Java-Zipkin:Zipkin 介绍
| ylbtech-Java-Zipkin:Zipkin 介绍 |
| 1.返回顶部 |
介绍
Zipkin 是一款开源的分布式实时数据追踪系统(Distributed Tracking System),基于 Google Dapper 的论文设计而来,由 Twitter公司开发贡献。其主要功能是聚集来自各个异构系统的实时监控数据,用来追踪微服务架构下的系统延时问题。应用系统需要进行装备(instrument)以向 Zipkin 报告数据。Zipkin 的用户界面可以呈现一幅关联图表,以显示有多少被追踪的请求通过了每一层应用。Zipkin 以 Trace 结构表示对一次请求的追踪,又把每个 Trace 拆分为若干个有依赖关系的 Span。在微服务架构中,一次用户请求可能会由后台若干个服务负责处理,那么每个处理请求的服务就可以理解为一个 Span(可以包括 API 服务,缓存服务,数据库服务以及报表服务等)。当然这个服务也可能继续请求其他的服务,因此 Span 是一个树形结构,以体现服务之间的调用关系。Zipkin 的用户界面除了可以查看 Span 的依赖关系之外,还以瀑布图的形式显示了每个 Span 的耗时情况,可以一目了然的看到各个服务的性能状况。打开每个 Span,还有更详细的数据以键值对的形式呈现,而且这些数据可以在装备应用的时候自行添加。
架构
zipkin结构
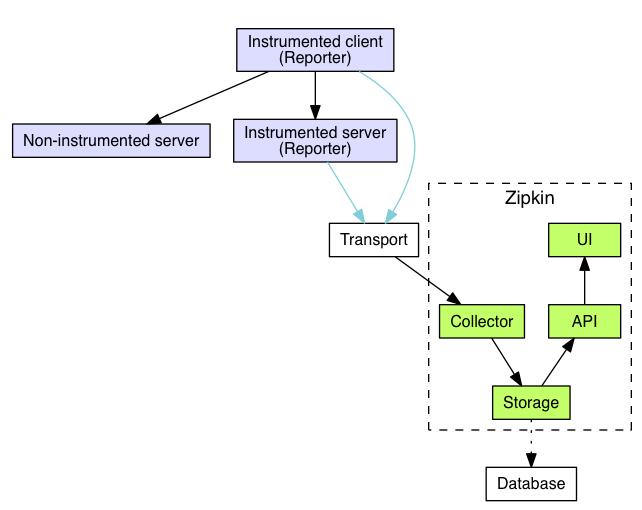
可以看到zipkin内部主要分为四部分:collector、storage、api、ui
collector:负责将各系统报告过来的追踪数据进行接收
storage:默认使用Cassandra存储数据,也可以替换为其他存储,例如mysql5.6-5.7,ElasticSearch 2.x和5.x,还有一些第三方的存储
api:查询服务用来向其他服务提供数据查询的能力,是以json api格式提供
ui:Web服务是官方默认提供的一个图形用户界面
transport
transport负责从运输从service收集来的spans,并把这些spans转化为zipkin的通用span,并将其传递到存储层,这种方法是模块化的,允许任何生产者接收任何类型的数据,zipkin配有HTTP、kafka、scribe三种类型的transport。instrumentations负责和transport进行交互。
instrumentations
官方维护
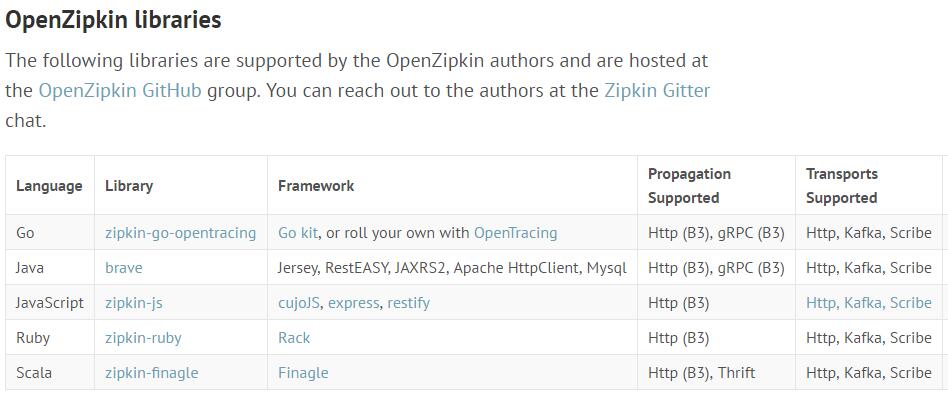
ps:支持go、scala,这个不错
第三方维护

ps:支持python,我就可以自己玩了,同时支持了四个Python库,最基础的是py_zipkin模块,pyramid_zipkin、swagger_zipkin、flask_zipkin三个都是基于py_zipkin再次封装的。
核心数据结构
traceId:全局跟踪ID,用它来标记一次完整服务调用,所以和一次服务调用相关的span中的traceId都是相同的,Zipkin将具有相同traceId的span组装成跟踪树来直观的将调用链路图展现在我们面前。
id:span的id,理论上来说,span的id只要做到一个traceId下唯一就可以
parentId:父span的id,调用有层级关系,所以span作为调用节点的存储结构,也有层级关系,就像图3所示,跟踪链是采用跟踪树的形式来展现的,树的根节点就是调用调用的顶点,从开发者的角度来说,顶级span是从接入了Zipkin的应用中最先接触到服务调用的应用中采集的。所以,顶级span是没有parentId字段的
name:span的名称,主要用于在界面上展示,一般是接口方法名,name的作用是让人知道它是哪里采集的span,不然某个span耗时高我都不知道是哪个服务节点耗时高
timestamp:span创建时的时间戳,用来记录采集的时刻。
duration:持续时间,即span的创建到span完成最终的采集所经历的时间,除去span自己逻辑处理的时间,该时间段可以理解成对于该跟踪埋点来说服务调用的总耗时
annotations:基本标注列表,一个标注可以理解成span生命周期中重要时刻的数据快照,比如一个标注中一般包含发生时刻(timestamp)、事件类型(value)、端点(endpoint)等信息
事件类型
cs:客户端/消费者发起请求
cr:客户端/消费者接收到应答
sr:服务端/生产者接收到请求
ss:服务端/生产者发送应答
PS:这四种事件类型的统计都应该是Zipkin提供客户端来做的,因为这些事件和业务无关,这也是为什么跟踪数据的采集适合放到中间件或者公共库来做的原因。
binaryAnnotations:业务标注列表,如果某些跟踪埋点需要带上部分业务数据(比如url地址、返回码和异常信息等),可以将需要的数据以键值对的形式放入到这个字段中。
参考
| 2.返回顶部 |
| 3.返回顶部 |
| 4.返回顶部 |
| 5.返回顶部 |
| 6.返回顶部 |
 |
作者:ylbtech 出处:http://ylbtech.cnblogs.com/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 |
Java-Zipkin:Zipkin 介绍的更多相关文章
- 调用链系列一、Zipkin架构介绍、Springboot集承(springmvc,HttpClient)调用链跟踪、Zipkin UI详解
1.Zipkin是什么 Zipkin分布式跟踪系统:它可以帮助收集时间数据,解决在microservice架构下的延迟问题:它管理这些数据的收集和查找:Zipkin的设计是基于谷歌的Google Da ...
- JAVA基本类库介绍
我们曾经讲过,Java已经为编程者编制了许多类,这些类已经经过测试,基本上不存在错误,这些类都是我们编程的基础.如果不利用这些已存在的类,我们的 编程工作将变得异常复杂,所以我们应尽可能多的掌握Jav ...
- Java垃圾回收介绍(译)
在Java中,对象内存空间的分配与回收是由JVM中的垃圾回收进程自动完成的.与C语言不同的是,在Java中开发者不需要专门为垃圾回收写代码.这是使Java流行的众多特征之一,也帮助了程序员写出了更好的 ...
- Java Web开发介绍
转自:http://www.cnblogs.com/pythontesting/p/4963021.html Java Web开发介绍 简介 Java很好地支持web开发,在桌面上Eclipse RC ...
- [译]Java 垃圾回收介绍
说明:这篇文章来翻译来自于Javapapers 的Java Garbage Collection Introduction 在Java中,对象内存空间的分配与回收是由JVM中的垃圾回收进程自动完成的. ...
- Java高新技术 Myeclipse 介绍
Java高新技术 Myeclipse 介绍 知识概述: (1)Myeclipse开发工具介绍 (2)Myeclipse常用开发步骤详解 ...
- [Java并发编程(三)] Java volatile 关键字介绍
[Java并发编程(三)] Java volatile 关键字介绍 摘要 Java volatile 关键字是用来标记 Java 变量,并表示变量 "存储于主内存中" .更准确的说 ...
- java.util.concurrent介绍【转】
java.util.concurrent介绍 java.util.concurrent 包含许多线程安全.测试良好.高性能的并发构建块.不客气地说,创建 java.util.concurrent ...
- 【转】Spring学习---Bean配置的三种方式(XML、注解、Java类)介绍与对比
[原文]https://www.toutiao.com/i6594205115605844493/ Spring学习Bean配置的三种方式(XML.注解.Java类)介绍与对比 本文将详细介绍Spri ...
- Java EE平台介绍(译)
Java EE平台介绍 2.1 企业应用总览 这一部分将对企业应用及其设计和开发进行简单介绍. 就像之前说的,Java EE 平台是为了帮助开发者开发大规模.多层次.可伸缩.服务可靠.网络安全的应用而 ...
随机推荐
- java的原子变量
java的原子变量类似c++的InterlockedDecrement()操作.其实就是在进行算术时,把整个算式看为一个整体,并且保证同一时间只计算该式子一次. 它的用途比如,多个线程可能会调用某个函 ...
- VHDL之User-defined data types
VHDL allows the user to define own data types. 1 user-defined integer types -- This is indeed the pr ...
- DNN:windows使用 YOLO V1,V2
本文有修改,如有疑问,请移步原文. 原文链接: YOLO v1之总结篇(linux+windows) 此外: YOLO-V2总结篇 Yolo9000的改进还是非常大的 由于原版的官方YOLOv ...
- AI:IPPR的数学表示-CNN结构进化(Alex、ZF、Inception、Res、InceptionRes)
前言: 文章:CNN的结构分析-------: 文章:历年ImageNet冠军模型网络结构解析-------: 文章:GoogleLeNet系列解读-------: 文章:DNN结构演进Histor ...
- 图像局部显著性—点特征(GLOH)
基于古老的Marr视觉理论,视觉识别和场景重建的基础即第一阶段为局部显著性探测.探测到的主要特征为直觉上可刺激底层视觉的局部显著性--特征点.特征线.特征块. 相关介绍:局部特征显著性-点特征(SIF ...
- 实现Android-JNI本地C++调试
1. 原文链接:NDK单步调试方法 如有问题或者版权要求,请拜访原作者或者通知本人. 最近为了性能需求,开始搞JNI,白手起搞真心不容易.中间差点崩溃了好几次,最终总算得到一点心得. JN ...
- vue实现单页应用demo
vue + webpack +ES6/7 + axiso + vuex + vue-router构建项目前端,node + express + mongodb 开发后台 项目demo地址 https: ...
- 关于js开发中保留小数位计算函数(以向上取整或向下取整的方式保留小数)
前端工作中经常遇到数字计算保留小数问题,由于不是四舍五入的方式不能使用toFixed函数,本文采用正则表达式匹配字符串的方式,解决对数字的向上或向下保留小数问题: 1.向上保留小数(只要目标小数位后有 ...
- @dalao help!!!
- BZOJ 3744 Gty的妹子序列 (分块+树状数组+主席树)
题面传送门 题目大意:给你一个序列,多次询问,每次取出一段连续的子序列$[l,r]$,询问这段子序列的逆序对个数,强制在线 很熟悉的分块套路啊,和很多可持久化01Trie的题目类似,用分块预处理出贡献 ...