CS229 7.2 应用机器学习方法的技巧,准确率,召回率与 F值
建立模型
当使用机器学习的方法来解决问题时,比如垃圾邮件分类等,一般的步骤是这样的:
1)从一个简单的算法入手这样可以很快的实现这个算法,并且可以在交叉验证集上进行测试;
2)画学习曲线以决定是否更多的数据,更多的特征或者其他方式会有所帮助;
3)人工检查那些算法预测错误的例子(在交叉验证集上),看看能否找到一些产生错误的原因。
评估模型
首先,引入一个概念,非对称性分类。考虑癌症预测问题,y=1 代表癌症,y=0 代表没有癌症,对于一个数据集,我们建立logistic 回归模型,经过以上建模的步骤,得到一个优化的模型,错误率仅为1%,这貌似是一个很好的结果,但考虑数据集若仅有0.05%的正例(y=1),那么我们直接预测所有y=0,我们得到的模型的错误率仅为0.5%,这便是非对称分类的问题,这样的问题仅考虑错误率是有风险的。
下面引入一种标准的衡量方法:Precision/Recall(精确度和召回率),这种度量最早出现在信息检索问题中的,如下:
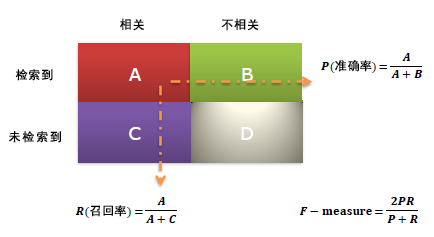
在机器学习的模型中,也可以用这种评估方法,具体如下:

其中:
True Positive (真正例, TP)被模型预测为正的正样本;可以称作判断为真的正确率
True Negative(真负例 , TN)被模型预测为负的负样本 ;可以称作判断为假的正确率
False Positive (假正例, FP)被模型预测为正的负样本;可以称作误报率
False Negative(假负例 , FN)被模型预测为负的正样本;可以称作漏报率
现在需要考虑权衡Precision/Recall:
以logistic 回归为例:
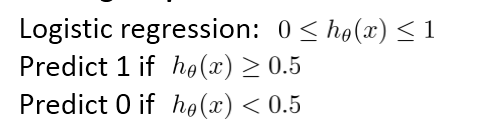
假设我们非常有把握时才预测病人得癌症(y=1), 这个时候,我们常常将阈值设置的很高,FP变小,FN增大,这会导致高精确度,低召回率(Higher precision, lower recall);
假设我们不希望将太多的癌症例子错分(避免假负例,本身得了癌症,确被分类为没有得癌症), 这个时候,阈值就可以设置的低一些,FP变大,FN变小,这又会导致高召回率,低精确度(Higher recall, lower precision);

以上的描述可以用如下的PR曲线来描述,一般准确率提高,召回率会下降:
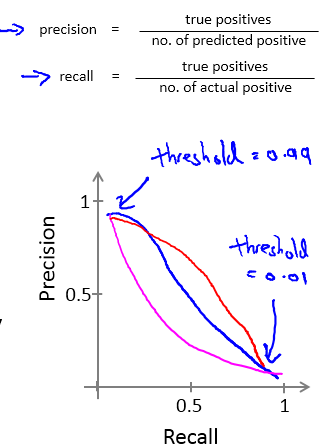
关于如何权衡准确率与召回率:
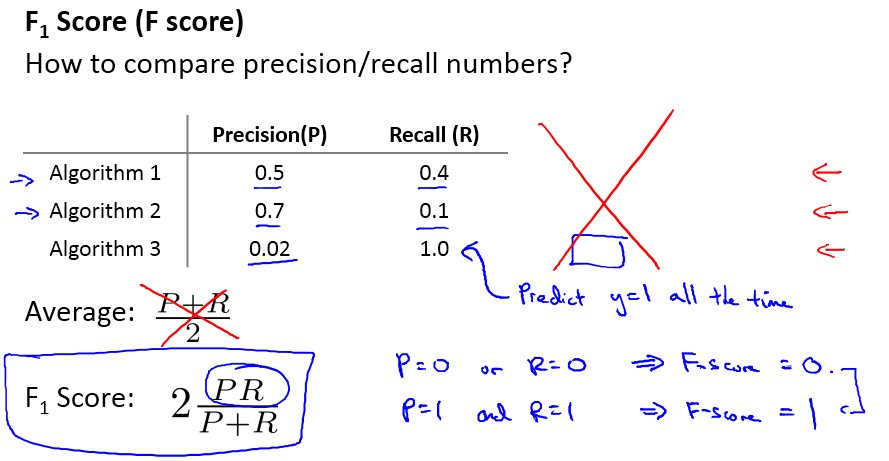
如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。在两者都要求高的情况下,可以用F1来衡量。
CS229 7.2 应用机器学习方法的技巧,准确率,召回率与 F值的更多相关文章
- (七)7.2 应用机器学习方法的技巧,准确率,召回率与 F值
建立模型 当使用机器学习的方法来解决问题时,比如垃圾邮件分类等,一般的步骤是这样的: 1)从一个简单的算法入手这样可以很快的实现这个算法,并且可以在交叉验证集上进行测试: 2)画学习曲线以决定是否更多 ...
- 机器学习方法(七):Kmeans聚类K值如何选,以及数据重抽样方法Bootstrapping
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入.我的博客写一些自己用得到东西,并分享给 ...
- Stanford机器学习---第六讲. 怎样选择机器学习方法、系统
原文:http://blog.csdn.net/abcjennifer/article/details/7797502 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- 美团网基于机器学习方法的POI品类推荐算法
美团网基于机器学习方法的POI品类推荐算法 前言 在美团商家数据中心(MDC),有超过100w的已校准审核的POI数据(我们一般将商家标示为POI,POI基础信息包括:门店名称.品类.电话.地址.坐标 ...
- 关于”机器学习方法“,"深度学习方法"系列
"机器学习/深度学习方法"系列,我本着开放与共享(open and share)的精神撰写,目的是让很多其它的人了解机器学习的概念,理解其原理,学会应用.如今网上各种技术类文章非常 ...
- R语言进行机器学习方法及实例(一)
版权声明:本文为博主原创文章,转载请注明出处 机器学习的研究领域是发明计算机算法,把数据转变为智能行为.机器学习和数据挖掘的区别可能是机器学习侧重于执行一个已知的任务,而数据发掘是在大数据中寻找有 ...
- 机器学习方法、距离度量、K_Means
特征向量 1.特征向量:以人为例,每个元素可能就对应这人的某些方面,这就是特征,例如:身高.年龄.性别.国际....2.特征工程:目的就是将现有数据中可作为信号的特征与那些仅是噪声的特征区分开来:当数 ...
- 不平衡数据下的机器学习方法简介 imbalanced time series classification
imbalanced time series classification http://www.vipzhuanli.com/pat/books/201510229367.5/2.html?page ...
- 基于CRF工具的机器学习方法命名实体识别的过
[转自百度文库] 基于CRF工具的机器学习方法命名实体识别的过程 | 浏览:226 | 更新:2014-04-11 09:32 这里只讲基本过程,不涉及具体实现,我也是初学者,想给其他初学者一些帮助, ...
随机推荐
- 应用端连接MySQL数据库报Communications link failure
事情的起因: 某项目的开发同学突然Q我们组的某同学,要求我们调整MySQL的连接等待超时参数wait_timeout.要求我们从28800s调整到31536000s(也就是一年) 应用端测试环境的to ...
- webpack 打包产生的文件名中,hash、chunkhash、contenthash 的区别
table th:first-of-type { width: 90px; } hash 类型 区别 hash 每一次打包都会生成一个唯一的 hash chunkhash 根据每个 chunk 的内容 ...
- java 迭代
迭代器的作用是提供一种方法对一个容器对象中的各个元素进行访问,而又不暴露该对象容器的内部细节. java中的很多容器都实现了Iterable接口,容器中的元素都是可以遍历的. 如下例,list容器中存 ...
- HanLP的自定义词典使用方式与注意事项介绍
[环境]python 2.7 方法一:使用pyhanlp,具体方法如下: pip install pyhanlp # 安装pyhanlp 进入python安装包路径,如 /usr/lib/pytho ...
- [转]TA-Lib 安装
转自:https://mrjbq7.github.io/ta-lib/install.html Installation You can install from PyPI: $ pip instal ...
- CentOS7创建本地yum源
[root@master ~]# mkdir -p /var/www/html 使用安装系统的ISO镜像文件CentOS-7-x86_64-Everything-1611.iso 把CentOS-7- ...
- hyperledger fabric各类节点及其故障分析 摘自https://www.cnblogs.com/preminem/p/8729781.html
hyperledger fabric各类节点及其故障分析 1.Client节点 client代表由最终用户操作的实体,它必须连接到某一个peer节点或者orderer节点上与区块链网络通信.客户端 ...
- git 仓库相关命令
git配置文件 : .git/config 配置存储远程连接用户信息 [credential] helper = store 配置www用户下默认git pull账号和密码,这样每一个新加的项目都不用 ...
- 代码编辑器之notepad++
引用及下载地址:http://www.iplaysoft.com/notepad-plus.html NotePad++ 优秀的支持语法高亮的开源免费编辑器绿色版下载 EditPlus,它始终是一款收 ...
- NIO基本操作
NIO是Java 4里面提供的新的API,目的是用来解决传统IO的问题 NIO主要有三大核心部分:Channel(通道),Buffer(缓冲区), Selector(选择器) Channel(通道) ...