大数据入门第十七天——storm上游数据源 之kafka详解(三)其他问题
一、kafka文件存储机制
1.topic存储
在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序序号,第一个partiton序号从0开始,序号最大值为partitions数量减1。
以上面创建的topic_1为例,在mini1这台机器上的目录如下:
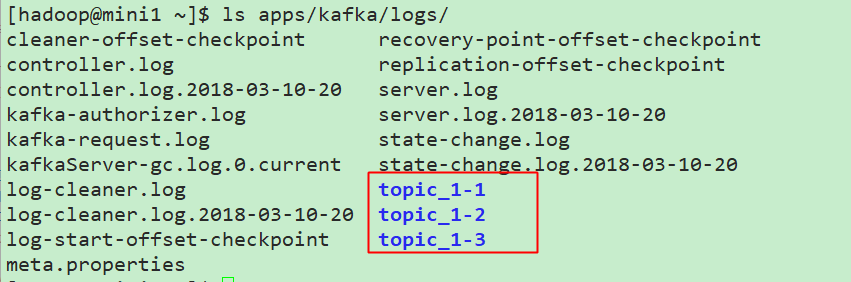
综合查看3台机器的分布,如下所示:
mini1:
1 2 3
mini2:
0 2 3
mini3:
0 1
// 这里是设置了副本数量,如果为了看清楚分配情况,可以设置一个副本来进行查看,其中,分区的分配是通过以下一个简单的小算法进行确认的:
list(mini1,mini2,mini3)
for(int i = 0; i < partitionNum; i++) {
broIdx = i%broker;
hostname = list.get(broIdx);//borIdx+1?
}
// 最好的方式是试验验证!
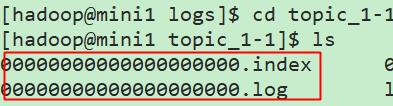
2.segment
每一个partition目录下的文件被平均切割成大小相等(有一个默认的滚动的大小,可以手动去设置)的数据文件,
每一个数据文件都被称为一个段(segment file),但每个段消息数量不一定相等,这种特性能够使得老的segment可以被快速清除。
默认保留7天的数据。
滚动的示意如下:

二、其他问题
主要是第一篇kafka入门中提出的几个问题
1、kafka是什么
类JMS消息队列,结合JMS中的两种模式,可以有多个消费者主动拉取数据,在JMS中只有点对点模式才有消费者主动拉取数据。
kafka是一个生产-消费模型。
Producer:生产者,只负责数据生产,生产者的代码可以集成到任务系统中。
数据的分发策略由producer决定,默认是defaultPartition Utils.abs(key.hashCode) % numPartitions
Broker:当前服务器上的Kafka进程,俗称拉皮条。只管数据存储,不管是谁生产,不管是谁消费。
在集群中每个broker都有一个唯一brokerid,不得重复。
Topic:目标发送的目的地,这是一个逻辑上的概念,落到磁盘上是一个partition的目录。
partition的目录中有多个segment组合(index,log)
一个Topic对应多个partition[0,1,2,3],一个partition对应多个segment组合。一个segment有默认的大小是1G。
每个partition可以设置多个副本(replication-factor 1),会从所有的副本中选取一个leader出来。
所有读写操作都是通过leader来进行的。
特别强调,和mysql中主从有区别,mysql做主从是为了读写分离,在kafka中读写操作都是leader。
ConsumerGroup:数据消费者组,ConsumerGroup可以有多个,每个ConsumerGroup消费的数据都是一样的。
可以把多个consumer线程划分为一个组,组里面所有成员共同消费一个topic的数据,组员之间不能重复消费。 2、kafka生产数据时的分组策略
默认是defaultPartition(在kafka的productor.properties中有相关配置) Utils.abs(key.hashCode) % numPartitions
上文中的key是producer在发送数据时传入的,produer.send(KeyedMessage(topic,myPartitionKey,messageContent)) 3、kafka如何保证数据的完全生产
ack机制:broker表示发来的数据已确认接收无误,表示数据已经保存到磁盘。
0:不等待broker返回确认消息
1:等待topic中某个partition leader保存成功的状态反馈
-1:等待topic中某个partition 所有副本都保存成功的状态反馈 4、broker如何保存数据
在理论环境下,broker按照顺序读写的机制,可以每秒保存600M的数据。主要通过pagecache机制,
尽可能的利用当前物理机器上的空闲内存来做缓存。
当前topic所属的broker,必定有一个该topic的partition,partition是一个磁盘目录。
partition的目录中有多个segment组合(index,log) 5、partition如何分布在不同的broker上
int i = 0
list{kafka01,kafka02,kafka03} for(int i=0;i<5;i++){
brIndex = i%broker;
hostName = list.get(brIndex) // brIndex+1?
} 6、consumerGroup的组员和partition之间如何做负载均衡
最好是一一对应,一个partition对应一个consumer。
如果consumer的数量过多,必然有空闲的consumer。 算法:
假如topic1,具有如下partitions: P0,P1,P2,P3
加入group中,有如下consumer: C1,C2
首先根据partition索引号对partitions排序: P0,P1,P2,P3
根据consumer.id排序: C0,C1
计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)] 7、如何保证kafka消费者消费数据是全局有序的
伪命题
如果要全局有序的,必须保证生产有序,存储有序,消费有序。
由于生产可以做集群,存储可以分片,消费可以设置为一个consumerGroup,要保证全局有序,就需要保证每个环节都有序。
只有一个可能,就是一个生产者,一个partition,一个消费者。这种场景和大数据应用场景相悖。
三、更多参考
参考博文:https://blog.csdn.net/lingbo229/article/details/80761778
https://www.jianshu.com/p/d3e963ff8b70
大数据入门第十七天——storm上游数据源 之kafka详解(三)其他问题的更多相关文章
- 大数据入门第十七天——storm上游数据源 之kafka详解(一)入门与集群安装
一.概述 1.kafka是什么 根据标题可以有个概念:kafka是storm的上游数据源之一,也是一对经典的组合,就像郭德纲和于谦 根据官网:http://kafka.apache.org/intro ...
- 大数据入门第十七天——storm上游数据源 之kafka详解(二)常用命令
一.kafka常用命令 1.创建topic bin/kafka-topics. --replication-factor --zookeeper mini1: // 如果配置了PATH可以省略相关命令 ...
- 大数据入门第十六天——流式计算之storm详解(一)入门与集群安装
一.概述 今天起就正式进入了流式计算.这里先解释一下流式计算的概念 离线计算 离线计算:批量获取数据.批量传输数据.周期性批量计算数据.数据展示 代表技术:Sqoop批量导入数据.HDFS批量存储数据 ...
- 大数据入门第十八天——kafka整合flume、storm
一.实时业务指标分析 1.业务 业务: 订单系统---->MQ---->Kakfa--->Storm 数据:订单编号.订单时间.支付编号.支付时间.商品编号.商家名称.商品价格.优惠 ...
- 大数据入门第十六天——流式计算之storm详解(二)常用命令与wc实例
一.常用命令 1.提交命令 提交任务命令格式:storm jar [jar路径] [拓扑包名.拓扑类名] [拓扑名称] torm jar examples/storm-starter/storm-st ...
- 大数据入门第八天——MapReduce详解(三)MR的shuffer、combiner与Yarn集群分析
/mr的combiner /mr的排序 /mr的shuffle /mr与yarn /mr运行模式 /mr实现join /mr全局图 /mr的压缩 今日提纲 一.流量汇总排序的实现 1.需求 对日志数据 ...
- 大数据入门第二十天——scala入门(一)入门与配置
一.概述 1.什么是scala Scala是一种多范式的编程语言,其设计的初衷是要集成面向对象编程和函数式编程的各种特性.Scala运行于Java平台(Java虚拟机),并兼容现有的Java程序. ...
- 大数据入门第十九天——推荐系统与mahout(一)入门与概述
一.推荐系统概述 为了解决信息过载和用户无明确需求的问题,找到用户感兴趣的物品,才有了个性化推荐系统.其实,解决信息过载的问题,代表性的解决方案是分类目录和搜索引擎,如hao123,电商首页的分类目录 ...
- 大数据入门第七天——MapReduce详解(一)入门与简单示例
一.概述 1.map-reduce是什么 Hadoop MapReduce is a software framework for easily writing applications which ...
随机推荐
- Python网络爬虫笔记(一):网页抓取方式和LXML示例
(一) 三种网页抓取方法 1. 正则表达式: 模块使用C语言编写,速度快,但是很脆弱,可能网页更新后就不能用了. 2. Beautiful Soup 模块使用Python编写,速度慢. ...
- 机器学习实战(Machine Learning in Action)学习笔记————04.朴素贝叶斯分类(bayes)
机器学习实战(Machine Learning in Action)学习笔记————04.朴素贝叶斯分类(bayes) 关键字:朴素贝叶斯.python.源码解析作者:米仓山下时间:2018-10-2 ...
- CSS 小结笔记之图标字体(IconFont)
本篇主要介绍一种非常好用的图标大法——图标字体(IconFont). 什么是图标字体?顾名思义,它是一种字体,只不过这个字体显示的并不是具体的文字之类的,而是各种图标. 网站上经常会用到各种图标,之前 ...
- maven学习笔记--maven项目创建
使用Maven命令和Eclipse的Maven插件,创建Maven项目 (1)maven命令生成项目 新建一个文件目录,dos进入该目录并执行下面命令: mvn archetype:c ...
- CAC的Debian-8-64bit安装BBR正确打开方式
装过三台debian 64 bit, CAC, 2欧, KVM虚拟机 做法都一样---下面说下正确安装方式 0. 有装锐速记得先删除,免得换核心后,锐速在扯后腿. 1.换4.9版kernel ...
- 转:C#综合揭秘——细说多线程(下)
原文地址:http://www.cnblogs.com/leslies2/archive/2012/02/08/2320914.html 引言 本文主要从线程的基础用法,CLR线程池当中工作者线程与I ...
- js经典应用
一.js字符串转数字: 1.parseInt()和parseFloat()两个转换函数: 2.强制类型转换,Number(value)——把给定的值转换成数字(可以是整数或浮点数): 3.利用js变量 ...
- 创建SQL Server数据库集群的经历
自己尝试安装SQL Server集群和配置AlwaysOn可用性组,服务器系统是Windows Server 2012 R2,SQL Server是2014企业版,我的环境是一台服务器,然后用Hype ...
- Windows用命令打开常用的设置页面和常用快捷键
Win+R输入以下内容来快捷打开常用设置 compmgmt.msc # 计算机管理 diskmgmt.msc # 磁盘管理 devmgmt.msc # 设备管理 services.msc # 服务管理 ...
- Windows 软件推荐大全【all】
FastStone: 视频下载王: IDE: FinalShell: 免费海外服务器远程桌面加速,ssh加速,双边tcp加速,内网穿透.FinalShell使用---Xshell的良心国产软件 P ...