opencv 车牌字符分割 ANN网络识别字符
最近在复习OPENCV的知识,学习caffe的深度神经网络,正好想起以前做过的车牌识别项目,可以拿出来研究下
以前的环境是VS2013和OpenCV2.4.9,感觉OpenCV2.4.9是个经典版本啊!不过要使用caffe模型的话,还是要最新的OpenCV3.3更合适!
一、车牌图片库
以前也是网上下的,如果找不到的小伙伴可以从我这儿下: 链接:http://pan.baidu.com/s/1hrQF92G 密码:43jl
里面有数字 “0-9”,字母“A-Z”的训练图片各50张。
测试车牌图片当时是从他人得到已经定位到车牌的图片,类似如下:

目标当然就是对这些车牌图片进行预处理,单字符分割,单字符识别!
二、预处理
图像的预处理做来做去就是滤波去噪,光照补偿,灰度/二值化,形态学基本操作等等。这些图片都是自然场景得到所以基本的去噪操作可以做一下,然后为了单字符分割,灰度化和形态学可以结合效果调整。
光照补偿其实一直是个问题,大多数有直方图均衡化,亮度参考白,利用公式统计补偿图片。这方面也可以结合图像增强方法来做!笔者当时觉得前两者对大多数场景已经适用。
二值化可以使用 cv::threshold函数,如:
- Mat t1=imread("2.png",);
- cvtColor(inimg, gimg, CV_BGR2GRAY);
- threshold(gimg, gimg, , , CV_THRESH_BINARY);
- imshow("gimg", gimg);
第一行imread(),由于flag设为1所以读的是彩图,采用cvtColor函数转化为灰度图。如果你读入就是灰度图可以省略第二行代码。第三行就是转化为二值化函数,阈值100可以修改,在灰度对比不明显是有必要!
效果:
如果预处理做的好,某些小的白色区域是可以去掉的。这个效果也可以识别。
同时可以发现车牌外围被一圈白色包围,如若能去除外围白色,对于单字符分割更有益。但其实通过寻找列像素之间的变化,白色区域只是影响了阈值不会对结果太大影响。
想要去除白色外圈可以参考:http://blog.csdn.net/u011630458/article/details/43733057
如果想要使用直方图均衡化,OPENCV有equalizeHist(inputmat, outputmat);非常方便,但是效果不好。
使用直方图均衡化后的上述车牌二值化图片:

效果更惨烈了,因为均衡化就是让直方图的像素分布更加平衡,上图黑色多,均衡之后自然白色多了,反而不好!
二、单字符分割
单字符分割主要策略就是检测列像素的总和变化,因为没有字符的区域基本是黑色,像素值低;有字符的区域白色较多,列像素和就变大了!
列像素变化的阈值是个问题,看到很多博客是固定的阈值进行检测,除非你处理后的二值化图像非常完美,不然有的图片混入了白色区域就会分割错误!而且对于得到分割宽度如果太小也应该使用策略进行剔除,没有一定的宽度限制分割后的图片可能是很多个窄窄的小区域。。。
- int getColSum(Mat& bimg, int col)
- {
- int height = bimg.rows;
- int sum = ;
- for (int i = ; i < height; i++)
- {
- sum += bimg.at<uchar>(i, col);
- }
- cout << sum << endl;
- return sum;
- }
- int cutLeft(Mat& src, int Tsum, int right)//左右切割
- {
- int left;
- left = ;
- int i;
- for (i=; i < src.cols; i++)
- {
- int colValue = getColSum(src, i);
- if (colValue> Tsum)
- {
- left = i;
- break;
- }
- }
- int roiWidth=src.cols/;
- for (; i < src.cols; i++)
- {
- int colValue = getColSum(src, i);
- if (colValue < Tsum)
- {
- right = i;
- if ((right - left) < (src.cols/))
- continue;
- else
- {
- roiWidth = right - left;
- break;
- }
- }
- }
- return roiWidth;
- }
- int getOne(Mat& inimg)
- {
- Mat gimg,histimg;
- cvtColor(inimg, gimg, CV_BGR2GRAY);
- equalizeHist(gimg,histimg);
- //imshow("histimg", histimg);
- threshold(gimg, gimg, , , CV_THRESH_BINARY);
- imshow("gimg", gimg);
- waitKey();
- int psum=;
- for (int i = ; i < gimg.cols; i++)
- {
- psum+=getColSum(gimg, i);
- }
- cout <<"psum/col:"<< psum/gimg.cols << endl;
- int Tsum = 0.6*(psum / gimg.cols);
- int roiWid= cutLeft(gimg, Tsum, );
- return roiWid;
- }
笔者思路也很简单:
首先统计所有列像素的总和,取其列像素的均值作为参考标准之一(也可以选用其他数学指标参考),列像素的阈值Tsum设置为列像素均值的百分比(如60%,是情景定)。
利用cutLeft()函数对图片进行列扫描,将列像素超过阈值的列标记为左边,再继续寻找右边,将满足阈值的右边进行标记。左右相减即可得到宽度分割字符。
考虑到车牌中只有7个字符,所以先判断得到宽度大小,如果小于总宽的七分之一视为干扰放弃;其实也可以加大到总宽的8分之一(因为车牌中间可能有连接符)。
getColSum()函数是求一列的像素和,这里用到了.at<> 方式,其实还有别的方法也可以,只要获得当前的像素值,并累加整列即可!
上图车牌的分割效果:







因为第三张有车牌的连接符,所以导致第三张和第四张稍有瑕疵,但总体分割还是满意的!
三、单字符识别
只论字符识别其实有不少选择方案,一开始笔者尝试了ORB特征,想利用特征匹配计算相似度来判断最优的字符结果。ORB特征相比SURF/SIFT更加快速,而且特征不变性也不错。但是在匹配时发现单字符的图片像素点太少,提取的特征点数极少,无法得到较好的匹配结果,只能放弃!
其实也有模板匹配来做字符识别的,但是OPENCV提供的模板匹配对于从同一副图片提取的模板图去匹配样本图效果很好,不是同一副图片时效果很一般。因为笔者用OPENCV的模板匹配一般用来找重复区域。
OCR识别是可以完全用在此处的,OCR识别甚至可以识别汉字,安装OCR的库之后就可以尝试一番!
笔者最后选择了神经网络ANN来做字符分类识别,利用SVM也可以都是分类器之一。使用神经网络可以和caffe的mnist模型有所对比的感觉!
- void ann10(Mat& testroi)
- {
- const string fileform = "*.png";
- const string perfileReadPath = "E:\\vswork\\charSamples";
- const int sample_mun_perclass = ;//训练字符每类数量
- const int class_mun = ;//训练字符类数 0-9 A-Z 除了I、O
- const int image_cols = ;
- const int image_rows = ;
- string fileReadName,fileReadPath;
- char temp[];
- float trainingData[class_mun*sample_mun_perclass][image_rows*image_cols] = { { } };//每一行一个训练样本
- float labels[class_mun*sample_mun_perclass][class_mun] = { { } };//训练样本标签
- for (int i = ; i <= class_mun - ; i++)//不同类
- {
- //读取每个类文件夹下所有图像
- int j = ;//每一类读取图像个数计数
- if (i <= )//0-9
- {
- sprintf(temp, "%d", i);
- //printf("%d\n", i);
- }
- else//A-Z
- {
- sprintf(temp, "%c", i + );
- //printf("%c\n", i+55);
- }
- fileReadPath = perfileReadPath + "/" + temp + "/" + fileform;
- cout << "文件夹" << fileReadPath << endl;
- HANDLE hFile;
- LPCTSTR lpFileName = StringToWchar(fileReadPath);//指定搜索目录和文件类型,如搜索d盘的音频文件可以是"D:\\*.mp3"
- WIN32_FIND_DATA pNextInfo; //搜索得到的文件信息将储存在pNextInfo中;
- hFile = FindFirstFile(lpFileName, &pNextInfo);//请注意是 &pNextInfo , 不是 pNextInfo;
- if (hFile == INVALID_HANDLE_VALUE)
- {
- continue;//搜索失败
- }
- //do-while循环读取
- do
- {
- if (pNextInfo.cFileName[] == '.')//过滤.和..
- continue;
- j++;//读取一张图
- //wcout<<pNextInfo.cFileName<<endl;
- //printf("%s\n",WcharToChar(pNextInfo.cFileName));
- //对读入的图片进行处理
- Mat srcImage = imread(perfileReadPath + "/" + temp + "/" + WcharToChar(pNextInfo.cFileName), CV_LOAD_IMAGE_GRAYSCALE);
- Mat resizeImage;
- Mat trainImage;
- Mat result;
- resize(srcImage, resizeImage, Size(image_cols, image_rows), (, ), (, ), CV_INTER_AREA);//使用象素关系重采样。当图像缩小时候,该方法可以避免波纹出现
- threshold(resizeImage, trainImage, , , CV_THRESH_BINARY | CV_THRESH_OTSU);
- for (int k = ; k<image_rows*image_cols; ++k)
- {
- trainingData[i*sample_mun_perclass + (j - )][k] = (float)trainImage.data[k];
- //trainingData[i*sample_mun_perclass+(j-1)][k] = (float)trainImage.at<unsigned char>((int)k/8,(int)k%8);//(float)train_image.data[k];
- //cout<<trainingData[i*sample_mun_perclass+(j-1)][k] <<" "<< (float)trainImage.at<unsigned char>(k/8,k%8)<<endl;
- }
- } while (FindNextFile(hFile, &pNextInfo) && j<sample_mun_perclass);//如果设置读入的图片数量,则以设置的为准,如果图片不够,则读取文件夹下所有图片
- }
- // Set up training data Mat
- Mat trainingDataMat(class_mun*sample_mun_perclass, image_rows*image_cols, CV_32FC1, trainingData);
- cout << "trainingDataMat——OK!" << endl;
- // Set up label data
- for (int i = ; i <= class_mun - ; ++i)
- {
- for (int j = ; j <= sample_mun_perclass - ; ++j)
- {
- for (int k = ; k < class_mun; ++k)
- {
- if (k == i)
- if (k == )
- {
- labels[i*sample_mun_perclass + j][] = ;
- }
- else if (k == )
- {
- labels[i*sample_mun_perclass + j][] = ;
- }
- else
- {
- labels[i*sample_mun_perclass + j][k] = ;
- }
- else
- labels[i*sample_mun_perclass + j][k] = ;
- }
- }
- }
- Mat labelsMat(class_mun*sample_mun_perclass, class_mun, CV_32FC1, labels);
- cout << "labelsMat:" << endl;
- ofstream outfile("out.txt");
- outfile << labelsMat;
- //cout<<labelsMat<<endl;
- cout << "labelsMat——OK!" << endl;
- //训练代码
- cout << "training start...." << endl;
- CvANN_MLP bp;
- // Set up BPNetwork's parameters
- CvANN_MLP_TrainParams params;
- params.train_method = CvANN_MLP_TrainParams::BACKPROP;
- params.bp_dw_scale = 0.001;
- params.bp_moment_scale = 0.1;
- params.term_crit = cvTermCriteria(CV_TERMCRIT_ITER | CV_TERMCRIT_EPS, , 0.0001); //设置结束条件
- //params.train_method=CvANN_MLP_TrainParams::RPROP;
- //params.rp_dw0 = 0.1;
- //params.rp_dw_plus = 1.2;
- //params.rp_dw_minus = 0.5;
- //params.rp_dw_min = FLT_EPSILON;
- //params.rp_dw_max = 50.;
- //Setup the BPNetwork
- Mat layerSizes = (Mat_<int>(, ) << image_rows*image_cols, , , , class_mun);
- bp.create(layerSizes, CvANN_MLP::SIGMOID_SYM, 1.0, 1.0);//CvANN_MLP::SIGMOID_SYM
- //CvANN_MLP::GAUSSIAN
- //CvANN_MLP::IDENTITY
- cout << "training...." << endl;
- bp.train(trainingDataMat, labelsMat, Mat(), Mat(), params);
- bp.save("../bpcharModel.xml"); //save classifier
- cout << "training finish...bpModel.xml saved " << endl;
- return;
- }
ann10
ann10函数主要完成读取图片训练ANN网络的功能。
注意点:
修改图片文件类型 fileform;
修改训练图片路径 perfileReadPath等;
修改训练图片数量 sample_mun_perclass;
修改训练类别数 class_mun;(34类是因为IO与10很像,所以少了两类);
image_cols和image_rows根据自己图片情况修改;
观察代码发现训练文件在工程目录的 bpcharModel.xml;之后调用该网络模型即可,网上有很多网络调用和网络训练没有分开,这样你每预测分类一个字符都要重新训练网络会相当浪费时间的,笔者的渣电脑训练一次就要几分钟,每次分类都训练时间有点伤不起。。。真正的实际应用也是用训练好的网络参数直接调用,速度很快。就像caffe中的深度神经网络,使用网络分类时也只是调用生成好的caffemodel和标签、solver文件就行了,如果还要重新训练一小时根本没有实用性。
- void predictann(Mat testroi)
- {
- //测试神经网络
- CvANN_MLP bp;
- bp.load("E:\\vswork\\CarNumRecog\\bpcharModel.xml");
- const int image_cols = ;
- const int image_rows = ;
- cout << "测试:" << endl;
- //Mat test_image = imread("E:\\vswork\\charSamples\\3.png", CV_LOAD_IMAGE_GRAYSCALE);
- Mat test_temp;
- resize(testroi, test_temp, Size(image_cols, image_rows), (, ), (, ), CV_INTER_AREA);//使用象素关系重采样。当图像缩小时候,该方法可以避免波纹出现
- threshold(test_temp, test_temp, , , CV_THRESH_BINARY | CV_THRESH_OTSU);
- Mat_<float>sampleMat(, image_rows*image_cols);
- for (int i = ; i<image_rows*image_cols; ++i)
- {
- sampleMat.at<float>(, i) = (float)test_temp.at<uchar>(i / , i % );
- }
- Mat responseMat;
- bp.predict(sampleMat, responseMat);
- Point maxLoc;
- double maxVal = ;
- minMaxLoc(responseMat, NULL, &maxVal, NULL, &maxLoc);
- char temp[];
- if (maxLoc.x <= )//0-9
- {
- sprintf(temp, "%d", maxLoc.x);
- //printf("%d\n", i);
- }
- else//A-Z
- {
- sprintf(temp, "%c", maxLoc.x + );
- //printf("%c\n", i+55);
- }
- cout << "识别结果:" << temp << " 相似度:" << maxVal * << "%" << endl;
- imshow("test_image", testroi);
- waitKey();
- return;
- }
predictann
predictann函数就是调用ann10函数生成的网络模型文件,进行预测分类的功能。
上述车牌的单字符识别效果如下:
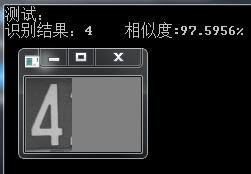
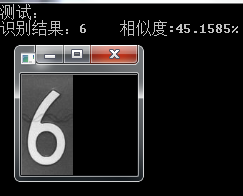
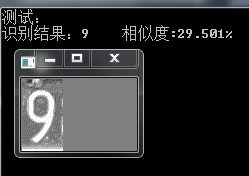
可以看到有的相似度很高,有的却很低,也有一些识别错误的,我不再显示。。。
相比之前使用的caffe mnist识别率真的是差距有点大,以后有机会将mnist的模型来识别车牌字符试试~~
度盘失效了,附上我的github地址,里面会传数据集和完整代码!欢迎大家star 和 fork 我~~
https://github.com/chenzhefan/CarNumRecognize.git
opencv 车牌字符分割 ANN网络识别字符的更多相关文章
- OpenCV+Python识别车牌和字符分割的实现
本篇文章主要基于python语言和OpenCV库(cv2)进行车牌区域识别和字符分割,开篇之前针对在python中安装opencv的环境这里不做介绍,可以自行安装配置! 车牌号检测需要大致分为四个部分 ...
- 车牌识别LPR(六)-- 字符分割
第六篇:字符分割 在知道了车牌字符的规律之后,可以根据车牌的特点对字符进行分割.一般最容易想到的方法就是根据车牌投影.像素统计特征对车牌图像进行字符分割的方法.是一种最常用的.最基本的.最简单的车牌字 ...
- 字符型图片验证码识别完整过程及Python实现
字符型图片验证码识别完整过程及Python实现 1 摘要 验证码是目前互联网上非常常见也是非常重要的一个事物,充当着很多系统的 防火墙 功能,但是随时OCR技术的发展,验证码暴露出来的安全问题也越 ...
- EasyPR--开发详解(7)字符分割
大家好,好久不见了. 一转眼距离上一篇博客已经是4个月前的事了.要问博主这段时间去干了什么,我只能说:我去“外面看了看”. 图1 我想去看看 在外面跟几家创业公司谈了谈,交流了一些大数据与机器视觉相关 ...
- EasyPR源码剖析(8):字符分割
通过前面的学习,我们已经可以从图像中定位出车牌区域,并且通过SVM模型删除“虚假”车牌,下面我们需要对车牌检测步骤中获取到的车牌图像,进行光学字符识别(OCR),在进行光学字符识别之前,需要对车牌图块 ...
- Python识别字符型图片验证码
前言 验证码是目前互联网上非常常见也是非常重要的一个事物,充当着很多系统的 防火墙 功能,但是随时OCR技术的发展,验证码暴露出来的安全问题也越来越严峻.本文介绍了一套字符验证码识别的完整流程,对于验 ...
- 使用opencv320演示window平台cmake的使用方法以及一个使用CNN识别字符的例子 20180408
cmake是干啥的: 本来是Linux平台的一个编译工具. window平台上,cmake可以生成一个可以用vs(可以指定)打开的工程,然后使用 vs 编译相关的 lib.dll 或者 exe以供使用 ...
- 1.Java 字符分割
使用方法 性能比较 使用方法 或|,点.,加+,乘*,在字符串中出现时,如果这个字符串需要被split,则split时候,需要在前面加两个反斜杠. 与&,在split时候,不需要转义. 一.j ...
- CDH5.4.5运行多字符分割记录
准备工作: 测试文件内容:cis_cust_imp_info 20131131|+|100010001001|+|BR01|+|2000.0120131131|+|100010001002|+|BR0 ...
随机推荐
- Linux下利用json-c从一个json数组中提取每一个元素中的部分字段组成一个新json数组
先把代码贴上来,有时间整理一下 首先说一下要实现的功能: 假定现在有一个json格式的字符串,而且他是一个josn中的数组,比如: [ { "id": "NEW20170 ...
- 5 vue-cli整合axios的几种方法
vue-cli配置axios https://www.cnblogs.com/rinzoo/p/7880525.html https://www.cnblogs.com/XHappyness/p/76 ...
- 【版本管理】git分支管理
创建与合并分支: 首先,我们创建dev分支,然后切换到dev分支: git checkout -b dev,命令加上-b参数表示创建并切换, 相当于以下两条命令: git branch dev: gi ...
- 一本通1641【例 1】矩阵 A×B
1641: [例 1]矩阵 A×B sol:矩阵乘法模板.三个for循环 #include <bits/stdc++.h> using namespace std; typedef lon ...
- Mybatis返回HashMap时,某个字段值为null时,不会保存key
转载: http://blog.csdn.net/little2z/article/details/38525327 mybatis 的 callSettersOnNulls 问题项目用到mybati ...
- 奔小康赚大钱 HDU - 2255(最大权值匹配 KM板题)
奔小康赚大钱 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Subm ...
- 【BZOJ1205】[HNOI2005]星际贸易(动态规划)
[BZOJ1205][HNOI2005]星际贸易(动态规划) 题面 BZOJ 洛谷 题解 第一问就是一个裸\(dp\),因为什么都不用考虑... 所以设\(f[i][j]\)表示当前停靠在第\(i\) ...
- 【bzoj2440】 中山市选2011—完全平方数
http://www.lydsy.com/JudgeOnline/problem.php?id=2440 (题目链接) 题意 求第K个不含有完全平方因子的数 Solution 没想到莫比乌斯还可以用来 ...
- Eclipse Neon安装指导
[下载] 前往Eclipse官网:http://www.eclipse.org/,点击DOWNLOAD: 进入下载页面后,会显示如下下载界面: 找到 Get Eclipse Neon,然后点击下面的” ...
- P2073 送花
P2073 送花 题目背景 小明准备给小红送一束花,以表达他对小红的爱意.他在花店看中了一些花,准备用它们包成花束. 题目描述 这些花都很漂亮,每朵花有一个美丽值W,价格为C. 小明一开始有一个空的花 ...