机器学习经典算法之KNN
/*请尊重作者劳动成果,转载请标明原文链接:*/
/* https://www.cnblogs.com/jpcflyer/p/11111817.html * /

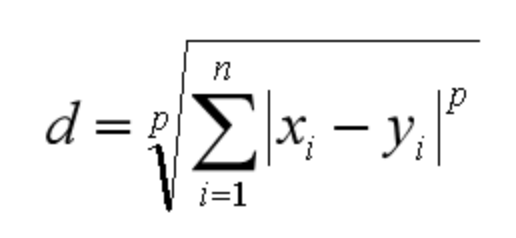
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neighbors import KNeighborsRegressor
# 加载数据
digits = load_digits()
data = digits.data
# 数据探索
print(data.shape)
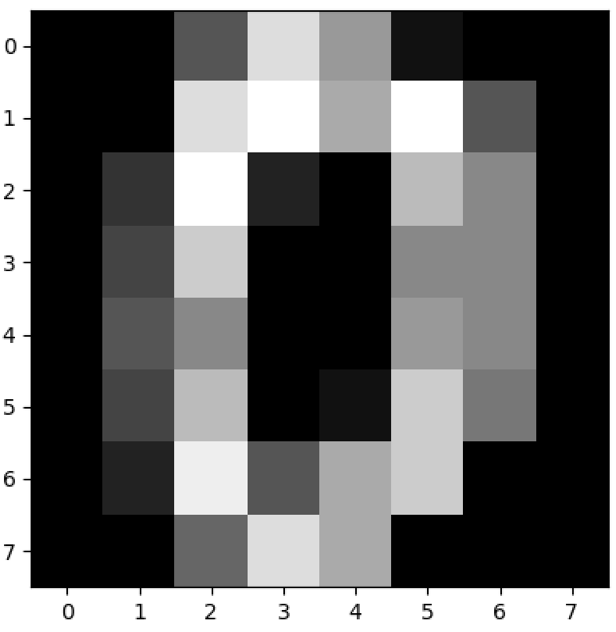
# 查看第一幅图像
print(digits.images[0])
# 第一幅图像代表的数字含义
print(digits.target[0])
# 将第一幅图像显示出来
plt.gray()
plt.imshow(digits.images[0])
plt.show()
(1797, 64)
[[ 0. 0. 5. 13. 9. 1. 0. 0.]
[ 0. 0. 13. 15. 10. 15. 5. 0.]
[ 0. 3. 15. 2. 0. 11. 8. 0.]
[ 0. 4. 12. 0. 0. 8. 8. 0.]
[ 0. 5. 8. 0. 0. 9. 8. 0.]
[ 0. 4. 11. 0. 1. 12. 7. 0.]
[ 0. 2. 14. 5. 10. 12. 0. 0.]
[ 0. 0. 6. 13. 10. 0. 0. 0.]]
0
# 分割数据,将 25% 的数据作为测试集,其余作为训练集(你也可以指定其他比例的数据作为训练集)
train_x, test_x, train_y, test_y = train_test_split(data, digits.target, test_size=0.25, random_state=33)
# 采用 Z-Score 规范化
ss = preprocessing.StandardScaler()
train_ss_x = ss.fit_transform(train_x)
test_ss_x = ss.transform(test_x)
然后我们构造一个 KNN 分类器 knn,把训练集的数据传入构造好的 knn,并通过测试集进行结果预测,与测试集的结果进行对比,得到 KNN 分类器准确率,代码如下:
# 创建 KNN 分类器
knn = KNeighborsClassifier()
knn.fit(train_ss_x, train_y)
predict_y = knn.predict(test_ss_x)
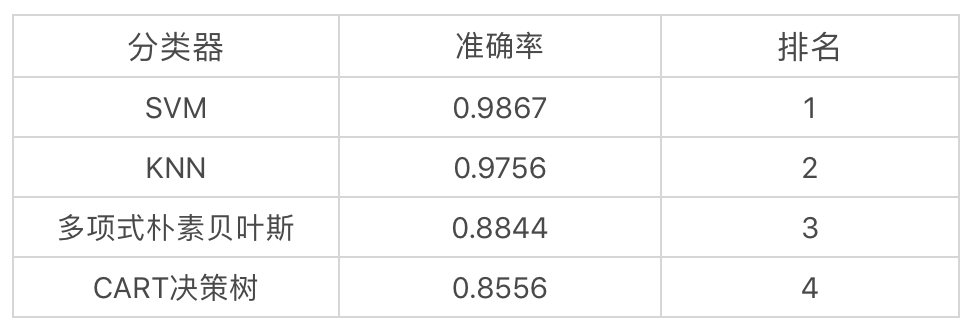
print("KNN 准确率: %.4lf" % accuracy_score(predict_y, test_y))
KNN 准确率: 0.975
# 创建 SVM 分类器
svm = SVC()
svm.fit(train_ss_x, train_y)
predict_y=svm.predict(test_ss_x)
print('SVM 准确率: %0.4lf' % accuracy_score(predict_y, test_y))
# 采用 Min-Max 规范化
mm = preprocessing.MinMaxScaler()
train_mm_x = mm.fit_transform(train_x)
test_mm_x = mm.transform(test_x)
# 创建 Naive Bayes 分类器
mnb = MultinomialNB()
mnb.fit(train_mm_x, train_y)
predict_y = mnb.predict(test_mm_x)
print(" 多项式朴素贝叶斯准确率: %.4lf" % accuracy_score(predict_y, test_y))
# 创建 CART 决策树分类器
dtc = DecisionTreeClassifier()
dtc.fit(train_mm_x, train_y)
predict_y = dtc.predict(test_mm_x)
print("CART 决策树准确率: %.4lf" % accuracy_score(predict_y, test_y))
SVM 准确率: 0.9867
多项式朴素贝叶斯准确率: 0.8844
CART 决策树准确率: 0.8556
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_digits
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import MultinomialNB
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
机器学习经典算法之KNN的更多相关文章
- Python3实现机器学习经典算法(二)KNN实现简单OCR
一.前言 1.ocr概述 OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗.亮的模式确定其形状,然 ...
- Python3实现机器学习经典算法(一)KNN
一.KNN概述 K-(最)近邻算法KNN(k-Nearest Neighbor)是数据挖掘分类技术中最简单的方法之一.它具有精度高.对异常值不敏感的优点,适合用来处理离散的数值型数据,但是它具有 非常 ...
- 机器学习经典算法具体解释及Python实现--K近邻(KNN)算法
(一)KNN依旧是一种监督学习算法 KNN(K Nearest Neighbors,K近邻 )算法是机器学习全部算法中理论最简单.最好理解的.KNN是一种基于实例的学习,通过计算新数据与训练数据特征值 ...
- Python3入门机器学习经典算法与应用
<Python3入门机器学习经典算法与应用> 章节第1章 欢迎来到 Python3 玩转机器学习1-1 什么是机器学习1-2 课程涵盖的内容和理念1-3 课程所使用的主要技术栈第2章 机器 ...
- Python3实现机器学习经典算法(三)ID3决策树
一.ID3决策树概述 ID3决策树是另一种非常重要的用来处理分类问题的结构,它形似一个嵌套N层的IF…ELSE结构,但是它的判断标准不再是一个关系表达式,而是对应的模块的信息增益.它通过信息增益的大小 ...
- 机器学习经典算法具体解释及Python实现--线性回归(Linear Regression)算法
(一)认识回归 回归是统计学中最有力的工具之中的一个. 机器学习监督学习算法分为分类算法和回归算法两种,事实上就是依据类别标签分布类型为离散型.连续性而定义的. 顾名思义.分类算法用于离散型分布预測, ...
- Python3入门机器学习经典算法与应用☝☝☝
Python3入门机器学习经典算法与应用 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 使用新版python3语言和流行的scikit-learn框架,算法与 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- Python3实现机器学习经典算法(四)C4.5决策树
一.C4.5决策树概述 C4.5决策树是ID3决策树的改进算法,它解决了ID3决策树无法处理连续型数据的问题以及ID3决策树在使用信息增益划分数据集的时候倾向于选择属性分支更多的属性的问题.它的大部分 ...
随机推荐
- struts2 no extension(excludePattern)
采用struts2 小伙伴非常希望更改或删除action扩展,本文将帮助你实现 struts2-core-2.3.16.jar , 下载链接: http://repo1.maven.org/maven ...
- 在python3下用PIL做图像处理
Python Imaging Library (PIL)是python下的图像处理模块,支持多种格式,并提供强大的图形与图像处理功能. 目前PIL的官方最新版本为1.1.7,支持的版本为python ...
- MFC中获取App,MainFrame,Doc和View类等指针的方法
From: http://hi.baidu.com/wxnxs/item/156a68f5b3b4ed18e3e3bd03 MFC中获取App,MainFrame,Doc和View类等指针的方法 ...
- 第一个spring boot工程
参考. 1. 碰到的问题: -出现bind:address already in use是因为当前项目正在运行,停掉当前项目即可.cmd中命令 netstat -nao 查看所有占用的端口及PID号, ...
- node 后台管理插件forever
在一台计算机上手动跑Node项目简单,node xx.js就搞定了,想让Node项目后台运行,虽然不能直接用node命令搞定,但是在安装了forever这个包以后,还是很轻松的.不过要是在远程服务器上 ...
- WPF GridSplitter最好设置HorizontalAlignment和VerticalAlignment,否则不可以左右移动
<Window x:Class="XamlTest.Window5" xmlns="http://schemas.microsoft.com/winf ...
- 【WPF】SnapsToDevicePixels与UseLayoutRounding二者到底有什么区别?供参考
原文:[WPF]SnapsToDevicePixels与UseLayoutRounding二者到底有什么区别?供参考 MSDN上解释了一大堆,二者对比来看,并不能发现什么明显的区别,微软爸爸也不知道多 ...
- Win8Metro(C#)数字图像处理--2.13Roberts边缘检测
原文:Win8Metro(C#)数字图像处理--2.13Roberts边缘检测 [函数名称] 图像Roberts边缘检测函数RobertEdgeProcess(WriteableBitmap s ...
- 基于EF6的快速开发Web框架——Swift.Net
Swift.Net This Is A Light-Weight And Fast-Develop .Net Framework. Usage STEP 1 Create Your Entities ...
- C#匹配中文字符串的4种正则表达式分享
本文介绍在C#中使用匹配中文的正则表达式,包括纯中文.有中文.中文开头.中文结尾等几个正则表达式示例.在正则表达式中,中文可以通过Unicode编码来确定正则表达式范围. 在C#中,匹配中文的正则表达 ...