皮质学习 HTM 知多少
目录
Hierarchical Temporal Memeory 0.1
—— Pegasus 2017 06 22
引言
Hierarchical Temporal Memeory(HTM,层级时间记忆,皮质学习) 是一种全新的机器学习算法,模拟新大脑皮质(neocortex)进行信息处理。 HTM包含新大脑皮质的三个显著特性:
- 记忆系统。数据流通过感观进入大脑皮质,其中的神元细胞通建立突触(snapses)连接,达到学习的目的,并将记忆储存其中。每个神经元都可看成一个‘记忆’系统。
- 记忆主要为时间(time-changing/temporal)模式。数据在新皮质上的输入输出是实时动态的,而且皮质的对输入数据的学习也是基于时间的,并基于此对动态信息进行预判。
- 层级连接。新皮质内的神经元在皮质内是以层级的方式连接的。因为所有的神经元都执行同样的基本记忆操作,故理解一个神经元的工作方式,即可理解整个皮质的工作方式。
历史
下图表示了HTM算法的发展历程,上面是历史的关键事件,注意到迄今为止算法已经进化(evolving)到第三代。目前以最新版(第三版)为基准。

HTM 概览
HTM的层级结构

上图[^6]表现的即为简化在脑皮质结构,也是HTM和大致结构。HTM是层级结构(注意,现阶段,我们一般只考虑一层。就或者说要形成HTM的层级结构,目前还没有好的解决方案,但一层对目前的数据学习已足够)。在每一层中,都有大量单元(cell),多个单元组成单元柱(mini-column),多个单元柱组成区块(region)。下文中,我们在考一层的皮质时,按下面的方式考虑:

按其为二维点阵列(每个点是一个单元,每一列是一个单元柱)。这样既便于理解,又不失一般性。
神经元
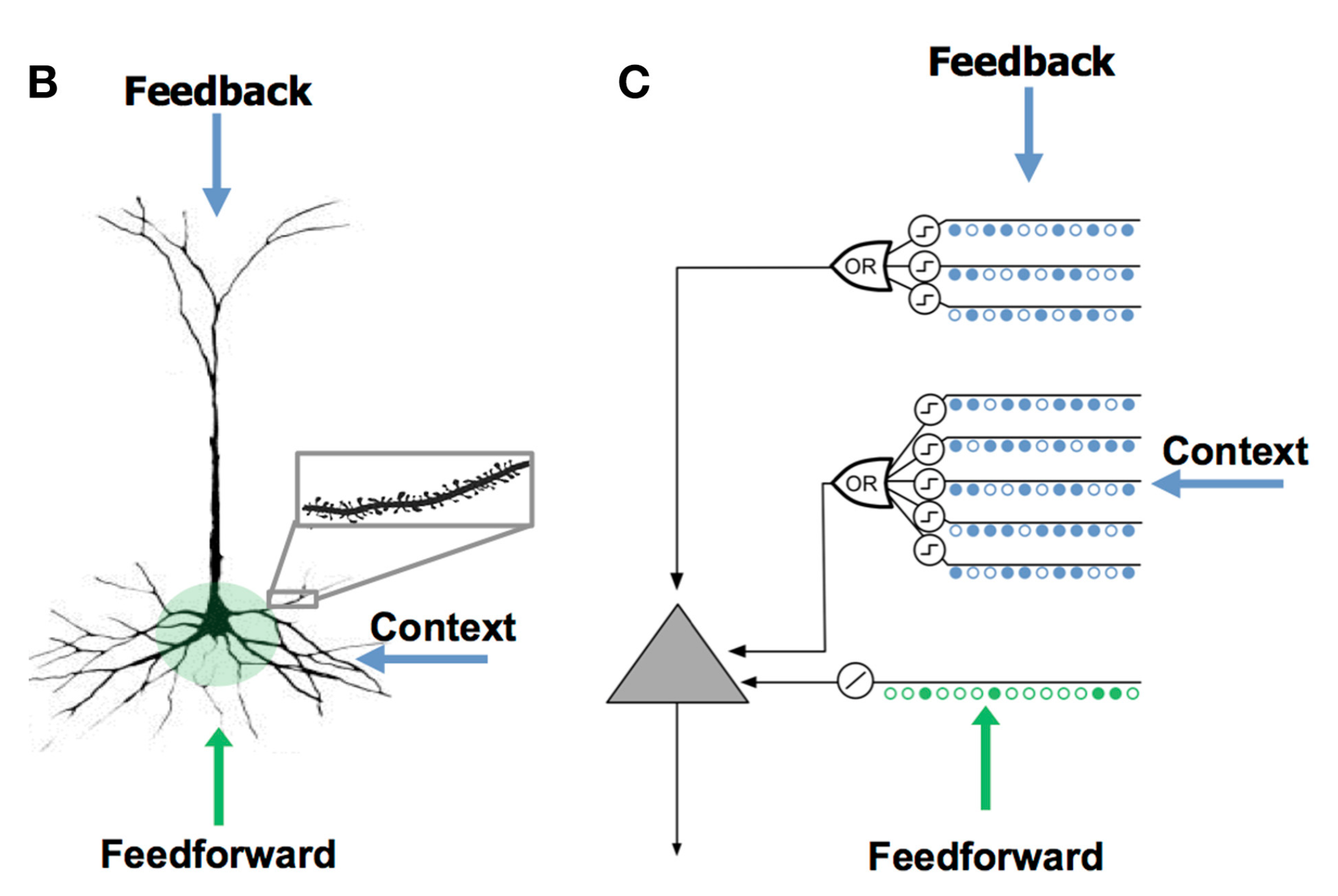
上图中 B 表示的是锥体细胞(pyramidal cell), 是新皮质主要的神经细胞,其有三种树突(dendrite): 近端树突(proximal dendrites),近端树突接受前馈输入信息;末端/基底树突(distal/basal dendrites),基底树突接受情境信息(context),数量比近端树突多很多;顶端树突(apical dendrites),接受反馈信息,其一般接收上一层或几层的信息。图C 则表示HTM中使用的、用以模拟锥体细胞的人工神经元,后文中统一称为单元(cell)。顶端树突接受反馈信息,在现阶段的模型当中,为简化,不予考虑。
HTM 端对端应用框架[^8]

HTM在实际应用过程中,一般会按照上图所示框架进行建模:原始数据进入数据编码器中,编码成二进制向量;然后再经HTM的空间池化(Spatial Pooling,SP)算法生成稀疏分布式代表元(Sparse Distributed Representation, SDR);既而经HTM时间记忆(Temporal Memeory,TM)生成预测向量(也是SDR类型),最后将SDR输到分类器中进行分类预测,或其他函数、算法、模型中,实现所需目的。
接下来,进行分块详述:数据编码(data encoding); 空间池化(spatial pooling)及 实时记忆(temporal memeory)。
数据编码[^1]
HTM模拟新大脑皮质,而大脑皮质接收的数据对其功能有重要影响。神经科学已有很多研究表明感觉器官将接收到的信息转化成稀疏数据。如耳蜗上面的绒毛细胞:
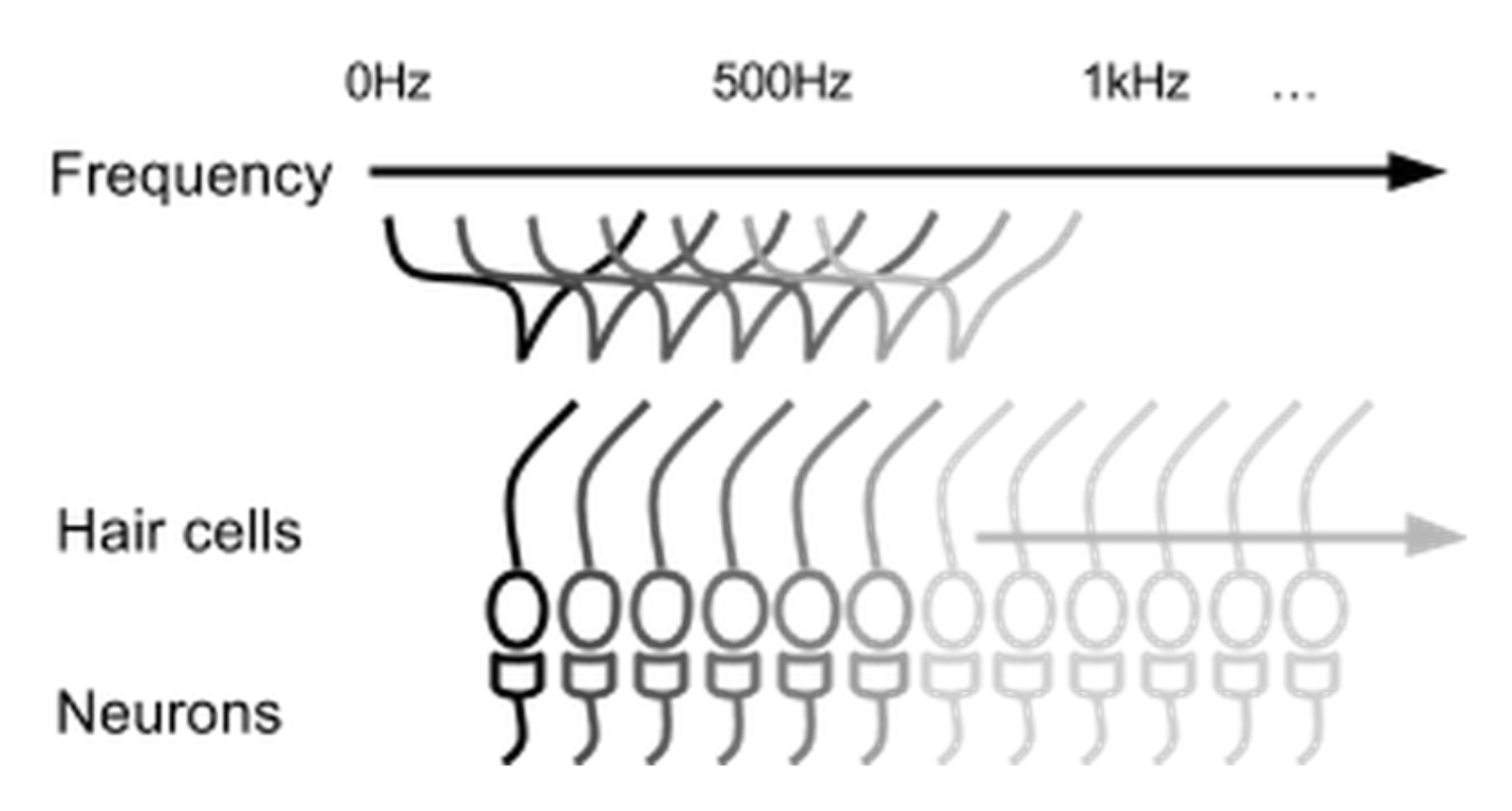
上图中,人可能听到的声音的频率从20 Hz到比如20k Hz,每个绒毛细胞如图能够接受一定范围的声音频率,即当声音频率在某个绒毛细胞可接受的频率范围,则绒毛细胞(或者可以说绒毛细胞下面的神经元,注:这里的神经元不同于新皮质内的神经元细胞)被激活。当声音(比如500 Hz)传到耳蜗时,可接受此频率的绒毛细胞全部被激活。但其数量占绒毛总量的比例也是非常小的。
从中可发现一些性质:数据输入是冗余的,即多个绒毛细胞可接受声音范围有重叠(Overlap),当同一信息输入时,多个绒毛细胞会被激活;信息在整个绒毛细胞列是稀疏的(Sparse)。
数据编码
基于些,数据通过编码器将原始数据转化成新皮质可用数据,需满足:
- 语义相似数据应生成有重叠的激活位点(bits);
- 相同输入总产生固定长度的二进制向量;
- 输出的二进制向量应有相同维度(位点总数);
- 二进制向量应有相似的稀疏度,并且有足够的位点忍受噪音,以及子采样(subsampling)
PS: Overlap(重叠)是二进制微量捕捉语义相似性的关键。
详细的数据编码可参考文献1.其中给出几种常用数据的编码方式,叙述非常清晰明了。因其对HTM理解影响,上面已经讲清,以防喧宾夺主,故点到即止。
数据输入
Sparse distributed representations (SDR) 稀疏分布式代表元, 超大容量(tremendous capacity),极度容忍噪声(extremely tolerant). SDR 对学习和记忆系统特别方便(之前的版本中,原始数据经编码过程产生的Output被命名为SDR,但最新版放弃了这种说法,转而把Spatial Pooling过程产生的output称为SDR;不过encoder产生的output也完全符合SDR性质,为叙述方便,不加区分,统称为SDR,至于代指哪一个过程,根据上下文过程可很容易区分)。输入到单元(cell)内的数据来自三种区域[^1]:
- 近端树突(proximal dendrites/zone):授受前馈输入,即接受原始数据经encoder产生的SDR, 定义最优感受野(classic receptive field), 通常,同一个细胞列(柱)内分享同一近端树突;
- 远端树突(distal dendrites/basal zone):接受背景环境输入,即接受同一区域(region)的SDR,也就是与同一层内的其它单元产生连接突触(注region一词指代不清,也因目前的算法发展层面,接下来假设每一层都只有一个区域,这种简化只是方便叙述,对理解,及对模型几乎没有影响。),学习序列转换,即学习数据的时间结构;
- 顶端树突(apical dendrites/ apical zone):接受反馈输入,唤起自上而下的‘序列’期望(注:当前版本还没有加入顶端树突,故接下来模型中没有考虑反馈输入)。
树突建模[^5,10]
数据编码成上述模式,还有一个很重要的原因,即在接下来的算法过程中,最主要用到的运算为Overlap 及Union.这两个算法都是二进制运算,最多可算是非常简单的矩阵运算,很大程度上减小运算的时空耗费。而接下来的运算区域或运算过程都是在树突上进行。
Overlap: 用以衡量两个SDR相似性:
\[
overlap(\boldsymbol{x,y}) = \boldsymbol{x\bullet y}
\]
其中x,y 为两SDR向量,”\(\bullet\)“表示向量点乘,此过程可简单理解为对‘1’进行计数。如果overlap 值超过一定阈值,比如\(\theta\),就称两个SDR匹配(下面的x,y均为向量):
\[
match(x,y) \equiv overlap(x,y) \ge \theta
\]
Union: 赋予HTM在一个固定长度代表元上存储大量模式的能力。这个能力使得HTM可以实时预测(在TM阶段):
\[
Union(x_1,x_2,\dots ) = \oplus(x_1,x_2,\dots)
\]其中"\(\oplus\)''表示逐元素相加\(x_i\) 表示SDR向量。
空间池化算法
Spatial Pooler (SP)[^2]:
SP对前馈连接进行建模,负责将二进制输入数据转化成SDR。SP即是对数据的空间(spatial)信息进行提取。
SP须满足的属性:
- fixed sparseness 固定稀疏性,即编码器出来的数据;
- Distributed coding 分布式编码;
- Preserving semantic similarity 保留语义相似性;
- Noise robustness/ fault tolerance 噪声、错误的容忍;
- Continuous learning 连续学习;
- Stability 稳定性;
前几个属性,因产生的是SDR即可满足,而后面的诸如连续学习,稳定性则是通过学习(突触连接控制得到的)。
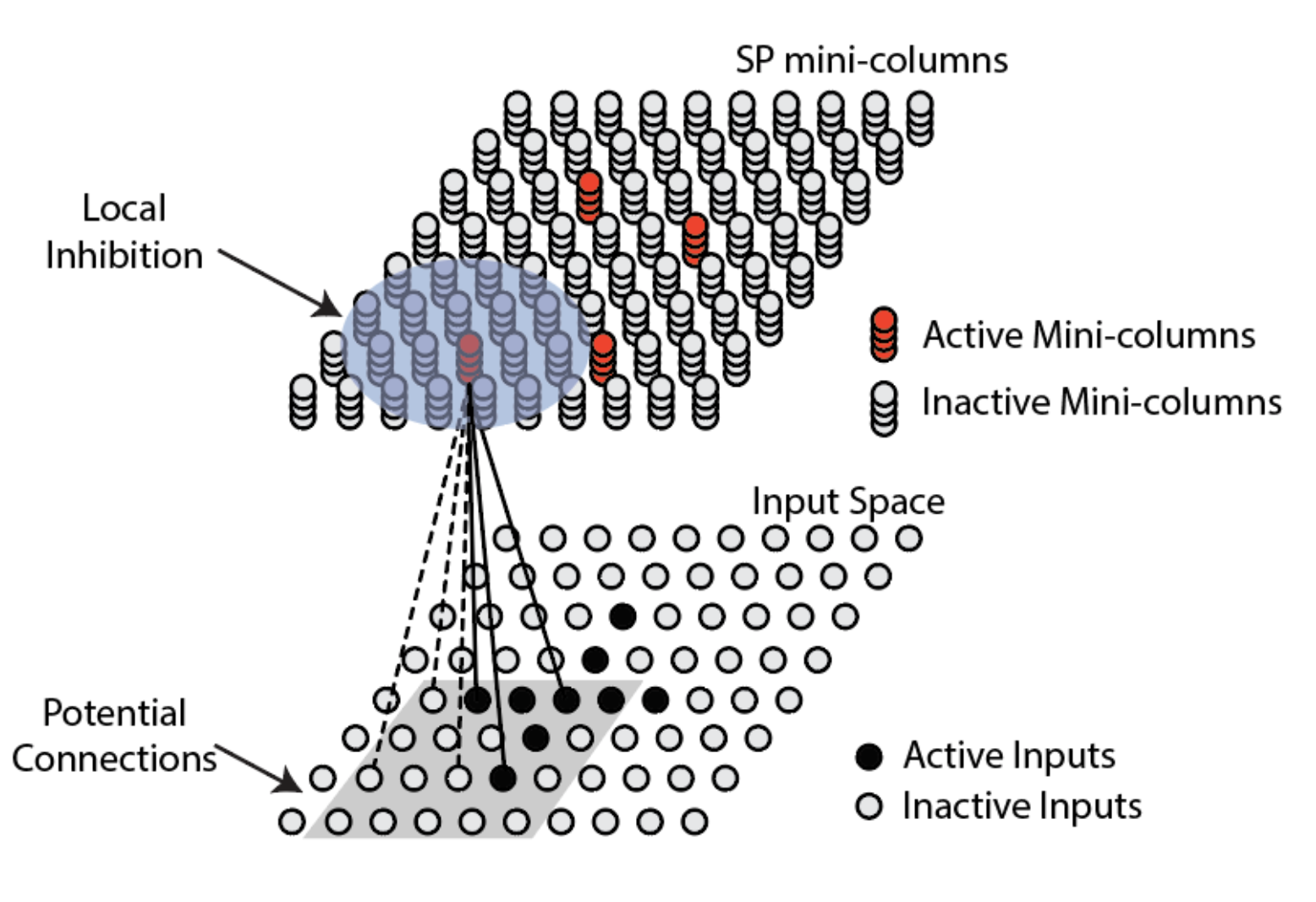
标准感受野
SP模型的第一步是确定标准感受野(Classic Receptive Field)(上图中的灰色方框),即每个单元柱(mini-column)读取输入数据的区域,也就是说每个单元柱只读取输入数据的一部分,而且相邻单元柱的标准感受野是有重叠的(overlap)。标准感受野确定之后,则要确定其中的潜在突触连接(potential connection)。所谓潜在连接即为单元柱可以形成与数据形成连接突触:
\[
PotentialInput(i) = \{j |I(x_j,x_i^c,\gamma)\ and \ Z_{ij} <p\}
\]
\(x_j\) 表示第 j 个输入数据(神经元)的位置,$ x_i^c$ 表示标准感受野的中心输入神经元的位置。\(\gamma\)表示局部感受野的边长(矩形); \(Z_{ij} \sim U(0,1)\) ,即服从均匀分布的一个随机数; p 表示成为潜在连接的阈值,只有小于此阈值,才能成为潜在连接,即形成连接突触(此处暗示,标准感受野内的数据并是都会被SP读取,但目前从算法的代码上看,p值被设成1,即标准感受野内的数据都会成为潜在连接,故此处可以先不用考虑p值问题,下面提到的标准感受与潜在连接等同)。潜在连接成为突触连接,须突触的持久度(permanence) 不小于突触稳定阈值。持久度是形成突触连接的调节参数,是SP需要学习的参数,非常关键。初始化是随机为每个连接突触分配一个持久度。然后根据持久度域值,形成突触连接一个二进制矩阵\(W\)(维度与标准感受野相同):
\[
W_{ij} = \left\{
\begin{array}
\\
1, if \ D_{ij} \ge \theta_c\\
0, otherwise
\end{array}
\right.
\]
其中,\(D_{ij}\) 为第 j 个输入神经元到第 i 个 SP单元柱的持久度,大小介于0,1之间。用均匀分布U(0,1)初始化:
$$
D_{ij} = \left{
\begin{array}
\
U(0,1), &\quad &j \in PotentialInput(i)\
0,&\quad& otherwise
\end{array}
\right.
$$
\(\theta_c\) 为持久阈值(例如:0.5).
已知一个输入向量 Z(即标准感受野内的数据),
则输入向量在第 i 个单元柱上的重合度(overlap):
\[
o_i = b_i \sum_{j} W_{ij} z_j = b_i W_i Z
\]
其中 \(b_i\) 为第 i 个单元柱的提升值(boost)(>0),其控制单元柱的激活性,是要学习的关键参数。
局部抑制
SP还对局部抑制(local inhibition)机制进行建模,也称'赢家通吃'原则,即,在第 i 个单元柱及其 n 个相邻单元柱中,如果第 i 个单元柱排在前k( k<n)个单元列中才会被激活。不过单元列的前馈输入的重合度(overlap) 还要不小于激活阈值(\(\theta_{stim}\))。用\(a_i\)表示第 i 个单元列的激活状态,则:
\[
a_i = \left\{
\begin{array}\\
1, \quad o_i \ge prctile(NeighborOverlap(i), 1 - s) \quad and\quad o_i \ge \theta_{stim};\\
0, \quad otherwise.
\end{array}
\right.
\]
其中,s 是目标激活密度,即总比例的前百分之几的单元柱被激活;\(prctile(x,p)\) 是分位函数, 而\(NeighboringOverlap(i)\) 是第 i 个单元柱及其周围相邻单元柱的重合度集合:
\[
NeighboringOverlap(i) = \{o_j| j \in Neighbor(i)\}
\]
其中\(Neighbor(i)\)是相邻单元柱的集合:
\[
Neighbor(i) = \{j | \left\| y_i - y_j\right\| <\phi, j \ne i\}
\]
其中$y_i \(表示第 i 个单元柱的位置,则\)\left|y_i - y_j \right|$表示 单元柱i,j位置的(欧式)距离。参数 \(\phi\) 表示抑制半径, 其由所有单元柱突触连接的平均值与每个输入神经元的单元柱数量乘积所得到。
参数更新
持久度:
前馈连接遵从赫布规则(hebbian rule): 对于每一个激活的单元柱的所有潜在连接,加强激活的突触连接,即增大其持久度(+p); 惩罚未激活的突触连接,即减小其持久度(-p),但不能超过1,或小于0。如果超过1就按1处理,小于0 当0处理,即遵从截尾效应。
提升值:
通过比较每一个单元柱与其相邻单元柱的近期活性(recent activity),
第 i 个单元柱在 t 时刻的活性表示为\(a_i(t)\),定义第 i 个单元柱的近期活性表示为:
\[
\bar{a}_i(t) =\frac{ (T - 1) *\bar{a}_i(t-1) + a_i(t)}{T}
\]
参数 T 控制提升值的更新速度(趋势惯性)。
相邻单元柱的近期活性定义为:
\[
<\bar{a}_i(t)> = \frac{1}{|Neighbor(i)|} \sum_{j \in Neighbor(i)} \bar{a}_j(t)
\]
更新提升值\(b_i\):
\[
b_i = exp(-\beta(\bar{a}_i(t) - <\bar{a}_i(t)>))
\]
局部抑制半径\(\phi\):
所有单元柱突触连接的平均值与每个输入神经元的连接单元柱数量乘积。
SP总结
经SP过程,产生真正意义上的SDR。SP过程,有多个步骤使数据稀疏化(当然这些步骤是在完成提取必要信息的过程中完成的稀疏化):第一个是 潜在连接的产生过程(当然目前,算法的p值设为1,没有实际意义,但不应该忽略其作用);第二个是根据持久度形成的突触连接;第三个是竞争性局部抑制。
SP后,产生的SDR维度与这一层的维度一致(即在目前算法中,为一个M维向量,这里的M为本层内单元柱的个数)。
SP激活的最小单位是单元柱,这也是前面强调的,同一单元柱内的单元共享近端树突的数据输入。其中提取的是数据 的空间特征。
Temporal Memory(TM):时实记忆[^1]
TM 算法是HTM最核心的算法,正因为TM, HTM才具备的学习及预测能力。当SDR输入到TM中, 学习SDR中所代表的数据及其背景环境(context)。学习:通过增加或者减少潜在突触连接而达到学习目的。预测:根据SDR预测。基于过去与当前对未来进行预测。
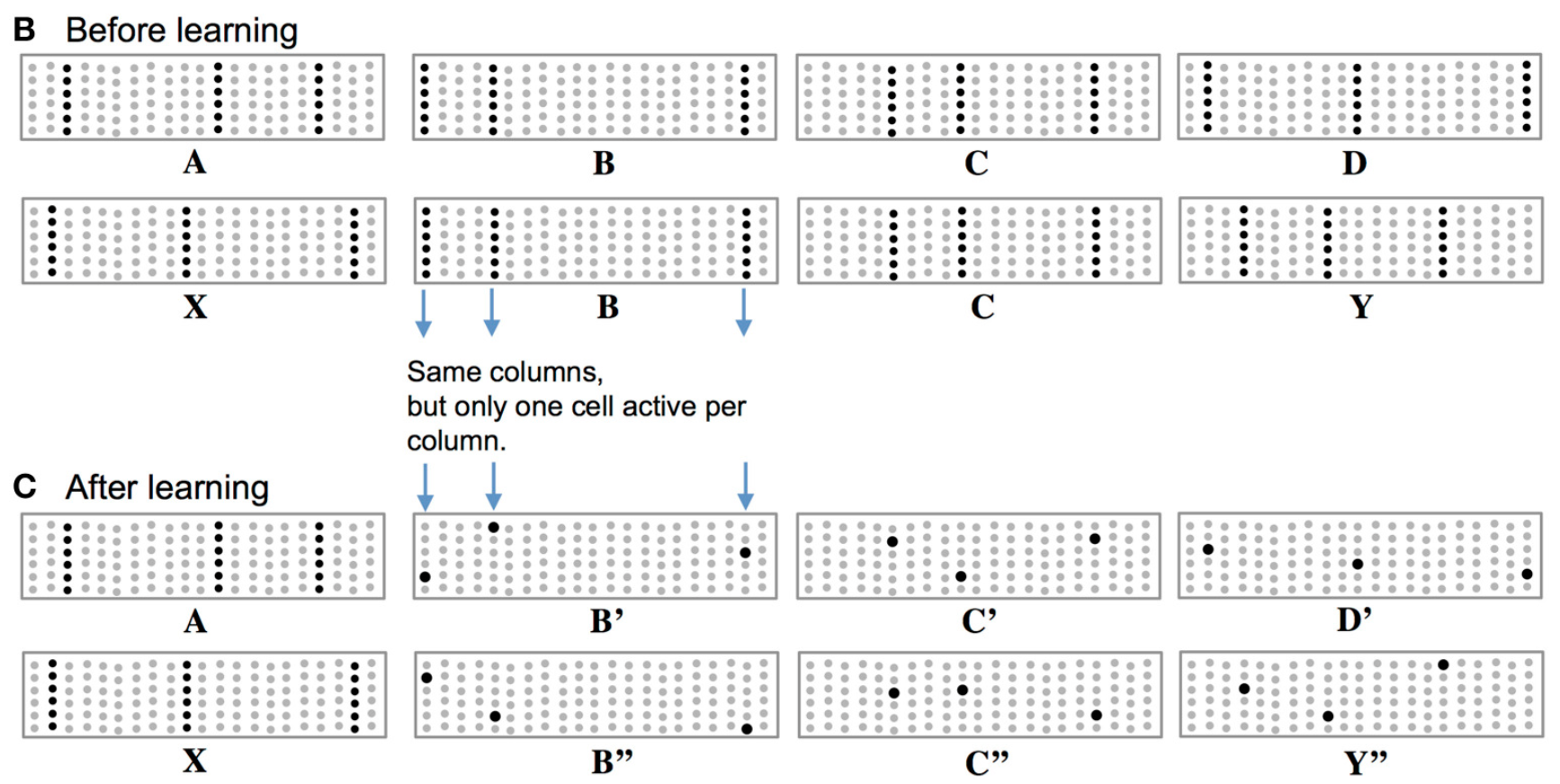
上图中可视为TM的一个学习过程。在SP阶段,数据输出SDR,其中提取的只能显示出空间特性,而时间特征,则需要在TM阶段过程提取,而提取过程中数据的学习,则是通过学习数据模式(pattern)的方式,而模式的表示则需要‘精确’到单元柱中的单元。上图B中,序列‘BC'分别在序列’ABCD‘与‘XABY’中出现,经SP过程两序列中‘BC'的表却是相同的(见上图B中 B,C表示)。为既能体现BC是相同的,又要体现两序列中’BC'处在不同的情境(context)中,HTM采用的做法是在同一单元柱内用不同的单元表示(如上图C中B'C'与B''C'')。
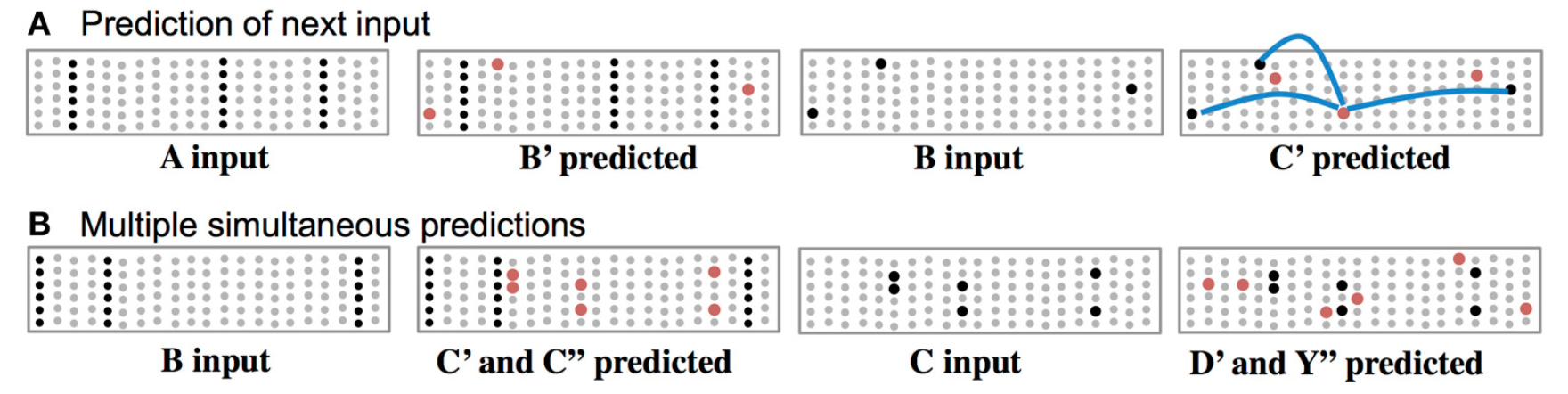
学习过程紧跟着预测过程。上图A中‘A’输入后,TM预测出‘B’(图中红点)出如果B成功预测,则接下来会预测’C‘。上图B中,当输入‘B’时,会预测'C',但由于此时‘C’不唯一,TM会两种情况都给出(’C'‘,’C'‘ ’),输入‘C'同理会给出’D'‘,’Y'‘ ’两种预测。

在TM阶段,用到的树突是基底树突,即上图标有‘Context'处。基底树突相较于前馈输入的近端树突,其数会很大,一个单元中蕴含多个基底树突。基底树突是HTM的记忆系统,这里储存着大量的HTM学习到的数据模工,这些模式是预测的基础。每个树突都含有一个M~X~N的模式矩阵,且是稀疏的,大量的模式包含在这个矩阵中(以Union ('OR')的形式储存)。
基本参数:
N: 单元柱数量;
M:每个单元柱所含单元数;
D: 每个单元所含基底树突数;
S:每个基底突触所突触数
\(A^t\): t时刻激活状态矩阵,其中\(a_{ij}^t\)表示在t时刻,第 j 个单元柱上第 i 个单元的状态;
\(\Pi^t\):t时刻单元预测状态矩阵, 其中 \(\pi_{ij}^t\) 表示在t时刻,第 j 个单元柱上第 i 个单元的预测状态;
\(D_{ij}\):单元基底树突集,其中\(D_{ij}^d\)表示\(a_{ij}^t\)第 j 个单元柱上第 i 个单元的第 d 个基底树突,为一稀疏矩阵(M~X~N),其中非0元素代表,潜在突触的持久度;
\(\dot{D}_{ij}^d\): M~X~N的0,1矩阵,其中元素1所处位置表示处此处的\(D_{ij}\)的持久度为非0(>0);
\(\tilde{D}_{ij}^d\): M~X~N 的0,1矩阵,其中元素1所处位置表示此处形成突触连接;
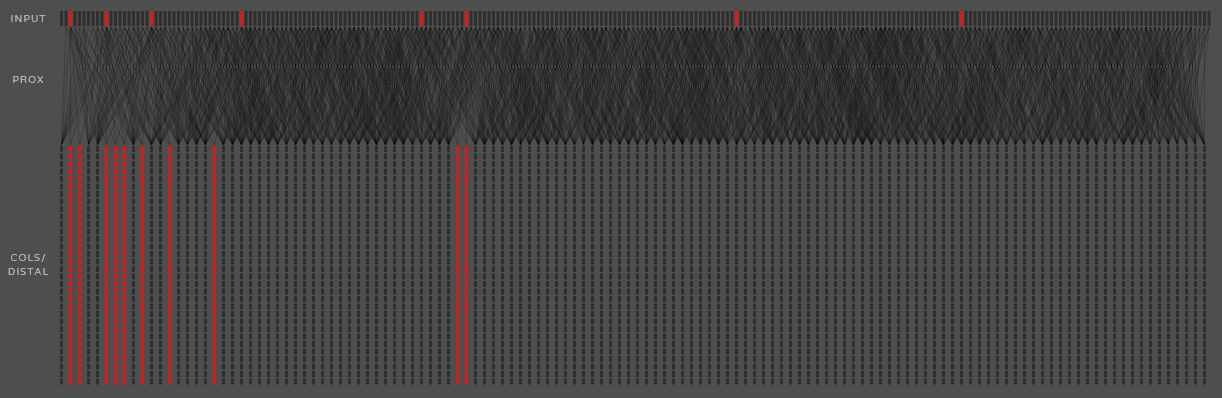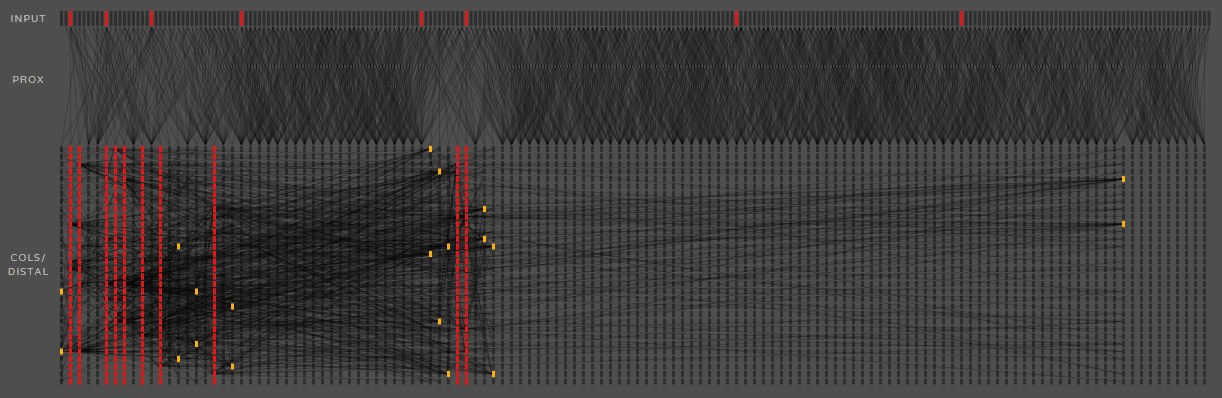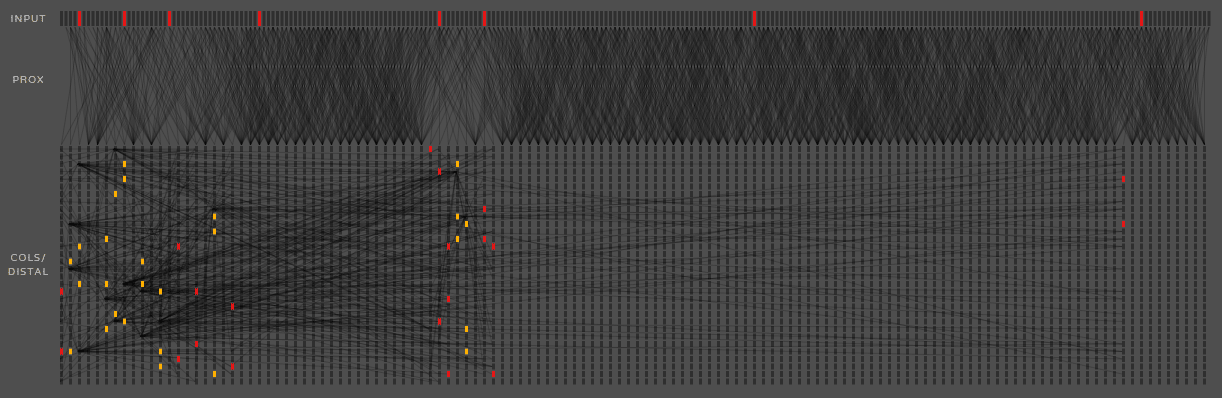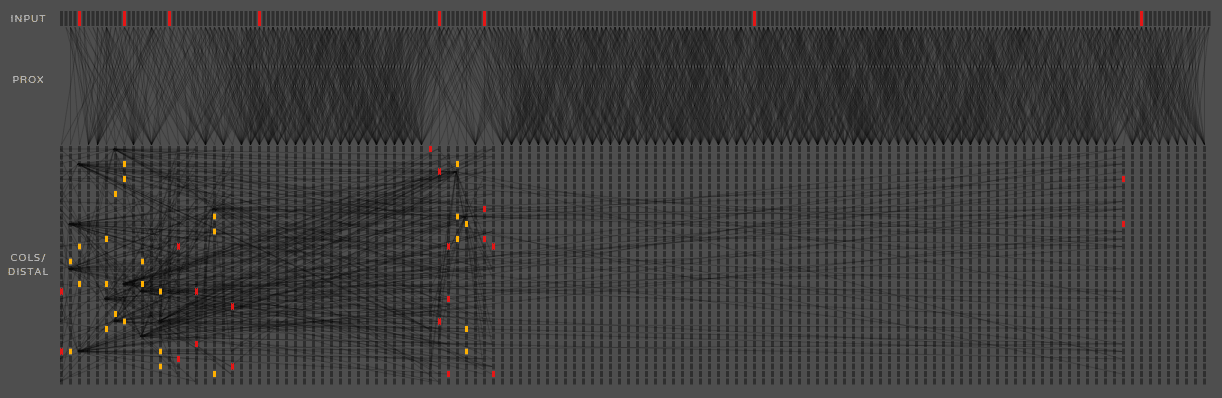
上图是TM的动态演示,动得太快有点乱,这里就不作过多关注,只需对其中连接有个直观认识即可。
初始化:
随机选取一组单元,并为这些单元的基底树突分配随机分配持久度,同SP阶段一样,持久度是调节突触连接的关键,是需要学习的参数,也正因为持久度的变化,才能使得HTM具备了学习的能力。这里的树突不是层与层间的树突,而是同一层内,一个单元与其他所有单元的连接突触。
计算单元状态:
局部抑制过程作用之后(SP过程之后),一组激活的单元柱(\(W^t\))产生,现在来计算单元柱中每个单元的状态,则:
\[
a_{ij}^t = \left\{
\begin{array}
\\
1, \quad j\in W^t , \pi_{ij}^{t-1} = 1;\\
1,\quad j \in W^t,\sum_{i} \pi_{ij}^{t-1} = 0;\\
0,\quad otherwise.
\end{array}
\right.
\]
上式表示,当单元处于激活单元柱中,并且处在预测状态(predictive state)(即在t-1时刻被预测为t时刻要被激活),则此单元即被激活;或者单元处在激活单元柱中,但所在单元柱中所有单元均不处于预测状态,则被激活(这句话说明,如果所处激活单元柱中所单元都不处于激活状态,则单元柱上的所有单元均被激活)。
而单元的预测状态:
\[
\pi_{ij}^t = \left\{
\begin{array}
\\
1, \quad \exists_d \left \| \tilde{D}_{ij}^d \circ A^t \right\|_1 > \theta;\\
0,\quad otherwise.
\end{array}
\right.
\]
其中\(\theta\) 表示预测状态激活阈值,‘\(\circ\)’ 表示逐元素相乘。即当某一单元的任意基底树突与状态矩阵的突触连接数大于预测状态阈值,单元则处于激活状态。
更新树突及突触:
更新树突选择
TM的学习及预测的物理基础即为树突的长衰,而树突的长衰则是通过树突的持久度来调节。那第一步即是选择要更新的树突。设要更新的树突集合为\(D_u\),则:
\[
D_{u1} :\left\{D_{ij}^d \ \Big|\ \ \forall_{j\in W^t}\left( \pi_{ij}^{t-1} > 0\right) and \left\| \tilde{D}_{ij}^d \circ A^{t-1}\right\| >\theta\right\}
\]
\(D_{u1}\)表示那些成功预测的单元基底树突。
如果激活的单元柱为非预测的,需要选择其中一个单元(选择基底树突包含持久度最大的那个单元)表示数据及其情境,为未来预测作准备:
\[
D_{u2} :\left\{D_{ij}^d \ \Big|\ \ \forall_{j\in W^t}\left( \sum_{i}\pi_{ij}^{t-1} = 0\right) and \left\| \dot{D}_{ij}^d \circ A^{t-1}\right\| = \max_{i}\left(\left\|\dot{D}_{ij}^d \circ A^{t-1}\right\|_1\right)\right\}
\]
则需要更新的树突集合为:
\[
D_u = D_{u1} + D_{u2}
\]
持久度更新
更新的原则遵从赫布规则:奖励激活单元的突触,惩罚非激活单元突触,具体实施,即增加、减小持久度:
\[
D_{ij}^d: =D_{ij}^d + \Delta D_{ij}^d
\]
其中\(\Delta D_{ij}^d\)即为拷久度变化值,其可分为两种情况:一是对于激活单元;另一种是对那些并未激活的单元(即预测失败的单元),给予其微小的衰减,因为
\[
\Delta D_{ij}^d = \left\{
\begin{array}
\\
p^+\left(\dot{D}_{ij}^d\circ A^{t-1}\right) - p^-\dot{D}_{ij}^d,&&\quad a_{ij}^t = 1;\\
p^{--}\dot{D}_{ij}^d,&&\quad a_{ij}^t = 0 \ and \ \left\| \tilde{D}_{ij}^d \circ A^{t-1}\right\| >\theta.
\end{array}
\right.
\]
TM总结
这一过程主要可分为两个过程,即学习及预测。学习的是数据的模式,预测则是根据学习到的数据模式进行预测。
TM最小单位是单元。
输出的数据(或者说预测的数据)是M~X~N的稀疏矩阵。
参考文献
PS:此处列出的是最新版本的相关文献,之前版本的文献则没有囊括。
[1]: Scott Purdy (2016) Encoding Data for HTM Sytems. arXiv. 1602.05925
[2]: Yuwei Cui et al. (2017) The HTM Spatial Pooler — a neocortical algorithm for online sparse distributed coding doi: http://dx.doi.org/10.1101/085035.
[4]: Hawkins J and Ahmad S (2016) Why Neurons Have Thousands ofSynapses, a Theory of SequenceMemory in Neocortex.Front. Neural Circuits 10:23.doi: 10.3389/fncir.2016.00023
[6]: Zyarah, Abdullah M., "Design and Analysis of a Reconfigurable Hierarchical Temporal Memory Architecture"(2015). Thesis. Rochester Institute of Technology. Accessed from
[7]: Hawkins, Jeff, Subutai Ahmad and D. Dubinsky.(2011) "HIERARCHICAL TEMPORAL MEMORY including HTM Cortical Learning Algorithms." Technical report, Numenta, Inc, Palto Alto http://numenta.org/cla-white-paper.htm
[9]: Subutai Ahmad, Scott Purdy (2016) Real-Time Anomaly Detection for Stream Analytics arXiv: 1607.02480v1
[10]: Subutai Ahmad, Jeff Hawkins (2015) Properties of Sparse Distributed Representations and their Application to Hierarchical Temporal Memory.
皮质学习 HTM 知多少的更多相关文章
- Java学习路线-知乎
鼬自来晓 378 人赞同 可以从几方面来看Java:JVM Java JVM:内存结构和相关参数含义 · Issue #24 · pzxwhc/MineKnowContainer · GitHub J ...
- 学习下知然网友写的taskqueue
博主在他的博客里对taskqueue的各种使用情况和使用方法都介绍的很清楚:http://www.cnblogs.com/zhiranok/archive/2013/01/14/task_queue. ...
- 学习PHP中的iconv扩展相关函数
想必 iconv 这个扩展的相关函数大家多少都接触过,做为 PHP 的默认扩展它已经存在了很久,也是我们在操作字符编码时经常会使用的函数.不过除了 iconv() 这个函数外,你还知道它的其它函数吗? ...
- PHP的rar解压读取扩展包学习
作为压缩解压方面的扩展学习,两大王牌压缩格式 rar 和 zip 一直是计算机领域的压缩终结者.rar 格式的压缩包是 Windows 系统中有接近统治地位的存在,今天我们学习的 PHP 扩展就是针对 ...
- 20145208《Java程序设计》第3周学习总结
20145208 <Java程序设计>第3周学习总结 教材学习内容总结 认识对象 类类型 在第三章的学习中,我了解到JAVA可区分为基本类型和类类型两种类型,在上周的学习中我学习了JAVA ...
- Java学习步骤
我们为什么选择Java 大多数人选择Java可能只是因为听说Java前景好.Java比较好找工作.Java语言在TIOBE排行榜上一直位于前三等等之类的原因,但是Java具体好在哪里,心里却是没有什么 ...
- 为你揭秘知乎是如何搞AI的——窥大厂 | 数智方法论第1期
文章发布于公号[数智物语] (ID:decision_engine),关注公号不错过每一篇干货. 数智物语(公众号ID:decision_engine)出品 策划.编写:卷毛雅各布 「我们相信,在垃圾 ...
- 深度学习国外课程资料(Deep Learning for Self-Driving Cars)+(Deep Reinforcement Learning and Control )
MIT(Deep Learning for Self-Driving Cars) CMU(Deep Reinforcement Learning and Control ) 参考网址: 1 Deep ...
- 【Python】【爬虫】如何学习Python爬虫?
如何学习Python爬虫[入门篇]? 路人甲 1 年前 想写这么一篇文章,但是知乎社区爬虫大神很多,光是整理他们的答案就够我这篇文章的内容了.对于我个人来说我更喜欢那种非常实用的教程,这种教程对于想直 ...
随机推荐
- 为什么分布式数据库中不使用uuid作为主键?
分布式数据库当然也有主键的需求,但是为什么不直接使用uuid作为主键呢?作为曾经被这个问题困惑过的人,试着回答一下 1. UUID生成速率低下 Java的UUID依赖于SecureRandom.nex ...
- SpringMVC控制器方法参数传入的ModelMap 和Model类型有啥区别
参考 http://blog.csdn.net/u013067598/article/details/69372309 http://blog.csdn.net/u013686993/article/ ...
- JAVA微信公众号网页开发 —— 接收微信服务器发送的消息
WeixinMessage.java package com.test; import java.io.Serializable; /** * This is an object that conta ...
- rpm 包的安装、卸载、升级、查询、验证
关键字: rpm 强制卸载jdk rpm -e j2sdk1.4.2_04 强制覆盖安装jdk rpm -Uvh j2sdk-1_4_1_02-fcs-linux-i586.rpm --force - ...
- C#设计模式(8)——桥接模式(Bridge Pattern)(转)
一.引言 这里以电视遥控器的一个例子来引出桥接模式解决的问题,首先,我们每个牌子的电视机都有一个遥控器,此时我们能想到的一个设计是——把遥控器做为一个抽象类,抽象类中提供遥控器的所有实现,其他具体电视 ...
- python 爬虫-1
买了本书在自学,我也不知道自己能学到什么地步,反正不用这个找工作,纯属爱好,有可能之后就会放弃 233333333.... 先来一个特别简单点的:将百度搜索主页 扒下来,并保存到一个文件里面 fir ...
- 关于ajax返回数据处理
查看jquery文档,我们知道jquery有很多种Ajax调用方法,下面结合springmvc返回的数据,假设返回的是data ='{"label":"1",& ...
- [转载]lib和dll文件的区别和联系
出处:https://blog.csdn.net/weiaipan1314/article/details/52252478 什么是lib文件,lib和dll的关系如何 (2008-04-18 19: ...
- 移动端picker插件
项目需要,要做移动端网页,比如选择出生日期什么的.可笑weui给的控件,竟然选择后的数据不准确. 于是自己写了一个. 链接: https://pan.baidu.com/s/1qY2SSxQ 密码: ...
- 4A Watermelon
A. Watermelon time limit per test 1 second memory limit per test 64 megabytes input standard input o ...