装载Combiner类,这个我后面讲mapreduce运行机制时候会讲述,其实本例去掉第四行也没有关系,但是使用了第四行理论上运行效率会更好。
再接下来是:
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
这个是定义输出的key/value的类型,也就是最终存储在hdfs上结果文件的key/value的类型。
最后是:
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
第一行就是构建输入的数据文件,第二行是构建输出的数据文件,最后一行如果job运行成功了,我们的程序就会正常退出。FileInputFormat和FileOutputFormat是很有学问的,我会在下面的mapreduce运行机制里讲解到它们。
MapReduce运行机制

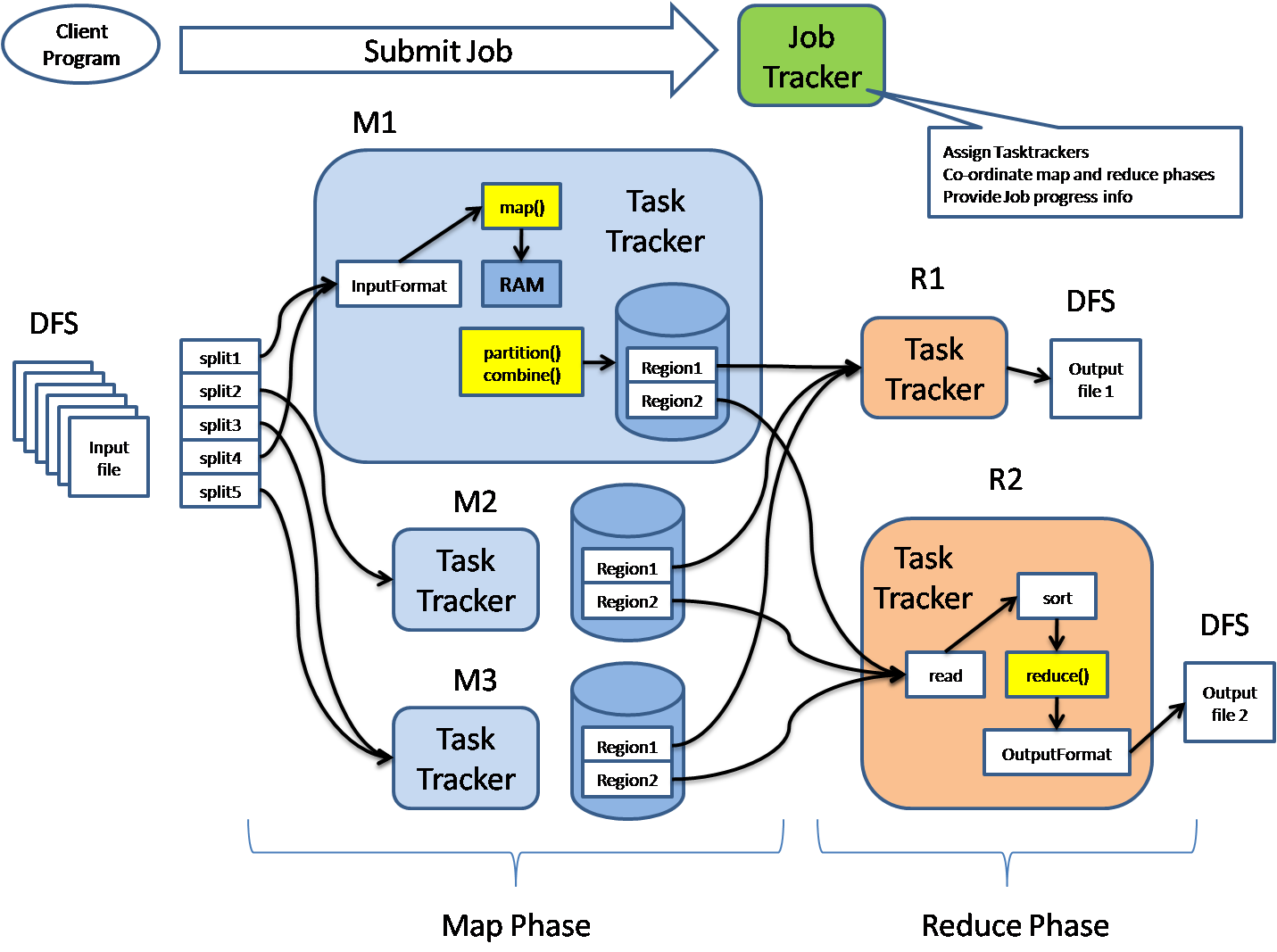
首先讲讲物理实体,mapreduce作业执行涉及4个独立的实体:
- 客户端(Client):编写mapreduce程序,配置作业,提交作业,这就是程序员完成的工作;
- JobTracker:初始化作业,分配作业,与TaskTracker通信,协调整个作业的执行;
- TaskTracker:保持与JobTracker的通信,在分配的数据片段上执行Map或Reduce任务;
- Hdfs:保存作业的数据、配置信息等等,最后的结果也是保存在hdfs上面。
注意:TaskTracker可以有多个,JobTracker则只会有一个(JobTracker只能有一个就和hdfs里namenode一样存在单点故障,我会在后面的mapreduce的相关问题里讲到这个问题的)

首先是客户端要编写好mapreduce程序,配置好mapreduce的作业也就是job,接下来就是提交job了,提交job是提交到JobTracker上的,这个时候JobTracker就会构建这个job,具体就是分配一个新的job任务的ID值,接下来它会做检查操作,这个检查就是确定输出目录是否存在,如果存在那么job就不能正常运行下去,JobTracker会抛出错误给客户端,接下来还要检查输入目录是否存在,如果不存在同样抛出错误,如果存在JobTracker会根据输入计算输入分片(Input Split),如果分片计算不出来也会抛出错误,至于输入分片我后面会做讲解的,这些都做好了JobTracker就会配置Job需要的资源了。分配好资源后,JobTracker就会初始化作业,初始化主要做的是将Job放入一个内部的队列,让配置好的作业调度器能调度到这个作业,作业调度器会初始化这个job,初始化就是创建一个正在运行的job对象(封装任务和记录信息),以便JobTracker跟踪job的状态和进程。
初始化完毕后,作业调度器会获取输入分片信息(input split),每个分片创建一个map任务。接下来就是任务分配了,这个时候tasktracker会运行一个简单的循环机制定期发送心跳给jobtracker,心跳间隔是5秒,程序员可以配置这个时间,心跳就是jobtracker和tasktracker沟通的桥梁,通过心跳,jobtracker可以监控tasktracker是否存活,也可以获取tasktracker处理的状态和问题,同时tasktracker也可以通过心跳里的返回值获取jobtracker给它的操作指令。任务分配好后就是执行任务了。在任务执行时候jobtracker可以通过心跳机制监控tasktracker的状态和进度,同时也能计算出整个job的状态和进度,而tasktracker也可以本地监控自己的状态和进度。当jobtracker获得了最后一个完成指定任务的tasktracker操作成功的通知时候,jobtracker会把整个job状态置为成功,然后当客户端查询job运行状态时候(注意:这个是异步操作),客户端会查到job完成的通知的。如果job中途失败,mapreduce也会有相应机制处理。
下面从逻辑实体的角度讲解mapreduce运行机制,这些按照时间顺序包括:输入分片(input split)、map阶段、combiner阶段、shuffle阶段和reduce阶段。
输入分片(input split)
在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组,输入分片(input split)往往和hdfs的block(块)关系很密切,假如我们设定hdfs的块的大小是64MB,如果我们输入有三个文件,大小分别是3MB、65MB和127MB,那么mapreduce会把3MB文件分为一个输入分片(input split),65MB则是两个输入分片(input split)而127MB也是两个输入分片(input split),换句话说我们如果在map计算前做输入分片调整,例如合并小文件,那么就会有5个map任务将执行,而且每个map执行的数据大小不均,这个也是mapreduce优化计算的一个关键点。
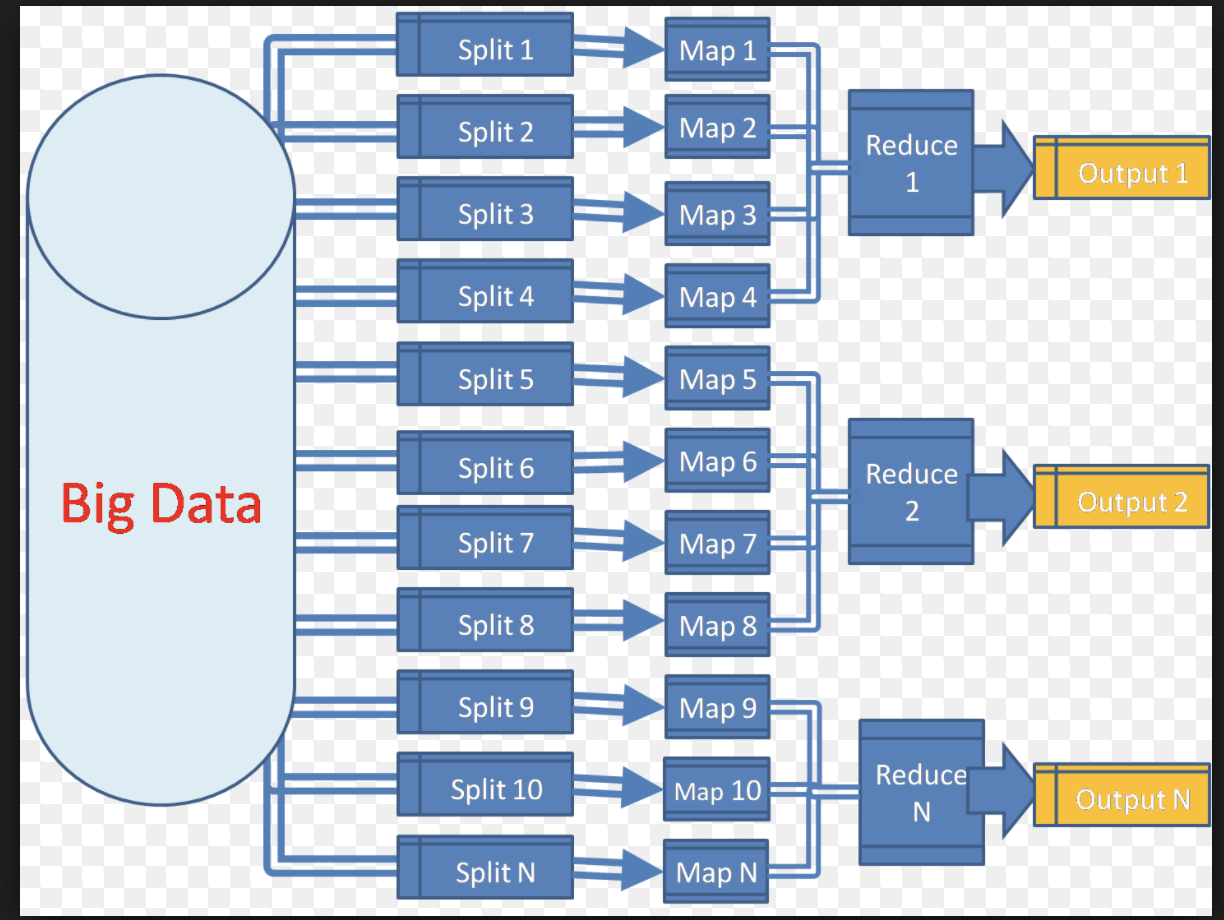
map阶段
就是程序员编写好的map函数了,因此map函数效率相对好控制,而且一般map操作都是本地化操作也就是在数据存储节点上进行;
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {…}
这里有三个参数,前面两个Object key, Text value就是输入的key和value,第三个参数Context context这是可以记录输入的key和value,例如:context.write(word, one); 此外context还会记录map运算的状态。
combiner阶段
combiner阶段是程序员可以选择的,combiner其实也是一种reduce操作,因此我们看见WordCount类里是用reduce进行加载的。Combiner是一个本地化的reduce操作,它是map运算的后续操作,主要是在map计算出中间文件前做一个简单的合并重复key值的操作,例如我们对文件里的单词频率做统计,map计算时候如果碰到一个hadoop的单词就会记录为1,但是这篇文章里hadoop可能会出现n多次,那么map输出文件冗余就会很多,因此在reduce计算前对相同的key做一个合并操作,那么文件会变小,这样就提高了宽带的传输效率,毕竟hadoop计算力宽带资源往往是计算的瓶颈也是最为宝贵的资源,但是combiner操作是有风险的,使用它的原则是combiner的输入不会影响到reduce计算的最终输入,例如:如果计算只是求总数,最大值,最小值可以使用combiner,但是做平均值计算使用combiner的话,最终的reduce计算结果就会出错。
shuffle阶段
将map的输出作为reduce的输入的过程就是shuffle了,这个是mapreduce优化的重点地方。这里我不讲怎么优化shuffle阶段,讲讲shuffle阶段的原理,因为大部分的书籍里都没讲清楚shuffle阶段。Shuffle一开始就是map阶段做输出操作,一般mapreduce计算的都是海量数据,map输出时候不可能把所有文件都放到内存操作,因此map写入磁盘的过程十分的复杂,更何况map输出时候要对结果进行排序,内存开销是很大的,map在做输出时候会在内存里开启一个环形内存缓冲区,这个缓冲区专门用来输出的,默认大小是100mb,并且在配置文件里为这个缓冲区设定了一个阀值,默认是0.80(这个大小和阀值都是可以在配置文件里进行配置的),同时map还会为输出操作启动一个守护线程,如果缓冲区的内存达到了阀值的80%时候,这个守护线程就会把内容写到磁盘上,这个过程叫spill,另外的20%内存可以继续写入要写进磁盘的数据,写入磁盘和写入内存操作是互不干扰的,如果缓存区被撑满了,那么map就会阻塞写入内存的操作,让写入磁盘操作完成后再继续执行写入内存操作,前面我讲到写入磁盘前会有个排序操作,这个是在写入磁盘操作时候进行,不是在写入内存时候进行的,如果我们定义了combiner函数,那么排序前还会执行combiner操作。
每次spill操作也就是写入磁盘操作时候就会写一个溢出文件,也就是说在做map输出有几次spill就会产生多少个溢出文件,等map输出全部做完后,map会合并这些输出文件。这个过程里还会有一个Partitioner操作,对于这个操作很多人都很迷糊,其实Partitioner操作和map阶段的输入分片(Input split)很像,一个Partitioner对应一个reduce作业,如果我们mapreduce操作只有一个reduce操作,那么Partitioner就只有一个,如果我们有多个reduce操作,那么Partitioner对应的就会有多个,Partitioner因此就是reduce的输入分片,这个程序员可以编程控制,主要是根据实际key和value的值,根据实际业务类型或者为了更好的reduce负载均衡要求进行,这是提高reduce效率的一个关键所在。到了reduce阶段就是合并map输出文件了,Partitioner会找到对应的map输出文件,然后进行复制操作,复制操作时reduce会开启几个复制线程,这些线程默认个数是5个,程序员也可以在配置文件更改复制线程的个数,这个复制过程和map写入磁盘过程类似,也有阀值和内存大小,阀值一样可以在配置文件里配置,而内存大小是直接使用reduce的tasktracker的内存大小,复制时候reduce还会进行排序操作和合并文件操作,这些操作完了就会进行reduce计算了。
reduce阶段
和map函数一样也是程序员编写的,最终结果是存储在hdfs上的。
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {…}
reduce函数的输入也是一个key/value的形式,不过它的value是一个迭代器的形式Iterable<IntWritable> values,也就是说reduce的输入是一个key对应一组的值的value,reduce也有context和map的context作用一致。
相关问题
jobtracker的单点故障
jobtracker和hdfs的namenode一样也存在单点故障,单点故障一直是hadoop被人诟病的大问题,为什么hadoop的做的文件系统和mapreduce计算框架都是高容错的,但是最重要的管理节点的故障机制却如此不好,我认为主要是namenode和jobtracker在实际运行中都是在内存操作,而做到内存的容错就比较复杂了,只有当内存数据被持久化后容错才好做,namenode和jobtracker都可以备份自己持久化的文件,但是这个持久化都会有延迟,因此真的出故障,任然不能整体恢复,另外hadoop框架里包含zookeeper框架,zookeeper可以结合jobtracker,用几台机器同时部署jobtracker,保证一台出故障,有一台马上能补充上,不过这种方式也没法恢复正在跑的mapreduce任务。
输出目录的检查
做mapreduce计算时候,输出一般是一个文件夹,而且该文件夹是不能存在,我在出面试题时候提到了这个问题,而且这个检查做的很早,当我们提交job时候就会进行,mapreduce之所以这么设计是保证数据可靠性,如果输出目录存在reduce就搞不清楚你到底是要追加还是覆盖,不管是追加和覆盖操作都会有可能导致最终结果出问题,mapreduce是做海量数据计算,一个生产计算的成本很高,例如一个job完全执行完可能要几个小时,因此一切影响错误的情况mapreduce是零容忍的。
InputFormat和OutputFormat
我们在编写map函数时候发现map方法的参数是之间操作行数据,没有牵涉到InputFormat,这些事情在我们new Path时候mapreduce计算框架帮我们做好了,而OutputFormat也是reduce帮我们做好了,我们使用什么样的输入文件,就要调用什么样的InputFormat,InputFormat是和我们输入的文件类型相关的,mapreduce里常用的InputFormat有FileInputFormat普通文本文件,SequenceFileInputFormat是指hadoop的序列化文件,另外还有KeyValueTextInputFormat。OutputFormat就是我们想最终存储到hdfs系统上的文件格式了,这个根据你需要定义了,hadoop有支持很多文件格式,这里不一一列举。
MapReduce原理的更多相关文章
- 04 MapReduce原理介绍
大数据实战(上) # MapReduce原理介绍 大纲: * Mapreduce介绍 * MapReduce2运行原理 * shuffle及排序 定义 * Mapreduce 最早是由googl ...
- 大数据运算模型 MapReduce 原理
大数据运算模型 MapReduce 原理 2016-01-24 杜亦舒 MapReduce 是一个大数据集合的并行运算模型,由google提出,现在流行的hadoop中也使用了MapReduce作为计 ...
- MapReduce原理及其主要实现平台分析
原文:http://www.infotech.ac.cn/article/2012/1003-3513-28-2-60.html MapReduce原理及其主要实现平台分析 亢丽芸, 王效岳, 白如江 ...
- Hapoop原理及MapReduce原理分析
Hapoop原理 Hadoop是一个开源的可运行于大规模集群上的分布式并行编程框架,其最核心的设计包括:MapReduce和HDFS.基于 Hadoop,你可以轻松地编写可处理海量数据的分布式并行程序 ...
- Hadoop学习记录(4)|MapReduce原理|API操作使用
MapReduce概念 MapReduce是一种分布式计算模型,由谷歌提出,主要用于搜索领域,解决海量数据计算问题. MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce( ...
- hadoop笔记之MapReduce原理
MapReduce原理 MapReduce原理 简单来说就是,一个大任务分成多个小的子任务(map),并行执行后,合并结果(reduce). 例子: 100GB的网站访问日志文件,找出访问次数最多的I ...
- MapReduce 原理与 Python 实践
MapReduce 原理与 Python 实践 1. MapReduce 原理 以下是个人在MongoDB和Redis实际应用中总结的Map-Reduce的理解 Hadoop 的 MapReduce ...
- 大数据 --> MapReduce原理与设计思想
MapReduce原理与设计思想 简单解释 MapReduce 算法 一个有趣的例子:你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查并且数出有多少张是黑桃? MapReduce方法则是: 给在座 ...
- hadoop自带例子SecondarySort源码分析MapReduce原理
这里分析MapReduce原理并没用WordCount,目前没用过hadoop也没接触过大数据,感觉,只是感觉,在项目中,如果真的用到了MapReduce那待排序的肯定会更加实用. 先贴上源码 pac ...
随机推荐
- javaweb笔记
(1)web项目需复制web.xml文件 (2)需要复制classes文件 需要把bin里面的com----复制到classes中
- redis的主从服务器配置
1. redis的主从配置: (1)把redis的配置文件(reids.conf)拷贝2份 [root@192 redis]# cp redis.conf redis6380.conf [root@1 ...
- mvc中AntiForgeryToken的实现方式--看Mvc源码
通过 AntiForgeryWorker的GetHtml()方法生成html --input hide元素--value=要验证的值,并生成cookie--用于保存需要验证的值. 类中的AntiFor ...
- Linux下chkconfig命令
chkconfig命令主要用来更新(启动或停止)和查询系统服务的运行级信息.谨记chkconfig不是立即自动禁止或激活一个服务,它只是简单的改变了符号连接. 使用语法:chkconfig [--ad ...
- 开发入门,学Java还是学大数据?
经常有人问,我想学习开发,到底是学Java好还是学大数据好?或者是,学习大数据还有必要学Java吗? 依我说,这个提问的标准答案是:两者都学. 先来甩两张图. 一张是腾讯 ...
- 如何确定一台linux主机是Linux (i386/i686)还是Linux (x86_64)
在下软件包的时候,往往会遇到一个选择: 假设自己的主机是Linux,那么Linux (i386/i686)和Linux (x86_64)究竟应该选哪一个呢? 针对当今的硬件而言,如果你主机的CPU是6 ...
- Zip文件和RAR文件解压
直接上工具类: package com.ksource.pwlp.util; import java.io.File; import java.io.FileOutputStream; import ...
- ninja-build环境安装
ninja是一个小型构建系统,专注于速度,和常用的make类似,有一些软件就是基于ninja编译构建的,比如clickhouse数据库就需要依赖ninja,因为最近在研究clickhouse,需要依赖 ...
- Translate Angular >=4 with ngx-translate and multiple modules
原文:https://medium.com/@lopesgon/translate-angular-4-with-ngx-translate-and-multiple-modules-7d9f0252 ...
- wait-for
Use a tool such as wait-for-it, dockerize, or sh-compatible wait-for. These are small wrapper script ...