storm(二)消息的可靠处理
storm 通过 trident保证了对消息提供不同的级别。beast effort,at least once, exactly once。
一个tuple 从spout流出,可能会导致大量的tuple被创建。如下面的单词统计
- TopologyBuilder builder = new TopologyBuilder();
- builder.setSpout("sentences", new KestrelSpout("kestrel.backtype.com",
- 22133,
- "sentence_queue",
- new StringScheme()));
- builder.setBolt("split", new SplitSentence(), 10)
- .shuffleGrouping("sentences");
- builder.setBolt("count", new WordCount(), 20)
- .fieldsGrouping("split", new Fields("word"));
storm任务会从数据源(kestrel queue)读取一个完整的英文句子,将句子按照空格分解为一个个的单词,然后再发送之前计算的单词的数量,从spout中流出的一个tuple会触发创建许多的tuples;一个tuple对应句子中的一个单词,一个tuple对应每个单词的count。这些tuple构成一个树状结构,如下图所示:
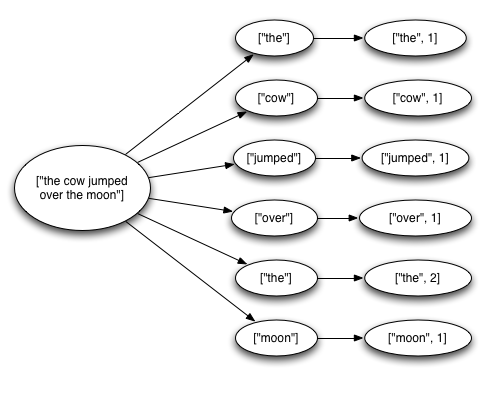
storm怎么会认为一个从spout中发送出来的消息被完全处理呢?
当tuple tree 不在生长
tree中的任何消息被标记为“已处理”
当一个tuple tree 没有在特定的时间内完全处理,tuple就会被认为是失败的 。可以指定在topology上使用Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS来配置这个超时时间,并且默认为30秒。
消息的生命周期
如果消息被完整处理或未能完全处理,会发生什么?我们先看下spout的生命周期
- public interface ISpout extends Serializable {
- void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
- void close();
- void nextTuple();
- void ack(Object msgId);
- void fail(Object msgId);
- }
首先storm 请求一个spout中的tuple,使用spout里面的nextTuple方法。 spout使用SpoutOutputCollector提供的open方法,发送tuple输出到outputstreams的其中一个。当发送tuple的时候,spout会提供一个“message id”,用于以后标识tuple。例如,我们从kestrel队列中读取消息,Spout会将kestrel 队列为这个消息设置的ID作为此消息的message ID。 向SpoutOutputCollector中发送消息格式如下:
- _collector.emit(new Values("field1", "field2", 3) , msgId);
接下来,tuple会背送到消费的bolts中,storm开始监控创建 the tree of message.如果storm检测到tuple被完全处理,Spout 上根据message id 调用 ack 方法.同样的,如果处理 tuple超时了,Storm会调用在 Spout 上调用 fail 方法。一个消息只会由发送它的那个spout任务来调用ack或fail。如果系统中某个spout由多个任务运行,消息也只会由创建它的spout任务来应答(ack或fail),绝不会由其他的spout的任务来应答。
为了使用Storm提供的可靠处理特性,我们需要做两件事情:
- 无论何时在tuple tree中创建了一个新的节点,我们需要明确的通知Storm;
- 当处理完一个单独的消息时,我们需要告诉Storm 这棵tuple tree的变化状态。
- public class SplitSentence extends BaseRichBolt {
- OutputCollector _collector;
- public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
- _collector = collector;
- }
- public void execute(Tuple tuple) {
- String sentence = tuple.getString(0);
- for(String word: sentence.split(" ")) {
- _collector.emit(tuple, new Values(word));
- }
- _collector.ack(tuple);
- }
- public void declareOutputFields(OutputFieldsDeclarer declarer) {
- declarer.declare(new Fields("word"));
- }
- }
通过指定输入 tuple 作为emit 的第一个参数,每一个word tuple 就会被 锚定(anchored).由于 word tuple 被 锚定(anchor),如果 word tuple 下游处理失败,tuple tree 的根节点会重新处理.相比之下,我们看一下 word tuple像下面这样发送.
- _collector.emit(new Values(word));
这种方式发送 word tuple 不会被锚定(unanchored). 如果tuple在处理下游的时候失败,根节点的 tuple不会重新处理.根据你的 topology(拓扑)需要来保证容错保证,有时候发送一个 unanchored tuple 也比较适合.
输出的tuple可以 锚定(anchor) 多个input tuple,当join和聚合的时候,这是比较有用的.一个 multi-anchored 的tuple处理失败后,多个tuple都会被重新处理.通过指定一系列 tuples,而不是单个tuple来完成 Multi-anchoring.例如:
- List<Tuple> anchors = new ArrayList<Tuple>();
- anchors.add(tuple1);
- anchors.add(tuple2);
- _collector.emit(anchors, new Values(1, 2, 3));
Multi-anchoring 会添加 output tuple 到 multiple tuple trees.这就可能会破坏树形结构,创建了tuple DAGs,像这样:
- List<Tuple> anchors = new ArrayList<Tuple>();
- anchors.add(tuple1);
- anchors.add(tuple2);
- _collector.emit(anchors, new Values(1, 2, 3));
Multi-anchoring 会添加 output tuple 到 multiple tuple trees.这就可能会破坏树形结构,创建了tuple DAGs(有向无环图),像这样:
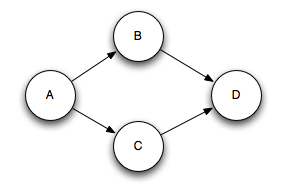
Storm 的实现适用于DAG和树(pre-release 只适用于trees,称为“tuple tree”)
OutputCollector 的 fail 方法,立即设置 tuple tree的根节点spout tuple为失败状态.例如,你的应用可能数据库异常,需要显式的 fail input tuple。通过显式的failing,spout tuple 可以比等待tuple超时速度更快.
- public class SplitSentence extends BaseBasicBolt {
- public void execute(Tuple tuple, BasicOutputCollector collector) {
- String sentence = tuple.getString(0);
- for(String word: sentence.split(" ")) {
- collector.emit(new Values(word));
- }
- }
- public void declareOutputFields(OutputFieldsDeclarer declarer) {
- declarer.declare(new Fields("word"));
- }
- }
之前的代码是
- public class SplitSentence extends BaseRichBolt {
- OutputCollector _collector;
- public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
- _collector = collector;
- }
- public void execute(Tuple tuple) {
- String sentence = tuple.getString(0);
- for(String word: sentence.split(" ")) {
- _collector.emit(tuple, new Values(word));
- }
- _collector.ack(tuple);
- }
- public void declareOutputFields(OutputFieldsDeclarer declarer) {
- declarer.declare(new Fields("word"));
- }
- }
该实现比以前的实现更简单,语义上相同。发送到 BasicOutputCollector 的 tuple 将自动 锚定(anchor) 到输入消息,并且,当execute执行完毕的时候,会自动应答输入消息。很多情况下,一个消息需要延迟应答,例如聚合或者是join。只有根据一组输入消息得到一个结果之后,才回应答之前所有的输入消息。并且聚合和join大部分时候对输出消息都是多重锚定。然而,这些特性不是IBasicBolt所能处理的
高效的实现tuple tree
storm系统中有一组叫做“acker”的特殊的任务,他们负责跟踪DAG(有向无环图)中的每个消息。每当发现一个DAG被完全处理,它就向创建这个跟消息的spout任务发送一个信息。拓扑中acker任务的并行度可以通过配置参数Config.TOPOLOGY_ACKERS来设置。默认的acker任务并行度为1.当系统中有大量的消息时,应该适当提高acker任务的并发度。
每个消息都知道它所在的tuple tree对应的根消息的id。每当bolt新生成一个消息,对应tuple tree中的根消息的messageID就拷贝到这个消息中。当这个消息被应答的时候,它就把关于tuple tree变化的信息发送给跟踪这棵树的acker。例如,他会告诉acker;本消息已经处理完毕,但是我派生出了一些新的消息帮忙跟踪一下。

Storm 跟踪 tuple trees 有一些细节.如前面所述,你可以在 topology中定义任意数量的 acker 任务。这导致了以下问题:当一个元组在 topology 中被 acked后,它如何知道是哪个 acker 任务发送的该消息?
系统使用一种哈希算法来根据spout消息的messageID来确定由哪个acker跟踪此消息派生出来的tuple tree。因为每个消息都知道与之对应的根消息的messageID,因此它知道应该与哪个acker通信。当spout发送一个消息的时候,它就通知对应的acker一个新的根消息就产生了,这时acker就会创建一个新的tuple tree。当acker发现这颗树被完全处理之后,它就会通知对应的spout任务。
tuple是如何倍跟踪的? 系统中有成千上万的消息,如果为每个spout发送的消息都构建一棵树的话,很快内存就会被耗尽。所以,必须采用不同的策略来跟踪每个消息。由于使用了新的跟踪算法,storm只需要固定的内存(大约20字节)就可以跟踪一棵树。这个算法是storm正确运行的核心。
acker任务保存了spout消息id到一对值的映射。第一个值就是spout的任务id,通过这个id,acker就知道消息处理完成时该通知那个spout任务。第二个值是一个64bit的数字,我们称之为ack val,它是树中所有消息的随机id的异或结果。ack val 表示了整棵树的状态,无论这棵树多大,只需要这个固定大小的水准就可以跟踪整棵树
假设你每秒钟发送一万个消息,从概率上说,至少需要50,000,000年才会有机会发生一次错误。即使如 此,也只有在这个消息确实处理失败的情况下才会有数据的丢失!
选择合适的级别
acker任务是轻量级的,所以在拓扑中并不需要太多的acker存在,可以通过storm UI来观察acker任务的吞吐量,如果看上去吞吐量不够的话,说明需要添加一些额外的acker。
如果你并不要求每个消息必须被处理(允许在处理过程中丢失一些消息),那么可以关闭消息的可靠处理机制,从而可以获取较好的性能。关闭消息的可靠 处理机制意味着系统中的消息数会减半(每个消息不需要应答了)。另外,关闭消息的可靠处理可以减少消息的大小(不需要每个tuple记录它的根id了), 从而节省带宽。
有三种方法可以关闭消息的可靠处理机制:
- 将参数Config.TOPOLOGY_ACKERS设置为0,通过此方法,当spout发送一个消息的时候,它的ack方法将立刻被调用。
- spout发送一个消息时,不指定此消息的messageID。当需要关闭特定消息可靠性的时候,可以使用此方法
- 如果不在意某个消息派生出来的 子孙消息的可靠性,则此消息派生出来的子消息在发送时不要做锚定,即在emit方法中不指定输入消息。因为这些子孙消息没有被锚定在任何tuple tree中,因此他们的失败不会引起任何spout重新发送消息。
集群的各级容错
1. 任务级失败
因为bolt任务crash引起的消息未被应答。此时,acker中所有与此bolt任务关联的消息都会因为超时而失败,对应spout的fail方法将被调用。
- acker任务失败。如果acker任务本身失败了,它在失败之前持有的所有消息都将会因为超时而失败。Spout的fail方法将被调用。
- Spout任务失败。这种情况下,Spout任务对接的外部设备(如MQ)负责消息的完整性。例如当客户端异常的情况下,kestrel队列会将处于pending状态的所有的消息重新放回到队列中。
2. 任务槽(slot)故障
- worker失败。每个worker中包含数个bolt(或spout)任务。supervisor负责监控这些任务,当我让客人失败后,supervisor负责监控这些任务,当worker失败后,supervisor会尝试在本机重启它。
- supervisor失败。supervisor是无状态的,因此supervisor的失败不会影响当前正在运行的任务,只要及时的将它重新启动即可。supervisor不是自举的,需要外部监控来及时重启。
- nimbus失败。nimbus是无状态的,因此nimbus的失败不会影响当前正在运行的任务(nimbus失败时,无法提交新的任务),只要及时的将它重新启动即可。nimbus不是自举的,需要外部监控来及时重启。
3. 集群节点(机器)故障
- storm集群中的节点故障。此时nimbus会将此机器上机器上所有正在运行的任务转移到其他可用的机器上运行
- zookeeper集群中的节点故障。zookeeper保证少于半数的机器宕机仍可正常运行,及时修复机器故障即可。
借助tuple tree,storm可以通过数据的应答机制来保证数据不丢失。
storm集群中除nimbus外,没有单点存在,人和街店都可以出故障而保证数据不会丢失。nimbus被设计为无状态的,只要可以及时重启,就不会影响正在运行的任务
storm(二)消息的可靠处理的更多相关文章
- 交易系统使用storm,在消息高可靠情况下,如何避免消息重复
概要:在使用storm分布式计算框架进行数据处理时,如何保证进入storm的消息的一定会被处理,且不会被重复处理.这个时候仅仅开启storm的ack机制并不能解决上述问题.那么该如何设计出一个好的方案 ...
- IM消息送达保证机制实现(二):保证离线消息的可靠投递
1.前言 本文的上篇<IM消息送达保证机制实现(一):保证在线实时消息的可靠投递>中,我们讨论了在线实时消息的投递可以通过应用层的确认.发送方的超时重传.接收方的去重等手段来保证业务层面消 ...
- storm入门教程 第四章 消息的可靠处理【转】
4.1 简介 storm可以确保spout发送出来的每个消息都会被完整的处理.本章将会描述storm体系是如何达到这个目标的,并将会详述开发者应该如何使用storm的这些机制来实现数据的可靠处理. 4 ...
- IM系统中如何保证消息的可靠投递(即QoS机制)(转)
消息的可靠性,即消息的不丢失和不重复,是im系统中的一个难点.当初qq在技术上(当时叫oicq)因为以下两点原因才打败了icq:1)qq的消息投递可靠(消息不丢失,不重复)2)qq的垃圾消息少(它an ...
- IM系统中如何保证消息的可靠投递(即QoS机制)
消息的可靠性,即消息的不丢失和不重复,是im系统中的一个难点.当初qq在技术上(当时叫oicq)因为以下两点原因才打败了icq:1)qq的消息投递可靠(消息不丢失,不重复)2)qq的垃圾消息少(它 ...
- [Storm] 内部消息缓存
这篇文件翻译自 http://www.michael-noll.com/blog/2013/06/21/understanding-storm-internal-message-buffers/ 当进 ...
- RabbitMQ如何保证发送端消息的可靠投递-发生镜像队列发生故障转移时
上一篇最后提到了mandatory这个参数,对于设置mandatory参数个人感觉还是很重要的,尤其在RabbitMQ镜像队列发生故障转移时. 模拟个测试环境如下: 首先在集群队列中增加两个镜像队列的 ...
- RabbitMQ 消息的可靠投递
mq 提供了两种方式确认消息的可靠投递 confirmCallback 确认模式 returnCallback 未投递到 queue 退回模式 在使用 RabbitMQ 的时候,作为消息发送方希望杜绝 ...
- RabbitMQ如何保证发送端消息的可靠投递
消息发布者向RabbitMQ进行消息投递时默认情况下是不返回发布者该条消息在broker中的状态的,也就是说发布者不知道这条消息是否真的抵达RabbitMQ的broker之上,也因此会发生消息丢失的情 ...
随机推荐
- Java相关思维导图分享
非常多朋友都给我发私信希望获得一份Java知识的思维导图,我来不及一一答复.原先是给大家一个百度网盘的链接分享,大家能够自己去下载,可是不知道云盘还能用多久.把相关资源转移到了QQ的群共享中.须要的朋 ...
- 简洁常用权限系统的设计与实现(六):不维护节点的深度level,手动计算level,构造树 (把一颗无序的树,变成有序的)
本篇介绍的方法,参考了网上的代码.在递归过程中,计算level,是受到了这种方法的启发. CSDN上有篇关于树的算法,目标是把一个无序的树,变成有序的. 我看了下代码,并运行了下,感觉是可行的. 我 ...
- 2014-07-20 体验到的不是北漂easy
北京首出租天,房子很潮,这房子我住了一个多月,我希望我真的不会活得很长,世界上只有一个真正的租房,只有明确的家是最好的. 550每月,不包括水电费.我不知道该怎么形容,房间里闪耀的太阳.一个窗口,一扇 ...
- Cocos2d-x 3.1.1 Lua演示样例 ActionManagerTest(动作管理)
Cocos2d-x 3.1.1 Lua演示样例 ActionManagerTest(动作管理) 本篇博客介绍Cocos2d-x的动作管理样例,这个样例展示了Cocos2d-x的几个动作: MoveTo ...
- 利用navicat写mysql的存储过程
最近项目经理让我给新的活动的预留一个插入红包和查看详情的sql,方便在项目出问题的做一些紧急操作,我想了下这里面还涉及到挺多逻辑和挺多表的一句句查也不方便啊,干脆写到存储过程里,于是开始在navica ...
- URAL 1684. Jack's Last Word KMP
题目来源:URAL 1684. Jack's Last Word 题意:输入a b 把b分成若干段 每一段都是a的前缀 思路:b为主串 然后用a匹配b 记录到b的i位置最大匹配的长度 然后切割 切割的 ...
- c语言学习笔记(14)——算法
链表 算法: 1.通俗定义: 解题的方法和步骤 2.狭义定义: 对存储数据的操作 对不同的存储结构,要完成某一个功能所执行的操作是不一样的 比如:要输出数组中所有的元素和输出链表中所有元素的操作是不一 ...
- android module 模块共用远程包
在项目有多模块,需要使用到同一个第三方包时,引入报错,个人解决方法如下 1. 在模块build.gradle 文件中配置maven远程地址 可从app下的build.gradle文件里复制 allpr ...
- std::string 简单入门
string的定义原型 typedef basic_string<char, char_traits<char>, allocator<char> > string ...
- 【oracle11g,13】表空间管理2:undo表空间管理(调优) ,闪回原理
一.undo空间原理: dml操作会产生undo数据. update时,sever process 会在databuffer 中找到该记录的buffer块,没有就从datafile中找并读入data ...