sklearn学习9----LDA(discriminat_analysis)
1、导入模块
http://scikit-learn.org/stable/modules/generated/sklearn.discriminant_analysis.LinearDiscriminantAnalysis.html#sklearn.discriminant_analysis.LinearDiscriminantAnalysis
- from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
- da = LinearDiscriminantAnalysis()
2、使用参数说明:https://blog.csdn.net/qsczse943062710/article/details/75977118
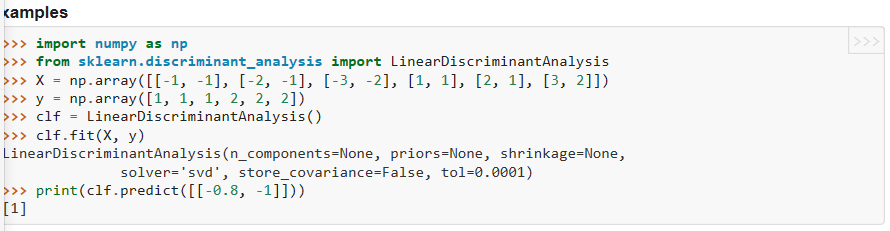
- class sklearn.discriminant_analysis.LinearDiscriminantAnalysis(solver=’svd’, shrinkage=None, priors=None, n_components=None, store_covariance=False, tol=0.0001)
solver:str,求解算法,
取值可以为:svd:使用奇异值分解求解,不用计算协方差矩阵,适用于特征数量很大的情形,无法使用参数收缩(shrinkage)lsqr:最小平方QR分解,可以结合shrinkage使用eigen:特征值分解,可以结合shrinkage使用
shrinkage:str or float,是否使用参数收缩
取值可以为:None:不适用参数收缩auto:str,使用Ledoit-Wolf lemma浮点数:自定义收缩比例
priors:array,用于LDA中贝叶斯规则的先验概率,当为None时,每个类priors为该类样本占总样本的比例;当为自定义值时,如果概率之和不为1,会按照自定义值进行归一化n_components:int,需要保留的特征个数,小于等于n-1store_covariance:是否计算每个类的协方差矩阵
3、方法:

4、LinearDiscriminantAnalysis类的fit方法
def fit(self, X, y, store_covariance=None, tol=None):类型检查,包括priors的检测根据不同的solver调用不同的求解方法
- 1
- 2
- 3
fit()方法里根据不同的solver调用的方法均为LinearDiscriminantAnalysis的类方法
fit()返回值:
self:LinearDiscriminantAnalysis实例对象
属性:
covariances_:每个类的协方差矩阵, shape = [n_features, n_features]means_:类均值,shape = [n_classes, n_features]priors_:归一化的先验概率rotations_:LDA分析得到的主轴,shape [n_features, n_component]scalings_:数组列表,每个高斯分布的方差σ
5、使用例子(可预测、可降维)
- from sklearn.discriminat_analysis import LinearDiscriminantAnalysis as LDA
- sklearn_lda=LDA(n_components=2)
- X_lda_sklearn=sklearn_lda.fit_transform(X,Y)
sklearn学习9----LDA(discriminat_analysis)的更多相关文章
- sklearn学习总结(超全面)
https://blog.csdn.net/fuqiuai/article/details/79495865 前言sklearn想必不用我多介绍了,一句话,她是机器学习领域中最知名的python模块之 ...
- sklearn学习笔记之简单线性回归
简单线性回归 线性回归是数据挖掘中的基础算法之一,从某种意义上来说,在学习函数的时候已经开始接触线性回归了,只不过那时候并没有涉及到误差项.线性回归的思想其实就是解一组方程,得到回归函数,不过在出现误 ...
- sklearn学习 第一篇:knn分类
K临近分类是一种监督式的分类方法,首先根据已标记的数据对模型进行训练,然后根据模型对新的数据点进行预测,预测新数据点的标签(label),也就是该数据所属的分类. 一,kNN算法的逻辑 kNN算法的核 ...
- sklearn 学习 第一篇:分类
分类属于监督学习算法,是指根据已有的数据和标签(分类)进行学习,预测未知数据的标签.分类问题的目标是预测数据的类别标签(class label),可以把分类问题划分为二分类和多分类问题.二分类是指在两 ...
- SKlearn | 学习总结
1 简介 scikit-learn,又写作sklearn,是一个开源的基于python语言的机器学习工具包.它通过NumPy, SciPy和Matplotlib等python数值计算的库实现高效的算法 ...
- sklearn学习笔记3
Explaining Titanic hypothesis with decision trees decision trees are very simple yet powerful superv ...
- sklearn学习笔记2
Text classifcation with Naïve Bayes In this section we will try to classify newsgroup messages using ...
- sklearn学习笔记1
Image recognition with Support Vector Machines #our dataset is provided within scikit-learn #let's s ...
- 莫烦sklearn学习自修第九天【过拟合问题处理】
1. 过拟合问题可以通过调整机器学习的参数来完成,比如sklearn中通过调节gamma参数,将训练损失和测试损失降到最低 2. 代码实现(显示gamma参数对训练损失和测试损失的影响) from _ ...
随机推荐
- Codevs 1077 多源最短路( Floyd水 )
链接:传送门 思路:裸 Floyd /************************************************************************* > Fi ...
- 深入了解Spring
1.Bean后处理器 Spring容器提供了一个接口InitializingBean,实现这个接口的bean只要重写afterPropertiesSet()或者在XML中添加init-method属性 ...
- 实战:一、使用mongo做一个注册的小demo
思路:1.使用mongoose 进行 数据库的链接 2.使用Schema来进行传输字段的定义 3.安装koa-router进行数据处理4.安装koa-bodyparser 进行post数据交互5.解决 ...
- oracle定时器执行一遍就不执行或本就不执行
转:http://blog.csdn.net/qq_23311211/article/details/76283689 以sqlplus/ assysdba进入sql命令模式,使用sql:select ...
- [Beginning SharePoint Designer 2010]Chapter 3 分析SharePoint页面
本章概要: 1.SharePoint中主要页面类型 2.SharePoint如何组织页面 3.如何编辑母板页 4.SharePoint母板页中的主要内容占位符
- <监听器模式>在C++ 与 Java 之间实现的差异
前言: 关于各种语言孰优孰劣的讨论在软件界就是个没完没了的话题,今天我决定也来掺和下. 只是我想探讨的不是哪种语言的性能怎样,钱途怎样.而是站在语言本身特性的基础上中肯地比較探讨.由于如今工作用的是C ...
- java的classLoader原理理解和分析
java的classLoader原理理解和分析 学习了:http://blog.csdn.net/tangkund3218/article/details/50088249 ClassNotFound ...
- tomcat内存大小设置
tomcat内存大小设置 如果安装为windows服务,需要进行内存设置的时候,选择configure...界面, 在Java Tab页面内可以进行内存参数的设置. 学习了:http://elf884 ...
- C++ 嵌入汇编程序提高计算效率
因为汇编语言比C++更接近硬件底层,所以在性能要求高的程序中往往能够採取在C++代码中嵌入汇编的方式来给程序提速. 在VC中能够简单的通过 __asm { //在这里加入汇编代码 } 来实现. 以下通 ...
- Apache Pig的前世今生
近期,散仙用了几周的Pig来处理分析我们站点搜索的日志数据,感觉用起来非常不错,今天就写篇笔记介绍下Pig的由来,除了搞大数据的人,可能非常少有人知道Pig是干啥的.包含一些是搞编程的,但不是搞大数据 ...