【转载】 强化学习(十)Double DQN (DDQN)
原文地址:
https://www.cnblogs.com/pinard/p/9778063.html
-----------------------------------------------------------------------------------------------
在强化学习(九)Deep Q-Learning进阶之Nature DQN中,我们讨论了Nature DQN的算法流程,它通过使用两个相同的神经网络,以解决数据样本和网络训练之前的相关性。但是还是有其他值得优化的点,文本就关注于Nature DQN的一个改进版本: Double DQN算法(以下简称DDQN)。
本章内容主要参考了ICML 2016的deep RL tutorial和DDQN的论文<Deep Reinforcement Learning with Double Q-learning>。
1. DQN的目标Q值计算问题
在DDQN之前,基本上所有的目标Q值都是通过贪婪法直接得到的,无论是Q-Learning, DQN(NIPS 2013)还是 Nature DQN,都是如此。比如对于Nature DQN,虽然用了两个Q网络并使用目标Q网络计算Q值,其第j个样本的目标Q值的计算还是贪婪法得到的,计算入下式:
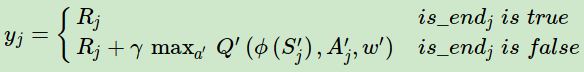
使用max虽然可以快速让Q值向可能的优化目标靠拢,但是很容易过犹不及,导致过度估计(Over Estimation),所谓过度估计就是最终我们得到的算法模型有很大的偏差(bias)。为了解决这个问题, DDQN通过 解耦 目标Q值动作的选择和目标Q值的计算这两步,来达到消除过度估计的问题。
2. DDQN的算法建模
DDQN和Nature DQN一样,也有一样的两个Q网络结构。在Nature DQN的基础上,通过解耦目标Q值动作的选择和目标Q值的计算这两步,来消除过度估计的问题。
在上一节里,Nature DQN对于非终止状态,其目标Q值的计算式子是:
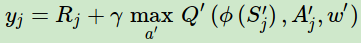
在DDQN这里,不再是直接在目标Q网络里面找各个动作中最大Q值,而是先在当前Q网络中先找出最大Q值对应的动作,即
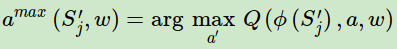
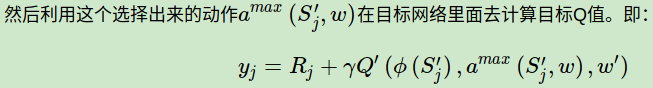
综合起来写就是:
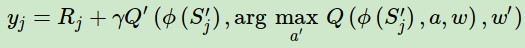
除了目标Q值的计算方式以外,DDQN算法和Nature DQN的算法流程完全相同。
3. DDQN算法流程
这里我们总结下DDQN的算法流程,和Nature DQN的区别仅仅在步骤2.f中目标Q值的计算。

输出:Q网络参数

注意,上述第二步的f步和g步的Q值计算也都需要通过Q网络计算得到。另外,实际应用中,为了算法较好的收敛,探索率εϵ需要随着迭代的进行而变小。
4. DDQN算法实例
下面我们用一个具体的例子来演示DQN的应用。仍然使用了OpenAI Gym中的CartPole-v0游戏来作为我们算法应用。CartPole-v0游戏的介绍参见这里。它比较简单,基本要求就是控制下面的cart移动使连接在上面的pole保持垂直不倒。这个任务只有两个离散动作,要么向左用力,要么向右用力。而state状态就是这个cart的位置和速度, pole的角度和角速度,4维的特征。坚持到200分的奖励则为过关。
完整的代码参见我的github: https://github.com/ljpzzz/machinelearning/blob/master/reinforcement-learning/ddqn.py
这里我们重点关注DDQN和上一节的Nature DQN的代码的不同之处。代码只有一个地方不一样,就是计算目标Q值的时候,如下:
# Step 2: calculate y
y_batch = []
current_Q_batch = self.Q_value.eval(feed_dict={self.state_input: next_state_batch})
max_action_next = np.argmax(current_Q_batch, axis=1)
target_Q_batch = self.target_Q_value.eval(feed_dict={self.state_input: next_state_batch}) for i in range(0,BATCH_SIZE):
done = minibatch[i][4]
if done:
y_batch.append(reward_batch[i])
else :
target_Q_value = target_Q_batch[i, max_action_next[i]]
y_batch.append(reward_batch[i] + GAMMA * target_Q_value)
而之前的Nature DQN这里的目标Q值计算是如下这样的:
# Step 2: calculate y
y_batch = []
Q_value_batch = self.target_Q_value.eval(feed_dict={self.state_input:next_state_batch})
for i in range(0,BATCH_SIZE):
done = minibatch[i][4]
if done:
y_batch.append(reward_batch[i])
else :
y_batch.append(reward_batch[i] + GAMMA * np.max(Q_value_batch[i]))
除了上面这部分的区别,两个算法的代码完全相同。
5. DDQN小结
DDQN算法出来以后,取得了比较好的效果,因此得到了比较广泛的应用。不过我们的DQN仍然有其他可以优化的点,如上一篇最后讲到的: 随机采样的方法好吗?按道理经验回放里不同样本的重要性是不一样的,TD误差大的样本重要程度应该高。针对这个问题,我们在下一节的Prioritised Replay DQN中讨论。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)
---------------------------------------------------------------------------------------------------
#######################################################################
# Copyright (C) #
# 2016 - 2019 Pinard Liu(liujianping-ok@163.com) #
# https://www.cnblogs.com/pinard #
# Permission given to modify the code as long as you keep this #
# declaration at the top #
#######################################################################
## https://www.cnblogs.com/pinard/p/9778063.html ##
## 强化学习(十)Double DQN (DDQN) ## import gym
import tensorflow as tf
import numpy as np
import random
from collections import deque # Hyper Parameters for DQN
GAMMA = 0.9 # discount factor for target Q
INITIAL_EPSILON = 0.5 # starting value of epsilon
FINAL_EPSILON = 0.01 # final value of epsilon
REPLAY_SIZE = 10000 # experience replay buffer size
BATCH_SIZE = 32 # size of minibatch
REPLACE_TARGET_FREQ = 10 # frequency to update target Q network class DQN():
# DQN Agent
def __init__(self, env):
# init experience replay
self.replay_buffer = deque()
# init some parameters
self.time_step = 0
self.epsilon = INITIAL_EPSILON
self.state_dim = env.observation_space.shape[0]
self.action_dim = env.action_space.n self.create_Q_network()
self.create_training_method() # Init session
self.session = tf.InteractiveSession()
self.session.run(tf.global_variables_initializer()) def create_Q_network(self):
# input layer
self.state_input = tf.placeholder("float", [None, self.state_dim])
# network weights
with tf.variable_scope('current_net'):
W1 = self.weight_variable([self.state_dim,20])
b1 = self.bias_variable([20])
W2 = self.weight_variable([20,self.action_dim])
b2 = self.bias_variable([self.action_dim]) # hidden layers
h_layer = tf.nn.relu(tf.matmul(self.state_input,W1) + b1)
# Q Value layer
self.Q_value = tf.matmul(h_layer,W2) + b2 with tf.variable_scope('target_net'):
W1t = self.weight_variable([self.state_dim,20])
b1t = self.bias_variable([20])
W2t = self.weight_variable([20,self.action_dim])
b2t = self.bias_variable([self.action_dim]) # hidden layers
h_layer_t = tf.nn.relu(tf.matmul(self.state_input,W1t) + b1t)
# Q Value layer
self.target_Q_value = tf.matmul(h_layer,W2t) + b2t t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='target_net')
e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='current_net') with tf.variable_scope('soft_replacement'):
self.target_replace_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)] def create_training_method(self):
self.action_input = tf.placeholder("float",[None,self.action_dim]) # one hot presentation
self.y_input = tf.placeholder("float",[None])
Q_action = tf.reduce_sum(tf.multiply(self.Q_value,self.action_input),reduction_indices = 1)
self.cost = tf.reduce_mean(tf.square(self.y_input - Q_action))
self.optimizer = tf.train.AdamOptimizer(0.0001).minimize(self.cost) def perceive(self,state,action,reward,next_state,done):
one_hot_action = np.zeros(self.action_dim)
one_hot_action[action] = 1
self.replay_buffer.append((state,one_hot_action,reward,next_state,done))
if len(self.replay_buffer) > REPLAY_SIZE:
self.replay_buffer.popleft() if len(self.replay_buffer) > BATCH_SIZE:
self.train_Q_network() def train_Q_network(self):
self.time_step += 1
# Step 1: obtain random minibatch from replay memory
minibatch = random.sample(self.replay_buffer,BATCH_SIZE)
state_batch = [data[0] for data in minibatch]
action_batch = [data[1] for data in minibatch]
reward_batch = [data[2] for data in minibatch]
next_state_batch = [data[3] for data in minibatch] # Step 2: calculate y
y_batch = []
current_Q_batch = self.Q_value.eval(feed_dict={self.state_input: next_state_batch})
max_action_next = np.argmax(current_Q_batch, axis=1)
target_Q_batch = self.target_Q_value.eval(feed_dict={self.state_input: next_state_batch}) for i in range(0,BATCH_SIZE):
done = minibatch[i][4]
if done:
y_batch.append(reward_batch[i])
else :
target_Q_value = target_Q_batch[i, max_action_next[i]]
y_batch.append(reward_batch[i] + GAMMA * target_Q_value) self.optimizer.run(feed_dict={
self.y_input:y_batch,
self.action_input:action_batch,
self.state_input:state_batch
}) def egreedy_action(self,state):
Q_value = self.Q_value.eval(feed_dict = {
self.state_input:[state]
})[0]
if random.random() <= self.epsilon:
self.epsilon -= (INITIAL_EPSILON - FINAL_EPSILON) / 10000
return random.randint(0,self.action_dim - 1)
else:
self.epsilon -= (INITIAL_EPSILON - FINAL_EPSILON) / 10000
return np.argmax(Q_value) def action(self,state):
return np.argmax(self.Q_value.eval(feed_dict = {
self.state_input:[state]
})[0]) def update_target_q_network(self, episode):
# update target Q netowrk
if episode % REPLACE_TARGET_FREQ == 0:
self.session.run(self.target_replace_op)
#print('episode '+str(episode) +', target Q network params replaced!') def weight_variable(self,shape):
initial = tf.truncated_normal(shape)
return tf.Variable(initial) def bias_variable(self,shape):
initial = tf.constant(0.01, shape = shape)
return tf.Variable(initial)
# ---------------------------------------------------------
# Hyper Parameters
ENV_NAME = 'CartPole-v0'
EPISODE = 3000 # Episode limitation
STEP = 300 # Step limitation in an episode
TEST = 5 # The number of experiment test every 100 episode def main():
# initialize OpenAI Gym env and dqn agent
env = gym.make(ENV_NAME)
agent = DQN(env) for episode in range(EPISODE):
# initialize task
state = env.reset()
# Train
for step in range(STEP):
action = agent.egreedy_action(state) # e-greedy action for train
next_state,reward,done,_ = env.step(action)
# Define reward for agent
reward = -1 if done else 0.1
agent.perceive(state,action,reward,next_state,done)
state = next_state
if done:
break
# Test every 100 episodes
if episode % 100 == 0:
total_reward = 0
for i in range(TEST):
state = env.reset()
for j in range(STEP):
env.render()
action = agent.action(state) # direct action for test
state,reward,done,_ = env.step(action)
total_reward += reward
if done:
break
ave_reward = total_reward/TEST
print ('episode: ',episode,'Evaluation Average Reward:',ave_reward)
agent.update_target_q_network(episode) if __name__ == '__main__':
main()

【转载】 强化学习(十)Double DQN (DDQN)的更多相关文章
- 强化学习(十六) 深度确定性策略梯度(DDPG)
在强化学习(十五) A3C中,我们讨论了使用多线程的方法来解决Actor-Critic难收敛的问题,今天我们不使用多线程,而是使用和DDQN类似的方法:即经验回放和双网络的方法来改进Actor-Cri ...
- 强化学习(十五) A3C
在强化学习(十四) Actor-Critic中,我们讨论了Actor-Critic的算法流程,但是由于普通的Actor-Critic算法难以收敛,需要一些其他的优化.而Asynchronous Adv ...
- 强化学习(十四) Actor-Critic
在强化学习(十三) 策略梯度(Policy Gradient)中,我们讲到了基于策略(Policy Based)的强化学习方法的基本思路,并讨论了蒙特卡罗策略梯度reinforce算法.但是由于该算法 ...
- 强化学习(十九) AlphaGo Zero强化学习原理
在强化学习(十八) 基于模拟的搜索与蒙特卡罗树搜索(MCTS)中,我们讨论了MCTS的原理和在棋类中的基本应用.这里我们在前一节MCTS的基础上,讨论下DeepMind的AlphaGo Zero强化学 ...
- 强化学习(十)Double DQN (DDQN)
在强化学习(九)Deep Q-Learning进阶之Nature DQN中,我们讨论了Nature DQN的算法流程,它通过使用两个相同的神经网络,以解决数据样本和网络训练之前的相关性.但是还是有其他 ...
- 强化学习(十二) Dueling DQN
在强化学习(十一) Prioritized Replay DQN中,我们讨论了对DQN的经验回放池按权重采样来优化DQN算法的方法,本文讨论另一种优化方法,Dueling DQN.本章内容主要参考了I ...
- 【论文研读】强化学习入门之DQN
最近在学习斯坦福2017年秋季学期的<强化学习>课程,感兴趣的同学可以follow一下,Sergey大神的,有英文字幕,语速有点快,适合有一些基础的入门生. 今天主要总结上午看的有关DQN ...
- 强化学习(十八) 基于模拟的搜索与蒙特卡罗树搜索(MCTS)
在强化学习(十七) 基于模型的强化学习与Dyna算法框架中,我们讨论基于模型的强化学习方法的基本思路,以及集合基于模型与不基于模型的强化学习框架Dyna.本文我们讨论另一种非常流行的集合基于模型与不基 ...
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
随机推荐
- (转载)Unity学习笔记:关于Dropdown的学习
今天组长让我写一个界面,其中用到了下拉条,我的印象还停留在以前的NGUI有现成的组件,但是uGUI没有的那阶段,组长跟我说uGUI现在也有了,研究了一下,发现real方便哦,今天就来简单说一下用法吧. ...
- Git Github的区别 & Pycharm使用GitHub
首先:git和github功能很强大,随着使用深入,我将随时填充,更新这篇文章,记录随时遇到的新的问题和感悟. 第一次知道github是看廖雪峰的课程,所谓版本管理,之前在辉煌科技用的是SVN,了解一 ...
- oracle 11 g release 2 卸载
Win 10 系统,Oracle 11 g R 2 ,安装目录C盘根目录 1.停止Oracle的所有服务 打开“服务”窗口,关闭Oracle的所有服务 2.运行Oracle Universal Ins ...
- Angular4.0 项目报错:Unexpected value xxxComponent' declared by the module 'xxxxModule'. Please add a @Pipe...
最近刚刚开始学习angular 4.0,在网上找了一个小项目教程学习,然而学习的过程有点艰辛,,各种报错,我明明就是按照博主的步骤老老实实走的呀!!话不多说,上bug- .- Uncaught Er ...
- 文献导读 | A Pan-Cancer Analysis of Enhancer Expression in Nearly 9000 Patient Samples
Chen, H., Li, C., Peng, X., Zhou, Z., Weinstein, J.N., Liang, H. and Cancer Genome Atlas Research Ne ...
- Go语言开发Prometheus Exporter示例
一.Prometheus中的基本概念 Prometheus将所有数据存储为时间序列,这里先来了解一下prometheus中的一些基本概念 指标名和标签每个时间序列都由指标名和一组键值对(也称为标签)唯 ...
- POJ-3233 Matrix Power Series 矩阵A^1+A^2+A^3...求和转化
S(k)=A^1+A^2...+A^k. 保利求解就超时了,我们考虑一下当k为偶数的情况,A^1+A^2+A^3+A^4...+A^k,取其中前一半A^1+A^2...A^k/2,后一半提取公共矩阵A ...
- BootCamp 在MacBook 上安装Win10
首先到网上下载win10的ISO光盘, 制作win10安装盘时,一直停在copy文件.最后文件还是没有copy完整. 需要手工把iso里的文件拷贝到U盘里. 否则提示source\install.wi ...
- mac上配置java开发环境
项目在mac上跑起来的步骤: 1. 访问,https://brew.sh/ 装上这个然后 brew install git brew install maven, settings.xml需要放 ...
- arguments.callee弃用与webuploader
使用最近使用ueditor的时候 谷歌浏览器下上传相同图片两次后第三次上传不了 而且取消了后会出现一个错误的图片.使用的ueditor是1.4.3 后来发现 这个是 webuploader插件的问题. ...