solr(四) : springboot 整合 solr
前言:
solr服务器搭起来, 数据导入之后, 就该应用到项目中去了. 那在项目中, 该怎么整合和应用solr呢?
接下来, 就来整合和应用solr
一. 整合
1. 引入jar包
<properties>
<spring.data.solr.version>2.1.1.RELEASE</spring.data.solr.version>
</properties> <dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-solr</artifactId>
<version>${spring.data.solr.version}</version>
</dependency>
</dependencies>
</dependencyManagement> <dependencies>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-solr</artifactId>
</dependency> <!-- 默认 starter 会加载 solrj 进来, 下面这个可不引-->
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>6.6.2</version>
</dependency>
</dependencies>
2. 配置文件
spring:
data:
solr:
host: http://127.0.0.1:8081/solr
host 也可以写成 http://127.0.0.1:8081/solr/collection1.
这里的collection1是 core 的名字, 可以在 core admin 选项中进行配置.
collection1 这里可以理解为数据库的概念. 在操作的时, 如果有多个core, 可以切换数据库. 也就是切换 core

二. 索引和查询
package org.elvin.mysolr.controller; import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController; import java.util.List;
import java.util.Map;
import java.util.UUID; @RestController
@RequestMapping("solr")
public class SolrController { @Autowired
private SolrClient client; /**
* 新增/修改 索引
* 当 id 存在的时候, 此方法是修改(当然, 我这里用的 uuid, 不会存在的), 如果 id 不存在, 则是新增
* @return
*/
@RequestMapping("add")
public String add() {
String uuid = UUID.randomUUID().toString().replaceAll("-", "");
try {
SolrInputDocument doc = new SolrInputDocument();
doc.setField("id", uuid);
doc.setField("content_ik", "我是中国人, 我爱中国"); /* 如果spring.data.solr.host 里面配置到 core了, 那么这里就不需要传 collection1 这个参数
* 下面都是一样的
*/ client.add("collection1", doc);
//client.commit();
client.commit("collection1");
return uuid;
} catch (Exception e) {
e.printStackTrace();
} return "error";
} /**
* 根据id删除索引
* @param id
* @return
*/
@RequestMapping("delete")
public String delete(String id) {
try {
client.deleteById("collection1",id);
client.commit("collection1"); return id;
} catch (Exception e) {
e.printStackTrace();
} return "error";
} /**
* 删除所有的索引
* @return
*/
@RequestMapping("deleteAll")
public String deleteAll(){
try { client.deleteByQuery("collection1","*:*");
client.commit("collection1"); return "success";
} catch (Exception e) {
e.printStackTrace();
}
return "error";
} /**
* 根据id查询索引
* @return
* @throws Exception
*/
@RequestMapping("getById")
public String getById() throws Exception {
SolrDocument document = client.getById("collection1", "536563");
System.out.println(document);
return document.toString();
} /**
* 综合查询: 在综合查询中, 有按条件查询, 条件过滤, 排序, 分页, 高亮显示, 获取部分域信息
* @return
*/
@RequestMapping("search")
public Map<String, Map<String, List<String>>> search(){ try {
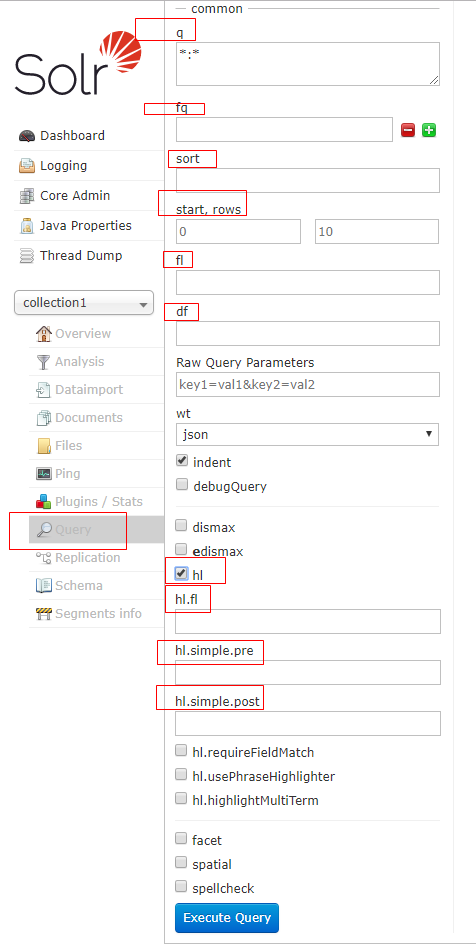
SolrQuery params = new SolrQuery(); //查询条件, 这里的 q 对应 下面图片标红的地方
params.set("q", "手机"); //过滤条件
params.set("fq", "product_price:[100 TO 100000]"); //排序
params.addSort("product_price", SolrQuery.ORDER.asc); //分页
params.setStart(0);
params.setRows(20); //默认域
params.set("df", "product_title"); //只查询指定域
params.set("fl", "id,product_title,product_price"); //高亮
//打开开关
params.setHighlight(true);
//指定高亮域
params.addHighlightField("product_title");
//设置前缀
params.setHighlightSimplePre("<span style='color:red'>");
//设置后缀
params.setHighlightSimplePost("</span>"); QueryResponse queryResponse = client.query(params); SolrDocumentList results = queryResponse.getResults(); long numFound = results.getNumFound(); System.out.println(numFound);
//获取高亮显示的结果, 高亮显示的结果和查询结果是分开放的
Map<String, Map<String, List<String>>> highlight = queryResponse.getHighlighting(); for (SolrDocument result : results) {
System.out.println(result.get("id"));
System.out.println(result.get("product_title"));
//System.out.println(result.get("product_num"));
System.out.println(result.get("product_price"));
//System.out.println(result.get("product_image")); Map<String, List<String>> map = highlight.get(result.get("id"));
List<String> list = map.get("product_title");
System.out.println(list.get(0)); System.out.println("------------------");
System.out.println();
}
return highlight;
} catch (Exception e) {
e.printStackTrace();
}
return null;
} }
三. 补充
这里特别需要补充一点的是, 在页面上执行增改查, 都很方便, 感觉是在做填空题.
但是删除的时候, 貌似不能直接填空了. 有点特别
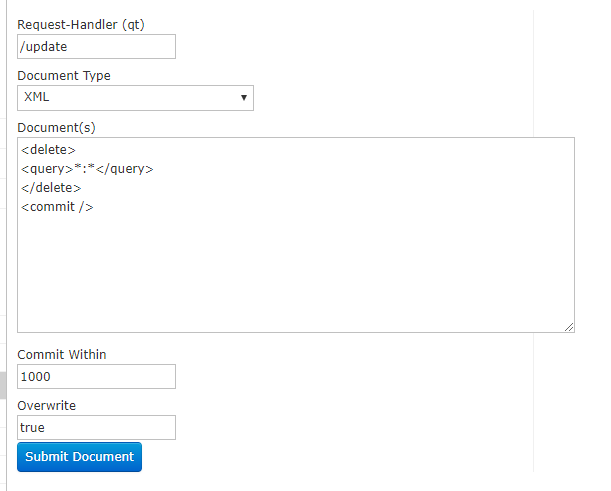
这里需要使用 xml 的方式操作, 且必须加上 commit, 下面的1000ms自动提交, 不适用于delete
<!--删除所有索引-->
<delete>
<query>*:*</query>
</delete>
<commit /> <!-- 根据 id 进行删除-->
<delete>
<id>1</id>
</delete>
<commit />
solr(四) : springboot 整合 solr的更多相关文章
- springboot整合solr
上一篇博客中简要写了solr在windows的安装与配置,这一篇接上文写一下springboot整合solr,代码已经上传到github,传送门. 1.新建core并配置schema 上篇博客中已经有 ...
- solr8.0 springboot整合solr(四)
引言: solr搭建起后,就该应用到java后台开发里了,接下来就用springboot整合应用solr 一:引入jar包 <!--solr--> <dependency> & ...
- mybatis源码学习(四)--springboot整合mybatis原理
我们接下来说:springboot是如何和mybatis进行整合的 1.首先,springboot中使用mybatis需要用到mybatis-spring-boot-start,可以理解为mybati ...
- SpringBoot整合Redis、ApachSolr和SpringSession
SpringBoot整合Redis.ApachSolr和SpringSession 一.简介 SpringBoot自从问世以来,以其方便的配置受到了广大开发者的青睐.它提供了各种starter简化很多 ...
- springboot学习笔记-6 springboot整合RabbitMQ
一 RabbitMQ的介绍 RabbitMQ是消息中间件的一种,消息中间件即分布式系统中完成消息的发送和接收的基础软件.这些软件有很多,包括ActiveMQ(apache公司的),RocketMQ(阿 ...
- 整合Solr与tomcat以及第一个core的配置
整合Solr与tomcat以及第一个core的配置 一.准备安装文件 Tomcat : apache-tomcat-8.5.32.tar.gz Solr:solr-5.3.1.tgz 二.创建目录并解 ...
- 【solr】java整合solr5.0之solrj的使用
1.首先导入solrj需要的的架包 2.需要注意的是低版本是solr是使用SolrServer进行URL实例的,5.0之后已经使用SolrClient替代这个类了,在添加之后首先我们需要根据schem ...
- 整合Solr到Tomcat服务器,并配置IK分词
好久没有接触新东西了,最新开始熟悉solr,实例展示单机环境solr整合. 整合方案一 1.下载Tomcat与solr并解压 Tomcat解压后磁盘路径为D:\program files\Tomcat ...
- solr + tomcat + mysql整合
上一次分享了solr+tomcat的整合 学习就是要一步一步的进行才有趣 所以这次给大家分享solr+tomcat+mysql 一.准备工作 1.一张带数据的数据库表(我用的是这张叫merchant的 ...
随机推荐
- c需要注意的细节
1.在纯的.c文件中,例如struct Stu,之后不可以只使用Stu作为关键字来表示这个定义的结构体类型,一定要使用struct Stu一起作为类似int这种关键字来定义或者获取size. 2.函数 ...
- (树状数组+离散化)lines--hdu --5124
http://acm.hdu.edu.cn/showproblem.php?pid=5124 lines Time Limit: 5000/2500 MS (Java/Others) Memor ...
- Python自动化开发 - Python操作MySQL
本篇对于Python操作MySQL主要使用两种方式: 原生模块 pymsql ORM框架 SQLAchemy 一.pymysql pymsql是Python中操作MySQL的模块,其使用方法和mysq ...
- delphi怎么做桌面滚动文字?
就是在桌面显示从TXT读取出来的字,并限制在1个框内移动(就是从框左边出现往右边移动并从框边消失)我用HDC+textout只是读取字显示到桌面,不知道桌面移动哪位大侠指点下啊,或用其他方法,最好有详 ...
- PostgresSQL使用Copy命令能大大提高数据导入速度
最近在做会员系统,其中会员系统有一份企业信息初始化的数据,需要从SQL Server数据库导入到PostgreSQL,单表的数据近30万.最开始的方案是在SQL Server上生成insert int ...
- C# json字符串转为对象
方法1: using System.Web.Script.Serialization; string ss = "{\"NewsCount\":\"3482\& ...
- HashSet源码解析
此文已由作者赵计刚授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 6.1.对于HashSet需要掌握以下几点 HashSet的创建:HashSet() 往HashSet中添加 ...
- 《Python自动化运维之路》 系统基础信息模块(一)
系统性能收集模块Psutil 目录: 系统性能信息模块psutil 系统性能信息模块psutil psutil能够轻松实现获取系统运行的进程和系统利用率包括(CPU,内存,磁盘 和网络)等.主要用于系 ...
- linux shell实现批量关闭局域网中主机端口
假设局域网中有多台主机,只能开通ssh服务(端口22),如果发现其他服务打开,则全部关闭.通过运行一个shell脚本,完成以上功能.在实际运维中,可以通过puppet等工具更快更好的完成这个功能,所以 ...
- 人工智能-机器学习之Selenium(chrome驱动,火狐驱动)
selenium是一个用于web应用程序测试的工具,Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE.Mozilla Firefox.Mozilla Suite等 ...