hadoop 修改datanode balance带宽使用限制
前段时间,一个客户现场的Hadoop看起来很不正常,有的机器的存储占用达到95%,有的机器只有40%左右,刚好前任的负责人走了,这边还没有明确接班人的时候。
我负责的大数据计算部分,又要依赖Hadoop的基础平台,要是Hadoop死了,我的报表也跑不出来(专业背锅)。
做下balance,让各个节点的存储均衡一下。
1、首先需要配上这个参数:
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value></value>
<description>hdfs做balance的占用的网络带宽,建议配置网卡带宽的一半(//*=480MBps)</description>
</property>
2、重启datanode
# 停止datanode
[hadoop@venn06 sbin]$ ./hadoop-daemon.sh stop datanode
stopping datanode # 启动datanode
[hadoop@venn06 sbin]$ ./hadoop-daemon.sh start datanode
starting datanode, logging to /opt/hadoop/hadoop3/logs/hadoop-hadoop-datanode-venn06.out
服务器网卡的带宽有限,不设置这个参数,做balance的时候,会把网卡的带宽跑满。需要移动的block很多,执行时间就会很长,会导致集群网络资源不足,任务跑得很慢。
3、执行balance
[hadoop@venn05 bin]$ pwd
/opt/hadoop/hadoop3/bin
[hadoop@venn05 bin]$ nohup ./hdfs balancer -threshold 1 &
由于执行时间会很长,所以把命令放到后台执行。
HDFS做balance的方式大概如下:
1、计算集群中需要移动的block数量,计算需要移动的文件大小。
2、并发的从资源占用高的机器,往资源占用低的机器移数据。一批一批的移,一批的大小,会根据需要移动的文件大小计算。
3、重复第1步,直到资源均衡(1%左右的差距)
HDFS做balance的时候,会先移动block,成功后才会删除数据,只要集群网络资源充足,可以不警慎的执行balance操作,随时停也不影响,不会丢数据。
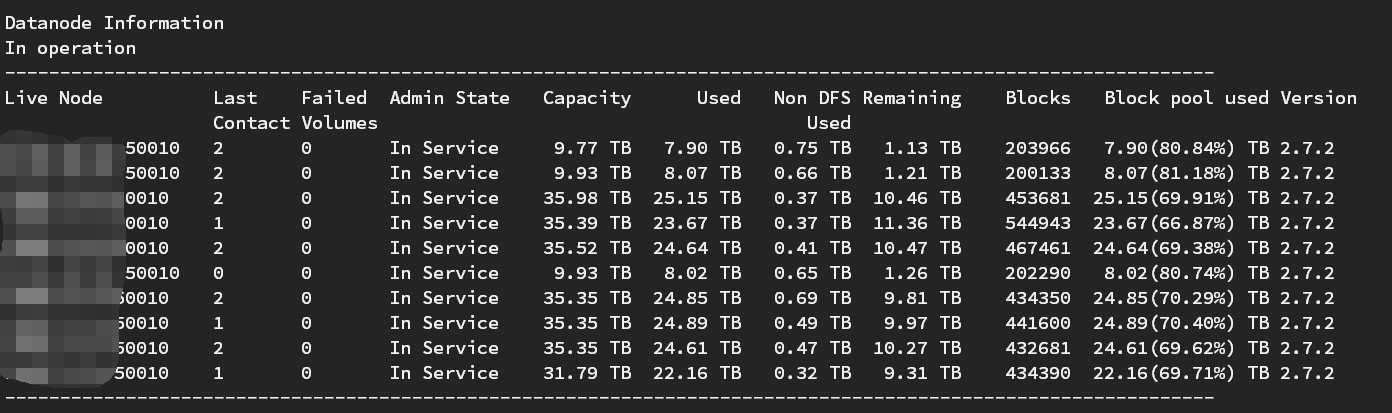
由于datanode 空间大小不同,所以有的机器磁盘占用会高一点。
hadoop 修改datanode balance带宽使用限制的更多相关文章
- Hadoop的datanode无法启动
Hadoop的datanode无法启动 hdfs-site中配置的dfs.data.dir为/usr/local/hadoop/hdfs/data 用bin/hadoop start-all.sh启动 ...
- 设置Hadoop的 dataNode的单个Map的内存配置
1.进入hadoop的配置目录 ,找到 环境变量的 $HADOOP_HOME cd $HADOOP_HOME 2.修改dataNode 节点的 单个map的能使用的内存配置 找到配置的文件: /opt ...
- hadoop修改MR的提交的代码程序的副本数
hadoop修改MR的提交的代码程序的副本数 Under-Replicated Blocks的数量很多,有7万多个.hadoop fsck -blocks 检查发现有很多replica missing ...
- linux及hadoop修改权限
linux下修改文件权限: 在shell环境里输入:ls -l 或者 ls -lh drwxr-xr-x 2 nsf users 1024 12-10 17:37 下载文件备份对应:文件属性 连接数 ...
- hadoop启动 datanode的live node为0
hadoop启动 datanode的live node为0 浏览器访问主节点50070端口,发现 Data Node 的 Live Node 为 0 查看子节点的日志 看到 可能是无法访问到主节点的9 ...
- 解决hadoop no dataNode to stop问题
错误原因: datanode的clusterID 和 namenode的 clusterID 不匹配. 解决办法: 1. 打开 hadoop/tmp/dfs/namenode/name/dir 配置对 ...
- hadoop修改
https://github.com/medcl/elasticsearch-analysis-ik/releases hadoop-/etc/hadoop/core-site.xml <con ...
- hadoop 运行 datanode , mac 系统
问题描述 今天使用 hadoop 时,发现无法通过下面命令上传文件到 hadoop 文件系统,会报错. bin/hadoop fs -put input . 运行 jps 后,输出如下: Resour ...
- hadoop中datanode无法启动
一.问题描述 当我多次格式化文件系统时,如 [hadoop@xsh hadoop]$ ./bin/hdfs namenode -format 会出现datanode无法启动,查看日志(/usr/loc ...
随机推荐
- Django的几种缓存的配置
1.缓存的简介 在动态网站中,用户所有的请求,服务器都会去数据库中进行相应的增,删,查,改,渲染模板,执行业务逻辑,最后生成用户看到的页面. 当一个网站的用户访问量很大的时候,每一次的的后台操作,都会 ...
- Android 单元测试四大组件Activity,Service,Content Provider , Broadcast Receiver
先mark, 后补充 https://blog.csdn.net/stevenhu_223/article/details/14054313 https://www.jianshu.com/p/3aa ...
- mysql、oracle 中按照拼音首字母排序
mysql中按照拼音首字母排序 convert(name using gbk) ASC 注:name 为字段名称 oracle中按照拼音首字母排序 nlssort(enterprise_name,'N ...
- TZOJ 2725 See you~(二维树状数组单点更新区间查询)
描述 Now I am leaving hust acm. In the past two and half years, I learned so many knowledge about Algo ...
- TZOJ 1800 Martian Mining(二维dp)
描述 The NASA Space Center, Houston, is less than 200 miles from San Antonio, Texas (the site of the A ...
- HDU 2680 Choose the best route(SPFA)
Problem DescriptionOne day , Kiki wants to visit one of her friends. As she is liable to carsickness ...
- 关于vue搭建项目运行出行的错误问题,简直是大坑啊
解决方法简单粗暴,非常简单粗暴 直接在根目录新建一个test文件夹就可以搞定,用来放置配置文件的 折腾了我一上午啊
- [z]一分钟教你知道乐观锁和悲观锁的区别
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁.传统的关系型数据 ...
- C#—Dev XtraTabControl操作总结如动态增加Tab和关闭选项卡方法等
1:显示行号 找到gridview属性 点击事件 CustomDrawRowIndicator private void gridView1_CustomDrawRowIndicator(object ...
- Redhat Linux网卡配置与绑定
Redhat Linux的网络配置,基本上是通过修改几个配置文件来实现的,虽然也可以用ifconfig来设置IP,用route来配置默认网关,用hostname来配置主机名,但是重启后会丢失. 相关的 ...