shp系列(三)——利用C++进行DBF文件的读(打开)
1.DBF文件要点
DBF文件又叫属性文件,也叫dBASE文件,文件后缀是.dbf,实际上ArcGIS打开后的属性表就是DBF的信息。DBF文件遵循以下几个条件:
- 每个要素在表中必须要包含一个与之相对应的记录。
- 记录的顺序必须与要素在主文件中(*.shp)的顺序一样。
- dBASE 文件头中的年份值必须要晚于 1900 年。
2.DBF文件的组成
属性文件(.dbf)用于记录属性信息。它是一个标准的DBF文件,也是由头文件和实体信息两部分构成:

3.DBF文件的头文件
文件头部分的长度是不定长的,它主要对DBF文件作了一些总体说明。
其中最主要的是对这个DBF文件的记录项(字段)的信息进行了详细地描述,比如对每个记录项(字段)的名称、数据类型、长度等信息都有具体的说明。
3.1头文件
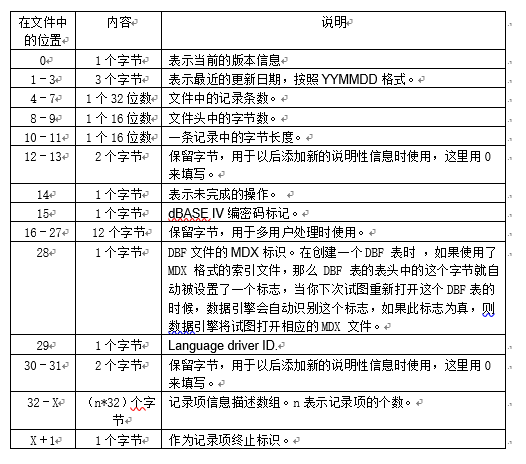
- date[3],BYTE,更新日期
- verision,BYTE类型,版本信息
- RecordNum,int,文件中记录条数
- HeaderByteNum,short,文件头的字节数
- RecordByteNum,short,一条记录的字节长度
- Reserved1,short
- Flag4s,BYTE
- EncrypteFlag,BYTE
- Unused[3],int,保留字节
- MDXFlag,BYTE,MDX标识
- LDriID,BYTE
- Reserved2,short
- RecordItem(记录项数组详情见下),32,字段描述信息
- terminator,BYTE,终止标识
- 头文件的字节数为:1 + 1 * 3 + 4 + 2 + 2 + 2 + 1 + 1 + 4 * 3 + 1 + 1 + 2 + 32 * RecordNum + 1 = 33 + 32 * RecordNum
3.2记录项数组
记录项数组其实就是描述表中字段信息的数组

- name[11],BYTE,字段名
- fieldType,BYTE,字段类型,包括B、C、D、G、L、M和N
- Reserved3,int
- fieldLength,BYTE,记录项长度
- decimalCount,BYTE,记录项精度
- Reserved4,short
- workID,BYTE
- Reserved5[5],short,
- mDXFflag1,BYTE
- 一个记录项字节数为:11 + 1 + 4 + 1 + 1 + 2 + 1 + 5 * 2 + 1 = 32
记录项描述信息中fieldType的类型说明

4.实体信息
实体信息部分就是一条条属性记录,每条记录都是由若干个记录项(字段)构成,因此只要依次循环读取每条记录就可以了。
5.读取DBF代码
由于实际上每个shp文件的表的字段数可能不一样,并且每个字段的类型不固定,需要每次判定字段类型,然后根据不同类型设置来读取信息。可以根据字段数量设置一个数组,数组的每个元素存储对应顺序字段的类型,然后根据数组元素的值定义变量获取记录的信息。
上述想法是一种比较完善的做法,即对于任何数量和类型的字段都可以满足要求,也应该是ArcGIS读取表的方法。完善即代表需要考虑各种情况,费时费力。
这里根据实际情况,简化一下,读取已知字段数和字段类型的DBF的信息。
假设要读取一个八个字段的表:
- int类型:ObjectID,Ecrm,Elevt
- double类型:shapeArea,shapeLength
- CString类型:Dest,Ec,cc
代码如下
void readDbf(CString filename)
{
//****在读取shp之后打开DBF文件
int n = filename.ReverseFind('.');
filename = filename.Left(n);
filename = filename + ".dbf";
FILE* m_DbfFile_fp;//****Dbf文件指针
if ((m_DbfFile_fp = fopen(filename, "rb")) == NULL)//打开dbf文件
return; //****读取dbf文件的文件头
int i, j;
BYTE version;
fread(&version, 1, 1, m_DbfFile_fp);
BYTE date[3];
for (i = 0; i<3; i++)
fread(date + i, 1, 1, m_DbfFile_fp); int RecordNum;//文件中的记录条数
fread(&RecordNum, sizeof(int), 1, m_DbfFile_fp);
short HeaderByteNum;//文件头中的字节数
fread(&HeaderByteNum, sizeof(short), 1, m_DbfFile_fp);
short RecordByteNum;//一条记录中的字节长度
fread(&RecordByteNum, sizeof(short), 1, m_DbfFile_fp);
short Reserved1;
fread(&Reserved1, sizeof(short), 1, m_DbfFile_fp);
BYTE Flag4s;
fread(&Flag4s, sizeof(BYTE), 1, m_DbfFile_fp);
BYTE EncrypteFlag;
fread(&EncrypteFlag, sizeof(BYTE), 1, m_DbfFile_fp);
int Unused[3];
for (i = 0; i<3; i++)
fread(Unused + i, sizeof(int), 1, m_DbfFile_fp);
int a = Unused[0];
int b = Unused[1];
int c = Unused[2]; BYTE MDXFlag;
fread(&MDXFlag, sizeof(BYTE), 1, m_DbfFile_fp);
BYTE LDriID;
fread(&LDriID, sizeof(BYTE), 1, m_DbfFile_fp);
short Reserved2;
fread(&Reserved2, sizeof(short), 1, m_DbfFile_fp);
BYTE name[11];
BYTE fieldType;
int Reserved3;
BYTE fieldLength;
BYTE decimalCount;
short Reserved4;
BYTE workID;
short Reserved5[5];
BYTE mDXFlag1;
int fieldscount;
fieldscount = (HeaderByteNum - 32) / 32;
fieldscount_final = fieldscount; //****读取记录项信息-共有8个记录项
for (i = 0; i< fieldscount; i++)//字段数
{
RecordItem recordItem; //定义记录项存储信息,便于写dbf使用 fread(name, 11, 1, m_DbfFile_fp); //FieldName----11 bytes
memcpy(recordItem.name, name, 11); fread(&fieldType, sizeof(BYTE), 1, m_DbfFile_fp); //FieldType----1 bytes
recordItem.fieldType = fieldType; fread(&Reserved3, sizeof(int), 1, m_DbfFile_fp); //Reserved3----4 bytes
recordItem.Reserved3 = Reserved3; fread(&fieldLength, sizeof(BYTE), 1, m_DbfFile_fp); //FieldLength--1 bytes
recordItem.fieldLength = fieldLength; fread(&decimalCount, sizeof(BYTE), 1, m_DbfFile_fp);//DecimalCount-1 bytes
recordItem.decimalCount = decimalCount; fread(&Reserved4, sizeof(short), 1, m_DbfFile_fp); //Reserved4----2 bytes
recordItem.Reserved4 = Reserved4; fread(&workID, sizeof(BYTE), 1, m_DbfFile_fp); //WorkID-------1 bytes
recordItem.workID = workID; for (j = 0; j<5; j++) //Reserved5----10 bytes
fread(Reserved5 + j, sizeof(short), 1, m_DbfFile_fp);
memcpy(recordItem.Reserved5, Reserved5, 10); fread(&mDXFlag1, sizeof(BYTE), 1, m_DbfFile_fp); //MDXFlag1-----1 bytes
recordItem.mDXFlag1 = mDXFlag1;
recordItems.push_back(recordItem);
}
BYTE terminator; //terminator----1 bytes
fread(&terminator, sizeof(BYTE), 1, m_DbfFile_fp);
//****读取dbf文件头结束 //****读取dbf文件记录 开始
int ObjectID, Ecrm, Elevt;
double shapeArea, shapeLength;
CString Dest, Ec, cc;
BYTE deleteFlag;
char media[40];
vector<CString> polygonAttribute;
vector<double> ShapeArea;
vector<int>temp1; for (i = 0; i<RecordNum; i++) {
fread(&deleteFlag, sizeof(BYTE), 1, m_DbfFile_fp); //读取删除标记 1字节 //****读取 ObjectID int
for (j = 0; j<40; j++)
strcpy(media + j, "\0");
for (j = 0; j<10; j++)
fread(media + j, sizeof(char), 1, m_DbfFile_fp); //--10
ObjectID = atoi(media); //****读取 Dest string
for (j = 0; j<40; j++)
strcpy(media + j, "\0");
for (j = 0; j<32; j++)
fread(media + j, sizeof(char), 1, m_DbfFile_fp); //--32
Dest = media; //****读取 Ec string
for (j = 0; j<40; j++)
strcpy(media + j, "\0");
for (j = 0; j<16; j++)
fread(media + j, sizeof(char), 1, m_DbfFile_fp); //--16
Ec = media;//同上 //****读取 EcRm int
for (j = 0; j<40; j++)
strcpy(media + j, "\0");
for (j = 0; j<10; j++)
fread(media + j, sizeof(char), 1, m_DbfFile_fp); //--10
Ecrm = atoi(media); //****读取 Elevt int
for (j = 0; j<40; j++)
strcpy(media + j, "\0");
for (j = 0; j<10; j++)
fread(media + j, sizeof(char), 1, m_DbfFile_fp); //--10
Elevt = atoi(media); //****读取 Cc int
for (j = 0; j<40; j++)
strcpy(media + j, "\0");
for (j = 0; j<8; j++)
fread(media + j, sizeof(char), 1, m_DbfFile_fp); //--8
cc = media;//4值4'' //****读取 shape_length double
for (j = 0; j<40; j++)
strcpy(media + j, "\0");
for (j = 0; j<19; j++)
fread(media + j, sizeof(char), 1, m_DbfFile_fp); //--19
shapeLength = atof(media);//带e的 //****读取 shape_Area double
for (j = 0; j<40; j++)
strcpy(media + j, "\0");
for (j = 0; j<19; j++)
fread(media + j, sizeof(char), 1, m_DbfFile_fp); //--19
shapeArea = atof(media);
}
//****读取dbf文件记录 结束
}
这是在已知字段数和字段类型情况下读取的情况,如果未知的情况下,需要设置数组存储每个字段的类型,则数组的长度就是字段数量;在读取实体记录时,根据数组的每个元素的值设定对应类型的变量,来存储记录信息,必要时最后结果要转化(如字符型转化成整型)。这一部分大家可以自己去完善。
下一篇我们将讲述shx文件的读取。
shp系列(三)——利用C++进行DBF文件的读(打开)的更多相关文章
- shp系列(六)——利用C++进行Dbf文件的写(创建)
上一篇介绍了shp文件的创建,接下来介绍dbf的创建. 推荐结合读取dbf的博客一起看! 推荐结合读取dbf的博客一起看! 推荐结合读取dbf的博客一起看! 1.Dbf头文件的创建 Dbf头文件的结构 ...
- shp系列(四)——利用C++进行Shx文件的读(打开)
1.shx文件的基本情况 shx文件又叫索引文件,主要包含坐标文件的索引信息,文件中每个记录包含对应的坐标文件记录距离坐标文件的初始位置的偏移量.通过索引文件可以很方便地在坐标文件中定位到指定目标的坐 ...
- python常识系列07-->python利用xlwt写入excel文件
前言 读书之法,在循序而渐进,熟读而精思.--朱熹 抽空又来写一篇,毕竟知识在于分享! 一.xlwt模块是什么 python第三方工具包,用于往excel中写入数据:(ps:只能创建新表格,不能修改表 ...
- ArcGis 属性表.dbf文件使用Excel打开中文乱码的解决方法
2019年4月 拓展: ArcGis——好好的属性表,咋就乱码了呢? 2019年3月27日补充: 在ArcMap10.3+(根据官网描述应该是,作者测试使用10.5,可行)以后的版本,可以使用ArcT ...
- 解决Arcgis10.2.2中dbf文件用EXCEL打开乱码问题
1.开始 -- 运行,输入”Regedit“,打开 注册表 . 2.如是用的是 10.x 版本 ArcGIS Desktop,定位到 ‘计算机\HKEY_CURRENT_USER\Software\E ...
- C#利用NPOI操作Excel文件
NPOI作为开源免费的组件,功能强大,可用来读写Excel(兼容xls和xlsx两种版本).Word.PPT文件.可是要让我们记住所有的操作,这便有点困难了,至此,总结一些在开发中常用的针对Excel ...
- shp系列(一)——利用C++进行shp文件的读(打开)与写(创建)开言
博客背景和目的 最近在用C++写一个底层的东西,需要读取和创建shp文件.虽然接触shp文件已经几年了,但是对于shp文件内到底包含什么东西一直是一知半解.以前使用shp文件都是利用软件(如ArcGI ...
- shp系列(七)——利用C++进行Shx文件的写(创建)
之前介绍了Shp文件和Dbf的写(创建),最后来介绍一下Shx文件的写(创建).Shx文件是三者之中最简单的一个,原因有两个:第一是Shx文件的头文件与Shp文件的头文件几乎一样(除了FileLeng ...
- shp系列(五)——利用C++进行shp文件的写(创建)
之前介绍了shp文件.dbf文件和shx文件的的读取,接下来将分别介绍它们的创建过程.一般来说,读和写的一一对应的,写出的文件就是为了保存数据供以后读取的.写的文件要符合shapefile的标准.之前 ...
随机推荐
- php数据库增删改查
首先建立一个数据库db_0808,将db_0808中表格student导入网页. CURD.php <!DOCTYPE html> <html lang="en" ...
- Linux rsync配置用于服务器之间传输大量的数据
Linux的rsync 配置,用于服务器之间远程传大量的数据 [教程主题]:rsync [课程录制]: 创E [主要内容] [1] rsync介绍 Rsync(Remote Synchronize ...
- IOS 监控网络变化案例源码
随着移动网络升级:2G->3G->4G甚至相传正在研发的5G,网络速度是越来越快,但这流量也像流水一般哗哗的溜走. 网上不是流传一个段子:睡觉忘记关流量,第二天房子就归移动了! 这固然是一 ...
- centos开机运行级别更改
1.使用命令切换运行级别/目标 # systemctl isolate multi-user.target //切换到运行级别3,该命令对下次启动无影响,等价于telinit 3 # systemct ...
- dubbo之多协议
(1) 不同服务不同协议 比如:不同服务在性能上适用不同协议进行传输,比如大数据用短连接协议,小数据大并发用长连接协议 consumer.xml <?xml version="1.0& ...
- Everything is a file
"Everything is a file" describes one of the defining features of Unix, and its derivatives ...
- vue http请求 vue自带的 vue-resource
vue-resource安装 npm install vue-resource --save-dev 配置 在main.js中引入插件 //Resource 为自定义名 vue-resource 为插 ...
- [IOI2007]矿工配餐
状态是f[i][a][b][c][d]表示第i个餐车,1号矿洞最近两顿是a,b,2号矿洞最近两顿是c,d. 给的空间是16MB,滚动数组滚动了第一维就行了 (给的变量是char是因为这个不超过256, ...
- Java 动态实现word导出功能
1.word模板:xx.ftl生成,ftl文件就是word的源代码,类似html一样是拥有标签和样式的代码. 把需要导出的doc文件模板用office版本的word工具打开. 把doc文件另存为xx. ...
- __call__ 和 __str__ 魔术方法
魔术方法,在python中,是通过触发的形式调用,之所以称为魔术方法,是因为不需要特地的打印或调用它,在某些特定的时候,他会自己调用,所谓的特定的时候,也是我们自己所输入的代码操作的,不是莫名其妙的触 ...