Scrapy——5 下载中间件常用函数、scrapy怎么对接selenium、常用的Setting内置设置有哪些
Scrapy——5
(Downloader Middleware)下载中间件常用函数有哪些


Scrapy怎样对接Selenium
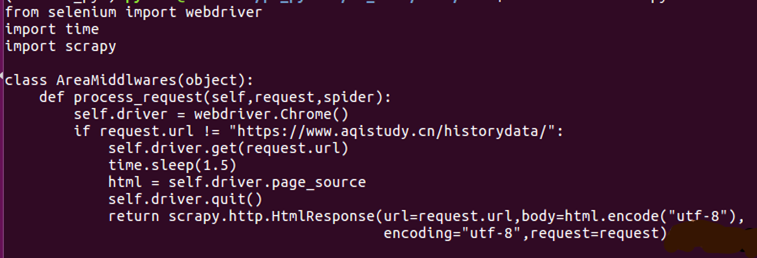
设置setting.py里的DOWNLOADER_MIDDLIEWARES,添加自己编写的下载中间件类

常用的Setting内置设置有哪些
详情可以参考https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/settings.html#concurrent-items
CONCURRENT_REQUESTS
- 默认:
16 - Scrapy downloader 并发请求(concurrent requests)的最大值。
CONCURRENT_ITEMS
- 默认:
100 - Item Processor(即 Item Pipeline) 同时处理(每个response的)item的最大值。
DOWNLOAD_TIMEOUT
- 默认:
180 - 下载器超时时间(单位: 秒)。
DOWNLOAD_DELAY
- 默认:
0 - 下载器在下载同一个网站下一个页面前需要等待的时间。该选项可以用来限制爬取速度, 减轻服务器压力。同时也支持小数:
DOWNLOAD_DELAY = 0.25 # 250 ms of delay
- 该设定影响(默认启用的)
RANDOMIZE_DOWNLOAD_DELAY设定。 默认情况下,Scrapy在两个请求间不等待一个固定的值, 而是使用0.5到1.5之间的一个随机值 *DOWNLOAD_DELAY的结果作为等待间隔。 - 当
CONCURRENT_REQUESTS_PER_IP非0时,延迟针对的是每个ip而不是网站。 - 另外您可以通过spider的
download_delay属性为每个spider设置该设定。
LOG_ENCODING
- 默认:
'utf-8' - logging使用的编码。
ITEM_PIPELINES
- 默认:
{} - 保存项目中启用的pipeline及其顺序的字典。该字典默认为空,值(value)任意。 不过值(value)习惯设定在0-1000范围内。
COOKIES_ENABLED
- 默认:
True - 是否启用cookies middleware。如果关闭,cookies将不会发送给web server。
对接selenium实战——PM2.5历史数据_空气质量指数历史数据_中国空气质量在线监测分析平...
此网站的数据都是通过加密传输的,我们可以通过对接selenium跳过数据加密过程,直接获取到网页js渲染后的代码,达到数据的提取
唯一的缺点就是速度太慢
- 首先创建项目(光标所在的文件是日志文件)
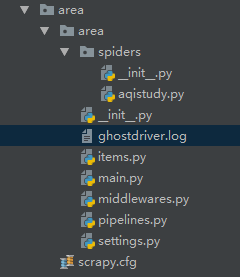
本次实战旨在selenium的对接,就不考虑保存数据的问题,所以不用配置items文件
- /area/area/settings.py 设置无视爬虫协议,设置对应下载中间件的激活,日志等级(设置日志等级后运行程序会生成相应的日志信息,主要的作用是为了屏蔽程序运行时过多的日志,方便观察运行结果)



- /area/area/spiders/aqistudy.py 直接编写代码
# -*- coding: utf-8 -*-
import scrapy class AqistudySpider(scrapy.Spider):
name = 'aqistudy'
# allowed_domains = ['aqistudy.cn']
start_urls = ['https://www.aqistudy.cn/historydata/'] def parse(self, response):
print('开始获取主要城市地址...')
city_list = response.xpath("//ul[@class='unstyled']/li/a/@href").extract() for city_url in city_list[1:3]:
yield scrapy.Request(url=self.start_urls[0]+city_url, callback=self.parse_month) def parse_month(self, response):
print('开始获取当前城市的月份地址...')
month_urls= response.xpath('//ul[@class="unstyled1"]/li/a/@href').extract() for month_url in month_urls:
yield scrapy.Request(url=self.start_urls[0]+month_url, callback=self.parse_day) def parse_day(self, response):
print('开始获取空气数据...')
print(response.xpath('//h2[@id="title"]/text()').extract_first()+'\n')
item_list = response.xpath('//tr')[1:]
for item in item_list:
print('day: '+item.xpath('./td[1]/text()').extract_first() + '\t'
+ 'API: '+item.xpath('./td[2]/text()').extract_first() + '\t'
+ '质量: '+item.xpath('./td[3]/span/text()').extract_first() + '\t'
+ 'MP2.5: '+item.xpath('./td[4]/text()').extract_first() + '\t'
+ 'MP10: '+item.xpath('./td[5]/text()').extract_first() + '\t'
+ 'SO2: '+item.xpath('./td[6]/text()').extract_first() + '\t'
+ 'CO: '+item.xpath('./td[7]/text()').extract_first() + '\t'
+ 'NO2: '+item.xpath('./td[8]/text()').extract_first() + '\t'
+ 'O3_8h: '+item.xpath('./td[9]/text()').extract_first()
) - /area/area/middlewares.py 设置下载中间件
- 程序代码发起requests的时候,都会经过中间件,所以用了一个 if 'month' in request.url:来区分
- 此处对接的是PhantomJS,也可以用别的驱动程序,用Chrome的话,一定也要记得设置无窗口模式,否则会不同的弹出窗口,更多关于selenium启动项的知识,可以参考此处
- middlewares.py用到的类是自定义的,所以在前面的设置中,激活的是相应的中间件
# -*- coding: utf-8 -*- # Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html import time
from selenium import webdriver
import scrapy
from scrapy import signals class AreaSpiderMiddleware(object):
...... class AreaDownloaderMiddleware(object):
...... class AreaMiddleware(object): def process_request(self, request, spider):
self.driver = webdriver.PhantomJS() if 'month' in request.url:
self.driver.get(request.url)
time.sleep(2)
html = self.driver.page_source
self.driver.quit() return scrapy.http.HtmlResponse(url=request.url, body=html,request=request, encoding='utf-8' ) - 因为笔者的虚拟机是服务器模式(命令行窗口,无法运行selenium),所以程序是在Windows中运行的。在项目文件中的main.py文件,就是一个运行程序的文件
- 这几行就可以将scrapy的多个程序综合在一个程序中运行了,前提是你为你的Windows安装了selenium的相应驱动和Scrapy库
# -*- coding: utf-8 -*-
# @Time : 2018/11/12 16:56
# @Author : wjh
# @File : main.py
from scrapy.cmdline import execute
execute(['scrapy','crawl','aqistudy'])
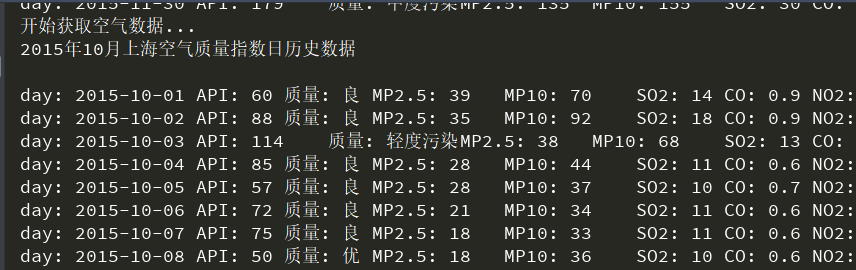
运行结果如下:
Scrapy——5 下载中间件常用函数、scrapy怎么对接selenium、常用的Setting内置设置有哪些的更多相关文章
- UA池 代理IP池 scrapy的下载中间件
# 一些概念 - 在scrapy中如何给所有的请求对象尽可能多的设置不一样的请求载体身份标识 - UA池,process_request(request) - 在scrapy中如何给发生异常的请求设置 ...
- Scrapy的下载中间件
下载中间件 简介 下载器,无法执行js代码,本身不支持代理 下载中间件用来hooks进Scrapy的request/response处理过程的框架,一个轻量级的底层系统,用来全局修改scrapy的re ...
- python之scrapy模块下载中间件
知识点 使用方法: 编写一个Downloader Middlewares和我们编写一个pipeline一样,定义一个类,然后在setting中开启 Downloader Middlewares默认的方 ...
- PHP常用函数(一):数组常用函数
1.list() list() 和 array() 一样,不是一个函数,而是一个语言结构,作用是为一组变量赋值. PHP手册中的介绍 使用详情 <?php //假设现在想为$a $b $c三个 ...
- python面向对象的基础语法(dir内置函数、self参数、初始化方法、内置方法和属性)
面相对象基础语法 目标 dir 内置函数 定义简单的类(只包含方法) 方法中的 self 参数 初始化方法 内置方法和属性 01. dir 内置函数(知道) 在 Python 中 对象几乎是无所不在的 ...
- python基础:函数传参、全局变量、局部变量、内置函数、匿名函数、递归、os模块、time模块
---恢复内容开始--- 一.函数相关: 1.1位置参数: ef hello(name,sex,county='china'): pass #hello('hh','nv') #位置参数.默认参数 1 ...
- python基础编程: 函数示例、装饰器、模块、内置函数
目录: 函数示例 装饰器 模块 内置函数 一.函数示例: 1.为什么使用函数之模块化程序设计: 不使用模块程序设计的缺点: 1.体系结构不清晰,可主读性差: 2.可扩展性差: 3.程序冗长: 2.定义 ...
- day16_函数作用域_匿名函数_函数式编程_map_reduce_filter_(部分)内置函数
20180729 补充部分代码 20180727 上传代码 #!/usr/bin/env python # -*- coding:utf-8 -*- # ***************** ...
- python递归函数、二分法、匿名函数、(sorted、map、filter内置函数应用)
#函数递归是一种特殊的函数嵌套调用,在调用一个函数的过程中,又直接或间接的调用该函数本身递归必须要有两个明确的阶段: 递推:一层一层递归调用下去,强调每进入下一层递归问题的规模都必须有所减少 回溯:递 ...
随机推荐
- 【Codeforces】 Round #374 (Div. 2)
Position:http://codeforces.com/contest/721 我的情况 开始还是rank1,秒出C.(11:00机房都走光了,我ma到11:05才走,只打了一个小时) 结果.. ...
- 重装mysql
重装mysql方法. 转自http://blog.sina.com.cn/s/blog_73000beb01012eh4.html 1.删除 mysql 1.1 sudo apt-get autore ...
- hdu 4123(树形dp+倍增)
Bob’s Race Time Limit: 5000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total ...
- 【模板】 倍增lca
虽然很基础,但是还是复习了一下,毕竟比树剖好写... 代码: #include<iostream> #include<cstdio> #include<cmath> ...
- 41. extjs--combobox下拉列表的triggerAction
转自:https://icrwen.iteye.com/blog/939247 一般combobox的store先load加载数据,然后combobox的mode设置为local,则不会每次下拉列表都 ...
- poj1200Crazy Search(hash)
题目大意 将一个字符串分成长度为N的字串.且不同的字符不会超过NC个.问总共有多少个不同的子串. /* 字符串hash O(n)枚举起点 然后O(1)查询子串hash值 然后O(n)找不一样的个数 ...
- P4049 [JSOI2007]合金
传送门 我数学可能白学了-- 因为三个数加起来等于\(1\),那么只要用前两个数就能表示,那么就能把每一种金属看成一个二维向量.考虑只有两个向量的时候,设这两个向量为\(a,b\),那么一个向量\(c ...
- Vue.js中学习使用Vuex详解
在SPA单页面组件的开发中 Vue的vuex和React的Redux 都统称为同一状态管理,个人的理解是全局状态管理更合适:简单的理解就是你在state中定义了一个数据之后,你可以在所在项目中的任何一 ...
- Idea使用Maven搭建SpringMVC的HelloSpringMvc并配置插件Maven和Jetty
这篇博文只是纯粹的搭建一个SpringMVC的项目, 并不会涉及里面配置文件该写些什么. 只是纯粹的搭建一个初始的Hello SpringMVC的项目. 废话不多说,上图. 1. 打开IDEA 并且 ...
- Spark 概念学习系列之Spark基本概念和模型(十八)
打好基础,别小瞧它! spark的运行模式多种多样,在单机上既可以本地模式运行,也可以伪分布模式运行.而当以分布式的方式在集群中运行时.底层的资源调度可以使用Mesos或者Yarn,也可使用spark ...