ceph mimic版本 部署安装

ceph 寻址过程
1. file --- object映射, 把file分割成N个相同的对象
2. object - PG 映射, 利用静态hash得到objectID的伪随机值,在 "位与" mask 上使得object获取属于自己的PG
3. pg -- osd 映射, 将pg映射到实际的存储单元osd, RADOS 利用 crush 算法, 由pgid得到一组n个osd,再由osd daemon 执行映射到本地的object在本地系统中存储,访问,数据维护, 此次映射功能直接受到crush map 以及rule应县个,只有cluster map 和 rule不发生改变时,pg 和osd的映射关系才固定。
1. 基本概念
ceph 的组件采用插件的机制,包括后端存储,KV 数据库,磁盘管理等。各组件之间可以灵活的组合。
基于后端存储包括 filestore, kvstore,memstore 和 bluestore。 Ceph Luminous 引用了 bluestore 的存储类型,不依赖文件系统,直接管理物理磁盘,相比filestore 在 io 写入的时候路径更短,也避免了二次写入的问题,性能会更加好。
KV 存储主要包括LevelDB, MemDB 和新的 RocksDB。RocksDB 是 Facebook 基于 LevelDB 开发的 key-value 数据,并对闪存(flash)有更友好的优化。
RocksDB 原本只基于文件系统的。但是得益于它本身的灵活性,bluestore 实现了一套 RocksDB 的 Env 接口,还在BlueStore 上面实现了一套 BlueFS 的接口与BluestoreEnv 对接。使得 RocksDB 可以存储在 BlueStore 上面。
BlueStore选择将DB 和WAL 分区交给BlueFs来使用,此时这两个分区分别存储BlueStore后端产生的元数据和日志文件,这样整个存储系统通过元数据对数据的操作效率极高,同时通过日志事务来维持系统的稳定性,整个系统相对来说稳定性就极高
后端存储使用 bluestore 时,wal 是 RocksDB 的write-ahead log,提前写的日志, 相当于之前的 journal 数据,db 是 RocksDB 的metadata 信息。在磁盘选择原则是 block.wal > block.db > block 如果所有的数据都在单块盘上,那是没有必要指定 wal &db 的大小的。 如果 wal & db 是在不同的盘上,由于 wal/db 一般都会分的比较小,是有满的可能性的。如果满了,这些数据会迁移到下一个快的盘上(wal - db - main)。所以最少不会因为数据满了,而造成无法写入
使用混合机械和固态硬盘设置时,block.db为Bluestore创建足够大的逻辑卷非常重要 。通常,block.db应该具有 尽可能大的逻辑卷。 建议block.db尺寸不小于4% block。例如,如果block大小为1TB,则block.db 不应小于40GB。 如果不使用快速和慢速设备的混合,则不需要为block.db(或block.wal)创建单独的逻辑卷。Bluestore将在空间内自动管理这些内容block 使用bluestore 时的 osd 分区
如果是使用的 ceph-disk 管理磁盘,他会建立一个 100MB 的分区,来存放 keyring / whoami 这些信息,这和之前的逻辑是一样的。 如果使用 ceph-volume 管理磁盘,/var/lib/ceph/osd/ceph- 分区会从tmpfs 挂载过来(也就是内存)

Ceph Monitor(ceph-mon)维护集群状态的映射,包括监视器映射,管理器映射,OSD映射和CRUSH映射。这些映射是Ceph守护进程相互协调所需的关键集群状态。监视器还负责管理守护进程和客户端之间的身份验证。冗余和高可用性通常至少需要三个监视器。 Ceph Manager守护程序(ceph-mgr)负责跟踪运行时指标和Ceph集群的当前状态,包括存储利用率,当前性能指标和系统负载。Ceph Manager守护进程还托管基于python的插件来管理和公开Ceph集群信息,包括基于Web的仪表板和REST API。高可用性通常至少需要两名经理。 Ceph OSD(对象存储守护进程 ceph-osd)存储数据,处理数据复制,恢复,重新平衡,并通过检查其他Ceph OSD守护进程来获取心跳,为Ceph监视器和管理器提供一些监视信息。冗余和高可用性通常至少需要3个Ceph OSD。 Ceph元数据服务器(MDS ceph-mds)代表Ceph文件系统存储元数据(即,Ceph块设备和Ceph对象存储不使用MDS)。Ceph的元数据服务器允许POSIX文件系统的用户来执行基本的命令(如 ls,find没有放置在一个Ceph存储集群的巨大负担,等等)。
2. 环境准备
3、 统一主机hosts
[root@monitor1 ceph-cluster]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.16.230.21 monitor1
172.16.230.22 monitor2
172.16.230.23 monitor3
172.16.230.24 node1
172.16.230.25 node2
172.16.230.26 node3
172.16.230.27 node4
172.16.230.28 node5
for i in {22..28}; do scp /etc/hosts root@172.16.230.$i:/etc/; done
4. 时间同步
[root@master1 ~]# crontab -l
#Ansible: 每隔5分钟同步时间服务器
*/ * * * * /usr/sbin/ntpdate 192.168.20.220
5. ssh密码打通
6. 修改visudo
找到 Defaults requiretty 选项,直接注释掉,这样 ceph-deploy 就可以用之前创建的用户(创建部署 Ceph 的用户 )连接了。
7. 设置阿里yum源
[Ceph]
name=Ceph packages for $basearch
baseurl=https://mirrors.aliyun.com/ceph/rpm-mimic/el7/x86_64/
enabled=
gpgcheck=
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc [Ceph-noarch]
name=Ceph noarch packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-mimic/el7/noarch/
enabled=
gpgcheck=
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc [ceph-source]
name=Ceph source packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-mimic/el7/SRPMS/
enabled=
gpgcheck=
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
8. ntp时间同步
*/ * * * * /usr/sbin/ntpdate ntp5.aliyun.com
9.安装ceph-deploy包
[root@master1 ~]# yum -y install ceph-deploy
10. 创建配置文件目录
[root@master1 ~]# mkdir /opt/ceph-cluster
11. 清除集群
想要重新开始,请执行以下操作以清除配置
ceph-deploy purgedata {ceph-node} [{ceph-node}]
ceph-deploy forgetkeys 要清除Ceph包
ceph-deploy purge {ceph-node} [{ceph-node}]
例:
ceph-deploy purge monitor1 osd1
12. 创建群集
[root@master1 ~]# mkdir /opt/ceph-cluster
[root@master1 ~]# cd /opt/ceph-cluster
[root@master1 ceph-cluster]# ceph-deploy new monitor1 monitor2 monitor3 当前目录会生成 Ceph配置文件,监视器密钥密钥环和新群集的日志文件
ceph.conf ceph-eploy-ceph.log ceph.mon.keyring
13. 修改ceph.conf 配置文件
[global]
fsid = a5e478b2-f3bf-4fbf-930a-69a6686502d1
mon_initial_members = monitor1, monitor2, monitor3
mon_host = 172.16.230.21,172.16.230.22,172.16.230.23
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd pool default size = # 修改的副本数
public network = 172.16.230.0/ # 指定public 网络
cluster network = 1.1.1.0/ # 指定cluster 网络
mon_allow_pool_delete = true # 允许删除pool, 需要重启monitor
14. 安装ceph
#所有节点安装ceph ceph-radosgw yum -y install ceph ceph-radosgw
15. 初始监视器并收集密钥
[root@monitor1 ceph-cluster]# ceph-deploy mon create-initial 执行完成后会在/etc/ceph目录多以下内容
ceph.client.admin.keyring
ceph.bootstrap-mgr.keyring
ceph.bootstrap-osd.keyring
ceph.bootstrap-mds.keyring
ceph.bootstrap-rgw.keyring
ceph.bootstrap-rbd.keyring
ceph.bootstrap-rbd-mirror.keyring
16. 将ceph.client.admin.keyring拷贝到各个节点上
[root@monitor1 ceph-cluster]# ceph-deploy --overwrite-con admin monitor1 monitor2 monitor3 node1 node2 node3 node4 node5
17. 查看osd节点分区情况
首先看一下块设备信息 [root@node1 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
fd0 : 4K disk
sda : 40G disk
├─sda1 : 1G part /boot
└─sda2 : 39G part
├─cl-root : .1G lvm /
└─cl-swap : .9G lvm [SWAP]
sdb : 70G disk
sdc : 50G disk
sr0 : 1024M rom
18.销毁osd节点硬盘数据
[root@monitor1 ceph-cluster]# ceph-deploy disk zap node1 /dev/sdc
[root@monitor1 ceph-cluster]# ceph-deploy disk zap node2 /dev/sdc
[root@monitor1 ceph-cluster]# ceph-deploy disk zap node3 /dev/sdc
[root@monitor1 ceph-cluster]# ceph-deploy disk zap node4 /dev/sdc
[root@monitor1 ceph-cluster]# ceph-deploy disk zap node5 /dev/sdc
创建一个bluestore的osd,有以下几种设备选择:
- A block device, a block.wal, and a block.db device
- A block device and a block.wal device
- A block device and a block.db device
- A single block device
参考:http://docs.ceph.com/docs/master/ceph-volume/lvm/prepare/#bluestore
block device也有如下三种选项:
- 整块磁盘
- 磁盘分区
- 逻辑卷(a logical volume of LVM)
配置使用整块磁盘时,ceph-volume会自动创建一个logical volume使用
19. 创建osd节点
[root@monitor1 ceph-cluster]# ceph-deploy osd create --data /dev/sdc node1
[root@monitor1 ceph-cluster]# ceph-deploy osd create --data /dev/sdc node2
[root@monitor1 ceph-cluster]# ceph-deploy osd create --data /dev/sdc node3
[root@monitor1 ceph-cluster]# ceph-deploy osd create --data /dev/sdc node4
[root@monitor1 ceph-cluster]# ceph-deploy osd create --data /dev/sdc node5
#######################################################################
sdc用于osd,sdb将他分成2个区用于bluestore的db和wal,sdc 是sas 盘, sdb 是固态硬盘
所有osd节点 上划分gpt分区
[root@node1 ~]# fdisk /dev/sdb Command (m for help): g
Building a new GPT disklabel (GUID: E0A9CECB-29AD-4C7A-BB61-223A3F5DB1C4) Command (m for help): n
Partition number (-, default ):
First sector (-, default ):
Last sector, +sectors or +size{K,M,G,T,P} (-, default ): +10G
Created partition Command (m for help): n
Partition number (-, default ):
First sector (-, default ):
Last sector, +sectors or +size{K,M,G,T,P} (-, default ): +10G
Created partition Command (m for help): w
The partition table has been altered!
如果发现分区未更新,执行命令
partprobe
再次查看:
[root@node1 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
fd0 : 4K disk
sda : 40G disk
├─sda1 : 1G part /boot
└─sda2 : 39G part
├─cl-root : .1G lvm /
└─cl-swap : .9G lvm [SWAP]
sdb : 70G disk
├─sdb1 : 14G part
├─sdb2 : 14G part
sdc : 50G disk
sr0 : 1024M rom
创建osd
[root@monitor1 ceph-cluster]# ceph-deploy osd create node1 --bluestore --data /dev/sdc --block-db /dev/sdb1 --block-wal /dev/sdb2
[root@monitor1 ceph-cluster]# ceph-deploy osd create node2 --bluestore --data /dev/sdc --block-db /dev/sdb1 --block-wal /dev/sdb2
[root@monitor1 ceph-cluster]# ceph-deploy osd create node3 --bluestore --data /dev/sdc --block-db /dev/sdb1 --block-wal /dev/sdb2
[root@monitor1 ceph-cluster]# ceph-deploy osd create node4 --bluestore --data /dev/sdc --block-db /dev/sdb1 --block-wal /dev/sdb2
[root@monitor1 ceph-cluster]# ceph-deploy osd create node5 --bluestore --data /dev/sdc --block-db /dev/sdb1 --block-wal /dev/sdb2
当出现报错:
[node4][DEBUG ] stderr: : (main()+0x2c58) [0x7f8e8dc18c18]
[node4][DEBUG ] stderr: : (__libc_start_main()+0xf5) [0x7f8e808c03d5]
[node4][DEBUG ] stderr: : (()+0x384ab0) [0x7f8e8dcf0ab0]
[node4][DEBUG ] stderr: NOTE: a copy of the executable, or `objdump -rdS <executable>` is needed to interpret this.
[node4][DEBUG ] --> Was unable to complete a new OSD, will rollback changes
[node4][DEBUG ] Running command: /bin/ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring osd purge-new osd. --yes-i-really-mean-it
[node4][DEBUG ] stderr: purged osd.
[node4][ERROR ] RuntimeError: command returned non-zero exit status:
[ceph_deploy.osd][ERROR ] Failed to execute command: /usr/sbin/ceph-volume --cluster ceph lvm create --bluestore --data /dev/sdc --block.wal /dev/sdb2 --block.db /dev/sdb1
[ceph_deploy][ERROR ] GenericError: Failed to create OSDs 修复:
node节点卸载挂载分区
[root@node4 ~]# umount /var/lib/ceph/osd/ceph-
查看lvs [root@node4 ~]# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
osd-block-ab4df89f---b683-e05c161089a4 ceph-183df03c-83fb-441c-a82e-d7b560e1a611 -wi-a----- .00g
root cl -wi-ao---- .12g
swap cl -wi-ao---- .88g 删除lv,vg,pv
[root@node4 ~]# lvremove osd-block-ab4df89f---b683-e05c161089a4 ceph-183df03c-83fb-441c-a82e-d7b560e1a611
Volume group "osd-block-ab4df89f-8682-4233-b683-e05c161089a4" not found
Cannot process volume group osd-block-ab4df89f---b683-e05c161089a4
Do you really want to remove active logical volume ceph-183df03c-83fb-441c-a82e-d7b560e1a611/osd-block-ab4df89f---b683-e05c161089a4? [y/n]: y
Logical volume "osd-block-ab4df89f-8682-4233-b683-e05c161089a4" successfully removed
[root@node4 ~]# vgremove ceph-183df03c-83fb-441c-a82e-d7b560e1a611
Volume group "ceph-183df03c-83fb-441c-a82e-d7b560e1a611" successfully removed
[root@node4 ~]# pvremove /dev/sdc
Labels on physical volume "/dev/sdc" successfully wiped. 删除/var/lib/ceph/osd/ 所有
[root@node4 ~]# rm /var/log/ceph/ceph-* -rf 删除 ceph 日志
[root@node4 ~]# rm -rf /var/lib/ceph/* monitor1 上重置node4 的sdc分区
[root@monitor1 ceph-cluster]# ceph-deploy disk zap node4 /dev/sdc monitor1 上重新创建osd节点
[root@monitor1 ceph-cluster]# ceph-deploy osd create node4 --bluestore --data /dev/sdc --block-db /dev/sdb1 --block-wal /dev/sdb2
####发现一个问题,添加osd 第一次都不成功,要按照上面步骤,重新添加
20. monitor上安装mgr
[root@monitor1 ceph-cluster]# ceph-deploy mgr create monitor1 monitor2 monitor3
21.开启dashboard功能, http://docs.ceph.com/docs/mimic/mgr/dashboard/
[root@monitor1 ceph-cluster]# ceph mgr module enable dashboard
22. ceph.conf 添加 mgr
[mon]
mgr initial modules = dashboard
22. 支持ssl.生成并安装自签名的证书
[root@monitor1 ceph-cluster]# ceph dashboard create-self-signed-cert
Self-signed certificate created
23. 生成证书
[root@monitor1 ceph-cluster]# mkdir ssl
[root@monitor1 ceph-cluster]# cd ssl
[root@monitor1 ceph-cluster]# openssl req -new -nodes -x509 \
-subj "/O=IT/CN=ceph-mgr-dashboard" -days \
-keyout dashboard.key -out dashboard.crt -extensions v3_ca
[root@monitor1 ceph-cluster]# ls dashboard.crt dashboard.key
24. 更改ssl证书和密钥后,需要手动重启mgr
[root@monitor1 ssl]# ceph mgr module disable dashboard
[root@monitor1 ssl]# ceph mgr module enable dashboard
25. 更改绑定的IP 和 端口号, ####修改后不起作用##########
[root@monitor1 ssl]# ceph config set mgr mgr/dashboard/server_addr 172.16.230.21
[root@monitor1 ssl]# ceph config set mgr mgr/dashboard/server_port 7000
23.创建 web 登录用户密码
[root@monitor1 ceph-cluster]# ceph dashboard set-login-credentials fengjian
Username and password updated
24.查看服务访问地址:
[root@monitor1 ceph-cluster]# ceph mgr services
{
"dashboard": "https://monitor1:8443/"
}
25.登录页面

用户管理
http://docs.ceph.com/docs/master/rados/operations/user-management/
当ceph在启动身份验证和授权的情况下,必须指定用户和包含指定用的密钥的密钥环,如果未指定用户名,ceph将client.admin 作为默认用户名, 如果没有指定密钥环,ceph将通过keyring ceph配置中的设置查找密钥环,
Ceph存储集群用户与Ceph对象存储用户或Ceph文件系统用户不同。Ceph对象网关使用Ceph存储集群用户在网关守护程序和存储集群之间进行通信,但网关为最终用户提供了自己的用户管理功能。Ceph文件系统使用POSIX语义。与Ceph文件系统关联的用户空间与Ceph存储群集用户不同。
添加用户
添加用户会创建用户名(即TYPE.ID),密钥以及用于创建用户的命令中包含的任何功能。
用户密钥使用户能够使用Ceph存储集群进行身份验证。用户的功能授权用户在Ceph监视器(mon),Ceph OSD(osd)或Ceph元数据服务器(mds)上读取,写入或执行。
有几种方法可以添加用户:
ceph auth add:此命令是添加用户的规范方式。它将创建用户,生成密钥并添加任何指定的功能。ceph auth get-or-create:此命令通常是创建用户最方便的方法,因为它返回一个密钥文件格式,其中包含用户名(括号中)和密钥。如果用户已存在,则此命令仅返回密钥文件格式的用户名和密钥。您可以使用该 选项将输出保存到文件。-o{filename}ceph auth get-or-create-key:此命令是创建用户并返回用户密钥(仅)的便捷方式。这对仅需要密钥的客户端(例如,libvirt)非常有用。如果用户已存在,则此命令只返回密钥。您可以使用该选项将输出保存到文件。-o {filename}
创建客户端用户时,您可以创建没有功能的用户。没有功能的用户除了仅仅身份验证之外没用,因为客户端无法从监视器检索群集映射。但是,如果您希望稍后使用该命令推迟添加功能,则可以创建没有功能的用户。ceph auth caps
典型用户至少具有Ceph监视器的读取功能以及Ceph OSD上的读写功能。此外,用户的OSD权限通常仅限于访问特定池。
ceph auth add client.john mon 'allow r' osd 'allow rw pool=liverpool'
ceph auth get-or-create client.paul mon 'allow r' osd 'allow rw pool=liverpool'
ceph auth get-or-create client.george mon 'allow r' osd 'allow rw pool=liverpool' -o george.keyring
ceph auth get-or-create-key client.ringo mon 'allow r' osd 'allow rw pool=liverpool' -o ringo.key
修改用户功能
该命令允许您指定用户并更改用户的功能。设置新功能将覆盖当前功能。查看当前运行的功能。要添加功能,还应在使用表单时指定现有功能:ceph auth capsceph auth get USERTYPE.USERID
ceph auth caps USERTYPE.USERID {daemon} 'allow [r|w|x|*|...] [pool={pool-name}] [namespace={namespace-name}]' [{daemon} 'allow [r|w|x|*|...] [pool={pool-name}] [namespace={namespace-name}]']
ceph auth get client.john
ceph auth caps client.john mon 'allow r' osd 'allow rw pool=liverpool'
ceph auth caps client.paul mon 'allow rw' osd 'allow rwx pool=liverpool'
ceph auth caps client.brian-manager mon 'allow *' osd 'allow *'
删除用户
ceph auth del {TYPE}.{ID}
哪里{TYPE}是一个client,osd,mon,或mds,并且{ID}是用户名或守护进程的ID
打印用户密钥
ceph auth print-key {TYPE}.{ID}
{TYPE}是一个client,osd,mon,或mds,并且{ID}是用户名或守护进程的ID。
当您需要使用用户密钥(例如,libvirt)填充客户端软件时,打印用户密钥非常有用。
mount -t ceph serverhost:/ mountpoint -o name=client.user,secret=`ceph auth print-key client.user`
导入用户
要导入一个或多个用户,请使用并指定密钥环:ceph auth import
sudo ceph auth import -i /etc/ceph/ceph.keyring
ceph存储集群将添加新用户,他们的密钥和功能,并将更新现有用户,他们的密钥和功能
密钥环管理
当通过Ceph客户端访问Ceph时,Ceph客户端将查找本地密钥环。Ceph keyring默认使用以下四个密钥环名称预设设置,因此不必在Ceph配置文件中设置它们,除非您想覆盖默认值(不推荐):
/etc/ceph/$cluster.$name.keyring/etc/ceph/$cluster.keyring/etc/ceph/keyring/etc/ceph/keyring.bin
$cluster变量是您的Ceph集群名称,由Ceph配置文件的名称定义(即,ceph.conf表示集群名称ceph;因此,ceph.keyring)。$name变量是用户类型和用户ID(例如,client.admin因此ceph.client.admin.keyring)
创建用户(例如,client.ringo)之后,您必须获取密钥并将其添加到Ceph客户端上的密钥环,以便用户可以访问Ceph存储群集。
创建密钥环
当您使用“ 管理用户”部分中的过程创建用户时,您需要向Ceph客户端提供用户密钥,以便Ceph客户端可以检索指定用户的密钥并使用Ceph存储群集进行身份验证。Ceph客户端访问密钥环以查找用户名并检索用户密钥。
该ceph-authtool实用程序允许您创建密钥环。要创建空密钥环,请使用--create-keyring或-C。例如
在创建具有多个用户的密钥环时,我们建议使用群集名称(例如$cluster.keyring)作为密钥环文件名并将其保存在 /etc/ceph目录中,以便keyring配置默认设置将获取文件名
ceph-authtool -C /etc/ceph/ceph.keyring
使用单个用户创建密钥环时,建议使用群集名称,用户类型和用户名并将其保存在/etc/ceph目录中。例如,ceph.client.admin.keyring对于client.admin用户。
要创建密钥环/etc/ceph,您必须这样做root。这意味着该文件仅具有用户rw权限root,这在密钥环包含管理员密钥时是合适的。但是,如果您打算为特定用户或用户组使用密钥环,请确保执行chown或chmod建立适当的密钥环所有权和访问权限。
第一种创建用户方法:
当 添加用户到Ceph的存储集群,并且保存用户私钥环。
1. 创建client.george用户
ceph auth get-or-create client.george mon 'allow r' osd 'allow rw pool=liverpool' -o george.keyring

2. 将用户添加的密钥环中
ceph auth get client.george -o /etc/ceph/ceph.keyring

如果要将用户导入密钥环,可以使用ceph-authtool 指定目标密钥环和源密钥环
ceph-authtool /etc/ceph/ceph.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring
第二种创建用户方法:
创建密钥环并向密钥环添加新用户
sudo ceph-authtool -C /etc/ceph/ceph.keyring -n client.ringo --cap osd 'allow rwx' --cap mon 'allow rwx' --gen-key
新用户client.ringo仅在密钥环中。要将新用户添加到Ceph存储群集,必须将新用户添加到Ceph存储群集
ceph auth add client.ringo -i /etc/ceph/ceph.keyring
修改用户
要修改密钥环中用户记录的功能,请指定密钥环,然后指定用户的功能
ceph-authtool /etc/ceph/ceph.keyring -n client.ringo --cap osd 'allow rwx' --cap mon 'allow rwx'
要将用户更新为Ceph存储群集,必须将密钥环中的用户更新为Ceph存储群集中的用户条目
ceph auth import -i /etc/ceph/ceph.keyring
您也可以直接在群集中修改用户功能,将结果存储到密钥环文件中; 然后,将密钥环导入主 ceph.keyring文件
权限测试
[root@monitor1 ceph]# ceph auth get-or-create client.feng mon 'allow r' osd 'allow rw pool=liverpool' -o george.keyring [root@monitor1 ceph]# ceph auth get client.feng
exported keyring for client.feng
[client.feng]
key = AQAJYbBcGMVHGxAApIKfjyuV3ZuDhYtMIvx0UA==
caps mon = "allow r"
caps osd = "allow rw pool=liverpool" 导出到 /etc/ceph/ceph.client.feng.keyring
[root@monitor1 ceph]# ceph auth get client.feng -o /etc/ceph/ceph.client.feng.keyring
exported keyring for client.feng # 使用client.feng 用户测试 ceph -s
[root@monitor1 ceph]# ceph -s --name client.feng
cluster:
id: 7d518340-a55f--98ff-debb0d85e00b
health: HEALTH_OK services:
mon: daemons, quorum monitor1,monitor2,monitor3
mgr: monitor1(active), standbys: monitor3, monitor2
osd: osds: up, in data:
pools: pools, pgs
objects: objects, B
usage: GiB used, GiB / GiB avail
pgs: 创建第二个用户:
[root@monitor1 ceph]# ceph-authtool -C /etc/ceph/ceph.client.fengjian.keyring -n client.fengjian --cap osd 'allow x' --cap mon 'allow x' --gen-key
creating /etc/ceph/ceph.client.fengjian.keyring
导入到ceph 集群中
[root@monitor1 ceph]# ceph auth add client.fengjian -i /etc/ceph/ceph.client.fengjian.keyring
added key for client.fengjian 执行 ceph -s 测试
[root@monitor1 ceph]# ceph -s --name client.fengjian
Error EACCES: access denied
You have new mail in /var/spool/mail/root
数据放置概述
Ceph动态地存储,复制和重新平衡RADOS集群中的数据对象。由于许多不同的用户在不同的OSD中将对象存储在不同的池中,因此Ceph操作需要一些数据放置计划。Ceph中的主要数据放置规划概念包括:
- 池: Ceph在池中存储数据,池是用于存储对象的逻辑组。池管理放置组的数量,副本的数量以及池的CRUSH规则。要将数据存储在池中,您必须拥有一个具有池权限的经过身份验证的用户。Ceph可以快照池。有关其他详细信息,请参阅池。
- 放置组: Ceph将对象映射到放置组(PG)。放置组(PG)是逻辑对象池的分片或片段,它将对象作为一组放入OSD中。当Ceph将数据存储在OSD中时,放置组会减少每个对象元数据的数量。更多数量的放置组(例如,每个OSD 100个)可以实现更好的平衡。有关其他详细信息,请参阅 放置组。
- CRUSH地图: CRUSH是允许Ceph在没有性能瓶颈的情况下扩展的重要组成部分,不受可扩展性的限制,并且没有单点故障。CRUSH映射将群集的物理拓扑结构提供给CRUSH算法,以确定应存储对象及其副本的数据的位置,以及如何跨故障域执行此操作以增加数据安全性等。有关其他详细信息,请参阅CRUSH Maps。
- 平衡器:平衡器是一种功能,可以自动优化设备间PG的分布,实现平衡的数据分布,最大化可以存储在群集中的数据量,并在OSD之间均匀分配工作负载。
OSD相互监控
完成ceph配置后, ceph monitor 会报告 ceph 存储集群的当前状态,ceph monitor 通过要求每个ceph osd守护进程的报告以及从ceph osd daemon 接受有关相邻 ceph osd守护进程状态的报告来了解集群。 每个ceph osd 守护进程每6秒检查一次 其他ceph osd 守护进程的心跳, 如果相邻的osd 守护进程20内,没有显示心跳, 相邻的ceph osd 将报告给ceph monitor, ceph监视器将更新 ceph cluster map, http://docs.ceph.com/docs/master/rados/configuration/mon-osd-interaction/
添加删除monitor
为了实现高可用性,您应该运行至少具有三个监视器的生产Ceph集群。Ceph使用Paxos算法,这需要法定人数中的大多数监视器达成共识。使用Paxos,监视器无法确定仅使用两个监视器建立仲裁的多数。大多数监视器必须按如下计算:1:1,2:3,3:4,3:5,4:6等。
添加:
[root@monitor1 ceph-cluster]# cd /opt/ceph-cluster/ . 使用ceph-deploy 添加 node1 node2 monitor
[root@monitor1 ceph-cluster]# ceph-deploy mon create node1 node2 . ceph.conf配置文件中添加 monitor
[global]
fsid = 7d518340-a55f--98ff-debb0d85e00b
mon_initial_members = monitor1, monitor2, monitor3, node1, node2
mon_host = 172.16.230.21,172.16.230.22,172.16.230.23,172.16.230.24,172.16.230.25
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd pool default size =
osd pool default min size =
public network = 172.16.230.0/
cluster network = 1.1.1.0/ osd pool default pg num=
osd pool defaultpgp num=
[mon]
mgr modules = dashboard . 同步ceph.conf 配置文件到其他机器中
[root@monitor1 ceph-cluster]# ceph-deploy --overwrite-conf admin monitor1 monitor2 monitor3 node1 node2 node3 node4 node5 . 查看映射状态
[root@monitor1 ceph-cluster]# ceph -s
cluster:
id: 7d518340-a55f--98ff-debb0d85e00b
health: HEALTH_OK services:
mon: daemons, quorum monitor1,monitor2,monitor3,node1,node2
mgr: monitor1(active), standbys: monitor3, monitor2
osd: osds: up, in data:
pools: pools, pgs
objects: objects, B
usage: GiB used, GiB / GiB avail
pgs: active+clean
删除monitor
. 删除 monitor node1 node2 映射
[root@monitor1 ceph-cluster]# ceph-deploy mon destroy node1 node2 . 删除配置文件中
[root@monitor1 ceph-cluster]# cat ceph.conf
[global]
fsid = 7d518340-a55f--98ff-debb0d85e00b
mon_initial_members = monitor1, monitor2, monitor3
mon_host = 172.16.230.21,172.16.230.22,172.16.230.23
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd pool default size =
osd pool default min size =
public network = 172.16.230.0/
cluster network = 1.1.1.0/ osd pool default pg num=
osd pool defaultpgp num= . 同步配置文件
ceph-deploy --overwrite-conf admin monitor1 monitor2 monitor3 node1 node2 node3 node4 node5
添加OSD
1. 使用 SSD 硬盘的 sdb分区 sdb3 sdb4 当作 rocksdb 的 wal 和 db(元数据),对sdb进行继续分区
[root@node5 ~]# fdisk /dev/sdb
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Welcome to fdisk (util-linux 2.23.). Changes will remain in memory only, until you decide to write them.
Be careful before using the write command. Command (m for help): n
Partition number (-, default ):
First sector (-, default ):
Last sector, +sectors or +size{K,M,G,T,P} (-, default ): +10G
Created partition Command (m for help): n
Partition number (-, default ):
First sector (-, default ):
Last sector, +sectors or +size{K,M,G,T,P} (-, default ): +10G
Created partition Command (m for help): w
The partition table has been altered! Calling ioctl() to re-read partition table. WARNING: Re-reading the partition table failed with error : Device or resource busy.
The kernel still uses the old table. The new table will be used at
the next reboot or after you run partprobe() or kpartx()
Syncing disks. [root@node5 ~]# partprobe
2. 使用zap 清除新硬盘上的数据
[root@monitor1 ceph-cluster]# ceph-deploy disk zap node1 /dev/sdd
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.): /usr/bin/ceph-deploy disk zap node1 /dev/sdd
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] debug : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : zap
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x159ba28>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] host : node1
[ceph_deploy.cli][INFO ] func : <function disk at 0x1584c08>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] disk : ['/dev/sdd']
[ceph_deploy.osd][DEBUG ] zapping /dev/sdd on node1
[node1][DEBUG ] connected to host: node1
[node1][DEBUG ] detect platform information from remote host
[node1][DEBUG ] detect machine type
[node1][DEBUG ] find the location of an executable
[ceph_deploy.osd][INFO ] Distro info: CentOS Linux 7.3. Core
[node1][DEBUG ] zeroing last few blocks of device
[node1][DEBUG ] find the location of an executable
[node1][INFO ] Running command: /usr/sbin/ceph-volume lvm zap /dev/sdd
[node1][DEBUG ] --> Zapping: /dev/sdd
[node1][DEBUG ] --> --destroy was not specified, but zapping a whole device will remove the partition table
[node1][DEBUG ] Running command: /usr/sbin/wipefs --all /dev/sdd
[node1][DEBUG ] Running command: /bin/dd if=/dev/zero of=/dev/sdd bs=1M count=
[node1][DEBUG ] stderr: + records in
[node1][DEBUG ] + records out
[node1][DEBUG ] bytes ( MB) copied
[node1][DEBUG ] stderr: , 3.00327 s, 3.5 MB/s
[node1][DEBUG ] --> Zapping successful for: <Raw Device: /dev/sdd>
[root@monitor1 ceph-cluster]# ceph-deploy disk zap node1 /dev/sdd
[root@monitor1 ceph-cluster]# ceph-deploy disk zap node2 /dev/sdd
[root@monitor1 ceph-cluster]# ceph-deploy disk zap node3 /dev/sdd
[root@monitor1 ceph-cluster]# ceph-deploy disk zap node4 /dev/sdd
[root@monitor1 ceph-cluster]# ceph-deploy disk zap node5 /dev/sdd
添加osd节点
###还是会报错,需要卸载,删除lv, vg, pv, 删除日志, 删除rm -rf /var/lib/ceph/osd/ceph-$id} -rf
[root@monitor1 ceph-cluster]# ceph-deploy osd create node1 --bluestore --data /dev/sdd --block-db /dev/sdb3 --block-wal /dev/sdb4 [root@monitor1 ceph-cluster]# ceph-deploy osd create node2 --bluestore --data /dev/sdd --block-db /dev/sdb3 --block-wal /dev/sdb4 [root@monitor1 ceph-cluster]# ceph-deploy osd create node3 --bluestore --data /dev/sdd --block-db /dev/sdb3 --block-wal /dev/sdb4 [root@monitor1 ceph-cluster]# ceph-deploy osd create node4 --bluestore --data /dev/sdd --block-db /dev/sdb3 --block-wal /dev/sdb4 [root@monitor1 ceph-cluster]# ceph-deploy osd create node5 --bluestore --data /dev/sdd --block-db /dev/sdb3 --block-wal /dev/sdb4
列出node节点 硬盘情况
[root@monitor1 ceph-cluster]# ceph-deploy disk list node1
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.): /usr/bin/ceph-deploy disk list node1
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] debug : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : list
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x1b27a28>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] host : ['node1']
[ceph_deploy.cli][INFO ] func : <function disk at 0x1b10c08>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[node1][DEBUG ] connected to host: node1
[node1][DEBUG ] detect platform information from remote host
[node1][DEBUG ] detect machine type
[node1][DEBUG ] find the location of an executable
[node1][INFO ] Running command: fdisk -l
[node1][INFO ] Disk /dev/sdb: 75.2 GB, bytes, sectors
[node1][INFO ] Disk /dev/sdc: 53.7 GB, bytes, sectors
[node1][INFO ] Disk /dev/sda: 42.9 GB, bytes, sectors
[node1][INFO ] Disk /dev/sdd: 42.9 GB, bytes, sectors
[node1][INFO ] Disk /dev/mapper/cl-root: 37.7 GB, bytes, sectors
[node1][INFO ] Disk /dev/mapper/cl-swap: MB, bytes, sectors
[node1][INFO ] Disk /dev/mapper/ceph--7104aa88--187b--455a--933b--fa44514ea24f-osd--block--49bdb336----43ba----7f1a23e570bc: 53.7 GB, bytes, sectors
[node1][INFO ] Disk /dev/mapper/ceph--cae55dd8--599b----a179--48de13bf6204-osd--block--edacf21d--fdf3----af0f--d07422fc8660: 42.9 GB, bytes, sectors
删除osd(mimic 版本) 节点
1. 查询osd 结构
[root@monitor1 ceph-cluster]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
- 0.53696 root default
- 0.10739 host node1
hdd 0.05859 osd. up 1.00000 1.00000
hdd 0.04880 osd. up 1.00000 1.00000
- 0.10739 host node2
hdd 0.05859 osd. up 1.00000 1.00000
hdd 0.04880 osd. up 1.00000 1.00000
- 0.10739 host node3
hdd 0.05859 osd. up 1.00000
hdd 0.04880 osd. up 1.00000
- 0.10739 host node4
hdd 0.05859 osd. up 1.00000 1.00000
hdd 0.04880 osd. up 1.00000 1.00000
- 0.10739 host node5
hdd 0.05859 osd. up 1.00000 1.00000
hdd 0.04880 osd. up 1.00000 1.00000
osd. down 1.00000
有时,通常在主机很少的“小”集群中(例如,使用小型测试集群),采用outOSD 的事实可能会产生一个CRUSH转角情况,其中一些PG仍然停留在该 active+remapped状态。如果您在这种情况下,您应该使用以下标记OSD in:
[root@monitor1 ceph-cluster]# ceph osd in osd.
返回到初始状态然后,不是标记out OSD,而是将其权重设置为0
[root@monitor1 ceph-cluster]# ceph osd crush reweight osd.
2. 地址osd进程
将OSD从群集中取出后,它可能仍在运行。也就是说,OSD可以是up和out。在从配置中删除OSD之前,必须先停止OSD
[root@monitor1 ceph-cluster]# ssh node1
[root@monitor1 ceph-cluster]# systemctl stop ceph-osd@
3. 删除
从群集映射中删除OSD,删除其身份验证密钥,从OSD映射中删除OSD,并从ceph.conf文件中删除OSD 。如果主机有多个驱动器,则可能需要通过重复此过程为每个驱动器删除OSD。
[root@monitor1 ceph-cluster]# ceph osd purge --yes-i-really-mean-it
4. 修改ceph.conf 配置文件,删除 osd.10 相关信息
5. 同步ceph.conf 到其他节点
############################################
删除老版本osd
1. 关闭osd.10 进程
systemctl stop ceph-osd@
2. 卸载挂载
umount /var/lib/ceph/osd/ceph-
3. 把osd.10 下线
ceph osd out osd.
4. 从CRUSH映射中删除OSD
ceph osd crush remove osd.
5.删除osd验证密钥
ceph auth del osd.
6. 删除osd
ceph osd rm osd.
更换osd节点硬盘
当硬盘发生故障,或者管理员想要使用新的后端重新部署osd时, 需要更换osd,与删除 osd不通,在osd被销毁更换后,需要更换osd的id和crush映射
1. 模拟osd0 宕机
[root@node1 ~]# systemctl stop ceph-osd@
[root@node1 ~]# df -Th
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/cl-root xfs 36G .4G 29G % /
devtmpfs devtmpfs .9G .9G % /dev
tmpfs tmpfs .9G 84K .9G % /dev/shm
tmpfs tmpfs .9G 8.9M .9G % /run
tmpfs tmpfs .9G .9G % /sys/fs/cgroup
/dev/sda1 xfs 1014M 174M 841M % /boot
tmpfs tmpfs .9G 24K .9G % /var/lib/ceph/osd/ceph-
tmpfs tmpfs .9G 24K .9G % /var/lib/ceph/osd/ceph-
tmpfs tmpfs 783M 16K 783M % /run/user/
tmpfs tmpfs 783M 783M % /run/user/
[root@node1 ~]# umount /var/lib/ceph/osd/ceph-/
2. 直接删除 /dev/sdc
root@node1 ~]# pvs
/dev/ceph-7104aa88-187b-455a-933b-fa44514ea24f/osd-block-49bdb336--43ba--7f1a23e570bc: read failed after of at : Input/output error
/dev/ceph-7104aa88-187b-455a-933b-fa44514ea24f/osd-block-49bdb336--43ba--7f1a23e570bc: read failed after of at : Input/output error
/dev/ceph-7104aa88-187b-455a-933b-fa44514ea24f/osd-block-49bdb336--43ba--7f1a23e570bc: read failed after of at : Input/output error
/dev/ceph-7104aa88-187b-455a-933b-fa44514ea24f/osd-block-49bdb336--43ba--7f1a23e570bc: read failed after of at : Input/output error
PV VG Fmt Attr PSize PFree
/dev/sda2 cl lvm2 a-- .00g 4.00m
/dev/sdd ceph-cae55dd8-599b--a179-48de13bf6204 lvm2 a-- .00g 删除过时的/dev/sdX设备节点并清理过时的设备映射器节点 [root@node1 ~]# dmsetup remove /dev/myvg/*
[root@node1 ~]# echo 1 > /sys/block/sdb/device/delete
2. 销毁OSD
[root@monitor1 ceph-cluster]# ceph osd destroy --yes-i-really-mean-it
destroyed osd.
3. 更换硬盘
4.擦出osd 新硬盘数据
[root@node1 ~]# ceph-volume lvm zap /dev/sde
--> Zapping: /dev/sde
--> --destroy was not specified, but zapping a whole device will remove the partition table
Running command: /usr/sbin/wipefs --all /dev/sde
Running command: /bin/dd if=/dev/zero of=/dev/sde bs=1M count=
stderr: + records in
+ records out
bytes ( MB) copied
stderr: , 0.186683 s, 56.2 MB/s
--> Zapping successful for: <Raw Device: /dev/sde>
You have new mail in /var/spool/mail/root
5. 使用先前销毁的 osd id 添加到集群中
[root@node1 ~]# ceph-volume lvm create --osd-id --data /dev/sde --bluestore --block.db /dev/sdb1 --block.wal /dev/sdb2
6. 启动osd.0 节点
[root@node1 ~]# systemctl start ceph-osd@
7. 查看node1 osd 0 状态
/var/lib/ceph/osd/ceph-0 为替换的osd [root@node1 ~]# df -Th
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/cl-root xfs 36G .4G 29G % /
devtmpfs devtmpfs .9G .9G % /dev
tmpfs tmpfs .9G 84K .9G % /dev/shm
tmpfs tmpfs .9G 8.9M .9G % /run
tmpfs tmpfs .9G .9G % /sys/fs/cgroup
/dev/sda1 xfs 1014M 174M 841M % /boot
tmpfs tmpfs .9G 24K .9G % /var/lib/ceph/osd/ceph-
tmpfs tmpfs 783M 16K 783M % /run/user/
tmpfs tmpfs 783M 783M % /run/user/
tmpfs tmpfs .9G 48K .9G % /var/lib/ceph/osd/ceph-
8. monitor 上查看
如果osd.0 为down状态
执行 in 加入映射中
[root@monitor1 ceph-cluster]# ceph osd in 查看
[root@monitor1 ceph-cluster]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
- 0.53696 root default
- 0.10739 host node1
hdd 0.05859 osd. up 1.00000 1.00000
hdd 0.04880 osd. up 1.00000 1.00000
- 0.10739 host node2
hdd 0.05859 osd. up 1.00000 1.00000
hdd 0.04880 osd. up 1.00000 1.00000
- 0.10739 host node3
hdd 0.05859 osd. up 1.00000 1.00000
hdd 0.04880 osd. up 1.00000 1.00000
- 0.10739 host node4
hdd 0.05859 osd. up 1.00000 1.00000
hdd 0.04880 osd. up 1.00000 1.00000
- 0.10739 host node5
hdd 0.05859 osd. up 1.00000 1.00000
hdd 0.04880 osd. up 1.00000 1.00000
配置文件和密钥管理
使用ceph-deploy,可以将客户端管理密钥和Ceph配置文件提供给其他主机,以便主机上的用户可以将ceph 命令行用作管理用户。
. 要使主机能够以管理员权限执行ceph 命令,请使用admin命令
ceph-deploy admin monitor1 monitor2 monitor3 node1 node2 node3 node4 node5 . 将更新的配置文件发送到集群中的主机
ceph-deploy config push monitor1 monitor2 monitor3 node1 node2 node3 node4 node5 . 要将集群中ceph的配置文件 拉取过来
ceph-deploy config pull node1 .....
POOL FULL
一个或者多个池已经达到起配合, 不再允许写入
查看池的配合和利用率
[root@monitor1 ceph-cluster]# ceph df detail
GLOBAL:
SIZE AVAIL RAW USED %RAW USED OBJECTS
GiB GiB GiB 21.20
POOLS:
NAME ID QUOTA OBJECTS QUOTA BYTES USED %USED MAX AVAIL OBJECTS DIRTY READ WRITE RAW USED
senyintpool N/A GiB B GiB B B B
提高池配额
[root@monitor1 ceph-cluster]# ceph osd pool set-quota senyintpool max_bytes $(( * * * ))
查看配额
[root@monitor1 ceph-cluster]# ceph osd pool get-quota senyintpool
quotas for pool 'senyintpool':
max objects: N/A
max bytes : GiB
检查集群的使用情况统计信息
[root@monitor1 ceph-cluster]# ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
GiB GiB GiB 21.20
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
senyintpool B GiB 输出的RAW STORAGE部分概述了群集管理的存储量。 GLOBAL: 全局(或集群的总数)
SIZE:群集管理的存储容量。
AVAIL:群集中可用的可用空间量。
RAW USED:用户数据,内部开销或预留容量消耗的原始存储量。
%RAW USED:使用的原始存储空间的百分比。将此数字与the一起使用,以确保您没有达到群集的容量。则名义使用量将为1MB,但实际使用量可能为2MB或更多,具体取决于副本,克隆和快照的数量。 POOLS :
NAME:池的名称。
ID:池ID。
USED:以千字节为单位存储的名义数据量,除非该数字附加M表示兆字节或G表示千兆字节。
%USED:每个池使用的名义存储百分比。
MAX AVAIL:可以写入此池的名义数据量的估计值。
OBJECTS:每个池存储的名义对象数。
PG数量
少于5个OSD设置pg_num为128
5到10个OSD设置pg_num为512
10到50个OSD设置pg_num为1024
如果您有超过50个OSD,您需要了解权衡以及如何自己计算pg_num值
存储具有吞吐量限制,他影响读写性能和可扩展性能, 所以存储系统都支持条带化以增加存储系统的吞吐量并提升性能, 条带化最常见的的方式是做raid,
在磁盘阵列中,数据是以条带的方式贯穿在磁盘阵列所有硬盘中,ceph条带化后,将获得N个带有唯一object的id, object id 是进行线性映射生成的。

Ceph客户端将计算对象应该在哪个放置组中。它通过对对象ID进行散列并根据定义的池中的PG数量和池的ID应用操作来完成此操作
创建池
[root@monitor1 ceph-cluster]# ceph osd pool create fengpool
设置pool 配额
设置fengpool 最大的对象为10000个
[root@monitor1 ceph-cluster]# ceph osd pool set-quota fengpool max_objects
删除pool配额, 值设置为0
[root@monitor1 ceph-cluster]# ceph osd pool set-quota fengpool max_objects
删除池
[root@monitor1 ceph-cluster]# ceph osd pool delete fengpool --yes-i-really-really-mean-it
如果自己创建的池创建了自己的规则,则应该考虑在不再需要池时将其删除
ceph osd pool get {pool-name} crush_rule
如果您创建的用户严格使用不再存在的池,则应考虑删除这些用户
ceph auth ls | grep -C fengpool
ceph auth del {user}
重命名池
ceph osd pool rename {current-pool-name} {new-pool-name}
统计池的信息
[root@monitor1 ceph-cluster]# rados df
获取特定池的io 信息
[root@monitor1 ceph-cluster]# ceph osd pool stats fengpool
pool fengpool id
nothing is going on
制作池的快照
ceph osd pool mksnap {pool-name} {snap-name}
删除池的快照
ceph osd pool rmsnap {pool-name} {snap-name}
设置 pool的对象副本数
ceph osd pool set fengpool size
crush map
CRUSH算法确定如何存储和通过计算数据存储位置检索数据。CRUSH使Ceph客户能够直接与OSD通信,而不是通过集中式服务器或代理。通过算法确定的存储和检索数据的方法,Ceph可以避免单点故障,性能瓶颈以及对其可扩展性的物理限制。
CRUSH需要集群的映射,并使用CRUSH映射在OSD中伪随机存储和检索数据,并在集群中统一分布数据
CRUSH地图包含OSD列表,用于将设备聚合到物理位置的“存储桶”列表,以及告诉CRUSH如何在Ceph集群池中复制数据的规则列表。通过反映安装的基础物理组织,CRUSH可以建模 - 从而解决相关设备故障的潜在来源。典型的来源包括物理接近,共享电源和共享网络。通过将此信息编码到群集映射中,CRUSH放置策略可以跨不同的故障域分隔对象副本,同时仍保持所需的分布。例如,为了解决并发故障的可能性,可能需要确保数据副本在使用不同架子,机架,电源,控制器和/或物理位置的设备上。
部署OSD时,它们会自动放置在CRUSH映射中,该映射位于host以其运行的主机的主机名命名的节点下 。这与默认的CRUSH故障域相结合,可确保副主机或擦除代码分片在主机之间分离,单个主机故障不会影响可用性。但是,对于较大的群集,管理员应仔细考虑他们选择的故障域。例如,跨机架分离副本对于中型到大型集群来说很常见。
CRUSH 结构
CRUSH映射包括描述集群物理拓扑的层次结构,以及定义关于如何在这些设备上放置数据的策略的一组规则。层次结构ceph-osd在叶子上有设备(守护进程),内部节点对应于其他物理特征或分组:主机,机架,行,数据中心等
DEVICES
设备是ceph-osd可以存储数据的单独守护程序。对于群集中的每个OSD守护程序,通常会在此处定义一个。设备由id(非负整数)和名称标识,通常osd.N在哪里N是设备ID。
设备还可以具有与它们相关联的设备类(例如, hdd或ssd),允许它们通过压溃规则方便地成为目标。
TYPES AND BUCKETS
存储桶是层次结构中内部节点的CRUSH术语:主机,机架,行等.CRUSH映射定义了一系列用于描述这些节点的类型。默认情况下,这些类型包括:
osd (or device)
host
chassis
rack
row
pdu
pod
room
datacenter
region
root

crush rule
规则定义有关如何跨层次结构中的设备分布数据的策略
查看集群定义的规则
[root@monitor1 ~]# ceph osd crush rule ls
replicated_rule
查看规则内容
[root@monitor1 ~]# ceph osd crush rule dump
[
{
"rule_id": ,
"rule_name": "replicated_rule",
"ruleset": ,
"type": ,
"min_size": ,
"max_size": ,
"steps": [
{
"op": "take",
"item": -,
"item_name": "default"
},
{
"op": "chooseleaf_firstn",
"num": ,
"type": "host"
},
{
"op": "emit"
}
]
}
]
手动编辑crush 地图
. 获取CRUSH map。
. 反编译 CRUSH map。
. 至少编辑一个设备,存储桶和规则。
. 重新编译 CRUSH映射。
. 设置CRUSH map。
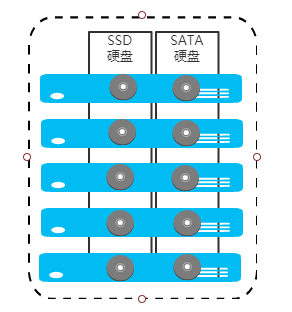
crush 设计 SSD, SATA 混合实例
存储节点上既有STAT硬盘 也有SSD盘, 把各个节点的SSD 和 SATA整合成独立的存储池, 为不同的应用提供不同的性能
[root@monitor1 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
- 0.53696 root default
- 0.10739 host node1
hdd 0.05859 osd. up 1.00000 1.00000
hdd 0.04880 osd. up 1.00000 1.00000
- 0.10739 host node2
hdd 0.05859 osd. up 1.00000 1.00000
hdd 0.04880 osd. up 1.00000 1.00000
- 0.10739 host node3
hdd 0.05859 osd. up 1.00000 1.00000
hdd 0.04880 osd. up 1.00000 1.00000
- 0.10739 host node4
hdd 0.05859 osd. up 1.00000 1.00000
hdd 0.04880 osd. up 1.00000 1.00000
- 0.10739 host node5
hdd 0.05859 osd. up 1.00000 1.00000
hdd 0.04880 osd. up 1.00000 1.00000
osd[0 - 4] 为SSD, osd[5-9] 为SATA硬盘
https://ceph.com/community/new-luminous-crush-device-classes/
luminous版本的ceph新增了一个功能crush class,这个功能又可以称为磁盘智能分组。因为这个功能就是根据磁盘类型自动的进行属性的关联,然后进行分类。无需手动修改crushmap,极大的减少了人为的操作

ceph中的每个osd设备都可以选择一个class类型与之关联,默认情况下,在创建osd的时候会自动识别设备类型,然后设置该设备为相应的类。通常有三种class类型:hdd,ssd,nvme。
查询 crush class
[root@monitor1 tmp]# ceph osd crush class ls
[
"hdd"
]
通过对 ceph osd tree 查看 所有的 class 类都是 hdd, 如果自动设备检测出错,可以手动修改
#删除 class 类
[root@monitor1 tmp]# ceph osd crush rm-device-class osd.
[root@monitor1 tmp]# ceph osd crush rm-device-class osd.
[root@monitor1 tmp]# ceph osd crush rm-device-class osd.
[root@monitor1 tmp]# ceph osd crush rm-device-class osd.
[root@monitor1 tmp]# ceph osd crush rm-device-class osd.
手动添加ssd类
[root@monitor1 tmp]# ceph osd crush set-device-class ssd osd.
[root@monitor1 tmp]# ceph osd crush set-device-class ssd osd.
[root@monitor1 tmp]# ceph osd crush set-device-class ssd osd.
[root@monitor1 tmp]# ceph osd crush set-device-class ssd osd.
[root@monitor1 tmp]# ceph osd crush set-device-class ssd osd.
修改后的结果
[root@monitor2 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
- 0.53696 root default
- 0.10739 host node1
hdd 0.04880 osd. up 1.00000 1.00000
ssd 0.05859 osd. up 1.00000 1.00000
- 0.10739 host node2
hdd 0.04880 osd. up 1.00000 1.00000
ssd 0.05859 osd. up 1.00000 1.00000
- 0.10739 host node3
hdd 0.04880 osd. up 1.00000 1.00000
ssd 0.05859 osd. up 1.00000 1.00000
- 0.10739 host node4
hdd 0.04880 osd. up 1.00000 1.00000
ssd 0.05859 osd. up 1.00000 1.00000
- 0.10739 host node5
hdd 0.04880 osd. up 1.00000 1.00000
ssd 0.05859 osd. up 1.00000 1.00000
查看crush class
[root@monitor1 tmp]# ceph osd crush class ls
[
"hdd",
"ssd"
]
把含有SSD 和SATA 聚合,并创建新的root层级,并保留默认的层级关系, 设计图如下
4. 创建一个优先使用ssd 规则的 crush-rule
osd crush rule create-replicated <name> <root> <type> {<class>} create crush rule <name> for replicated pool to start from <root>,
replicate across buckets of type <type>, using a choose mode of <firstn|
indep> (default firstn; indep best for erasure pools)
[root@monitor1 tmp]# ceph osd crush rule create-replicated ssd-rule default host ssd
5.查看crush rule
[root@monitor1 tmp]# ceph osd crush rule ls
replicated_rule
ssd-rule
6 获取 当前的crush map
[root@monitor1 tmp]# ceph osd getcrushmap -o /tmp/mycrushmap
7. 反编译crush map
[root@monitor1 tmp]# crushtool -d /tmp/mycrushmap > /tmp/mycrushmap.txt
8. 查看crush map 文本
[root@monitor1 tmp]# cat mycrushmap.txt
# begin crush map
tunable choose_local_tries
tunable choose_local_fallback_tries
tunable choose_total_tries
tunable chooseleaf_descend_once
tunable chooseleaf_vary_r
tunable chooseleaf_stable
tunable straw_calc_version
tunable allowed_bucket_algs # devices
device osd. class ssd
device osd. class ssd
device osd. class ssd
device osd. class ssd
device osd. class ssd
device osd. class hdd
device osd. class hdd
device osd. class hdd
device osd. class hdd
device osd. class hdd # types
type osd
type host
type chassis
type rack
type row
type pdu
type pod
type room
type datacenter
type region
type root # buckets
host node1 {
id - # do not change unnecessarily
id - class hdd # do not change unnecessarily
id - class ssd # do not change unnecessarily
# weight 0.107
alg straw2
hash # rjenkins1
item osd. weight 0.059
item osd. weight 0.049
}
host node2 {
id - # do not change unnecessarily
id - class hdd # do not change unnecessarily
id - class ssd # do not change unnecessarily
# weight 0.107
alg straw2
hash # rjenkins1
item osd. weight 0.059
item osd. weight 0.049
}
host node3 {
id - # do not change unnecessarily
id - class hdd # do not change unnecessarily
id - class ssd # do not change unnecessarily
# weight 0.107
alg straw2
hash # rjenkins1
item osd. weight 0.059
item osd. weight 0.049
}
host node4 {
id - # do not change unnecessarily
id - class hdd # do not change unnecessarily
id - class ssd # do not change unnecessarily
# weight 0.107
alg straw2
hash # rjenkins1
item osd. weight 0.059
item osd. weight 0.049
}
host node5 {
id - # do not change unnecessarily
id - class hdd # do not change unnecessarily
id - class ssd # do not change unnecessarily
# weight 0.107
alg straw2
hash # rjenkins1
item osd. weight 0.059
item osd. weight 0.049
}
root default {
id - # do not change unnecessarily
id - class hdd # do not change unnecessarily
id - class ssd # do not change unnecessarily
# weight 0.537
alg straw2
hash # rjenkins1
item node1 weight 0.107
item node2 weight 0.107
item node3 weight 0.107
item node4 weight 0.107
item node5 weight 0.107
} # rules
rule replicated_rule {
id
type replicated
min_size
max_size
step take default
step chooseleaf firstn type host
step emit
}
rule ssd-rule {
id
type replicated
min_size
max_size
step take default class ssd
step chooseleaf firstn type host
step emit
} # end crush map
看到 host 下 多出来了 id -6 class hdd, root default 下多了一个 id -18 class ssd ,并且 rule ssd-rule id 为1
9. 创建一个使用 ssd-rule 规则的存储池
osd pool create <poolname> <int[-]> {<int[-]>} {replicated|erasure} create pool
{<erasure_code_profile>} {<rule>} {<int>}
[root@monitor1 tmp]# ceph osd pool create cinyipool ssd-rule
pool 'cinyipool' created
10. 查询池信息, crush_rule 1
[root@monitor1 tmp]# ceph osd pool ls detail
pool 'senyintpool' replicated size min_size crush_rule object_hash rjenkins pg_num pgp_num last_change flags hashpspool max_bytes stripe_width
pool 'fengpool' replicated size min_size crush_rule object_hash rjenkins pg_num pgp_num last_change flags hashpspool stripe_width
pool 3 'cinyipool' replicated size 2 min_size 1 crush_rule 1 object_hash rjenkins pg_num 128 pgp_num 128 last_change 201 flags hashpspool stripe_width 0
11. 创建对象测试cinyipool
[root@monitor1 tmp]# rados -p cinyipool ls
[root@monitor1 ~]# rados -p cinyipool put test ceph-deploy-ceph.log
[root@monitor1 ~]# rados -p cinyipool ls
test
12. 查看对象osd组
[root@monitor1 ~]# ceph osd map cinyipool test
osdmap e203 pool 'cinyipool' () object 'test' -> pg .40e8aab5 (3.35) -> up ([,], p2) acting ([,], p2)
############################################
完全手动管理crush, 需要在/etc/ceph/ceph.conf配置中将挂钩关掉
osd_crush_update_on_start=false
#######################################
crsh 一致性hash
1. 故障域隔离, 同份数据的不同副本分配到不同的故障域,降低数据损坏分线
2. 负载均衡, 数据能够均匀的分布在磁盘容量不等的存储几点,避免部分节点空闲部分节点超载,从而影响系统性能。
3. 控制节点加入离开时引起的数量迁移量,当节点离开时,最优的数据迁移是只有离线节点上的数据被迁移到其他节点,正常的工作节点数据不会迁移
添加删除monitor
此过程创建ceph-mon数据目录,检索监视器映射并监视密钥环,并将ceph-mon守护程序添加到群集。如果这只导致两个监视器守护程序,则可以通过重复此过程添加更多监视器,直到您有足够数量的ceph-mon 守护程序来实现仲裁
1 .在安装的新monitor机器上创建目录
[root@monitor1 mon]# ssh node1
[root@node1 mon]# mkdir -p /var/lib/ceph/mon/ceph-monitor4
2. 创建一个临时目录{tmp} 保留创建过程中的文件,此目录应该与上一步中创建的监视器默认目录不同,并且可以执行删除
[root@node1 ~]# mkdir /root/tmp
3. 检索监视器的密钥环,其中{tmp}是检索到的密钥环的路径,并且{key-filename}是包含检索到的监视器密钥的文件的名称
[root@node1 tmp]# ceph auth get mon. -o tmp/client.monitornode1.keyring [root@node1 tmp]# cat client.monitornode1.keyring
[mon.]
key = AQCXta1cAAAAABAADjzWdjX1BWVg6WxMYgru4w==
caps mon = "allow *"
4. 检索monitor映射
[root@node1 tmp]# ceph mon getmap -o /root/tmp/map-node1monitor
5. 创建监视器,指定 keyring monitor map
sudo ceph-mon -i {mon-id} --mkfs --monmap {tmp}/{map-filename} --keyring {tmp}/{key-filename}
root@node1 tmp]# ceph-mon -i monitor4 --mkfs --monmap /root/tmp/map-node1monitor --keyring /root/tmp/client.monitornode1.keyring
6. 查看monitor map
[root@node1 tmp]# ceph mon dump
dumped monmap epoch
epoch
fsid 7d518340-a55f--98ff-debb0d85e00b
last_changed -- ::20.594821
created -- ::43.338493
: 172.16.230.21:/ mon.monitor1
: 172.16.230.22:/ mon.monitor2
: 172.16.230.23:/ mon.monitor3
7. 启动监视器,新monitor将自动加入集群, 守护进程需要通过参数绑定到那个地址 --public-addr {ip:port}
[root@node1 tmp]# ceph-mon -i monitor4 --public-addr 172.16.230.24:6789
8. 再次查看 monitor map, monitor4 已经加入到了monitor map中
[root@node1 tmp]# ceph mon dump
dumped monmap epoch
epoch
fsid 7d518340-a55f--98ff-debb0d85e00b
last_changed -- ::23.309986
created -- ::43.338493
: 172.16.230.21:/ mon.monitor1
: 172.16.230.22:/ mon.monitor2
: 172.16.230.23:/ mon.monitor3
: 172.16.230.24:/ mon.monitor4
9. 在ceph admin 修改ceph.conf,添加 [mon.monitor4]
[root@monitor1 ceph-cluster]# cat /etc/ceph/ceph.conf
[global]
fsid = 7d518340-a55f--98ff-debb0d85e00b
mon_initial_members = monitor1, monitor2, monitor3, monitor4 # 添加monitor4
mon_host = 172.16.230.21,172.16.230.22,172.16.230.23
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd pool default size =
osd pool default min size =
public network = 172.16.230.0/
cluster network = 1.1.1.0/ osd pool default pg num=
osd pool defaultpgp num=
[mon]
mgr modules = dashboard [mon.monitor4]
host=node1 #指定host 主机名为node1
addr=172.16.230.24:6789
删除监视器:
删除监视器(手动)
1. 停止进程
[root@node1 tmp]# ps -ef | grep ceph
ceph Apr16 ? :: /usr/bin/ceph-osd -f --cluster ceph --id --setuser ceph --setgroup ceph
ceph Apr16 ? :: /usr/bin/ceph-osd -f --cluster ceph --id --setuser ceph --setgroup ceph
root : ? :: ceph-mon -i monitor4 --public-addr 172.16.230.24: # 使用 systemctl stop ceph-mon@monitor4 无法关闭,直接kill
[root@node1 tmp]# kill -
2. 从mon集群map 删除monitor
[root@monitor1 ceph-cluster]# ceph mon rm monitor4 [root@monitor1 ceph-cluster]# ceph mon dump
dumped monmap epoch
epoch
fsid 7d518340-a55f--98ff-debb0d85e00b
last_changed -- ::49.912011
created -- ::43.338493
: 172.16.230.21:/ mon.monitor1
: 172.16.230.22:/ mon.monitor2
: 172.16.230.23:/ mon.monitor3
3 . 修改配置文件
4. 同步配置文件
删除集群中不健康的monitor
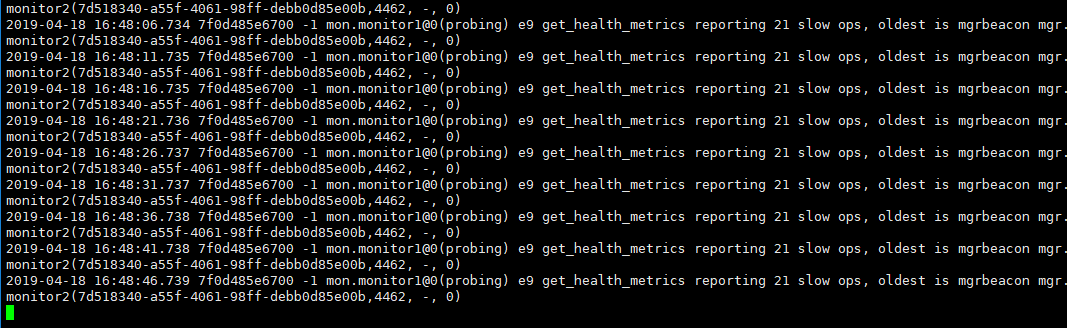
模拟monitor 集群中 , monitor2 monitor3 宕机, monitor1 正常, 此时集群不可用,以下为日志
1. 在存活的monitor1 关闭进程
[root@monitor1 ~]# systemctl stop ceph-mon@monitor1
2. . 在存活的monitor1 提取mon map
[root@monitor1 ~]# ceph-mon -i monitor1 --extract-monmap /tmp/monmap
3. 删除未存活的有问题的monitor(monitor2 monitor3 删除)
[root@monitor1 ~]# monmaptool /tmp/monmap --rm monitor2
[root@monitor1 ~]# monmaptool /tmp/monmap --rm monitor3
4. 把存活的monitor1 注入到 mon map中。monitor1
[root@monitor1 ~]# ceph-mon -i monitor1 --inject-monmap /tmp/monmap
5. 启动monitor1 mon进程
[root@monitor1 ~]# systemctl start ceph-mon@monitor1
6. 确认ceph 状态,
[root@monitor1 ~]# ceph -s
cluster:
id: 7d518340-a55f--98ff-debb0d85e00b
health: HEALTH_OK services:
mon: daemons, quorum monitor1 #变成一个monitor1。
mgr: monitor1(active), standbys: monitor3, monitor2
osd: osds: up, in data:
pools: pools, pgs
objects: objects, KiB
usage: GiB used, GiB / GiB avail
pgs: active+clean
7. 修改ceph.conf, 并且同步配置文件。
常用命令:
查看mon leader
ceph quorum_status
显示ceph密钥
ceph auth ls
显示pg映射
ceph pg dump
显示osd 状态
ceph osd stat
把crush map 导出到文件
ceph osd getcrushmap -o file
显示osd映射
ceph osd dump
显示osd tree
ceph osd tree
删除osd
ceph osd rm osd.
osd down
ceph osd down osd.0
marked down osd.0.
osd out
ceph osd out osd.
osd in
ceph osd in osd.
停止rados 的重新平衡
当磁盘发生故障,rados 会重新平衡,为了尽量减小因为数据迁移造成的性能下降,需要临时关闭数据迁移,再新的osd添加完成后,再启动
[root@monitor1 ceph-cluster]# ceph osd set --help
osd set full|pause|noup|nodown|noout|noin|nobackfill|norebalance|norecover noout mon在过300秒(mon_osd_down_out_interval)后 自动将down 的osd 标记为out, 一旦out数据就会迁移,(使用noout 防止数据迁移)
nobackfill 防止集群进行数据回填操作
norecover 防止硬盘数据发生恢复。 1. 设置集群为noout
ceph osd set noout
ceph osd set nobackfill
ceph osd set norecover . 更换硬盘后, 添加osd节点
维护完成后,重新启动osd
ceph osd unset noout
ceph osd unset nobackfill
ceph osd unset norecover
PG问题处理:
创建一个池
[root@monitor1 ceph-cluster]# ceph osd pool create fengjianpool
查看集群状态:
[root@monitor1 ceph-cluster]# ceph -s
cluster:
id: 7d518340-a55f--98ff-debb0d85e00b
health: HEALTH_WARN
too few PGs per OSD ( < min ) services:
mon: daemons, quorum monitor1,monitor2,monitor3
mgr: monitor1(active), standbys: monitor3, monitor2
osd: osds: up, in data:
pools: pools, pgs
objects: objects, B
usage: GiB used, GiB / GiB avail
pgs: active+clean
警告 osd分布pg数量小于默认的30
查看 osd节点默认的osd pg数量
[root@monitor1 ceph-cluster]# ssh node1
[root@monitor1 ceph-cluster]# ceph daemon osd. config show | grep pg_warn
"mon_pg_warn_max_object_skew": "10.000000",
"mon_pg_warn_min_objects": "",
"mon_pg_warn_min_per_osd": "", #默认是30
"mon_pg_warn_min_pool_objects": "",
由于创建池的时候 指定了6个PG, 导致分布到OSD的pg 数小于警告阀值30, 可以通过调整阀值,或者增大pool的PG 来消除警告
[root@monitor1 ceph-cluster]# ceph osd pool set fengjianpool pg_num
set pool pg_num to 128 [root@monitor1 ceph-cluster]# ceph osd pool set fengjianpool pgp_num 128
set pool pgp_num to 128 通常 PG 与 PGP 相等
再次查看集群状态
[root@monitor1 ceph-cluster]# ceph -s
cluster:
id: 7d518340-a55f--98ff-debb0d85e00b
health: HEALTH_OK services:
mon: daemons, quorum monitor1,monitor2,monitor3
mgr: monitor1(active), standbys: monitor3, monitor2
osd: osds: up, in data:
pools: pools, pgs
objects: objects, B
usage: GiB used, GiB / GiB avail
pgs: active+clean
PG的规划
公式
(TargePGsPerOSD) * (OSDNumber) * (DataPercent)
PoolPGCount = -------------------------------------------------------------------
PoolSize
设计计算公式的目的是确保这个集群拥有足够多的PG,从而实现数据均匀分布在各个osd上, 同时能够有效避免在恢复 和 回填的时候应为pg/osd 比值过高所造成的问题,

例如:

PG阻塞
在osd 接受IO请求的过程中, 如果出现网络抖动,导致IO阻塞,通过ceph health detail 查看阻塞的 osd,然后重启osd
ops are blocked > 32.768 sec on osd.
osds have slow requests io阻塞在osd. 上了, 重启osd. systemctl restart ceph-osd@
ceph文件系统
Ceph文件系统(CephFS)是一个符合POSIX标准的文件系统,它使用Ceph存储集群来存储其数据。
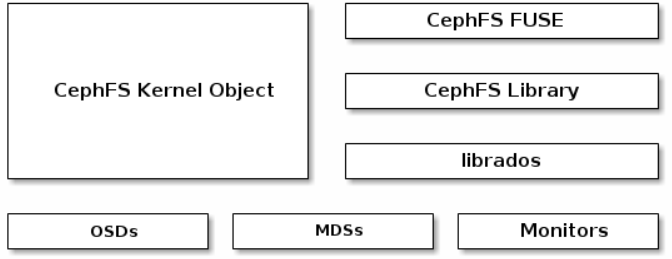
MDS 元数据部署
一 .自动创建mds
[root@monitor1 ceph-cluster]# ceph-deploy mds create monitor1 monitor2 monitor3
查看进程

[root@monitor3 ~]# ceph fs dump
dumped fsmap epoch
e12
enable_multiple, ever_enabled_multiple: ,
compat: compat={},rocompat={},incompat={=base v0.,=client writeable ranges,=default file layouts on dirs,=dir inode in separate object,=mds uses versioned encoding,=dirfrag is stored in omap,=no anchor table,=file layout v2,=snaprealm v2}
legacy client fscid: - No filesystems configured
Standby daemons: : 172.16.230.21:/ 'monitor1' mds.-1.0 up:standby seq
: 172.16.230.23:/ 'monitor3' mds.-1.0 up:standby seq
: 172.16.230.22:/ 'monitor2' mds.-1.0 up:standby seq
创建池
Ceph文件系统至少需要两个RADOS池,一个用于数据,一个用于元数据。配置这些池时,您可能会考虑:
- 对元数据池使用更高的复制级别,因为此池中的任何数据丢失都可能导致整个文件系统无法访问。
- 使用较低延迟的存储(如SSD)作为元数据池,因为这将直接影响客户端上文件系统操作的观察延迟。
[root@monitor1 ceph-cluster]# ceph osd pool create cephfs_data
[root@monitor1 ceph-cluster]# ceph osd pool create cephfs_metadata
创建文件系统
[root@monitor1 ceph-cluster]# ceph fs new cephfs cephfs_metadata cephfs_data
创建文件系统后,查看mds状态
[root@monitor1 ceph-cluster]# ceph mds stat
cephfs-// up {=monitor2=up:active}, up:standby
使用内核驱动挂载
[root@monitor1 ceph-cluster]# mkdir /data/testmount [root@monitor1 ceph-cluster]# mount -t ceph 172.16.230.21:,172.16.230.22:,172.16.230.23::/ /data/testmount/ -o name=admin,secret=AQAdv61c4OmVIxAAy217majZLxBO4Cl6+0pBTw==
或者使用 secretfile 挂载
[root@monitor1 ceph-cluster]# ceph-authtool -p /etc/ceph/ceph.client.admin.keyring" > admin.key
[root@monitor1 ceph-cluster]# mount -t ceph 172.16.230.21:,172.16.230.22:,172.16.230.23::/ /data/testmount/ -o name=admin,secretfile=admin.key 查看挂载情况
[root@monitor1 ceph-cluster]# df -Th
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/cl-root xfs 36G .9G 26G % /
devtmpfs devtmpfs .9G .9G % /dev
tmpfs tmpfs .9G 84K .9G % /dev/shm
tmpfs tmpfs .9G 185M .7G % /run
tmpfs tmpfs .9G .9G % /sys/fs/cgroup
/dev/sda1 xfs 1014M 175M 840M % /boot
tmpfs tmpfs 783M 16K 783M % /run/user/
tmpfs tmpfs 783M 783M % /run/user/
172.16.230.21:,172.16.230.22:,172.16.230.23::/ ceph 520G 111G 410G % /data/testmount
linux fstab 自动挂载
172.16.230.21:,172.16.230.22:,172.16.230.23::/ /mnt/ceph ceph name=admin,secretfile=/etc/ceph/secret.key,noatime,_netdev
使用 fuse 挂载
用户空间挂载 CEPH 文件系统
1. 安装 ceph-fuse
yum -y install ceph-fuse
2. 拷贝密钥环文件
从ceph 集群拷贝 ceph.conf 和 ceph.client.admin.keyring 到客户端 /etc/ceph/目录下
并且 属于644 权限 chmod 644 /etc/ceph/ceph.client.admin.keyring
3. 使用ceph-fuse 挂载命令
[root@monitor1 data]# ceph-fuse -m 172.16.230.21:,172.16.230.22:,172.16.230.23: /data/testmount
ceph-fuse[]: starting ceph client
-- ::48.920 7f625cd17c00 - init, newargv = 0x7f625e28faa0 newargc=
ceph-fuse[]: starting fuse [root@monitor1 data]# df -Th
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/cl-root xfs 36G .9G 26G % /
devtmpfs devtmpfs .9G .9G % /dev
tmpfs tmpfs .9G 84K .9G % /dev/shm
tmpfs tmpfs .9G 241M .6G % /run
tmpfs tmpfs .9G .9G % /sys/fs/cgroup
/dev/sda1 xfs 1014M 175M 840M % /boot
tmpfs tmpfs 783M 16K 783M % /run/user/
tmpfs tmpfs 783M 783M % /run/user/
ceph-fuse fuse.ceph-fuse 54G 54G % /data/testmount
4. 直接使用ceph存储默认身份验证
ceph-fuse -k /etc/ceph/ceph.client.admin.keyring -m
172.16.230.21:,172.16.230.22:,172.16.230.23: /data/testmount
二手动创建mds
1. 在node1 上手动创建mds目录,
[root@node1 mon]# mkdir /var/lib/ceph/mds/ceph-node1
2. 编辑ceph.conf并添加MDS部分
[mds.{$id}]
host = {hostname}
[mds.node1]
host=172.16.230.24
3. 创建身份验证和密钥环
ceph auth get-or-create mds.{$id} mon 'profile mds' mgr 'profile mds' mds 'allow *' osd 'allow *' > /var/lib/ceph/mds/ceph-{$id}/keyring
[root@monitor1 ceph-cluster]# ceph auth get-or-create mds.node1 mon 'profile mds' mgr 'profile mds' mds 'allow *' osd 'allow *' > /var/lib/ceph/mds/ceph-node1/keyring
4. 启动mds
[root@node1 ceph-node1]# systemctl restart ceph-mds@node1
5.查看映射关系
映射前
[root@monitor1 ceph-monitor1]# ceph mds stat
cephfs-// up {=monitor2=up:active}, up:standby 映射后
[root@monitor1 ceph-monitor1]# ceph mds stat
cephfs-// up {=monitor2=up:active}, up:standby
6. 删除原数据服务器
如果用元数据已经被挂载,需要先卸载,再删除
1. 关闭node1进程
[root@node1 ceph-node1]# systemctl stop ceph-mds@node1
2. 查看 映射关系
[root@monitor1 ceph-monitor1]# ceph mds stat
cephfs-// up {=monitor2=up:active}, up:standby
3. 修改admin 配置文件,去掉[mds.node1]
同步ceph到各个节点
ceph管理命令
ceph集群 支持多个cephfs 文件系统,不过需要添加命令允许创建多个文件系统
[root@monitor1 ceph-cluster]# ceph fs flag set enable_multiple true --yes-i-really-mean-it
创建文件系统
ceph osd pool create senyintfs_data
ceph osd pool create senyintfs_metadata ceph fs new senyintfs senyintfs_data senyintfs_metadata
查看文件系统
[root@monitor1 ceph-cluster]# ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
name: senyintfs, metadata pool: senyintfs_metadata, data pools: [senyintfs_data ]
查看fs map
[root@monitor1 ceph-cluster]# ceph fs dump
删除cephfs
关闭所有mds进程
[root@monitor1 ~]# systemctl stop ceph-mds@monitor1
[root@monitor2 ~]# systemctl stop ceph-mds@monitor2
[root@monitor3 ~]# systemctl stop ceph-mds@monitor3
2. 删除cephfs
[root@monitor1 ceph-cluster]# ceph fs rm senyintfs --yes-i-really-mean-it
3. 启动mds
设置允许保存的最大文件
[root@monitor1 ceph-cluster]# ceph fs set cephfs max_file_size
将集群关闭
[root@monitor1 ceph-cluster]# ceph fs set cephfs down true
打开集群
[root@monitor1 ceph-cluster]# ceph fs set cephfs down false
cephfs marked up, max_mds =
MDS缓存大小限制
通过以下方式限制元数据服务器(MDS)缓存的大小:
- 内存限制:Luminous版本中引入的新行为。使用mds_cache_memory_limit参数。我们建议使用内存限制而不是inode计数限制。
- Inode计数:使用mds_cache_size参数。默认情况下,禁用通过inode计数限制MDS缓存。
此外,您可以使用mds_cache_reservation参数为MDS操作指定缓存预留。缓存预留受限于内存或inode限制的百分比,默认设置为5%。此参数的目的是让MDS为其缓存维护额外的内存保留,以便使用新的元数据操作。因此,MDS通常应低于其内存限制,因为它将从客户端调用旧状态,以便将未使用的元数据丢弃在其缓存中。
cephfs 配额设置
CephFS允许在系统中的任何目录上设置配额。配额可以限制 目录层次结构中该点下面的字节数或文件数
限制:
. 配额是合作的,非对抗性的。CephFS配额依赖于正在挂载文件系统的客户端的合作,以在达到限制时停止编写器。无法阻止修改或对抗的客户端编写所需数据。不应依赖配额来防止在客户端完全不受信任的环境中填充系统。
. 配额是不精确的。写入文件系统的进程将在达到配额限制后的短时间内停止。它们将不可避免地被允许在配置的限制上写入一些数据。他们能够走多远的配额主要取决于时间量,而不是数据量。一般来说,编写者将在超过配置限制的十秒内停止。
. 配额在内核客户端4.17及更高版本中实现。 用户空间客户端(libcephfs,ceph-fuse)支持配额。Linux内核客户端> = .17支持CephFS配额,但仅限于模拟+集群。内核客户端(甚至是最新版本)将无法处理旧群集上的配额,即使它们可能能够设置配额扩展属性。
. 与基于路径的安装限制一起使用时,必须仔细配置配额。客户端需要访问配置了配额的目录inode才能强制执行配置。如果客户端/home/user基于MDS能力限制访问特定路径(例如),并且在他们无权访问(例如/home)的祖先目录上配置配额,则客户端将不强制执行该配额。使用基于路径的访问限制时,请务必在客户端受限制的目录上配置配额(例如/home/user)或嵌套在其下的内容。
. 已删除或更改的快照文件数据不计入配额。
设置配额:
ceph.quota.max_files - 文件限制
ceph.quota.max_bytes - 字节限制 setfattr -n ceph.quota.max_bytes -v /some/dir # MB
setfattr -n ceph.quota.max_files -v /some/dir # , files
查看配额
getfattr -n ceph.quota.max_bytes /some/dir
getfattr -n ceph.quota.max_files /some/dir
要删除的配合
setfattr -n ceph.quota.max_bytes -v /some/dir
setfattr -n ceph.quota.max_files -v /some/dir
ceph rbd块设备
块是一个字节序列(例如,512字节的数据块)。基于块的存储接口是使用旋转介质(如硬盘,CD,软盘甚至传统的9轨磁带)存储数据的最常用方法。无处不在的块设备接口使虚拟块设备成为与Ceph等海量数据存储系统交互的理想选择。
Ceph块设备是精简配置,可调整大小并存储在Ceph集群中多个OSD条带化的数据。Ceph块设备利用 RADOS功能,如快照,复制和一致性。Ceph的 RADOS块设备(RBD)使用内核模块或librbd库与OSD进行交互。

注意: 内核模块可以使用Linux页面缓存。对于librbd基于应用程序,Ceph支持RBD缓存。
1. 创建pool
ceph osd pool fengjian
2. 初始化pool给rbd使用
[root@monitor1 ~]# rbd pool init fengjian
3. 创建使用块设备的用户。
默认使用ceph集群的admin账户,此用户对集群有完全访问权限,建议设置用户权限。
4. 创建块设备
rbd create fengjian/test_image --size 10G --object-size --image-feature layering # --object-size 创建的object 大小, 24即 2^24, 16MB, 默认为 2^22, 4MB
# --image-feature layering 只使用layering功能
5. 查看池, 查看池中的块设备
[root@node5 ~]# ceph osd lspools
fengjian [root@node5 ~]# rbd ls fengjian -l
NAME SIZE PARENT FMT PROT LOCK
test2_image GiB
test_image GiB
6. 查看详细的块设备信息
[root@node5 ~]# rbd info fengjian/test_image
rbd image 'test_image':
size GiB in objects
order ( MiB objects)
id: 1494a6b8b4567
block_name_prefix: rbd_data.1494a6b8b4567
format:
features: layering
op_features:
flags:
create_timestamp: Sun May ::
7. 调整块设备的大小
# 增加块设备
[root@node5 ~]# rbd resize fengjian/test_image --size 5G
Resizing image: % complete...done. #缩小块设备,需要加参数--allow-shrink
[root@node5 ~]# rbd resize fengjian/test_image --size --allow-shrink
8. 映射与解除映射 rbd
映射
rbd map fengjia/test2_image
mkfs.xfs /dev/rbd0
mkdir /data/cephrbd0
mount /dev/rbd0 /data/cephrbd0 解除映射
umount /data/cephrbd0
rbd unmap /dev/rbd0
9.删除块设备
[root@node5 ~]# rbd rm fengjian/test2_image
10. trash 垃圾块 删除, 查看, 恢复
先把块挪到垃圾箱中
rbd trash move fengjian/test2_image . 查看垃圾箱中的块
rbd trash ls fengjian 14a5e6b8b4567 test3_image
1700d6b8b4567 test2_image . 从垃圾箱中恢复
rbd trash restore fengjian/14a5e6b8b4567 . 或者从垃圾箱中删除
rbd trash rm fengjian/14a5e6b8b4567
ceph 内核操作
获取image列表
. 获取ceph 的所有pool
ceph osd lspools . 获取池中的 所有imges
rbd ls -l fengjian
映射块设备
将rbd image映射到内核模块, 需要制定pool 的名字,image名字 和用户名。
rbd device map fengjian/test_image (--id admin)
如果使用cephx身份验证,必须制定密码, 可能来自 秘钥环或者包含秘钥文件
rbd device map rbd/image --id admin --keyring /path/to/keyring rbd device map rbd/image --id admin --keyfile /path/to/file
显示映射的块设备
rbd device list
取消映射的块设备
rbd device unmap /dev/rbd/{poolname}/imagename
rbd device unmap /dev/rbd/fengjian/rbd0
或者使用
rbd device unmap /dev/rbd0
rbd 快照
快照是特定时间点图像状态的只读副本
1 创建快照
[root@monitor1 ~]# rbd device map fengjian/test_image
/dev/rbd0 [root@monitor1 ~]# rbd device ls
id pool image snap device
fengjian test_image - /dev/rbd0 格式化rbd0
[root@monitor1 ~]# mkfs.xfs /dev/rbd0 -f 挂载rbd
[root@monitor1 ~]# mount /dev/rbd0 /data/testmount/ 创建快照
[root@monitor1 ~]# rbd snap create fengjian/test_image@test_image_snap 查看快照
[root@monitor1 ~]# rbd snap ls fengjian/test_image
SNAPID NAME SIZE TIMESTAMP
test_image_snap GiB Thu May :: 拷贝文件到目录中
[root@monitor1 ~]# cp /root/icbc-api-sdk-cop_v2_20190508.zip /data/testmount 恢复快照--必须卸载rbd
[root@monitor1 ~]# umount /data/testmount/ 恢复快照
[root@monitor1 ~]# rbd snap rollback fengjian/test_image@test_image_snap 挂载目录
[root@monitor1 ~]# mount /dev/rbd0 /data/testmount/
[root@monitor1 ~]# cd /data/testmount/
[root@monitor1 testmount]# ls
删除快照
[root@monitor1 testmount]# rbd snap rm fengjian/test_image@test_image_snap
Removing snap: % complete...done.
删除image中的所有快照
[root@monitor1 testmount]# rbd snap rm fengjian/test_image
快照和克隆
- 镜像:和源数据一样的数据,并且和源数据同步更新
- 克隆:某个时间点的源数据拷贝,数据量和源数据相同。克隆可以完整的恢复数据损坏的问题
- 快照:某个时间点的“虚拟”副本,不占用太多磁盘空间。快照在几秒钟内创建或者删除,不像克隆和镜像
#创建一个快照
rbd snap create fengjian/test_image@test_image_snap #查看快照
rbd snap ls fengjian/test_image #在克隆之前,确保快照处于protected状态
rbd snap protect fengjian/test_image #创建一个新的pool1:
ceph osd pool create linuxpool 128 128 #克隆到pool1:
rbd clone fengjian/test_image@test_image_snap linuxpool/new_image #查看快照的children:
rbd children fengjian/test_image@test_image_snap
#linuxpool/new_image #扁平化可以断开父子间的依赖关系:
rbd flatten linuxpool/new_image
CEPH对象网关
Ceph对象网关是一个对象存储接口,它构建在librados应用程序之上, 为Ceph存储集群提供RESTful网关。Ceph对象存储支持两个接口:
- S3兼容:提供对象存储功能,其接口与Amazon S3 RESTful API的大部分兼容。
- Swift兼容:提供对象存储功能,其接口与OpenStack Swift API的大部分兼容。
Ceph对象存储使用Ceph对象网关守护程序(radosgw),它是一个用于与Ceph存储集群交互的HTTP服务器。由于它提供与OpenStack Swift和Amazon S3兼容的接口,因此Ceph对象网关具有自己的用户管理。Ceph对象网关可以将数据存储在用于存储来自Ceph文件系统客户端或Ceph块设备客户端的数据的相同Ceph存储集群中。S3和Swift API共享一个公共命名空间,因此您可以使用一个API编写数据并使用另一个API检索它

概念和术语
AccessKey 、 SecreKey :使用S3 需要颁发AccessKey 和 SecretKey, AccesKey 用于标识客户的身份, SecretKey 作为私钥形式存放于客户端,不在网络中传递,SecretKey通常用作计算请求签名的秘钥,用于保证请求是来自制定的客户, 使用AccessKey进行身份识别,加上secretKey进行数字签名,即可完成应用接入与认证授权。
1. Regin(区域)
创建Bucket时,需要选择Region,Region 一般于标识资源存储的物理位置,比如中国区,欧洲区等
2. Region的外网域名
如 s3.cn.ceph.com 标识中国区的S3服务对外接入地址
3.Service(服务)
S3 提供给用户的虚拟存储空间,在这个虚拟空间中,每个用户可以拥有一个到多个Bucket
4. Bucket(存储空间)
Bucket 是存放object的容器,所有的object都必须存放在特定的Bucket中,在RGWz中默认每个用户最多可以常见1000个Bucket,每个
Bucket中可以存放无限个object,Bucket下的Object 是一个评级的结构,Bucket的名称全局唯一且命名规则与DNS名字规则相同。
5. Object:
在S3中,用户操作的基本数据单元是object, 单个object允许存储0~5TB的数据,object包括key和data,其中 key是object的名字, data是object的数据,
安装 radosgw
[root@monitor1 yum.repos.d]# yum -y install ceph-radosgw
创建rgw实例
[root@monitor1 ceph-cluster]# ceph-deploy rgw create monitor1 monitor2 monitor3
.........
[ceph_deploy.rgw][INFO ] The Ceph Object Gateway (RGW) is now running on host monitor3 and default port
#使用civeweb 方式比较简单,使用nginx作为前端服务的。
安装nginx
[root@monitor1 yum.repos.d]# yum -y install nginx
bucket index是整个RGW里面一个非常关键的数据结构,用于存储bucket的索引数据,默认情况下单个bucket的index全部存储在一个shard文件(shard数量为0,主要以OMAP-keys方式存储在leveldb中),随着单个bucket内的Object数量增加,整个shard文件的体积也在不断增长,当shard文件体积过大就会引发各种问题,常见的问题有:
- 对index pool进行scrub或deep-scrub的时候,如果shard对应的Object过大,会极大消耗底层存储设备性能,造成io请求超时。
- 底层deep-scrub的时候耗时过长,会出现request blocked,导致大量http请求超时而出现50x错误,从而影响到整个RGW服务的可用性。
- 当坏盘或者osd故障需要恢复数据的时候,恢复一个大体积的shard文件将耗尽存储节点性能,甚至可能因为OSD响应超时而导致整个集群出现雪崩。
ceph 优化配置文件
[global]
auth cluster required = cephx
auth service required = cephx
auth client required = cephx
cephx require signatures = False # Kernel RBD does NOT support signatures!
cephx cluster require signatures = True
cephx service require signatures = False
fsid = e19a0961-d284-41e3-b890-9322f2d4ad36
max open files =
osd pool default pg num =
osd pool default pgp num =
osd pool default size =
osd pool default min size =
osd pool default crush rule =
cluster addr = 172.16.254.13
public addr = 172.16.230.13
cluster network = 172.16.254.0/
public network = 172.16.230.0/
debug_lockdep = /
debug_context = /
debug_crush = /
debug_buffer = /
debug_timer = /
debug_filer = /
debug_objecter = /
debug_rados = /
debug_rbd = /
debug_journaler = /
debug_objectcatcher = /
debug_client = /
debug_osd = /
debug_optracker = /
debug_objclass = /
debug_filestore = /
debug_journal = /
debug_ms = /
debug_monc = /
debug_tp = /
debug_auth = /
debug_finisher = /
debug_heartbeatmap = /
debug_perfcounter = /
debug_asok = /
debug_throttle = /
debug_mon = /
debug_paxos = /
debug_rgw = /
osd crush update on start = false
mon_pg_warn_max_per_osd =
mds_session_blacklist_on_timeout = false
mon_max_pg_per_osd =
rgw_num_rados_handles =
rgw_num_async_rados_threads =
mon_osd_reporter_subtree_level = osd_domain
mon_osd_down_out_subtree_limit = " "
mon_osd_min_in_ratio = 0.66
mon_pg_warn_max_object_skew =
mds_standby_replay = true
mds_reconnect_timeout =
mds_session_timeout = [mon]
mon_allow_pool_delete = true
mon clock drift allowed =
mon clock drift warn backoff = [mon.node1]
host = node1
mon addr = 172.16.230.13 [mon.node2]
host = node2
mon addr = 172.16.230.14 [mon.node3]
host = node3
mon addr = 172.16.230.15 [osd]
osd max object namespace len =
osd_max_object_name_len =
osd mkfs type = xfs
osd mkfs options xfs = -f -i size=
osd mount options xfs = noatime,largeio,inode64,swalloc
osd_op_thread_timeout =
s3store_max_ops =
s3cache_max_dirty_objects =
bluestore = true
enable experimental unrecoverable data corrupting features = bluestore rocksdb
bluestore fsck on mount = true
osd objectstore = bluestore
bluestore_fsck_on_mkfs_deep = false
bluestore_fsck_on_mount_deep = false
journal_max_write_bytes =
journal_max_write_entries =
journal_queue_max_ops =
journal_queue_max_bytes =
osd_op_threads =
osd_client_message_cap = [osd.]
host = node1
bluestore block path = /dev/sdavgdata/sda-block1 [osd.]
host = node2
bluestore block path = /dev/sdavgdata/sda-block1 [osd.]
host = node3
bluestore block path = /dev/sdavgdata/sda-block1 [osd.]
host = node2
bluestore block path = /dev/sdbvgdata/sdb-block1 [osd.]
host = node1
bluestore block path = /dev/sdbvgdata/sdb-block1 [osd.]
host = node3
bluestore block path = /dev/sdbvgdata/sdb-block1 [osd.]
host = node2
bluestore block path = /dev/sdgvg/sdg-block1
bluestore block db path = /dev/sdavg/sda-db-0f754ef0-edce-45af-aa25-ed087ed329d3
bluestore block wal path = /dev/sdavg/sda-wal-cf6592ae-22fe-428c-9db8-4e1b3b8b1fd8 [osd.]
host = node3
bluestore block path = /dev/sdgvg/sdg-block1
bluestore block db path = /dev/sdavg/sda-db-0f754ef0-edce-45af-aa25-ed087ed329d3
bluestore block wal path = /dev/sdavg/sda-wal-cf6592ae-22fe-428c-9db8-4e1b3b8b1fd8 [osd.]
host = node1
bluestore block path = /dev/sdgvg/sdg-block1
bluestore block db path = /dev/sdavg/sda-db-0f754ef0-edce-45af-aa25-ed087ed329d3
bluestore block wal path = /dev/sdavg/sda-wal-cf6592ae-22fe-428c-9db8-4e1b3b8b1fd8 [osd.]
host = node2
bluestore block path = /dev/sdcvg/sdc-block1
bluestore block db path = /dev/sdbvg/sdb-db-24d7ed5b-88c0-42cc-a397-f435e719e39a
bluestore block wal path = /dev/sdbvg/sdb-wal-d3eb3b40-38ea-46e0-aec3-2d68f86a6ba0 [osd.]
host = node3
bluestore block path = /dev/sdcvg/sdc-block1
bluestore block db path = /dev/sdbvg/sdb-db-24d7ed5b-88c0-42cc-a397-f435e719e39a
bluestore block wal path = /dev/sdbvg/sdb-wal-d3eb3b40-38ea-46e0-aec3-2d68f86a6ba0 [osd.]
host = node1
bluestore block path = /dev/sdcvg/sdc-block1
bluestore block db path = /dev/sdbvg/sdb-db-24d7ed5b-88c0-42cc-a397-f435e719e39a
bluestore block wal path = /dev/sdbvg/sdb-wal-d3eb3b40-38ea-46e0-aec3-2d68f86a6ba0 [osd.]
host = node2
bluestore block path = /dev/sdmvg/sdm-block1
bluestore block db path = /dev/sdavg/sda-db-1f5dfd2e-a2ad-424a--4d4b9b03f8a8
bluestore block wal path = /dev/sdavg/sda-wal-4788bca9-888e-4db6-96db-6acd922609d9 [osd.]
host = node3
bluestore block path = /dev/sdmvg/sdm-block1
bluestore block db path = /dev/sdavg/sda-db-1f5dfd2e-a2ad-424a--4d4b9b03f8a8
bluestore block wal path = /dev/sdavg/sda-wal-4788bca9-888e-4db6-96db-6acd922609d9 [osd.]
host = node1
bluestore block path = /dev/sdmvg/sdm-block1
bluestore block db path = /dev/sdavg/sda-db-1f5dfd2e-a2ad-424a--4d4b9b03f8a8
bluestore block wal path = /dev/sdavg/sda-wal-4788bca9-888e-4db6-96db-6acd922609d9 [osd.]
host = node2
bluestore block path = /dev/sddvg/sdd-block1
bluestore block db path = /dev/sdbvg/sdb-db-23b626fd-259a-4f72-957c-f2495bb978fa
bluestore block wal path = /dev/sdbvg/sdb-wal-edd70a12-ac98-48bb-b1c2-0338776d9964 [osd.]
host = node3
bluestore block path = /dev/sddvg/sdd-block1
bluestore block db path = /dev/sdbvg/sdb-db-23b626fd-259a-4f72-957c-f2495bb978fa
bluestore block wal path = /dev/sdbvg/sdb-wal-edd70a12-ac98-48bb-b1c2-0338776d9964 [osd.]
host = node1
bluestore block path = /dev/sddvg/sdd-block1
bluestore block db path = /dev/sdbvg/sdb-db-23b626fd-259a-4f72-957c-f2495bb978fa
bluestore block wal path = /dev/sdbvg/sdb-wal-edd70a12-ac98-48bb-b1c2-0338776d9964 [osd.]
host = node2
bluestore block path = /dev/sdivg/sdi-block1
bluestore block db path = /dev/sdavg/sda-db-7aefabfa-d1ab-461b-a39c-9a4545d8d75d
bluestore block wal path = /dev/sdavg/sda-wal-4a388d88-fe95-472f-a00b-94e1abae7a91 [osd.]
host = node3
bluestore block path = /dev/sdivg/sdi-block1
bluestore block db path = /dev/sdavg/sda-db-7aefabfa-d1ab-461b-a39c-9a4545d8d75d
bluestore block wal path = /dev/sdavg/sda-wal-4a388d88-fe95-472f-a00b-94e1abae7a91 [osd.]
host = node1
bluestore block path = /dev/sdivg/sdi-block1
bluestore block db path = /dev/sdavg/sda-db-7aefabfa-d1ab-461b-a39c-9a4545d8d75d
bluestore block wal path = /dev/sdavg/sda-wal-4a388d88-fe95-472f-a00b-94e1abae7a91 [osd.]
host = node2
bluestore block path = /dev/sdkvg/sdk-block1
bluestore block db path = /dev/sdbvg/sdb-db-096cae87-b3da-426f-aa41-dcc625ebcc9c
bluestore block wal path = /dev/sdbvg/sdb-wal-ac9d1bb5-cf4a---e96c09d400d8 [osd.]
host = node3
bluestore block path = /dev/sdkvg/sdk-block1
bluestore block db path = /dev/sdbvg/sdb-db-096cae87-b3da-426f-aa41-dcc625ebcc9c
bluestore block wal path = /dev/sdbvg/sdb-wal-ac9d1bb5-cf4a---e96c09d400d8 [osd.]
host = node1
bluestore block path = /dev/sdkvg/sdk-block1
bluestore block db path = /dev/sdbvg/sdb-db-096cae87-b3da-426f-aa41-dcc625ebcc9c
bluestore block wal path = /dev/sdbvg/sdb-wal-ac9d1bb5-cf4a---e96c09d400d8 [osd.]
host = node2
bluestore block path = /dev/sdlvg/sdl-block1
bluestore block db path = /dev/sdavg/sda-db-55f7eba6-309f-4b3b-a352-7203febe79e5
bluestore block wal path = /dev/sdavg/sda-wal-8112d8c8-a452-4c92-b712-9f3abd2e8937 [osd.]
host = node1
bluestore block path = /dev/sdlvg/sdl-block1
bluestore block db path = /dev/sdavg/sda-db-55f7eba6-309f-4b3b-a352-7203febe79e5
bluestore block wal path = /dev/sdavg/sda-wal-8112d8c8-a452-4c92-b712-9f3abd2e8937 [osd.]
host = node3
bluestore block path = /dev/sdlvg/sdl-block1
bluestore block db path = /dev/sdavg/sda-db-55f7eba6-309f-4b3b-a352-7203febe79e5
bluestore block wal path = /dev/sdavg/sda-wal-8112d8c8-a452-4c92-b712-9f3abd2e8937 [osd.]
host = node2
bluestore block path = /dev/sdfvg/sdf-block1
bluestore block db path = /dev/sdbvg/sdb-db-a4fdf1c5-0c62-4d2d-ab11-0e72091a30ab
bluestore block wal path = /dev/sdbvg/sdb-wal-6b149894-636a-4cc7-ad03-c96f3b8c040d [osd.]
host = node3
bluestore block path = /dev/sdfvg/sdf-block1
bluestore block db path = /dev/sdbvg/sdb-db-a4fdf1c5-0c62-4d2d-ab11-0e72091a30ab
bluestore block wal path = /dev/sdbvg/sdb-wal-6b149894-636a-4cc7-ad03-c96f3b8c040d [osd.]
host = node1
bluestore block path = /dev/sdfvg/sdf-block1
bluestore block db path = /dev/sdbvg/sdb-db-a4fdf1c5-0c62-4d2d-ab11-0e72091a30ab
bluestore block wal path = /dev/sdbvg/sdb-wal-6b149894-636a-4cc7-ad03-c96f3b8c040d [osd.]
host = node2
bluestore block path = /dev/sdhvg/sdh-block1
bluestore block db path = /dev/sdavg/sda-db-c9d6edff-a28a-46a0-b021-8f8f59a92eec
bluestore block wal path = /dev/sdavg/sda-wal-3f3af9ad-1fc4--bf92-e042c2253945 [osd.]
host = node1
bluestore block path = /dev/sdhvg/sdh-block1
bluestore block db path = /dev/sdavg/sda-db-c9d6edff-a28a-46a0-b021-8f8f59a92eec
bluestore block wal path = /dev/sdavg/sda-wal-3f3af9ad-1fc4--bf92-e042c2253945 [osd.]
host = node3
bluestore block path = /dev/sdhvg/sdh-block1
bluestore block db path = /dev/sdavg/sda-db-c9d6edff-a28a-46a0-b021-8f8f59a92eec
bluestore block wal path = /dev/sdavg/sda-wal-3f3af9ad-1fc4--bf92-e042c2253945 [osd.]
host = node2
bluestore block path = /dev/sdnvg/sdn-block1
bluestore block db path = /dev/sdbvg/sdb-db-7a9322d7-f79c-4a1b--9c55f00da234
bluestore block wal path = /dev/sdbvg/sdb-wal-7582639e-f77b--82f0-8d344ded3885 [osd.]
host = node1
bluestore block path = /dev/sdnvg/sdn-block1
bluestore block db path = /dev/sdbvg/sdb-db-7a9322d7-f79c-4a1b--9c55f00da234
bluestore block wal path = /dev/sdbvg/sdb-wal-7582639e-f77b--82f0-8d344ded3885 [osd.]
host = node3
bluestore block path = /dev/sdnvg/sdn-block1
bluestore block db path = /dev/sdbvg/sdb-db-7a9322d7-f79c-4a1b--9c55f00da234
bluestore block wal path = /dev/sdbvg/sdb-wal-7582639e-f77b--82f0-8d344ded3885 [osd.]
host = node2
bluestore block path = /dev/sdjvg/sdj-block1
bluestore block db path = /dev/sdavg/sda-db-1f6e823e-a03d-4ea3--8a95d90d3f03
bluestore block wal path = /dev/sdavg/sda-wal-15ea59e1-dfd2-4d1c--201e7ca71a29 [osd.]
host = node1
bluestore block path = /dev/sdjvg/sdj-block1
bluestore block db path = /dev/sdavg/sda-db-1f6e823e-a03d-4ea3--8a95d90d3f03
bluestore block wal path = /dev/sdavg/sda-wal-15ea59e1-dfd2-4d1c--201e7ca71a29 [osd.]
host = node3
bluestore block path = /dev/sdjvg/sdj-block1
bluestore block db path = /dev/sdavg/sda-db-1f6e823e-a03d-4ea3--8a95d90d3f03
bluestore block wal path = /dev/sdavg/sda-wal-15ea59e1-dfd2-4d1c--201e7ca71a29 [osd.]
host = node2
bluestore block path = /dev/sdevg/sde-block1
bluestore block db path = /dev/sdbvg/sdb-db-fc6c4020-2f76--b26d-d8a253c04c9c
bluestore block wal path = /dev/sdbvg/sdb-wal-66a4bfa3-340e-4d58-94e3-949257f9105a [osd.]
host = node1
bluestore block path = /dev/sdevg/sde-block1
bluestore block db path = /dev/sdbvg/sdb-db-fc6c4020-2f76--b26d-d8a253c04c9c
bluestore block wal path = /dev/sdbvg/sdb-wal-66a4bfa3-340e-4d58-94e3-949257f9105a [osd.]
host = node3
bluestore block path = /dev/sdevg/sde-block1
bluestore block db path = /dev/sdbvg/sdb-db-fc6c4020-2f76--b26d-d8a253c04c9c
bluestore block wal path = /dev/sdbvg/sdb-wal-66a4bfa3-340e-4d58-94e3-949257f9105a [mds.node1]
host = node1
mds addr = 172.16.230.13 [mds.node2]
host = node2
mds addr = 172.16.230.14 [mds.node3]
host = node3
mds addr = 172.16.230.15 [client.rgw.node1]
host = node1
keyring = /etc/ucsm/ucsm.client.radosgw.keyring
rgw socket path = /var/run/ceph/ceph.radosgw.gateway.fastcgi.sock
log file = /var/log/ceph/ucsm-rgw-node1.log
rgw data = /var/lib/ceph/radosgw/ucsm-rgw.node1
rgw enable usage log = true
rgw enable ops log = true
rgw frontends = "civetweb port=7480" [client.rgw.node2]
host = node2
keyring = /etc/ucsm/ucsm.client.radosgw.keyring
rgw socket path = /var/run/ceph/ceph.radosgw.gateway.fastcgi.sock
log file = /var/log/ceph/ucsm-rgw-node2.log
rgw data = /var/lib/ceph/radosgw/ucsm-rgw.node2
rgw enable usage log = true
rgw enable ops log = true
rgw frontends = "civetweb port=7480" [client.rgw.node3]
host = node3
keyring = /etc/ucsm/ucsm.client.radosgw.keyring
rgw socket path = /var/run/ceph/ceph.radosgw.gateway.fastcgi.sock
log file = /var/log/ceph/ucsm-rgw-node3.log
rgw data = /var/lib/ceph/radosgw/ucsm-rgw.node3
rgw enable usage log = true
rgw enable ops log = true
rgw frontends = "civetweb port=7480" [mgr]
mgr modules = restful
mon_warn_on_pool_no_app = false
mon_pg_warn_max_per_osd =
mon_max_pg_per_osd = [mgr.node1]
host = node1
mgr addr = 172.16.230.13
mgr data = /var/lib/ceph/mgr/ucsm-node1 [mgr.node2]
host = node2
mgr addr = 172.16.230.14
mgr data = /var/lib/ceph/mgr/ucsm-node2 [mgr.node3]
host = node3
mgr addr = 172.16.230.15
mgr data = /var/lib/ceph/mgr/ucsm-node3
参考:
https://blog.csdn.net/lyf0327/article/details/83315207
http://xiaqunfeng.cc/2017/07/04/ceph-Luminous%E6%96%B0%E5%8A%9F%E8%83%BD%E4%B9%8Bcrush-class/
https://cloud.tencent.com/developer/article/1032858
ceph mimic版本 部署安装的更多相关文章
- Ceph学习之路(三)Ceph luminous版本部署
1.配置ceph.repo并安装批量管理工具ceph-deploy [root@ceph-node1 ~]# vim /etc/yum.repos.d/ceph.repo [ceph] name=Ce ...
- ceph luminous版本的安装部署
1. 前期准备 本次安装环境为: ceph1(集群命令分发管控,提供磁盘服务集群) CentOs7.5 10.160.20.28 ceph2(提供磁盘服务集群) CentOs7.5 10. ...
- ceph mimc版本ceph-deploy安装与配置
系统环境centos7.6 内核5.0.9 YUM源配置 [root@k8s-sys-10-82-4-200 ceph-cluster]# cat /etc/yum.repos.d/ceph.repo ...
- ceph部署实践(mimic版本)
一.准备环境 4台adminos7.4 环境,存储节点上两块磁盘(sda操作系统,sdb数据盘) clientadmin storage1storage2storage3 二.配置环境 1.修改主机名 ...
- ceph学习笔记之十二 Ubuntu安装部署Ceph J版本
https://cloud.tencent.com/info/2b70340c72d893c30f5e124e89c346cd.html 安装Ubuntu系统安装步骤略过 拓扑连接: 一.安装前准备工 ...
- 手动部署 Ceph Mimic 三节点
目录 文章目录 目录 前文列表 部署拓扑 存储设备拓扑 网络拓扑 基础系统环境 安装 ceph-deploy 半自动化部署工具 部署 MON 部署 Manager 部署 OSD 部署 MDS 部署 R ...
- openstack(liberty):部署实验平台(二,简单版本软件安装 part1)
软件安装过程中,考虑到现在是一个实验环境,且也考虑到规模不大,还有,网络压力不会大,出于简单考虑,将各个节点的拓扑结构改了一下,主要体现在网络节点和控制节点并在了一起.在一个服务器上安装! 到目前位置 ...
- ceph 常见问题百科全书---luminous安装部署篇
1. 执行步骤:ceph-deploy new node 机器:centos 7.5 ceph Luminous版本 源:阿里云 问题: Traceback (most r ...
- openstack(liberty):部署实验平台(二,简单版本软件安装 part2)
继续前面的part1,将后续的compute以及network部分的安装过程记录完毕! 首先说说compute部分nova的安装. n1.准备工作.创建数据库,配置权限!(密码依旧是openstack ...
随机推荐
- 网络编程socket之一
从今年10月22号开始我的python学习之路,一个月下来,磕磕碰碰,勉勉强强把基础部分算是学完了,一个月走过来,我过着别人看似单调,重复的生活,确实是,每天,每周都是一样的生活模式,早上7点40起床 ...
- Josephus Problem的详细算法及其Python、Java实现
笔者昨天看电视,偶尔看到一集讲述古罗马人与犹太人的战争--马萨达战争,深为震撼,有兴趣的同学可以移步:http://finance.ifeng.com/a/20170627/15491157_0. ...
- jQuery学习(1)猜数字游戏
jQuery是一个快捷.小型且特征丰富的JavaScript库.它使得HTML文档遍历及操作,事件处理,动画,Ajax等更简洁方便.它通过调用一个简单易用的API,就能在各种浏览器中使用.由于jQ ...
- Extjs4---Cannot read property 'addCls' of null 或者 el is null 关于tab关闭后再打开不显示或者报错
做后台管理系统时遇到的问题,关于tab关闭后再打开不显示,或者报错 我在新的tabpanel中加入了一个grid,当我关闭再次打开就会报错Cannot read property 'addCls' o ...
- C++注入记事本升级版,给记事本弄爱心
#include <iostream>; using namespace std; #include <windows.h>; #include <tlhelp32.h& ...
- HTML5 template元素
前言 转自http://www.zhangxinxu.com/wordpress/2014/07/hello-html5-template-tag/ 在单页面应用,我们对页面的无刷新有了更高的要求,H ...
- Python shelve
shelve模块只有一个open函数,返回类似字典的对象,可读可写; key必须为字符串,而值可以是python所支持的数据类型. import shelve f = shelve.open('SHE ...
- CSS总结div中的内容垂直居中的五种方法
一.行高(line-height)法 如果要垂直居中的只有一行或几个文字,那它的制作最为简单,只要让文字的行高和容器的高度相同即可,比如: p { height:30px; line-height:3 ...
- 【转】ASP.NET Core 依赖注入
DI在.NET Core里面被提到了一个非常重要的位置, 这篇文章主要再给大家普及一下关于依赖注入的概念,身边有工作六七年的同事还个东西搞不清楚.另外再介绍一下.NET Core的DI实现以及对实例 ...
- KVM虚拟化研究-1
使用qemu-img创建镜像 例子: [root@HOST31 rybtest]# qemu-img create -f raw /rybtest/test1.raw 1G 使用qemu-img查看镜 ...