AdaBoost算法原理及OpenCV实例
备注:OpenCV版本 2.4.10
在数据的挖掘和分析中,最基本和首要的任务是对数据进行分类,解决这个问题的常用方法是机器学习技术。通过使用已知实例集合中所有样本的属性值作为机器学习算法的训练集,导出一个分类机制后,再使用这个分类机制判别一个新实例的属性,并且可以通过不间断的学习,持续丰富和优化该分类机制,使机器具有像大脑一样的思考能力。
常用的分类方法有决策树分类、贝叶斯分类等。然而这些方法存在的问题是当数据量巨大时,分类的准确率不高。对于这样的困难问题,Boosting及其衍生算法提供了一个理想的解决途径。
Boosting算法是一种把若干个分类器整合为一个分类器的方法,其基本思想是:把一个复杂的分类任务分配给多位专家进行判断。这些专家可能并不是真正的专家,而仅仅是比普通人专业一点,他们称为弱分类器,依据一定机制,综合各位专家的结论,形成强分类器,得到最终的判断。
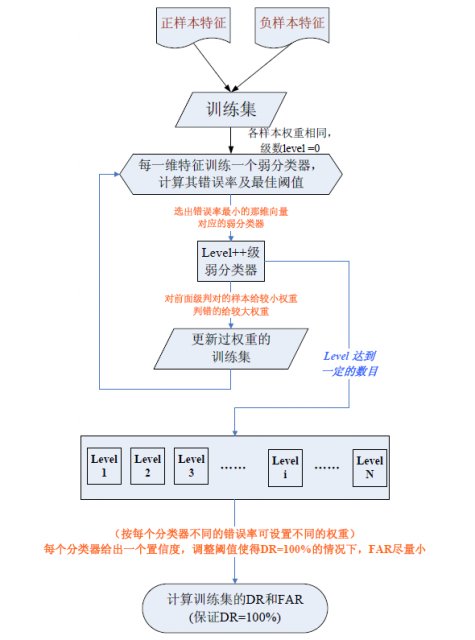
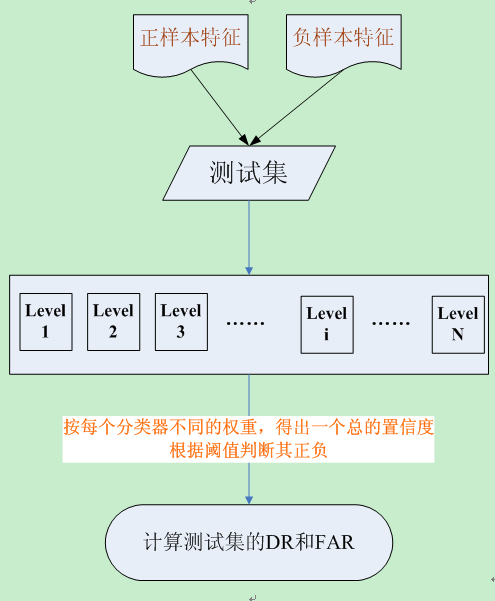
Boosting算法中应用最为广泛也最为有效的是1995年提出的AdaBoost(Adaptive Boosting,自适应增强)方法,其自适应之处在于前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个分类器,每一轮训练都会产生一个弱分类器,直到达到某个预订的足够小的错误率或者达到预先定义的最大迭代次数。
具体来说,整个AdaBoost迭代算法分为3步:
- 初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。
- 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
#include "opencv2/core/core.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/ml/ml.hpp"
#include <iostream>
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
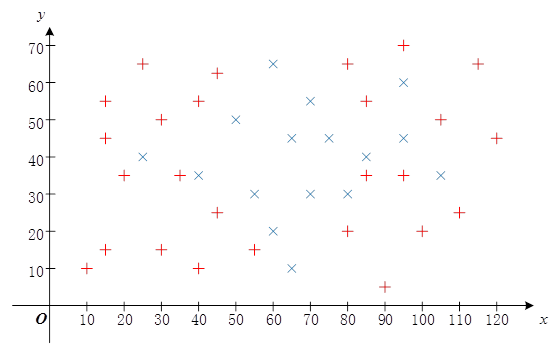
//训练样本
float trainingData[42][2]={ {40, 55},{35, 35},{55, 15},{45, 25},{10, 10},{15, 15},{40, 10},
{30, 15},{30, 50},{100, 20},{45, 65},{20, 35},{80, 20},{90, 5},
{95, 35},{80, 65},{15, 55},{25, 65},{85, 35},{85, 55},{95, 70},
{105, 50},{115, 65},{110, 25},{120, 45},{15, 45},
{55, 30},{60, 65},{95, 60},{25, 40},{75, 45},{105, 35},{65, 10},
{50, 50},{40, 35},{70, 55},{80, 30},{95, 45},{60, 20},{70, 30},
{65, 45},{85, 40} };
Mat trainingDataMat(42, 2, CV_32FC1, trainingData);
//训练样本的响应值
float responses[42] = {'R','R','R','R','R','R','R','R','R','R','R','R','R','R','R','R',
'R','R','R','R','R','R','R','R','R','R',
'B','B','B','B','B','B','B','B','B','B','B','B','B','B','B','B' };
Mat responsesMat(42, 1, CV_32FC1, responses);
float priors[2] = {1, 1}; //先验概率
CvBoostParams params( CvBoost::REAL, // boost_type
10, // weak_count
0.95, // weight_trim_rate
15, // max_depth
false, // use_surrogates
priors // priors
);
CvBoost boost;
boost.train ( trainingDataMat,
CV_ROW_SAMPLE,
responsesMat,
Mat(),
Mat(),
Mat(),
Mat(),
params
);
//预测样本
float myData[2] = {55, 25};
Mat myDataMat(2, 1, CV_32FC1, myData);
double r = boost.predict( myDataMat );
cout<<endl<<"result: "<<(char)r<<endl;
return 0;
} 输出结果为R,即测试坐标点(55,25)被分类为Red。
AdaBoost算法原理及OpenCV实例的更多相关文章
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- AdaBoost算法原理简介
AdaBoost算法原理 AdaBoost算法针对不同的训练集训练同一个基本分类器(弱分类器),然后把这些在不同训练集上得到的分类器集合起来,构成一个更强的最终的分类器(强分类器).理论证明,只要每个 ...
- Python实现的选择排序算法原理与用法实例分析
Python实现的选择排序算法原理与用法实例分析 这篇文章主要介绍了Python实现的选择排序算法,简单描述了选择排序的原理,并结合实例形式分析了Python实现与应用选择排序的具体操作技巧,需要的朋 ...
- 集成学习之Adaboost算法原理
在boosting系列算法中,Adaboost是最著名的算法之一.Adaboost既可以用作分类,也可以用作回归. 1. boosting算法基本原理 集成学习原理中,boosting系列算法的思想:
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 机器学习之Adaboost算法原理
转自:http://www.cnblogs.com/pinard/p/6133937.html 在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习 ...
- 基于单层决策树的AdaBoost算法原理+python实现
这里整理一下实验课实现的基于单层决策树的弱分类器的AdaBoost算法. 由于是初学,实验课在找资料的时候看到别人的代码中有太多英文的缩写,不容易看懂,而且还要同时看代码实现的细节.算法的原理什么的, ...
- AdaBoost 算法原理及推导
AdaBoost(Adaptive Boosting):自适应提升方法. 1.AdaBoost算法介绍 AdaBoost是Boosting方法中最优代表性的提升算法.该方法通过在每轮降低分对样例的权重 ...
- 随机森林算法原理及OpenCV应用
随机森林算法是机器学习.计算机视觉等领域内应用较为广泛的一个算法.它不仅可以用来做分类(包括二分类和多分类),也可用来做回归预测,也可以作为一种数据降维的手段. 在随机森林中,将生成很多的决策树,并不 ...
随机推荐
- 解决Linux动态库版本兼容问题
说道“动态库版本兼容”,很多人头脑中首先蹦出的就是“Dll Hell”.啊,这曾经让人头疼的难题.时至今日,这个难题已经很好地解决了. 在进一步讨论之前来思考一个问题:Linux下为什么没有让人头痛的 ...
- vue学习笔记三:常见的表单绑定
<template> <div id="app"> <input type="checkbox" id="checked ...
- 轻松掌握ISO8583报文协议
http://www.itpub.net/thread-419521-1-1.html 我刚进入金融行业时,就知道了IS08583报文协议,我想可能我还没进入这个行业都已经听过了,可知ISO8583的 ...
- signature.html
原文网址:http://www.youdzone.com/signature.html 阮一峰:http://www.ruanyifeng.com/blog/2011/08/what_is_a_d ...
- [Recompose] Transform Props using Recompose --mapProps
Learn how to use the 'mapProps' higher-order component to modify an existing component’s API (its pr ...
- hdu 1166 敌兵布阵 线段树 点更新
// hdu 1166 敌兵布阵 线段树 点更新 // // 这道题裸的线段树的点更新,直接写就能够了 // // 一直以来想要进线段树的坑,结果一直没有跳进去,今天算是跳进去吧, // 尽管十分简单 ...
- swift学习第一天:认识swift以及swift的常量和变量
一:认识swift // 1.导入框架 //#import <UIKit/UIKit.h> import UIKit // 2.定义一个标识符 // int a = 10; // swif ...
- Hibernate的ID主键生成策略
ID生成策略(一) 通过XML配置实现ID自己主动生成(測试uuid和native) 之前我们讲了除了通过注解的方式来创建一个持久化bean外.也能够在须要持久化的bean的包路径下创建一个与bean ...
- 【u213&&t037】修剪花卉
Time Limit: 1 second Memory Limit: 128 MB [问题描述] ZZ对数学饱有兴趣,并且是个勤奋好学的学生,总是在课后留在教室向老师请教一些问题. 一天他早晨骑车去上 ...
- 一大波Java来袭(四)String类、StringBuilder类、StringBuffer类对照
本文主要介绍String类.StringBuffer类.StringBuilder类的差别 : 一.概述 (一)String 字符串常量.可是它具有不可变性,就是一旦创建,对它进行的不论什么改动操作 ...