Scrapy工作原理
1. Scrapy旧版架构图(绿线是数据流向)
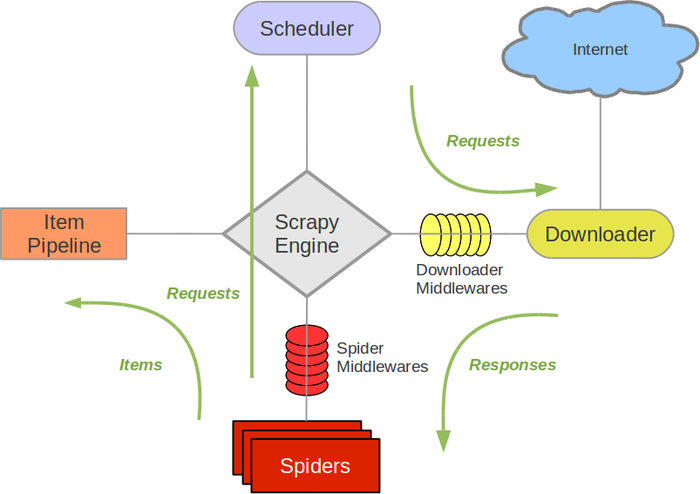
- Spiders(爬虫):负责处理所有Responses,从中分析提取数据,获取Items字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
- Engine(引擎):负责Spider、Item Pipeline、Downloader、Scheduler中间的通讯、信号以及数据传递等。
- Scheduler(调度器):负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列和入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载引擎发送的所有Requests请求,并将其获取到的Responses交还给引擎,由引擎交给Spider来处理。
- Item Pipeline(管道):负责处理Spider中获取到的Items,并进行后期处理(如详细分析、过滤、存储等)。
- Downloader Middlewares(下载中间件):一个可以自定义下载功能的组件。
- Spider Middlewares(Spider中间件):一个可以自定义引擎和Spider交互的组件。
- 通信的功能组件:如进入Spider的Responses和从Spider出去的Requests。
2. Scrapy新版架构图
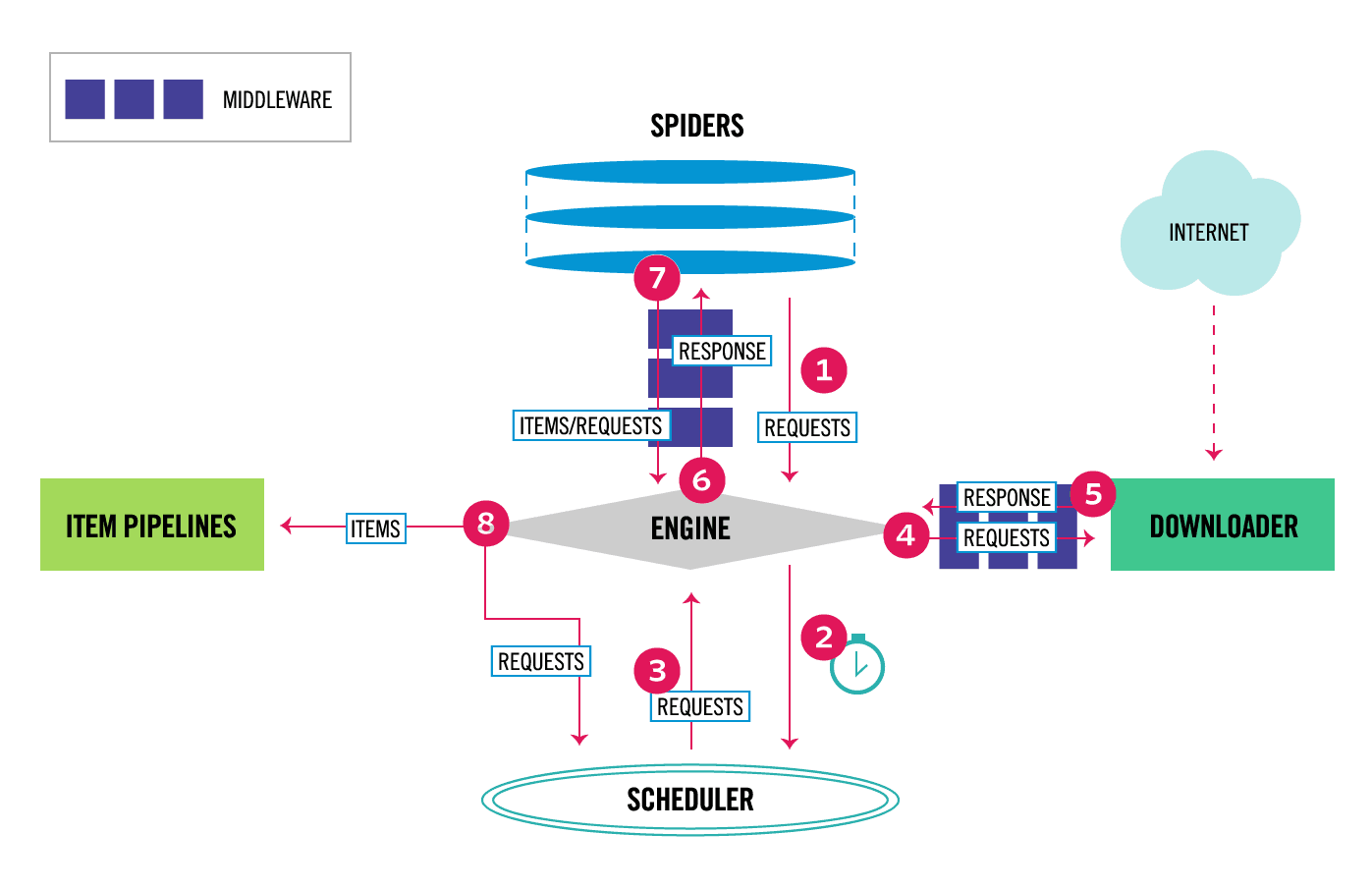
1. 组件介绍
- Scrapy Engine(引擎):引擎负责控制数据流在所有组件中的流动,并在相应动作发生时触发事件。
- Scheduler(调度器):调度器从引擎接受Request并将他们入队,以便之后引擎请求他们时提供给引擎。
- Downloader(下载器):下载器负责获取页面数据并提供给引擎,而后提供给Spiders。
- Spiders(爬虫):Spiders是用户编写用于分析Response并提取items(即获取到的items)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。 更多内容请看 Spiders 。
- Item Pipeline(管道):Item Pipeline负责处理被Spider提取出来的items。典型的处理有清理、 验证及持久化(例如存取到数据库中)。 更多内容查看 Item Pipeline 。
- Downloader Middlewares(下载器中间件):下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的Response(也包括引擎传递给下载器的Request),即处理下载请求。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看Downloader Middleware 。
- Spider middlewares(爬虫中间件):Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理Spider的输入(Response)和输出(Items及Requests),即处理解析。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Spider Middleware 。
2. 数据流(Data Flow)
- 引擎打开一个网站(open a domain),找到处理该网站的Spiders并向该Spiders请求第一个要爬取的URL(s)。
- 引擎从Spiders中获取到第一个要爬取的URL(s)并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL(s)。
- 调度器返回下一个要爬取的URL(s)给引擎,引擎将URL(s)通过下载中间件(请求(Request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(Response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spiders处理。
- Spiders处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spiders返回的)爬取到的Item推送给Item Pipelines,将(Spiders返回的)Request推送给调度器。
- (从第二步)重复直到调度器中没有更多的Request,引擎关闭该网站。
3. 使用Scrapy框架爬虫的重要命令
创建项目:scrapy startproject xxx (项目名)
进入项目:cd xxx
基本爬虫:scrapy genspider xxx(爬虫名) xxx.com (爬取域)
规则爬虫:scrapy genspider -t crawl xxx(爬虫名) xxx.com (爬取域)
运行命令:scrapy crawl xxx(项目名) -o xxx(项目名).json
4. Middlewares主要方法
1. Spider Middlewares: 处理解析Items的相关逻辑修正,比如数据不完整要添加默认,增加其他额外信息等
- process_spider_input(response, spider):当Response通过spider中间件时,该方法被调用,处理该Response。
- process_spider_output(response, result, spider):当Spider处理Response返回result时,该方法被调用。
- process_spider_exception(response, exception, spider):当spider或(其他spider中间件的) process_spider_input()抛出异常时, 该方法被调用。
2. Downloader Middlewares:处理发出去的请求(Request)和返回结果(Response)的一些回调
- process_request(request, spider):当每个request通过下载中间件时,该方法被调用,这里可以修改UA,代理,Refferer
- process_response(request, response, spider): 这里可以看返回是否是200加入重试机制
- process_exception(request, exception, spider):这里可以处理超时
参考:https://blog.csdn.net/baidu_32542573/article/details/79415947
https://blog.csdn.net/qq_37143745/article/details/80996707
Scrapy工作原理的更多相关文章
- scrapy工作原理探秘
def _next_request_from_scheduler(self, spider):#engine从调度器取得下一个request slot = self.slot request = sl ...
- scrapy工作原理概述
当运行scrapy crawl spider 时,会生成一个crawl命令对象,scrapy是调用execute函数(cmdlin.py)来执行命令的,execute函数会给命令对象添加crawler ...
- 一篇文章教会你理解Scrapy网络爬虫框架的工作原理和数据采集过程
今天小编给大家详细的讲解一下Scrapy爬虫框架,希望对大家的学习有帮助. 1.Scrapy爬虫框架 Scrapy是一个使用Python编程语言编写的爬虫框架,任何人都可以根据自己的需求进行修改,并且 ...
- Scrapy 框架结构及工作原理
1.下图为 Scrapy 框架的组成结构,并从数据流的角度揭示 Scrapy 的工作原理 2.首先.简单了解一下 Scrapy 框架中的各个组件 组 件 描 述 类 型 EN ...
- scrapy框架结构与工作原理
组件: ENGINE:引擎,框架的核心,其他组件在其控制下协同工作. SCHEDULER:调度器,负责对SPIDER提交的下载请求进行调度 DOWNLOADER:下载器,负责下载页面,发送HTTP请求 ...
- Python爬虫-Scrapy框架的工作原理
Scrapy框架工作原理 Scrapy框架架构图 Scrapy框架主要由六大组件组成,分别为: 调度器(Scheduler),下载器(Downler),爬虫(Spiders),中间件(Middwa ...
- scrapy学习笔记(二)框架结构工作原理
scrapy结构图: scrapy组件: ENGINE:引擎,框架的核心,其它所有组件在其控制下协同工作. SCHEDULER:调度器,负责对SPIDER提交的下载请求进行调度. DOWNLOADER ...
- Python 爬虫之 Scrapy 分布式原理以及部署
Scrapy分布式原理 关于Scrapy工作流程 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享 ...
- scrapy分布式原理
scrapy分布式原理 关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键 ...
随机推荐
- python线程池(threadpool)模块使用笔记 .python 线程池使用推荐
一.安装与简介 pip install threadpool pool = ThreadPool(poolsize) requests = makeRequests(some_callable, li ...
- 匿名函数gc分析
测试一:使用member function创建action会产生gc,不管该函数是否访问外部变量: private System.Action memberAct = null; // gc 112B ...
- 【Java编码规范】《阿里巴巴Java开发手册(正式版)》【转载】
2017年开春之际,诚意献上重磅大礼:阿里巴巴Java开发手册,首次公开阿里官方Java代码规范标准.这套Java统一规范标准将有助于提高行业编码规范化水平,帮助行业人员提高开发质量和效率.大大降低代 ...
- VMware ESXI添加第三方网卡驱动
VMware ESXI有两种方法添加第三方网卡驱动: 1.使用第三方工具 ESXI-Customizer.cmd工具可以将已经下载好的VMware ESXI.ISO镜像文件把下载好的驱动添加到里面,缺 ...
- javassist实例
我们常用到的动态特性主要是反射,在运行时查找对象属性.方法,修改作用域,通过方法名称调用方法等.在线的应用不会频繁使用反射,因为反射的性能开销较大.其实还有一种和反射一样强大的特性,但是开销却很低,它 ...
- The client and server cannot communicate, because they do not possess a common algorithm
The client and server cannot communicate, because they do not possess a common algorithm This was re ...
- composer lavarel 安装
一:packagist库:https://packagist.org/packages/laravel/laravel 二:composer安装 // 安装到laravel文件夹 composer c ...
- Mock an function to modify partial return value by special arguments on Python
Mock an function to modify partial return value by special arguments on Python python mock一个带参数的方法,修 ...
- 大整数加减运算的C语言实现
目录 大整数加减运算的C语言实现 一. 问题提出 二. 代码实现 三. 效果验证 大整数加减运算的C语言实现 标签: 大整数加减 C 一. 问题提出 培训老师给出一个题目:用C语言实现一个大整数计算器 ...
- zeppelin 一直报这个警告 也是醉了
用./zeppelin-daemon.sh start 启动zeppelin 一直报这个警告.. WARN [2017-03-23 19:11:34,461] ({qtp483422889-45} N ...