Relation Extraction中SVM分类样例unbalance data问题解决 -松弛变量与惩罚因子
转载自:http://blog.csdn.net/yangliuy/article/details/8152390
1、问题描述
做关系抽取就是要从产品评论中抽取出描述产品特征项的target短语以及修饰该target的opinion短语,在opinion mining里面属于很重要的task,很多DM、NLP相关的paper在做这方面的工作。基本的思路是:
(1)从sentence的parse tree(比如stanford parser)中选取候选target结点和候选opinion结点,然后对所有的候选target和opinion组合选取features,用SVM进行训练分类。
(2)给定种子opinion words,借助parse tree中的path rules,多次迭代抽取新的target和opinion,称为Double Propagation (Qiu et al, IJCAI'09)
(3) 采用Tree kernel 的方法进行关系抽取(Wu et al, EMNLP'09)
如果采用第一种思路,在用SVM分类时就会遇到正负样例不均衡的问题。原因是,即便候选target和opinion抽取的recall和presicion可以达到100%,其不同的组合中也是负样例居多,正样例比例很少。我做实验时,遇到正负样例的比例为1:9,用SVM分类时,所有测试样例均被分类道来负样例中,这样的问题称为Unbalanced Data分类。
2、解决办法
对不同类别设置不同的惩罚因子。要用到LibSVM 的–C及-W选项。详细解释见《LIBSVM: A Library for Support Vector Machines》论文第6部分Unbalanced Data and Solving the Two-variable Sub-problem。C是惩罚因子,可以针对正负样本使用不同的惩罚值。 可以认为这个惩罚值 是指 对要训练的分类器 发生误判的惩罚程度。
比如:对于unbalanced的数据集,假设正样本+1占10%,负样本-1占90%, 正负样本比例为1:9. 按道理来说,我们训练svm分类器时,如果将+1样本误判为-1样本,我们需要加大惩罚力度。结合Libsvm FAQ中所说的例子,“svm-train -s 0 -c 10 -w1 1 -w-15 data_file 。 the penalty for class"-1" is larger. Note that this -w option is for C-SVC only”。
那么要解决关系抽取中unbalance
data问题,命令应该是:svm-train -s 0 -c 10 -w1 9-w-1 1 data_file
,相当于采用C-SVC模式,对+1误判惩罚为10*9=90,
对-1误判为10*1=10,这样的设置会让分类器倾向分出更多的正样例来,这样分类结果就不再是全为-1了。并且,我们还可以进一步实验不同惩罚因子设置的情况下分类的准确率和召回率。
3、SVM中的松弛变量与惩罚因子
这一部分转自http://blog.csdn.net/qll125596718/article/details/6910921,对松弛变量和惩罚因子的介绍非常通俗易懂。
3.1 松弛变量
现在我们已经把一个本来线性不可分的文本分类问题,通过映射到高维空间而变成了线性可分的。就像下图这样:
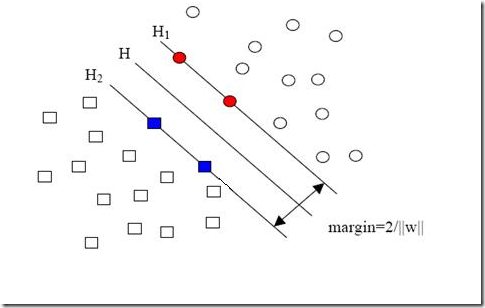
圆形和方形的点各有成千上万个(毕竟,这就是我们训练集中文档的数量嘛,当然很大了)。现在想象我们有另一个训练集,只比原先这个训练集多了一篇文章,映射到高维空间以后(当然,也使用了相同的核函数),也就多了一个样本点,但是这个样本的位置是这样的:
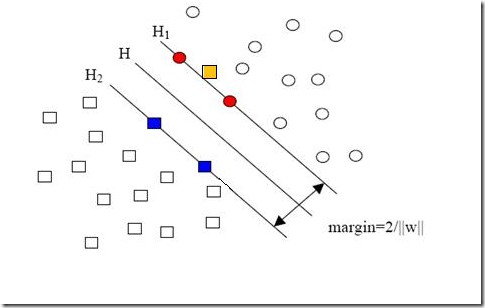
就是图中黄色那个点,它是方形的,因而它是负类的一个样本,这单独的一个样本,使得原本线性可分的问题变成了线性不可分的。这样类似的问题(仅有少数点线性不可分)叫做“近似线性可分”的问题。
以我们人类的常识来判断,说有一万个点都符合某种规律(因而线性可分),有一个点不符合,那这一个点是否就代表了分类规则中我们没有考虑到的方面呢(因而规则应该为它而做出修改)?
其实我们会觉得,更有可能的是,这个样本点压根就是错误,是噪声,是提供训练集的同学人工分类时一打瞌睡错放进去的。所以我们会简单的忽略这个样本点,仍然使用原来的分类器,其效果丝毫不受影响。
但这种对噪声的容错性是人的思维带来的,我们的程序可没有。由于我们原本的优化问题的表达式中,确实要考虑所有的样本点(不能忽略某一个,因为程序它怎么知道该忽略哪一个呢?),在此基础上寻找正负类之间的最大几何间隔,而几何间隔本身代表的是距离,是非负的,像上面这种有噪声的情况会使得整个问题无解。这种解法其实也叫做“硬间隔”分类法,因为他硬性的要求所有样本点都满足和分类平面间的距离必须大于某个值。
因此由上面的例子中也可以看出,硬间隔的分类法其结果容易受少数点的控制,这是很危险的(尽管有句话说真理总是掌握在少数人手中,但那不过是那一小撮人聊以自慰的词句罢了,咱还是得民主)。
但解决方法也很明显,就是仿照人的思路,允许一些点到分类平面的距离不满足原先的要求。由于不同的训练集各点的间距尺度不太一样,因此用间隔(而不是几何间隔)来衡量有利于我们表达形式的简洁。我们原先对样本点的要求是:
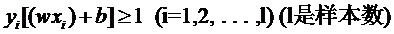
意思是说离分类面最近的样本点函数间隔也要比1大。如果要引入容错性,就给1这个硬性的阈值加一个松弛变量,即允许:
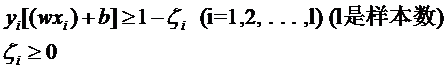
因为松弛变量是非负的,因此最终的结果是要求间隔可以比1小。但是当某些点出现这种间隔比1小的情况时(这些点也叫离群点),意味着我们放弃了对这些点的精确分类,而这对我们的分类器来说是种损失。但是放弃这些点也带来了好处,那就是使分类面不必向这些点的方向移动,因而可以得到更大的几何间隔(在低维空间看来,分类边界也更平滑)。显然我们必须权衡这种损失和好处。好处很明显,我们得到的分类间隔越大,好处就越多。回顾我们原始的硬间隔分类对应的优化问题:
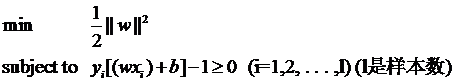
||w||^2就是我们的目标函数(当然系数可有可无),希望它越小越好,因而损失就必然是一个能使之变大的量(能使它变小就不叫损失了,我们本来就希望目标函数值越小越好)。那如何来衡量损失,有两种常用的方式,有人喜欢用:
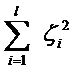
而有人喜欢用:
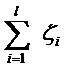
其中L都是样本的数目。两种方法没有大的区别。如果选择了第一种,得到的方法的就叫做二阶软间隔分类器,第二种就叫做一阶软间隔分类器。把损失加入到目标函数里的时候,就需要一个惩罚因子(cost,也就是libSVM的诸多参数中的C),原来的优化问题就变成了下面这样:
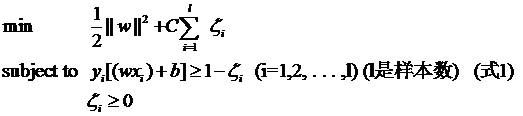
这个式子有这么几点要注意:
(1)并非所有的样本点都有一个松弛变量与其对应。实际上只有“离群点”才有,或者也可以这么看,所有没离群的点松弛变量都等于0(对负类来说,离群点就是在前面图中,跑到H2右侧的那些负样本点,对正类来说,就是跑到H1左侧的那些正样本点)。
(2)松弛变量的值实际上标示出了对应的点到底离群有多远,值越大,点就越远。
(3)惩罚因子C决定了你有多重视离群点带来的损失,显然当所有离群点的松弛变量的和一定时,你定的C越大,对目标函数的损失也越大,此时就暗示着你非常不愿意放弃这些离群点,最极端的情况是你把C定为无限大,这样只要稍有一个点离群,目标函数的值马上变成无限大,马上让问题变成无解,这就退化成了硬间隔问题。
(4)惩罚因子C不是一个变量,整个优化问题在解的时候,C是一个你必须事先指定的值,指定这个值以后,解一下,得到一个分类器,然后用测试数据看看结果怎么样,如果不够好,换一个C的值,再解一次优化问题,得到另一个分类器,再看看效果,如此就是一个参数寻优的过程,但这和优化问题本身决不是一回事,优化问题在解的过程中,C一直是定值,要记住。
(5)尽管加了松弛变量这么一说,但这个优化问题仍然是一个优化问题(汗,这不废话么),解它的过程比起原始的硬间隔问题来说,没有任何更加特殊的地方。
从大的方面说优化问题解的过程,就是先试着确定一下w,也就是确定了前面图中的三条直线,这时看看间隔有多大,又有多少点离群,把目标函数的值算一算,再换一组三条直线(你可以看到,分类的直线位置如果移动了,有些原来离群的点会变得不再离群,而有的本来不离群的点会变成离群点),再把目标函数的值算一算,如此往复(迭代),直到最终找到目标函数最小时的w。
啰嗦了这么多,读者一定可以马上自己总结出来,松弛变量也就是个解决线性不可分问题的方法罢了,但是回想一下,核函数的引入不也是为了解决线性不可分的问题么?为什么要为了一个问题使用两种方法呢?
其实两者还有微妙的不同。一般的过程应该是这样,还以文本分类为例。在原始的低维空间中,样本相当的不可分,无论你怎么找分类平面,总会有大量的离群点,此时用核函数向高维空间映射一下,虽然结果仍然是不可分的,但比原始空间里的要更加接近线性可分的状态(就是达到了近似线性可分的状态),此时再用松弛变量处理那些少数“冥顽不化”的离群点,就简单有效得多啦。
本节中的(式1)也确实是支持向量机最最常用的形式。至此一个比较完整的支持向量机框架就有了,简单说来,支持向量机就是使用了核函数的软间隔线性分类法。
3.2 惩罚因子
接下来要说的东西其实不是松弛变量本身,但由于是为了使用松弛变量才引入的,因此放在这里也算合适,那就是惩罚因子C。回头看一眼引入了松弛变量以后的优化问题:
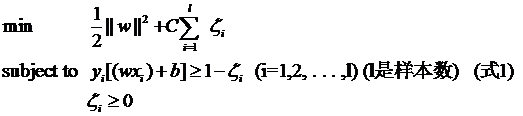
注意其中C的位置,也可以回想一下C所起的作用(表征你有多么重视离群点,C越大越重视,越不想丢掉它们)。这个式子是以前做SVM的人写的,大家也就这么用,但没有任何规定说必须对所有的松弛变量都使用同一个惩罚因子,我们完全可以给每一个离群点都使用不同的C,这时就意味着你对每个样本的重视程度都不一样,有些样本丢了也就丢了,错了也就错了,这些就给一个比较小的C;而有些样本很重要,决不能分类错误(比如中央下达的文件啥的,笑),就给一个很大的C。
当然实际使用的时候并没有这么极端,但一种很常用的变形可以用来解决分类问题中样本的“偏斜”问题。
先来说说样本的偏斜问题,也叫数据集偏斜(unbalanced),它指的是参与分类的两个类别(也可以指多个类别)样本数量差异很大。比如说正类有10,000个样本,而负类只给了100个,这会引起的问题显而易见,可以看看下面的图:
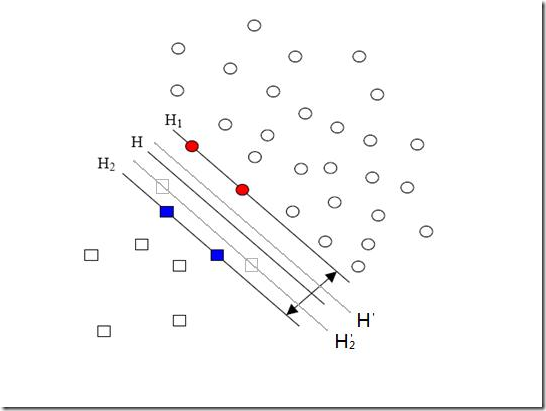
方形的点是负类。H,H1,H2是根据给的样本算出来的分类面,由于负类的样本很少很少,所以有一些本来是负类的样本点没有提供,比如图中两个灰色的方形点,如果这两个点有提供的话,那算出来的分类面应该是H’,H2’和H1,他们显然和之前的结果有出入,实际上负类给的样本点越多,就越容易出现在灰色点附近的点,我们算出的结果也就越接近于真实的分类面。但现在由于偏斜的现象存在,使得数量多的正类可以把分类面向负类的方向“推”,因而影响了结果的准确性。
对付数据集偏斜问题的方法之一就是在惩罚因子上作文章,想必大家也猜到了,那就是给样本数量少的负类更大的惩罚因子,表示我们重视这部分样本(本来数量就少,再抛弃一些,那人家负类还活不活了),因此我们的目标函数中因松弛变量而损失的部分就变成了:
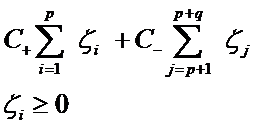
其中i=1…p都是正样本,j=p+1…p+q都是负样本。libSVM这个算法包在解决偏斜问题的时候用的就是这种方法。
那C+和C-怎么确定呢?它们的大小是试出来的(参数调优),但是他们的比例可以有些方法来确定。咱们先假定说C+是5这么大,那确定C-的一个很直观的方法就是使用两类样本数的比来算,对应到刚才举的例子,C-就可以定为500这么大(因为10,000:100=100:1嘛)。
但是这样并不够好,回看刚才的图,你会发现正类之所以可以“欺负”负类,其实并不是因为负类样本少,真实的原因是负类的样本分布的不够广(没扩充到负类本应该有的区域)。说一个具体点的例子,现在想给政治类和体育类的文章做分类,政治类文章很多,而体育类只提供了几篇关于篮球的文章,这时分类会明显偏向于政治类,如果要给体育类文章增加样本,但增加的样本仍然全都是关于篮球的(也就是说,没有足球,排球,赛车,游泳等等),那结果会怎样呢?虽然体育类文章在数量上可以达到与政治类一样多,但过于集中了,结果仍会偏向于政治类!所以给C+和C-确定比例更好的方法应该是衡量他们分布的程度。比如可以算算他们在空间中占据了多大的体积,例如给负类找一个超球——就是高维空间里的球啦——它可以包含所有负类的样本,再给正类找一个,比比两个球的半径,就可以大致确定分布的情况。显然半径大的分布就比较广,就给小一点的惩罚因子。
但是这样还不够好,因为有的类别样本确实很集中,这不是提供的样本数量多少的问题,这是类别本身的特征(就是某些话题涉及的面很窄,例如计算机类的文章就明显不如文化类的文章那么“天马行空”),这个时候即便超球的半径差异很大,也不应该赋予两个类别不同的惩罚因子。
看到这里读者一定疯了,因为说来说去,这岂不成了一个解决不了的问题?然而事实如此,完全的方法是没有的,根据需要,选择实现简单又合用的就好(例如libSVM就直接使用样本数量的比)。
Relation Extraction中SVM分类样例unbalance data问题解决 -松弛变量与惩罚因子的更多相关文章
- SQL SEVER 2008中的演示样例数据库
SQL SEVER 2008数据库是什么我就不说了,我在这里分享一下怎样学习SQL SEVER 2008数据库,假设是对数据库或是SQL SEVER 数据库全然陌生或是不熟悉的人来说,建议看看一些视频 ...
- SVM学习(续)核函数 & 松弛变量和惩罚因子
SVM的文章可以看:http://www.cnblogs.com/charlesblc/p/6193867.html 有写的最好的文章来自:http://www.blogjava.net/zhenan ...
- Funambol Developer's Guide 中 connector development样例的问题
今天学习Funambol的connector开发,官方文档中的样例有问题. 首先,文档中提供的maven命令不可用: mvn archetype:generate -DarchetypeGroupId ...
- SVM学习(五):松弛变量与惩罚因子
https://blog.csdn.net/qll125596718/article/details/6910921 1.松弛变量 现在我们已经把一个本来线性不可分的文本分类问题,通过映射到高维空间而 ...
- Ext3.0中复杂表头样例
注意要点:不出现滚动栏时要设置height和forceFit : false 效果例如以下图: this.columns = [{ header : '月份', dataIndex : '月份', w ...
- JDBC连接MySQL数据库及演示样例
JDBC是Sun公司制定的一个能够用Java语言连接数据库的技术. 一.JDBC基础知识 JDBC(Java Data Base Connectivity,java数据库连接)是一种用 ...
- Hadoop0.20.2 Bloom filter应用演示样例
1. 简单介绍 參见<Hadoop in Action>P102 以及 <Hadoop实战(第2版)>(陆嘉恒)P69 2. 案例 网上大部分的说明不过依照<Hadoop ...
- Cocos2d-x 3.2 Lua演示样例 AssetsManagerTest(资源管理器)
Cocos2d-x 3.2 Lua演示样例 AssetsManagerTest(资源管理器) 本篇博客介绍Cocos2d-x 为我们提供的一个类--AssetsManager在Lua中的使用样例,效果 ...
- zookeeper实战:SingleWorker代码样例
我们需要一个“单点worker”系统,此系统来确保系统中定时任务在分布式环境中,任意时刻只有一个实例处于活跃:比如,生产环境中,有6台机器支撑一个应用,但是一个应用中有30个定时任务,这些任务有些必须 ...
随机推荐
- HDU 5961 传递 随机化
传递 题目连接: http://acm.hdu.edu.cn/showproblem.php?pid=5961 Description 我们称一个有向图G是传递的,当且仅当对任意三个不同的顶点a,,若 ...
- Listener(2)—案例
ServletContext的事件监听器,创建:当前web应用被加载(或重新加载)到服务器中,销毁:当前web应用被卸载 import javax.servlet.ServletContextEven ...
- Vmware下mint os的安装
在vmware 11中,mint倒是很好安装.直接读取iso文件,会自动进入一个类似WindowsPE的安装系统,直接双击开始安装就好,比较傻瓜化. 但是安装好了,字体太小,看着很不舒服,于是就倒腾V ...
- html的文字样式、下行线、删除线、上标、下标等实现方式
先看效果如下: 代码如下: <del>del标签删除线</del><br/> <strike>strike标签删除线</strike>< ...
- wget整站抓取、网站抓取功能;下载整个网站;下载网站到本地
wget -r -p -np -k -E http://www.xxx.com 抓取整站 wget -l 1 -p -np -k http://www.xxx.com 抓取第一级 - ...
- Gitbook 简介 使用总结 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- Python 读取 支付宝账单并存储到 Access 中
我有一个很多年前自己写的C#+Access的记账程序,用了很多年,现在花钱的机会多了,并且大部分走的支付宝,于是就想把账单从支付宝网站上下载下来,直接写入到Access,这样就很省心了. 记账程序是长 ...
- 解决Everything1.4版本预览时不支持自定义后缀的问题
2017年6月Everything版本升级到了1.4.x 个人使用下来认为最主要的有以下几点 添加预览功能 搜索结果多选 点击目录列即打开文件所在目录(需要设置:常规->结果->双击路径列 ...
- ionic生成全尺寸icon和splash
http://www.jianshu.com/p/eda363eb28d3 重新添加platform --no-resources可以禁止重新生成icon和splash ionic cordova p ...
- Swoole PHP windows composer
直接下载了 Swoole PHP 的 Windows 版安装包来用,遇到需要 Composer. 先是下载了 composer.phar.在这里下的 https://getcomposer.org/d ...