机器学习实战1-1 KNN电影分类遇到的问题
为什么电脑排版效果和手机排版效果不一样~
目前只学习了python的基础语法,有些东西理解的不透彻,希望能一边看《机器学习实战》,一边加深对python的理解,所以写的内容很浅显,也许还会有一部分错误,希望得到大家的指正。在看到书上第一个KNN算法,实现简单的电影分类的时候,就遇到了很多问题,在这里把解决方法总结下来,时常翻看,加深理解。最近时间比较充裕,希望每天都能在这里总结输出,逐渐提升自己的能力!这样总有一天,我能尽情的吃牛肉干不心疼钱,嗯!
我用的是python3,《机器学习实战》里面是python2,所以有一些部分语法还是有些不同
跟着书敲的代码,然后自己加入了一部分注释,代码前面的有些注释写的不详细,后面会根据我自己的理解进一步解释
- #准备,用python 导入数据
- #导入numpy 方便矩阵操作
- from numpy import *
- #导入运算符模块
- import operator
- def createDataSet():
- group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])#注意,这里中括号的个数
- labels = ['A','A','B','B']
- return group,labels
- #classify0有四个输入变量,用于分类的输入向量是inX,输入的样本集是dataSet
- #标签向量为labels,k是用于选择最近的邻居数目
- def classify0(inX,dataSet,labels,k):
- dataSetSize = dataSet.shape[0] #表明dataSet有几组数据,根据上文中的group得知,应该有4组数据
- #tile是把输入向量inX扩充成和dataSet一样的行维度,也就是dataSet是几个数据,就把inX扩充成几个数据
- #方便后面向量操作,使inX减去dataSet里的数据,这样就可以不用循环了,直接矩阵运算就可以了
- #计算被测点到dataSet的距离
- diffMat = tile(inX,(dataSetSize,1)) - dataSet
- sqDiffMat = diffMat ** 2
- sqDistances = sqDiffMat.sum(axis = 1) #后面详细解释sqDiffMat.sum(axis = 1)用法
- distances = sqDistances ** 0.5
- #对距离进行排序.numpy中的argsort()是对数组从小到大拍讯,返回值是数值对应的索引值
- sortedDistIndicies = distances.argsort()
- classCount = {}#{}表示生成的是字典,这是一个dict,用于存储不同标签出现的次数
- for i in range(k): #range(k)就是range(0:k)
- '''
- 选取前k个距离最近的点,sortedDistIndicies是已经排序好的,用labels迭代的取前k个距离最近的样本点的标签
- 并计算该标签出现的次数,这里用到了dict.get(key,default=None)函数,key就是voteIlabel,如果不存在,就返回一个0并存入dict
- 如果存在,则读取当前值并+1
- '''
- voteIlabel = labels[sortedDistIndicies[i]]#注意这里也是中括号,不是小括号
- classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 #具体怎么实现的还是不清楚,已经解决了,具体用法在有道云笔记里,这篇文章后面也有解释说明
- '''
- items方法把字典中的key和value组成一个元组,并把这些元组放在列表中返回
- operator.itemgetter(1),按照第二个元素的次序对元组进行排序,这里面第二个元素具体指的就是,标签出现的次数
- False是默认升序排列,True是降序排列
- '''
- sortedClassCount = sorted(classCount.items(),key = operator.itemgetter(1),reverse = True)
- return sortedClassCount[0][0] #返回频率最高的元素标签。这里因为是降序排列,所以第一个([0][0])就是频率最高的那个
1、问题描述: 在python交互开发环境中,输入
import kNN
结果返回是,no module named kNN
这个问题折磨死我了,试过添加路径,试过好多别的方法,都不行,简直要怀疑人生了。
解决方法:https://blog.csdn.net/lingan_hong/article/details/69526154
R&S公司用的电脑一直不行,最后解决方法是:重新安装一遍python3.6,安装目录不是廖雪峰里面的默认目录,原因是,公司电脑的默认目录下,安装在C盘的APPdata里面,这个文件在电脑中是隐藏的,我写的python程序在另外的文件夹里,我想,这可能是找不到KNN这个模块的一个可能原因之一。
再一次重新安装的时候,我要在哪里存放脚本,就安装在哪里。新建文件夹命名为PYTHON,将python安装在PYTHON里,并且全选了所有要下载的东西进行安装,安装时间比较长。安装之后,在cmd安装wheel,先进入安装python3.6的路径,然后执行的命令是,pip install wheel 。在python安装目录下有一个Scrip的文件夹,我把秦大虎发给我和这个版本配套的numpy,matplolit等安装包下载到这里,并且在cmd里进入这个安装目录,在执行命令 “pip install 要安装的文件名”
2、问题描述:第22行,tile(inX,(dataSetSize,1)) 是什么意思
解决方法:tile(A,n)作用是将数组 A 重复 n 次,形成一个新的数组。
例如,A = 1,2,3
4,5,6
也就是说,A 是一个2行3列的矩阵,那么,B = tile [A,3],就是把A整体横着复制3次,所以

C = [A,(2,1)],就是把 A 看成整体,形成2行1列的数组,也就是变成:
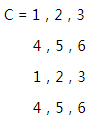
3、问题描述:numpy sum求和中axis问题
这个问题起源于,在使用numpy中的sum语句时,语法是这样的:
假设,a 是一个2维数组,那么为什么 a.sum(axis = 1),是对 a 的行求和,保留列数;a.sum(axis = 0),是对 a 的列求和,保留行数。但是,当a这个数组变化之后,不是2维数组,就不是按照上面规则求和了,有时甚至是甚至相同的语句下,结果是反过来的。这让我比较困惑,这个语句究竟是怎么工作的?究竟什么时候是行相加,什么时候是列相加?为什么 a.sum(axis= 2)会报错?为什么axis不能等于2?
解决方法:
首先理解什么是array的维度
numpy.array的维度问题,我的理解就是能用几个数确定array里面元素的位置,那么就是几维。
图1显示了一个数组 a

图1
其中,如图2所示,第一维(红色部分)有两个(也就是长度length为2),第二维(绿色部分)有2行(长度,length = 2),第三维(粉色部分)有3列(length = 3),所以,shape(a)是(2,2,3)。注意,shape中的数字指的是长度,所以从1开始计数。索引,是指位置,从0开始计数。
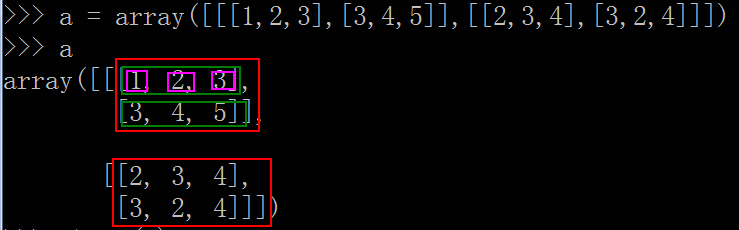
图2
在进一步理解一下,索引一下 a[0,1,2] ,想一想,应该是这个数组中的几?
揭晓一下答案:
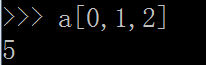
解释:
0:指的是第一维中的第1个红色部分的内容(索引从0开始计数),缩小了索引范围
1:指的是第二维中的第2个绿色部分的内容,进一步缩小索引范围
2:指的是第三维中的第3个粉色部分的内容,确定了我们要索引的数字,他就是5
由此想要知道 5 这个元素在数组中的位置,就至少需要3个数字,所以这个矩阵是一个三维数组(array)
那么axis=0,axis=1,又是什么意思呢?为什么有时axis=2成立,有时axis=2不成立,会报错?
在这里,我理解的 axis = 0 ;axis = 1; axis = 2;分别类比于3维空间里的x轴,y轴,z轴。我猜想,这也是 axis 这个单词翻译成轴的原因。这里的 axis=0 是指第一个维度,axis = 1是指第二个维度,axis = 3 是指第三个维度。那么在 kNN 算法实现的过程中,group长成下面这个样子:

你看,group的数组,是几维?
因为,group里面的元素可以用两个数字来进行精准定位,所以,他是一个2维数组。那么此时,只有 axis = 0 和 axis = 1 这两种情况,自然是不可能有 axis = 2 这种情况的。如果此时运行shape(group),结果应该是 (4,2)。来不信,给你运行一遍看看:

shape(group)结果是(4,2)原因是,axis = 0 (也就是第一维)长度为4,axis = 1(也就是第二维)长度为2。
再举一个栗子:
看到上面数组 a 没有?就是下面这个

也就是说,数组 a 是一个3维数组,那么,此时你来想一想,axis = 0(也就是第一维)长度是几?axis = 1(第二维)长度是几?axis = 2(第三维)长度是几?那么,也就能知道shape(a)的结果是(2,2,3)啦!
所以,我就把 axis = 0,类比想象成 x 轴;把 axis = 1 ,类比想象成 y 轴;把 axis = 2 类比想象成 z 轴。那么,再次申明一下,如果一个数组是二维的,就不可能有 axis = 2 这种情况了。
那么,sum(axis=0)的计算过程是怎样的?
我们先以group.sum(axis = 1) 例,看看,结果是什么?
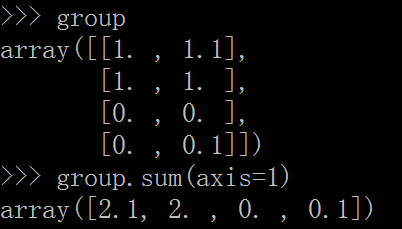
由结果推原因,我们可以得到,这是在把 group 的第一列和第二列相加的结果。
详细的计算过程是:
当 axis = 1 时,就是是把 shape(group)的结果(4,2)中的第二维(列)相加去掉,只剩下行,也就是只剩下 axis = 0 (第一维,行)。按照我们正常的想法应该是剩下一个列向量:
[ 2.1
2
0
0.1]
但是,注意,我们一开始定义group的时候的写法:
group = array([ [1,1.1], [1,1], [0,0], [0,0.1] ])
那么按列相加就是:

因此,在 python shell 环境中显示出来就是行向量的形式:[2.1,2,0,0.1]
summarize:group.sum(axis = 1)计算结果是,把axis = 1 弄消失,只剩下 axis =0 这一维度的长度保持不变。
再看看 group.sum(axis = 0) 结果应该是什么?
把 axis = 0 (第一维也就是行)相加去掉,只留下2列。想一下结果是什么?
结果,应该是 [2, 2.2]。
那么当数组 a 是三维的,a.sum(axis = 0),该怎么计算呢?

计算 a.sum(axis = 0) 就是把第一维相加并去掉,也就是说,把红色部分合并相加,只剩下一个红色的部分,(那我的猜想就是,这里是不是也可以理解为把三维数组降为,变成二维呢?不知道这么相对不对啊)
shape(a)结果是(2,2,3)
那么,去掉 axis = 0 就是去掉shape里的第一维:2。也就是说,最后结果的数组的shape是(2,3),即,最后是两行三列的数组。那么想家的方法,是把下面红色部分的数对应加到上面红色部分的数里,所以结果就是:
[ 3,5,7
6,6,9]
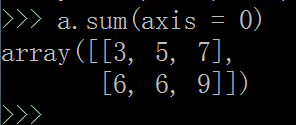
4、问题描述:搞不清楚 classCount.get(voteIlabel,0) 是什么意思
解决方法:

上面写了 dict.get 的用法,小白如我,还不太明白,看了好多博客,终于有了一点头绪。
现在举一个例子,直观的感受一下,如果要取出dict里面的键值,有两种做法。
第一种方法:不用函数,直接取出(如下图)。注意,这种取出的方法是中括号里面加引号,内容是关键字,返回的是value

第二种方法:用get()函数,上面查看get的帮助,可以这样理解,输入的命令格式是
D.get(k[,d])
其中,D是程序中的字典,k是D中的关键字key,中括号里面的内容是默认参数。现在看红色框部分是什么意思。D[k],前面已经知道,它的意思是取出 k 对应的 value。再加上 if k in D,意思就是,如果这个关键字 k 在字典 D 里面,那么就执行D[k],取出 k 对应的 value,如果 k 不在字典 D 里面,返回值就是 d,红框后面告诉我们了,d 的默认值是 None。
绕来绕去的,可能会有一点晕,我们直接看例子,然后再返回头理解上面的话
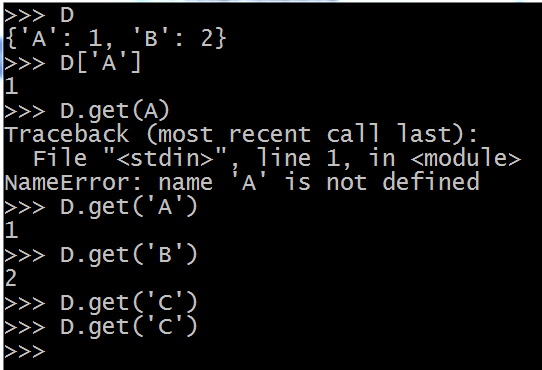
如果 C 不在 D 里,就返回None,在上面的例子中,我们看到,啥也没返回,难道这就是返回None的意思?
之后,我改变了 d 的默认值,让他不是None,是 0,看一下运行结果
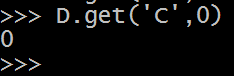
意思是,C 不在 D 里,执行 D.get('C',0),返回值就是 0

总结:python3的语法理解不深刻,体会的不到位,需要不断思考,不断总结。为了可以随心所欲的吃牛肉干,加油!
机器学习实战1-1 KNN电影分类遇到的问题的更多相关文章
- 机器学习实战1-2.1 KNN改进约会网站的配对效果 datingTestSet2.txt 下载方法
今天读<机器学习实战>读到了使用k-临近算法改进约会网站的配对效果,道理我都懂,但是看到代码里面的数据样本集 datingTestSet2.txt 有点懵,这个样本集在哪里,只给了我一个文 ...
- 机器学习实战第二章----KNN
tile的使用方法 tile(A,n)的功能是把A数组重复n次(可以在列方向,也可以在行方向) argsort()函数 argsort()函数返回的是数组中值从大到小的索引值 dict.get()函数 ...
- 机器学习实战---决策树CART简介及分类树实现
https://blog.csdn.net/weixin_43383558/article/details/84303339?utm_medium=distribute.pc_relevant_t0. ...
- 机器学习实战---决策树CART回归树实现
机器学习实战---决策树CART简介及分类树实现 一:对比分类树 CART回归树和CART分类树的建立算法大部分是类似的,所以这里我们只讨论CART回归树和CART分类树的建立算法不同的地方.首先,我 ...
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 机器学习实战笔记(Python实现)-01-K近邻算法(KNN)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 算法代码[置顶] 机器学习实战之KNN算法详解
改章节笔者在深圳喝咖啡的时候突然想到的...之前就有想写几篇关于算法代码的文章,所以回家到以后就奋笔疾书的写出来发表了 前一段时间介绍了Kmeans聚类,而KNN这个算法刚好是聚类以后经常使用的匹配技 ...
- 机器学习实战 之 KNN算法
现在 机器学习 这么火,小编也忍不住想学习一把.注意,小编是零基础哦. 所以,第一步,推荐买一本机器学习的书,我选的是Peter harrigton 的<机器学习实战>.这本书是基于pyt ...
- 基于kNN的手写字体识别——《机器学习实战》笔记
看完一节<机器学习实战>,算是踏入ML的大门了吧!这里就详细讲一下一个demo:使用kNN算法实现手写字体的简单识别 kNN 先简单介绍一下kNN,就是所谓的K-近邻算法: [作用原理]: ...
随机推荐
- Linux命令vi/vim 使用方法讲解
vi/vim 基本使用方法 vi编辑器是所有Unix及Linux系统下标准的编辑器,它的强大不逊色于任何最新的文本编辑器,这里只是简单地介绍一下它的用法和一小部分指令.由于对Unix及Linux系统的 ...
- PAT1111 Online Map【最短路】【dfs】
题目:https://pintia.cn/problem-sets/994805342720868352/problems/994805358663417856 题意: 给定一个图,每天边上有时间和路 ...
- 线段树合并 || 树状数组 || 离散化 || BZOJ 4756: [Usaco2017 Jan]Promotion Counting || Luogu P3605 [USACO17JAN]Promotion Counting晋升者计数
题面:P3605 [USACO17JAN]Promotion Counting晋升者计数 题解:这是一道万能题,树状数组 || 主席树 || 线段树合并 || 莫队套分块 || 线段树 都可以写..记 ...
- 关于mysql中like查询是否通过索引的测试
测试mysql的like语句是否通过索引时得到结果如下: 图片1: 图片2: 图片3: 通过上述3组图片我想大家很容易愤青我使用的'%8888888%','%8888888'和'8888888%'3中 ...
- EFM32G232F64时钟树
1.为了熟悉MCU的时钟树,先看看EFM32G232F64的CMU(ClockManagementUnit) 时钟管理单元(CMU)用于管控晶振(时钟源)和各个时钟节点.出于降低功耗和启动时间的目的, ...
- iptables精通
前提基础: 当主机收到一个数据包后,数据包先在内核空间中处理,若发现目的地址是自身,则传到用户空间中交给对应的应用程序处理,若发现目的不是自身,则会将包丢弃或进行转发. iptables实现防火墙功能 ...
- asp.net机制理解(Javaweb同理)
1.页面运行先后顺序 先执行aspx中的代码,然后再合并到HTML中,最后一起送到浏览器执行,HTML是从上到下执行的,而HTML中的Windows.onload()最后执行.而由于aspx中的代码是 ...
- 6种原型设计工具大比对! Axure,Invision, 墨刀……哪款适合你?
每一年的毕业季都是找工作高峰时期,产品经理.UI设计师这些岗位都会接触到原型设计工具.选择原型设计工具最重要的一点:适合自己的才是最好的! 下文将对目前超火的原型工具进行大对比,快来看看那一款于你而言 ...
- C# 获取 mp3文件信息【包括:文件大小、歌曲长度、歌手、专辑】
C# 获取 mp3文件信息[包括:文件大小.歌曲长度.歌手.专辑] 第一种方式:[代码已验证] // http://bbs.csdn.net/topics/390392612 string fil ...
- 改写pipeline
为什么要改写方法:get_media_requests,他们的区别在哪里 def get_media_requests(self, item, info):#原始的 return [Request(x ...