贝叶斯---最大似然估计(高翔slam---第六讲 )
1.贝叶斯---最大似然估计
回顾一下第二讲的经典SLAM模型:
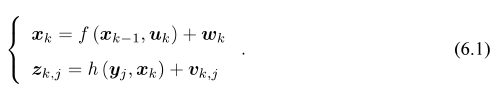
通过传感器(例如IMU)的运动参数u来估计运动(位姿x)[定位],通过相机的照片的观测参数z来估计物体的位置(地图y)[建图],都是有噪声的。因为运动参数和照片都有噪声,所以需要进行优化。而过去卡尔曼滤波只关心当前的状态估计,而非线性优化则对所有时刻采集的数据进行状态估计,被认为优于卡尔曼滤波。由于要估计所有的采集数据,所以待估计变量就变成:x={x1,…,xN,y1,….,yM}
所以对机器人状态的估计,就是求已知输入数据u(传感器参数)和观测数据z(图像像素)的条件下,计算状态x的条件概率分布(也就是根据u和z的数据事件好坏来估计x的优劣事件概率情况,这其中包含着关联,就好像已知一箱子里面有u和z个劣质的商品,求取出x个全是好商品的概率,同样的样本点,但是从不同角度分析可以得出不同的事件,不同的事件概率之间可以通过某些已知数据得出另些事件的概率):P(x|z, u)。当没有测量运动的传感器,只考虑观测照片z的情况下求x(这个过程也称SfM运动恢复),那么就变成P(x|z)。
贝叶斯公式求解(贝叶斯法则的分母部分与带估计的状态x无关,所以忽略P(z)):


2.最大似然估计---最小二乘问题
如何求最大似然估计呢?
回顾观测方程,我们知道z与x之间存在一个函数式: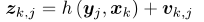 ,现在要求x导致z出现的概率最大,求x。
,现在要求x导致z出现的概率最大,求x。
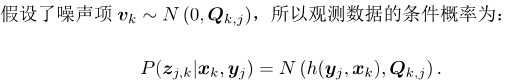
假设噪声项符号高斯分布,观测Z也符合高斯分布。
为了计算使它最大化的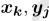 ,往往使用最小化负对数的方式,来求一个高斯分布的最大似然。
,往往使用最小化负对数的方式,来求一个高斯分布的最大似然。
任意的高位高斯分布 ,概率密度函数展开式:
,概率密度函数展开式:
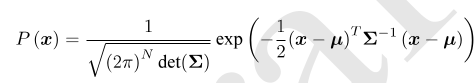
对其取负对数: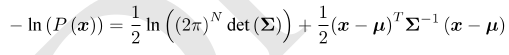
对原分布求最大化相当于对负对数求最小化,对上式x进行最小化时,第一项与x无关,略去,只需要最小化右侧的二次型,带入SLAM的观测模型,即求: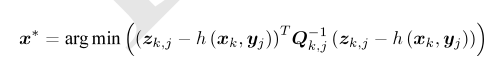
我们发现,该是等价于最小化噪声项(即误差)的平方( 范数意义下)。
范数意义下)。
因此对于所以对于所有的运动和观测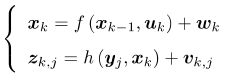 ,定义数据与估计值之间的误差:
,定义数据与估计值之间的误差: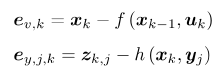 ,
,
误差的平方和: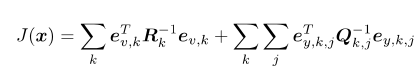 (6.12)
(6.12)
从而得到了一个总体意义下的最小二乘问题,它的最优解等于状态的最大似然估计。
直观上讲,由于噪声的存在,当我们把估计的轨迹和地图(xk,yj)代入SLAM的运动、观测方程中时,它们并不会完美的成立。这时候怎么办呢?我们把状态的估计值进行微调,使得整体的误差下降一些,它一般会到极小值。这就是一个典型的非线性优化过程。
贝叶斯---最大似然估计(高翔slam---第六讲 )的更多相关文章
- 从贝叶斯到粒子滤波——Round 2
上一篇博文已经讲了贝叶斯滤波的原理以及公式的推导:http://www.cnblogs.com/JunhaoWu/p/bayes_filter.html 本篇文章将从贝叶斯滤波引入到粒子滤波,讲诉粒子 ...
- Stanford大学机器学习公开课(六):朴素贝叶斯多项式模型、神经网络、SVM初步
(一)朴素贝叶斯多项式事件模型 在上篇笔记中,那个最基本的NB模型被称为多元伯努利事件模型(Multivariate Bernoulli Event Model,以下简称 NB-MBEM).该模型有多 ...
- SLAM的数学基础(4):先验概率、后验概率、贝叶斯准则
假设有事件A和事件B,可以同时发生但不是完全同时发生,如以下韦恩图所示: 其中,A∩B表示A和B的并集,即A和B同时发生的概率. 如此,我们很容易得出,在事件B发生的情况下,事件A发生的概率为: 这个 ...
- R语言︱贝叶斯网络语言实现及与朴素贝叶斯区别(笔记)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 一.贝叶斯网络与朴素贝叶斯的区别 朴素贝叶斯的 ...
- 高翔《视觉SLAM十四讲》从理论到实践
目录 第1讲 前言:本书讲什么:如何使用本书: 第2讲 初始SLAM:引子-小萝卜的例子:经典视觉SLAM框架:SLAM问题的数学表述:实践-编程基础: 第3讲 三维空间刚体运动 旋转矩阵:实践-Ei ...
- 白话贝叶斯理论及在足球比赛结果预测中的应用和C#实现
离去年“马尔可夫链进行彩票预测”已经一年了,同时我也计划了一个彩票数据框架的搭建,分析和预测的框架,会在今年逐步发表,拟定了一个目录,大家有什么样的意见和和问题,可以看看,留言我会在后面的文章中逐步改 ...
- [Machine Learning & Algorithm] 朴素贝叶斯算法(Naive Bayes)
生活中很多场合需要用到分类,比如新闻分类.病人分类等等. 本文介绍朴素贝叶斯分类器(Naive Bayes classifier),它是一种简单有效的常用分类算法. 一.病人分类的例子 让我从一个例子 ...
- 最大似然估计(Maximum Likelihood,ML)
先不要想其他的,首先要在大脑里形成概念! 最大似然估计是什么意思?呵呵,完全不懂字面意思,似然是个啥啊?其实似然是likelihood的文言翻译,就是可能性的意思,所以Maximum Likeliho ...
- 最大似然估计(MLE)和最大后验概率(MAP)
最大似然估计: 最大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”.简单而言,假设我们要统计全国人口的身高,首先假设这个身高服从服从正态分布,但是该分布的均值与方差未知 ...
随机推荐
- Linux内核分析第九次作业
理解进程调度时机跟踪分析进程调度与进程切换的过程 一.基础知识 Linux系统的一般执行过程 一般情况:正在运行的用户态进程X切换到运行用户态进程Y的过程 1. 正在运行的用户态进程X 2. 发生中断 ...
- 算法实践--最小生成树(Kruskal算法)
什么是最小生成树(Minimum Spanning Tree) 每两个端点之间的边都有一个权重值,最小生成树是这些边的一个子集.这些边可以将所有端点连到一起,且总的权重最小 下图所示的例子,最小生成树 ...
- ActiveMQ-5.15.2下载和启动(windows)
一.下载和部署 我的ActiveMQ版本是 5.15.2,参照别人家的博客,下载和启动照样成功.别人家的博客地址: http://blog.csdn.net/clj198606061111/artic ...
- Webservices部署在IIS6.0上的一个小问题
部署方式还是跟网站的部署方式一样,可是通过localhost访问一直提示400(bad request)错误. 可以在iis上预览到.在vs上引用的时候怎么都预览不到. 换个思路,把localhost ...
- 廖雪峰Java7处理日期和时间-1概念-1日期和时间
1.日期 日期是指某一天,如2016-11-20,2018-1-1 2.时间有2种: 不带日期的时间:14:23:54 带日期的时间:2017-1-1 20:21:23,唯一确定某个时刻 3.时区 时 ...
- MYSQL存储过程实现用户登录
MYSQL存储过程实现用户登录 CREATE DEFINER=`root`@`%` PROCEDURE `uc_session_login`( ), ) ) LANGUAGE SQL NOT DETE ...
- C++Primer第五版——习题答案详解(五)
习题答案目录:https://www.cnblogs.com/Mered1th/p/10485695.html 第6章 函数 练习6.4 #include<iostream> using ...
- Error:Execution failed for task :app:transformClassesWithInstantRunForDebug解决方案
转自https://blog.csdn.net/student9128/article/details/53026990
- Linux第八章:文件,文件系统的压缩,打包备份
压缩:gzip -v 文件名 1:压缩后成 文件名.gz 的压缩文件,原文件消失 2:压缩的文件可以直接使用zcat 文件名.gz 读取里面的内容 解压缩: gunzip 文件名.gz 替 ...
- Python3网络爬虫(四):使用User Agent和代理IP隐藏身份《转》
https://blog.csdn.net/c406495762/article/details/60137956 运行平台:Windows Python版本:Python3.x IDE:Sublim ...