记录python爬取猫眼票房排行榜(带stonefont字体网页),保存到text文件,csv文件和MongoDB数据库中
猫眼票房排行榜页面显示如下:
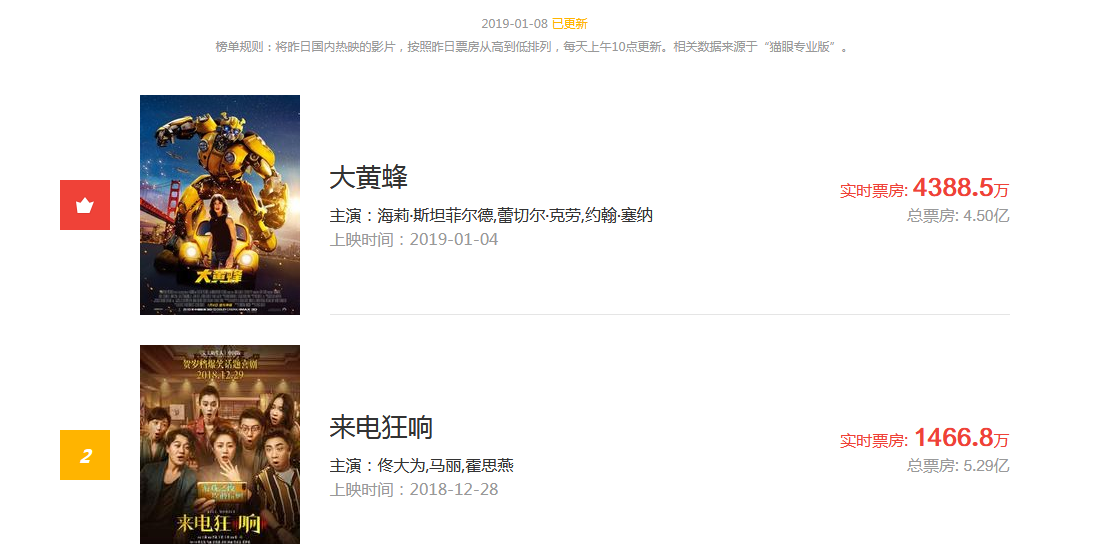
注意右边的票房数据显示,爬下来的数据是这样显示的:
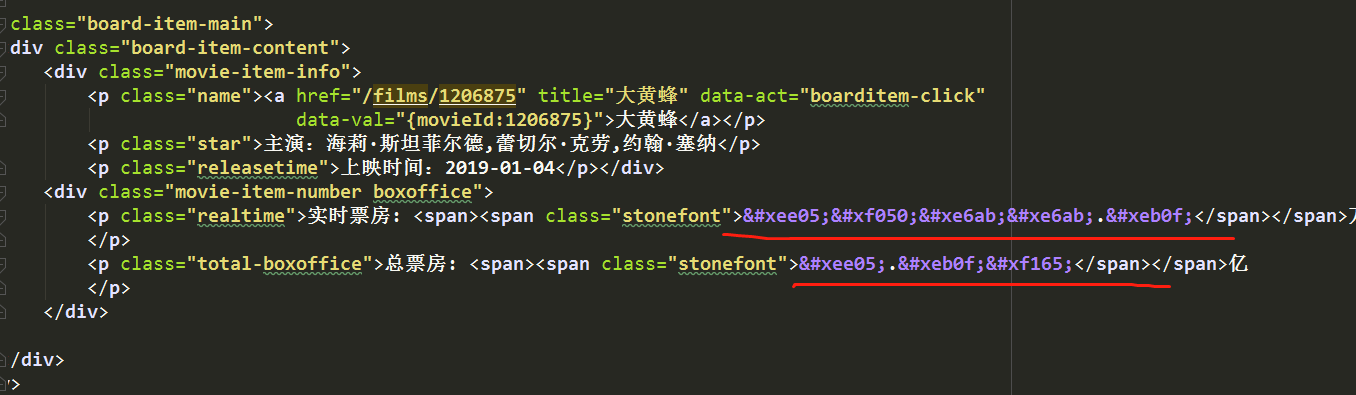
网页源代码中是这样显示的:

这是因为网页中使用了某种字体的缘故,分析源代码可知:
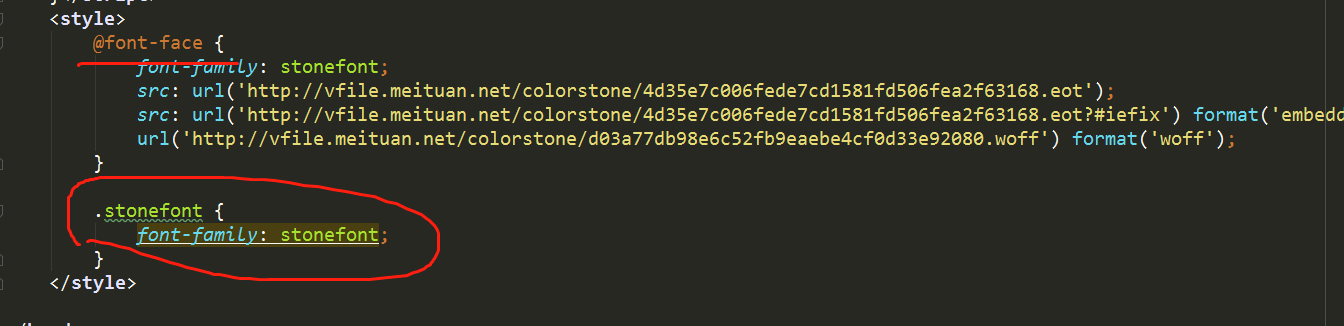
亲测可行:
代码中获取的是国内票房榜,稍加修改也可适用于最受期待榜和北美票房榜
解决思路如下:
1.获取网页数据后,查找字体信息,获取到字体链接,下载字体保存到本地
2.使用fontTools读取字体中的字符集,并构造字典(依据基准字体)
3.根据字典,替换网页中的相关数据信息。
注意:如果使用BeautifulSoup一定要先使用字典替换字符集,再解析。直接解析BeautifulSoup会将无法识别的字符置为空。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Project:pachong
@author:sandu
@Email: sandu12345@msn.cn
@Software: PyCharm
@file: test_maoyan.py
@time: 2019-01-08 0008 上午 10:05
""" import csv
import json
import os
import re
from hashlib import md5 import pymongo
import requests
from fontTools.ttLib import TTFont
from requests.exceptions import RequestException import woff2otf MONGO_URL = 'localhost'
MONGO_DB = 'maoyan'
MONGO_TABLE = 'maoyan_beimei' client = pymongo.MongoClient(MONGO_URL, connect=False)
db = client[MONGO_DB] # 获取单页数据
def get_one_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None # 解析单页数据,获取所需的数据
# '.*?board-index.*?>(\d+).*?' 获取顺序号
# '.*?data-src="(.*?)".*?' 获取图片链接
# '.*?name.*?title.*?>(.*?)</a>.*?' 获取电影名称
# '.*?star">(.*?)</p>.*?',re.S 获取演员名单(有换行,需要加上re.S,否则获取不到数据)
# '.*?releasetime">(.*?)</p>.*?' 获取上映时间
# '.*?integer">(.*?)</i>.*?' 获取主分
# '.*?fraction">(.*?)</i>.*?'获取辅分 # '.*?realtime.*?stonefont">(.*?)</span></span>(.*?)</p>.*?' 实时票房
# '.*?total-boxoffice.*?stonefont">(.*?)</span></span>(.*?)</p>.*?' 总票房
# 综合下来,加上最外层的dd def parse_one_page(html):
pattern = re.compile(
'<dd>.*?board-index.*?>(\d+).*?data-src="(.*?)".*?name.*?title.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?realtime.*?stonefont">(.*?)</span></span>(.*?)</p>.*?total-boxoffice.*?stonefont">(.*?)</span></span>(.*?)</p>.*?</dd>',
re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'img': item[1],
'name': item[2].strip(), # 去除前后空格换行符等
'star': item[3].strip()[3:], # 去除前后空格换行符等,切片截取指定的范围
'time': item[4][5:],
'实时票房': item[5] + item[6].strip(),
'总票房': item[7] + item[8].strip(),
} # 保存至文件
def save_to_file(content):
# 注意:把json数据保存到文件中显示出中文
with open('beimei.text', 'a', encoding='utf-8') as f:
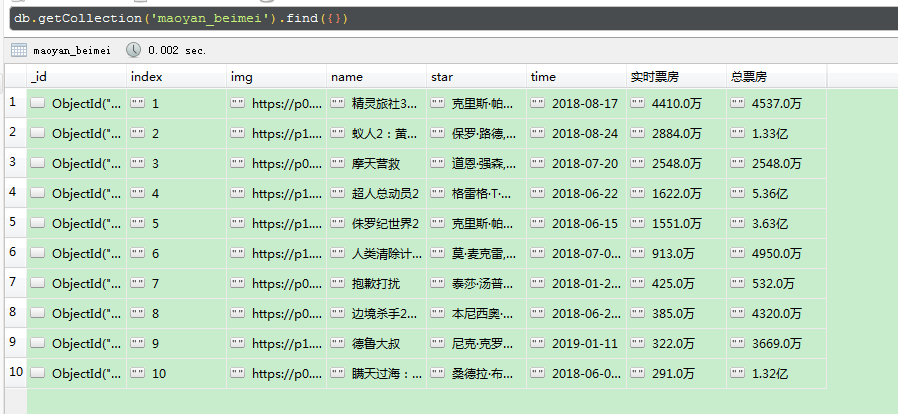
f.write(json.dumps(content, ensure_ascii=False) + '\n') # 保存到数据库中
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print('Successfully Saved to Mongo', result)
return True
return False # 请求图片url,获取图片二进制数据
def download_image(url):
try:
response = requests.get(url)
if response.status_code == 200:
save_image(response.content) # response.contenter二进制数据 response.text文本数据
return None
except RequestException:
print('请求图片出错')
return None # 数据存储到csv
def write_to_file3(item):
with open('beimei.csv', 'a', encoding='utf_8_sig', newline='') as f:
# 'a'为追加模式(添加)
# utf_8_sig格式导出csv不乱码
fieldnames = ['index', 'img', 'name', 'star', 'time', '实时票房', '总票房']
w = csv.DictWriter(f, fieldnames=fieldnames)
w.writerow(item) # 解析字体
def get_font_regx(html):
p = re.compile(r"url\('(.*?)'\)\sformat\('woff'\);") # 查找网页上的字体链接
uni_font_url = re.findall(p, html)
url = 'http:%s' % uni_font_url[0]
resp = requests.get(url)
with open('maoyan.woff', 'wb') as fontfile:
for chunk in resp.iter_content(chunk_size=1024):
if chunk:
fontfile.write(chunk) # 将字体下载到本地
woff2otf.convert('maoyan.woff', 'maoyan.otf')
baseFont = TTFont('base.otf') # base.otf是某一次访问获取的字体文件,然后人工识别内容,作为与后面获取字体的比对标本,从而让电脑自动获得后面获取字体的实际内容。
maoyanFont = TTFont('maoyan.otf')
uniList = maoyanFont['cmap'].tables[0].ttFont.getGlyphOrder() # 解析otf字体后获得的数据
numList = [] # 解析otf字体数据转换成数字
baseNumList = ['.', '', '', '', '', '', '', '', '', '', '']
baseUniCode = ['x', 'uniE78E', 'uniF176', 'uniEFE6', 'uniF074', 'uniE9C8', 'uniE912', 'uniEA71', 'uniE74E',
'uniE4B8', 'uniEE71']
for i in range(1, 12):
maoyanGlyph = maoyanFont['glyf'][uniList[i]]
for j in range(11):
baseGlyph = baseFont['glyf'][baseUniCode[j]]
if maoyanGlyph == baseGlyph:
numList.append(baseNumList[j])
break
uniList[1] = 'uni0078'
new_dict = dict(zip(uniList[2:], numList[1:])) # 实时获取字体映射关系
html = html.replace('&#x', 'uni')
for key in new_dict.keys():
initstr = key.lower() + ';'
html = html.replace(initstr, new_dict[key])
return html def save_image(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content) def main(offset):
url = 'https://maoyan.com/board/2?offset=' + str(offset) # 针对分页
html = get_one_page(url)
html = get_font_regx(html)
for item in parse_one_page(html):
print(item)
save_to_file(item) # 保存至文件
write_to_file3(item) # 写入到csv文件中,一定要写在保存到数据库的前面,因为先保存到数据库后保存的字典数据中会多一个_id值
save_to_mongo(item) # 保存到数据库
# download_image(item['img']) # 下载图片保存到当前目录 if __name__ == '__main__':
# for i in range(0, 100):
# main(str(i*10))
# 开启多线程
# pool = Pool()
# pool.map(main,0) main(0)
# 注:如何获取代码中base.otf相关信息?
# 1.根据获取到的woff字体文件,使用百度字体编辑器,获取字体数字等相关信息,地址:http://fontstore.baidu.com/static/editor/index.html# 2.将获取到的woff文件使用woff2otf.convert('maoyan.woff', 'base.otf')转化成base.otf文件保存到当前目录(
./woff2otf.py font.woff font.otf),从而获得baseFont(代码中变量)
# 3.根据百度字体编辑器获取到的信息,构造baseNumList和baseUniCode(代码中变量) # 4.再次发起请求根据获得的字体跟这个构造的基准字体进行对照,从而获得新的字体映射关系 # 注: woff2otf是导入的一个py文件,链接地址:https://github.com/hanikesn/woff2otf,作用是输入woff字体,输出otf字体 # 保存到csv文件中

# 保存到MongoDB数据库中
记录python爬取猫眼票房排行榜(带stonefont字体网页),保存到text文件,csv文件和MongoDB数据库中的更多相关文章
- Python爬取猫眼top100排行榜数据【含多线程】
# -*- coding: utf-8 -*- import requests from multiprocessing import Pool from requests.exceptions im ...
- Python 爬取 猫眼 top100 电影例子
一个Python 爬取猫眼top100的小栗子 import json import requests import re from multiprocessing import Pool #//进程 ...
- 票房和口碑称霸国庆档,用 Python 爬取猫眼评论区看看电影《我和我的家乡》到底有多牛
今年的国庆档电影市场的表现还是比较强势的,两名主力<我和我的家乡>和<姜子牙>起到了很好的带头作用. <姜子牙>首日破 2 亿,一举刷新由<哪吒之魔童降世&g ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- Python 爬取猫眼电影最受期待榜
主要爬取猫眼电影最受期待榜的电影排名.图片链接.名称.主演.上映时间. 思路:1.定义一个获取网页源代码的函数: 2.定义一个解析网页源代码的函数: 3.定义一个将解析的数据保存为本地文件的函数: ...
- 爬虫--requests爬取猫眼电影排行榜
'''目标:使用requests分页爬取猫眼电影中榜单栏目中TOP100榜的所有电影信息,并将信息写入文件URL地址:http://maoyan.com/board/4 其中参数offset表示其实条 ...
- scrapy爬取猫眼电影排行榜
做爬虫的人,一定离不开的一个框架就是scrapy框架,写小项目的时候可以用requests模块就能得到结果,但是当爬取的数据量大的时候,就一定要用到框架. 下面先练练手,用scrapy写一个爬取猫眼电 ...
- 使用xpath爬取猫眼电影排行榜
最近在学习xpath,在网上找资料的时候,发现一个新手经常拿来练手的项目,爬取猫眼电影前一百名排行的信息,很多都是跟崔庆才的很雷同,基本照抄.这里就用xpath自己写了一个程序,同样也是爬取猫眼电影, ...
随机推荐
- uva 10276 / pc 110908
黑书上说用二分图的知识来解,但我想不出来,只好找规律 发现,一条柱时为1,两条柱时为4.三条柱时为8.. 这些1,3,7,11的数字加1后,都是下一条柱的最底部的数字,而且一条柱的数字之和总是按照这样 ...
- HDU 3389
对于这道题,我们需要从(A+B)%3==0这式子考虑.对于第一条式子,我们可以知道,只能是奇偶盒子交替转移. 由第二条式子可知,要么是同余为0的A,B之间转移,要么是余数为1,2之间的 转移.后来仔细 ...
- HDU 4617
题目多读几次就明白了.主要是求异面直线的距离,然后用距离和两圆半径之和作比较. 空间直线的距离d=|AB*n| / |n| (AB表示异面直线任意2点的连线,n表示法向量,法向量为两条异面直线方向向量 ...
- HDU 1238
好吧,这题直接搜索就可以了,不过要按照长度最短的来搜,很容易想得到. 记得ACM比赛上有这道题,呃..不过,直接搜..呵呵了,真不敢想. #include <iostream> #incl ...
- SQL优化(SQL TUNING)之10分钟完毕亿级数据量性能优化(SQL调优)
前几天.一个用户研发QQ找我,例如以下: 自由的海豚. 16:12:01 岛主,我的一条SQL查不出来结果,能帮我看看不? 兰花岛主 16:12:10 多久不出结果? 自由的海豚 16:12:17 多 ...
- iOS不同版本号适配问题(#ifdef __IPHONE_7_0)
部分參考http://www.cnblogs.com/ios8/p/ios-version-com.html 以下举个简单的样例来说明在iOS7.0和iOS6.1(以及更低版本号)之间的适配问题(用的 ...
- NPOI文件导入操作
using EntMSM.SmsDbContext; using NPOI.HSSF.UserModel; using NPOI.SS.UserModel; using NPOI.XSSF.UserM ...
- GNU TeXmacs 1.99.8 发布,所见即所得科学编辑器(看看老实的GUI)
GNU TeXmacs 1.99.8 已发布,这是一个支持各种数学公式的所见即所得编辑器,可以用来编辑文本.图形.数学.交互内容,它的界面非常友好,并且内置高质量的排版引擎. 更新内容: bug 修复 ...
- 轻快的VIM(五):复制
操作相同文本的时候复制尤其有效,在Windows中我们都习惯了先用鼠标选择文本 而Vim下则不用那么麻烦,你甚至可以使用可视模式操作,但这里先略过 我在这一节主要说说命令模式下的复制 在讲复制之前我要 ...
- LDA解决的问题
人类是怎么生成文档的呢?LDA的这三位作者在原始论文中给了一个简单的例子.比如假设事先给定了这几个主题:Arts.Budgets.Children.Education,然后通过学习训练,获取每个主题T ...