[MapReduce_8] MapReduce 中的自定义分区实现
0. 说明
设置分区数量 && 编写自定义分区代码
1. 设置分区数量
分区(Partition)
分区决定了指定的 Key 进入到哪个 Reduce 中
分区目的:把相同的 Key 发送给同一个 Reduce
默认 hash 分区,算法
// 返回的分区号
(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks
设置分区数
job.setNumReduceTasks(3);
2. 代码编写
在 [MapReduce_1] 运行 Word Count 示例程序 代码基础之上进行以下操作
实现将文本中的数字存放在分区0,数字之外的内容放置到分区1
【2.1 编写 MyPartition.java】
package hadoop.mr.partition; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner; /**
* MapReduce 自定义分区
*/
public class MyPartition extends Partitioner<Text, IntWritable> {
/**
* 自定义分区将数字放在0号分区,其余放在1号分区
*/
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
try {
Integer.parseInt(key.toString());
return 0;
} catch (Exception e) {
return 1;
}
}
}
【2.2 修改 WCApp.java】

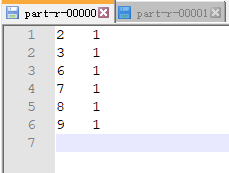
【2.3 最终结果】

[MapReduce_8] MapReduce 中的自定义分区实现的更多相关文章
- [大牛翻译系列]Hadoop(1)MapReduce 连接:重分区连接(Repartition join)
4.1 连接(Join) 连接是关系运算,可以用于合并关系(relation).对于数据库中的表连接操作,可能已经广为人知了.在MapReduce中,连接可以用于合并两个或多个数据集.例如,用户基本信 ...
- Hadoop mapreduce自定义分区HashPartitioner
本文发表于本人博客. 在上一篇文章我写了个简单的WordCount程序,也大致了解了下关于mapreduce运行原来,其中说到还可以自定义分区.排序.分组这些,那今天我就接上一次的代码继续完善实现自定 ...
- 在hadoop作业中自定义分区和归约
当遇到有特殊的业务需求时,需要对hadoop的作业进行分区处理 那么我们可以通过自定义的分区类来实现 还是通过单词计数的例子,JMapper和JReducer的代码不变,只是在JSubmit中改变了设 ...
- Hadoop学习之路(6)MapReduce自定义分区实现
MapReduce自带的分区器是HashPartitioner 原理:先对map输出的key求hash值,再模上reduce task个数,根据结果,决定此输出kv对,被匹配的reduce任务取走. ...
- 【Hadoop】MapReduce自定义分区Partition输出各运营商的手机号码
MapReduce和自定义Partition MobileDriver主类 package Partition; import org.apache.hadoop.io.NullWritable; i ...
- MapReduce之自定义分区器Partitioner
@ 目录 问题引出 默认Partitioner分区 自定义Partitioner步骤 Partition分区案例实操 分区总结 问题引出 要求将统计结果按照条件输出到不同文件中(分区). 比如:将统计 ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- MapReduce中的Join算法
在关系型数据库中Join是非常常见的操作,各种优化手段已经到了极致.在海量数据的环境下,不可避免的也会碰到这种类型的需求,例如在数据分析时需要从不同的数据源中获取数据.不同于传统的单机模式,在分布式存 ...
- [MapReduce_7] MapReduce 中的排序
0. 说明 部分排序 && 全排序 && 采样 && 二次排序 1. 介绍 sort 是根据 Key 进行排序 [部分排序] 在每个分区中,分别进行排序 ...
随机推荐
- Shell脚本中实现自动补全功能
对于Linuxer来说,自动补全是再熟悉不过的一个功能了.当你在命令行敲下部分的命令时,肯定会本能地按下Tab键补全完整的命令,当然除了命令补全之外,还有文件名补全. Bash-completion ...
- JavaScript “跑马灯”抽奖活动代码解析与优化(二)
既然是要编写插件.那么叫做"插件"的东西肯定是具有的某些特征能够满足我们平时开发的需求或者是提高我们的开发效率.那么叫做插件的东西应该具有哪些基本特征呢?让我们来总结一下: 1.J ...
- Spring Cloud Eureka 服务注册列表显示 IP 配置问题
服务提供者向 Eureka 注册中心注册,默认以 hostname 的形式显示,Eureka 服务页面显示的服务是机器名:端口,并不是IP+端口的形式 ,可以通过修改服务提供者配置自己的 IP 地址, ...
- css实现纯文字内容元素透明背景(兼容IE6)
HTML: <div class="title-wrapper"> <span class="title"> <span clas ...
- 从零开始学 Web 之 jQuery(六)为元素绑定多个相同事件,解绑事件
大家好,这里是「 从零开始学 Web 系列教程 」,并在下列地址同步更新...... github:https://github.com/Daotin/Web 微信公众号:Web前端之巅 博客园:ht ...
- C#效率优化(1)-- 使用泛型时避免装箱
本想接着上一篇详解泛型接着写一篇使用泛型时需要注意的一个性能问题,但是后来想着不如将之前的详解XX系列更正为现在的效率优化XX系列,记录在工作时遇到的一些性能优化的经验和技巧,如果有什么不足,还请大家 ...
- SaltStack快速入门-配置管理
1:定义远程配置时描述位置,salt配置用的是一种yaml的描述语法,saltstack也是可以分环境的,比如测试环境.生产环境,默认是base,base也是必须存在的,修改内容如下: file_ro ...
- Python装饰器举例分析
概述 装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象. 我们要需要一个能测试函数运行时间的decorator,可以定义如 ...
- [转]JS组件系列——Bootstrap组件福利篇:几款好用的组件推荐
本文转自:https://www.cnblogs.com/landeanfen/p/5461849.html#_label3 阅读目录 一.时间组件 1.效果展示 2.源码说明 3.代码示例 二.自增 ...
- SQL 行转列示例
--油表 select (select SUM(XiaoHaoLiang)as'油表消耗总值' FROM dbo.NengHaoYouBiao WHERE CaiJiRiQi between '201 ...