python爬虫入门---第二篇:获取2019年中国大学排名
我们需要爬取的网站:最好大学网
我们需要爬取的内容即为该网页中的表格部分:
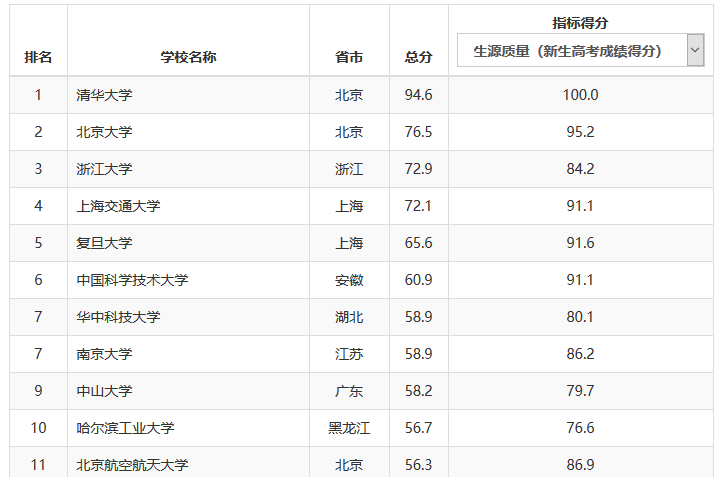
该部分的html关键代码为:
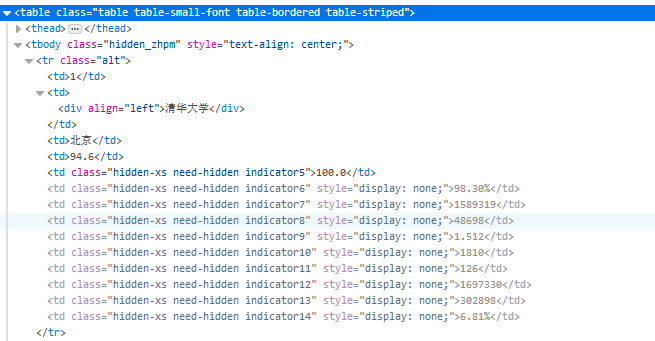
其中整个表的标签为<tbody>标签,每行的标签为<tr>标签,每行中的每个单元格的标签为<td>标签,而我们所需的内容即为每个单元格中的内容。
因此编写程序的大概思路就是先找到整个表格的<tbody>标签,再遍历<tbody>标签下的所有<tr>标签,最后遍历<tr>标签下的所有<td>标签,
我们用二维列表来存储所有的数据,其中二维列表中的每个列表用于存储一行中的每个单元格数据,即<tr>标签下的所有<td>标签中的所有字符串。
代码如下;
import requests
from bs4 import BeautifulSoup
import bs4 def get_html_text(url):
'''返回网页的HTML代码'''
try:
res = requests.get(url, timeout = 6)
res.raise_for_status()
res.encoding = res.apparent_encoding
return res.text
except:
return '' def fill_ulist(ulist, html):
'''将我们所需的数据写入一个列表ulist''' #解析HTML代码,并获得解析后的对象soup
soup = BeautifulSoup(html, 'html.parser')
#遍历得到第一个<tbody>标签
tbody = soup.tbody
#遍历<tbody>标签的孩子,即<tbody>下的所有<tr>标签及字符串
for tr in tbody.children:
#排除字符串
if isinstance(tr, bs4.element.Tag):
#使用find_all()函数找到tr标签中的所有<td>标签
u = tr.find_all('td')
#将<td>标签中的字符串内容写入列表ulist
ulist.append([u[0].string, u[1].string, u[2].string, u[3].string]) def display_urank(ulist):
'''格式化输出大学排名'''
tplt = "{:^5}\t{:{ocp}^12}\t{:{ocp}^5}\t{:^5}"
#方便中文对其显示,使用中文字宽作为站字符,chr(12288)为中文空格符
print(tplt.format("排名", "大学名称", "省市", "总分", ocp = chr(12288)))
for u in ulist:
print(tplt.format(u[0], u[1], u[2], u[3], ocp = chr(12288))) def write_in_file(ulist, file_path):
'''将大学排名写入文件'''
tplt = "{:^5}\t{:{ocp}^12}\t{:{ocp}^5}\t{:^5}\n"
with open(file_path, 'w') as file_object:
file_object.write('软科中国最好大学排名2019版:\n\n')
file_object.write(tplt.format("排名", "大学名称", "省市", "总分", ocp = chr(12288)))
for u in ulist:
file_object.write(tplt.format(u[0], u[1], u[2], u[3], ocp = chr(12288))) def main():
'''主函数'''
ulist = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
file_path = 'university rankings.txt'
html = get_html_text(url)
fill_ulist(ulist, html)
display_urank(ulist)
write_in_file(ulist, file_path) main()
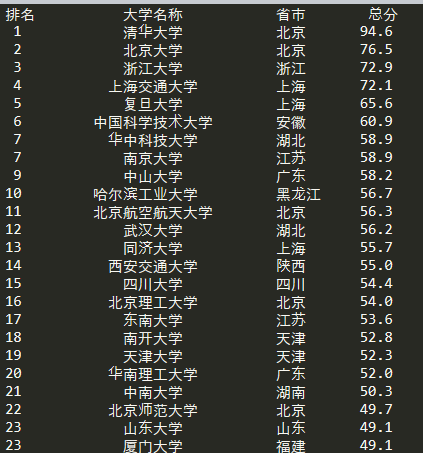
打印显示:
python爬虫入门---第二篇:获取2019年中国大学排名的更多相关文章
- Python爬虫入门案例:获取百词斩已学单词列表
百词斩是一款很不错的单词记忆APP,在学习过程中,它会记录你所学的每个单词及你答错的次数,通过此列表可以很方便地找到自己在记忆哪些单词时总是反复出错记不住.我们来用Python来爬取这些信息,同时学习 ...
- python爬虫入门---第一篇:获取某一网页所有超链接
这是一个通过使用requests和BeautifulSoup库,简单爬取网站的所有超链接的小爬虫.有任何问题欢迎留言讨论. import requests from bs4 import Beauti ...
- 2.Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- 转 Python爬虫入门二之爬虫基础了解
静觅 » Python爬虫入门二之爬虫基础了解 2.浏览网页的过程 在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以 ...
- Python爬虫入门有哪些基础知识点
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫入门(二)之Requests库
Python爬虫入门(二)之Requests库 我是照着小白教程做的,所以该篇是更小白教程hhhhhhhh 一.Requests库的简介 Requests 唯一的一个非转基因的 Python HTTP ...
- Python开发【第二篇】:初识Python
Python开发[第二篇]:初识Python Python简介 Python前世今生 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏 ...
- Python爬虫入门教程 43-100 百思不得姐APP数据-手机APP爬虫部分
1. Python爬虫入门教程 爬取背景 2019年1月10日深夜,打开了百思不得姐APP,想了一下是否可以爬呢?不自觉的安装到了夜神模拟器里面.这个APP还是比较有名和有意思的. 下面是百思不得姐的 ...
随机推荐
- 2019年微服务5大趋势,你pick哪个?
2018年对于微服务来说是非常重要的一年,这一年Service Mesh开始崭露头角,解决服务间复杂的通信问题,这一年很多国内互联网公司已经有了较为成熟的微服务实践案例,网易云主办的微服务实践沙龙中也 ...
- Learning WCF:Life Cycle of Service instance
示例代码下载地址:WCFDemo1Day 概述 客户端向WCF服务发出请求后,服务端会实例化一个Service对象(实现了契约接口的对象)用来处理请求,实例化Service对象以及维护其生命周期的方式 ...
- java之Stack详细介绍
1 Stack介绍 Stack简介 Stack是栈.它的特性是:先进后出(FILO, First In Last Out). java工具包中的Stack是继承于Vector(矢量队列)的,由于Ve ...
- maya2015卸载/安装失败/如何彻底卸载清除干净maya2015注册表和文件的方法
maya2015提示安装未完成,某些产品无法安装该怎样解决呢?一些朋友在win7或者win10系统下安装maya2015失败提示maya2015安装未完成,某些产品无法安装,也有时候想重新安装maya ...
- OpenStack-Ocata版+CentOS7.6 云平台环境搭建 — 4.镜像服务(glance)
节点配置信息说明: 控制节点:controller: IP:192.168.164.128 hostname&hosts:likeadmin 计算加点:Nova: IP:192.168.164 ...
- vertical-align css属性
vertical-align 属性设置元素的垂直对齐方式. vertical-align 的属性值: baseline:默认.元素放置在父元素的基线上. sub:垂直对齐文本的下标. super:垂直 ...
- 什么是Spring Boot?
什么是Spring Boot? Spring Boot是Spring开源组织下的子项目,是Spring组件一站式解决方案,主要是简化了使用Spring的难度,简省了繁重的配置,提供了各种启动器,开发者 ...
- Spring Boot 配置随机数技巧
Spring Boot支持在系统加载的时候配置随机数. 添加config/random.properties文件,添加以下内容: #随机32位MD5字符串 user.random.secret=${r ...
- tomcat容器是如何创建servlet类实例?用到了什么原理?
当容器启动时,会读取在webapps目录下所有的web应用中的web.xml文件,然后对 xml文件进行解析,并读取servlet注册信息.然后,将每个应用中注册的servlet类都进行加载,并通过 ...
- Python进程-理论
进程定义 程序: 计算机程序是存储在磁盘上的可执行二进制(或其他类型)文件.只有把它们加载到内存中,并被操作系统调用,它们才会拥有其自己的生命周期. 进程: 进程则是表示的一个正在执行的程序.每个进程 ...