spark 2.0.0集群安装与hive on spark配置
1. 环境准备:
JDK1.8
hive 2.3.4
hadoop 2.7.3
hbase 1.3.3
scala 2.11.12
mysql5.7
2. 下载spark2.0.0
cd /home/worksapce/software
wget https://archive.apache.org/dist/spark/spark-2.0.0/spark-2.0.0-bin-hadoop2.7.tgz
tar -xzvf spark-2.0.-bin-hadoop2..tgz
mv spark-2.0.-bin-hadoop2. spark-2.0.
3. 配置系统环境变量
vim /etc/profile
末尾添加
#spark
export SPARK_HOME=/home/workspace/software/spark-2.0.
export PATH=:$PATH:$SPARK_HOME/bin
4. 配置spark-env.sh
cd /home/workspace/software/spark-2.0./conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
末尾添加:
export JAVA_HOME=/usr/java/jdk1..0_172-amd64
export SCALA_HOME=/home/workspace/software/scala-2.11.
export HADOOP_HOME=/home/workspace/hadoop-2.7.
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop export SPARK_HOME=/home/workspace/software/spark-2.0.
export SPARK_DIST_CLASSPATH=$(/home/workspace/hadoop-2.7./bin/hadoop classpath)
export SPARK_LIBRARY_PATH=$SPARK_HOME/lib
export SPARK_LAUNCH_WITH_SCALA= export SPARK_WORKER_DIR=$SPARK_HOME/work
export SPARK_LOG_DIR=$SPARK_HOME/logs
export SPARK_PID_DIR=$SPARK_HOME/run export SPARK_MASTER_IP=192.168.1.101
export SPARK_MASTER_HOST=192.168.1.101
export SPARK_MASTER_WEBUI_PORT=
export SPARK_MASTER_PORT= export SPARK_LOCAL_IP=192.168.1.101 export SPARK_WORKER_CORES=
export SPARK_WORKER_PORT= export SPARK_WORKER_MEMORY=4g
export SPARK_DRIVER_MEMORY=4g
export SPARK_EXECUTOR_MEMORY=4g
5. 配置spark-defaults.conf
cd /home/workspace/software/spark-2.0./conf
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
末尾添加
spark.master spark://192.168.1.101:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://192.168.1.101:9000/spark-log
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.executor.memory 4g
spark.driver.memory 4g
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
6. 配置slaves
cd /home/workspace/software/spark-2.0./conf
cp slaves.template slaves
vim slaves
末尾添加
192.168.1.101
192.168.1.102
192.168.1.103
7. 创建相关目录(在spark-env.sh中定义)
hdfs dfs -mkdir -p /spark-log
hdfs dfs -chmod /spark-log
mkdir -p $SPARK_HOME/work $SPARK_HOME/logs $SPARK_HOME/run
mkdir -p $HIVE_HOME/logs
8.修改hive-site.xml
vim $HIVE_HOME/conf/hive-site.xml
把文件内容修改为
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/hive/tmp</value>
<description>Scratch space for Hive jobs</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/hive/log</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.1.103:9083</value>
</property>
<!--hive server2 settings-->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>192.168.1.103</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.webui.host</name>
<value>192.168.1.103</value>
</property>
<property>
<name>hive.server2.webui.host.port</name>
<value>10002</value>
</property>
<property>
<name>hive.server2.long.polling.timeout</name>
<value>5000</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>true</value>
</property>
<!--metadata database connection string settings-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.1.103:3308/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
<property>
<name>datanucleus.autoCreateSchema </name>
<value>false</value>
<description>creates necessary schema on a startup if one doesn't exist. set this to false, after creating it once</description>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>true</value>
</property>
<!-- hive on mr-->
<!--
<property>
<name>mapred.job.tracker</name>
<value>http://192.168.1.101:9001</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
-->
<!--hive on spark or spark on yarn -->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<property>
<name>spark.home</name>
<value>/home/workspace/software/spark-2.0.0</value>
</property>
<property>
<name>spark.master</name>
<value>spark://192.168.1.101:7077</value>
<!-- 或者yarn-cluster/yarn-client -->
</property>
<property>
<name>spark.submit.deployMode</name>
<value>client</value>
</property>
<property>
<name>spark.eventLog.enabled</name>
<value>true</value>
</property>
<property>
<name>spark.eventLog.dir</name>
<value>hdfs://192.168.1.101:9000/spark-log</value>
</property>
<property>
<name>spark.serializer</name>
<value>org.apache.spark.serializer.KryoSerializer</value>
</property>
<property>
<name>spark.executor.memeory</name>
<value>4g</value>
</property>
<property>
<name>spark.driver.memeory</name>
<value>4g</value>
</property>
<property>
<name>spark.executor.extraJavaOptions</name>
<value>-XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"</value>
</property>
<!--concurrency support-->
<property>
<name>hive.support.concurrency</name>
<value>true</value>
<description>Whether hive supports concurrency or not. A zookeeper instance must be up and running for the default hive lock manager to support read-write locks.</description>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<!--transaction support-->
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
</property>
<property>
<name>hive.stats.autogather</name>
<value>true</value>
<description>A flag to gather statistics automatically during the INSERT OVERWRITE command.</description>
</property>
<!--hive web interface settings, I think this is useless,so comment it-->
<!--
<property>
<name>hive.hwi.listen.host</name>
<value>192.168.1.131</value>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
</property>
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-2.1.1.war</value>
</property>
-->
</configuration>
9. 拷贝hive-site.xml到spark/conf下
cp $HIVE_HOME/conf/hive-site.xml $SPARK_HOME/conf
10 分发到192.168.1.102,192.168.1.103
cd /home/workspace/software/
scp -r spark-2.0. 192.168.1.102:/home/workspace/software
scp -r spark-2.0. 192.168.1.103:/home/workspace/software
修改102,103上的SPARK_LOCAL_IP值
vim /home/workspace/software/spark-2.0./conf/spark-env.sh
将SPARK_LOCAL_IP分别改为192.168.1.102,192.168.1.103
11 将mysql jar包复制到$SPARK_HOME/lib目录下(每台机器都要做)
cp $HIVE_HOME/lib/mysql-connector-java-5.1..jar $SPARK_HOME/lib
注:本例中之前已经安装好hive,如果没有,请到mysql官网网站下载对应的jdbc jar包
12. 启动spark集群
在spark master节点上(本例为192.168.1.101)执行下面语句
$SPARK_HOME/sbin/start-all.sh
192.168.1.101
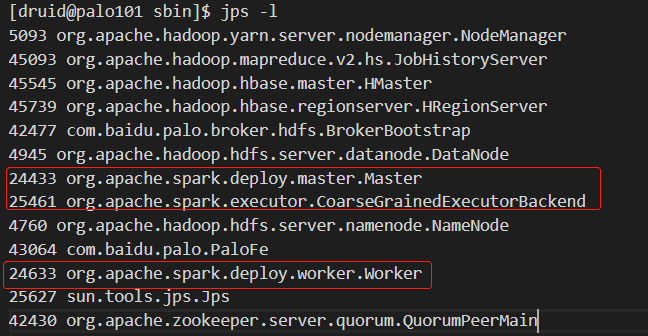
192.168.1.102:
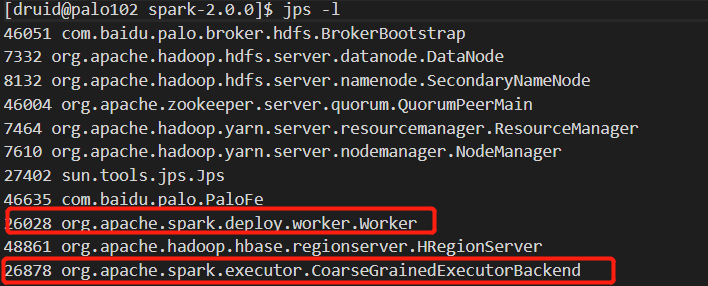
192.168.1.103:

浏览器打开http:192.168.1.101:18080

13.测试使用
[druid@palo101 apache-maven-3.6.]$ hive
/tmp/druid
Logging initialized using configuration in file:/home/workspace/software/apache-hive-2.3./conf/hive-log4j2.properties Async: true
hive> use kylin_flat_db;
OK
Time taken: 1.794 seconds
hive> desc kylin_sales;
OK
trans_id bigint
part_dt date Order Date
lstg_format_name string Order Transaction Type
leaf_categ_id bigint Category ID
lstg_site_id int Site ID
slr_segment_cd smallint
price decimal(,) Order Price
item_count bigint Number of Purchased Goods
seller_id bigint Seller ID
buyer_id bigint Buyer ID
ops_user_id string System User ID
ops_region string System User Region
Time taken: 0.579 seconds, Fetched: row(s)
hive> select trans_id, sum(price) as total, count(seller_id) as cnt from kylin_sales group by trans_id order by cnt desc limit 10;
Query ID = druid_20190209000716_9676460c-1a76-456d-9bd6-b6f557d5e02c
Total jobs =
Launching Job out of
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Spark Job = 72720bf1-750d-4f6f-bf9c-5cffa0e4c73b Query Hive on Spark job[] stages: [, , ] Status: Running (Hive on Spark job[])
--------------------------------------------------------------------------------------
STAGES ATTEMPT STATUS TOTAL COMPLETED RUNNING PENDING FAILED
--------------------------------------------------------------------------------------
Stage- ........ FINISHED
Stage- ........ FINISHED
Stage- ........ FINISHED
--------------------------------------------------------------------------------------
STAGES: / [==========================>>] % ELAPSED TIME: 10.12 s
--------------------------------------------------------------------------------------
Status: Finished successfully in 10.12 seconds
OK
33.4547
15.4188
88.6492
40.4308
63.5407
59.2537
79.8884
18.3204
78.6241
5.8088
Time taken: 21.788 seconds, Fetched: row(s)
hive>
13 FAQ:
13.1 如果在使用过程中遇到类似下面的错误
Exception in thread "main" java.lang.NoSuchFieldError: SPARK_RPC_SERVER_ADDRESS
通过查看hive的日志文件(在/tmp/{user}/hive.log),这是因为默认使用的spark安装包是继承了hive的包,名字为spark-xxx-bin-hadoopxx.xx.tgz都是继承了hive的包,在hive on spark模式下,会出现冲突,解决办法有两个:
1) 手动编译spark不包含hive的包,具体请参见本人的博文Spark2.0.0源码编译,编译指令为:
./make-distribution.sh --name "hadoop2.7.3-without-hive" --tgz -Dhadoop.version=2.7. -Dscala-2.11 -Phadoop-2.7 -Pyarn -DskipTests clean package
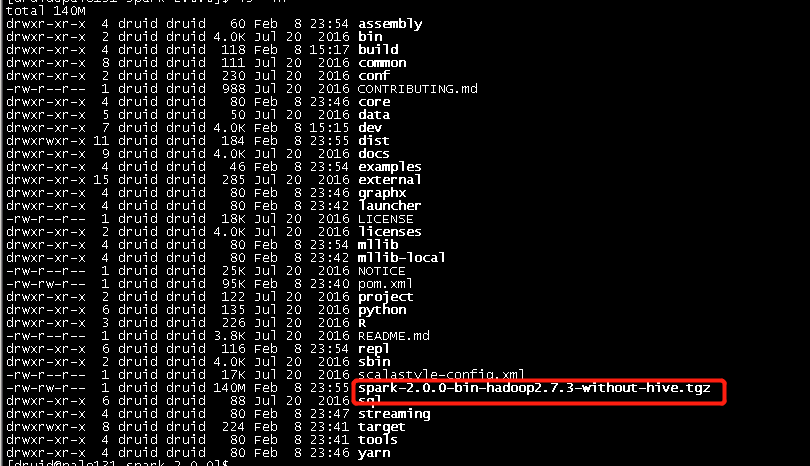
用编译出来的包来安装。
2) 删除预编译包中hive的jar包,具体操作为:
cd $SPARK_HOME/jars
rm -f hive-*
rm -rf spark-hive_*
#删除下面6个文件
# hive-beeline-1.2..spark2.jar
# hive-cli-1.2..spark2.jar
# hive-exec-1.2..spark2.jar
# hive-jdbc-1.2..spark2.jar
# hive-metastore-1.2..spark2.jar
# spark-hive_2.-2.0..jar
# spark-hive-thriftserver_2.-2.0..jar
注意:每台机器都要做.
13.2 如果出现类似下面的错误
Exception in thread "main" java.lang.NoClassDefFoundError: scala/collection/Iterable
at org.apache.hadoop.hive.ql.optimizer.spark.SetSparkReducerParallelism.getSparkMemoryAndCores(SetSparkReducerParallelism.java:)
at org.apache.hadoop.hive.ql.optimizer.spark.SetSparkReducerParallelism.process(SetSparkReducerParallelism.java:)
at org.apache.hadoop.hive.ql.lib.DefaultRuleDispatcher.dispatch(DefaultRuleDispatcher.java:)
at org.apache.hadoop.hive.ql.lib.DefaultGraphWalker.dispatchAndReturn(DefaultGraphWalker.java:)
at org.apache.hadoop.hive.ql.lib.DefaultGraphWalker.dispatch(DefaultGraphWalker.java:)
at org.apache.hadoop.hive.ql.lib.PreOrderWalker.walk(PreOrderWalker.java:)
at org.apache.hadoop.hive.ql.lib.PreOrderWalker.walk(PreOrderWalker.java:)
at org.apache.hadoop.hive.ql.lib.PreOrderWalker.walk(PreOrderWalker.java:)
at org.apache.hadoop.hive.ql.lib.PreOrderWalker.walk(PreOrderWalker.java:)
at org.apache.hadoop.hive.ql.lib.DefaultGraphWalker.startWalking(DefaultGraphWalker.java:)
at org.apache.hadoop.hive.ql.parse.spark.SparkCompiler.runSetReducerParallelism(SparkCompiler.java:)
at org.apache.hadoop.hive.ql.parse.spark.SparkCompiler.optimizeOperatorPlan(SparkCompiler.java:)
at org.apache.hadoop.hive.ql.parse.TaskCompiler.compile(TaskCompiler.java:)
at org.apache.hadoop.hive.ql.parse.SemanticAnalyzer.analyzeInternal(SemanticAnalyzer.java:)
at org.apache.hadoop.hive.ql.parse.CalcitePlanner.analyzeInternal(CalcitePlanner.java:)
at org.apache.hadoop.hive.ql.parse.BaseSemanticAnalyzer.analyze(BaseSemanticAnalyzer.java:)
at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:)
at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:)
at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:)
at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:)
at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.hadoop.util.RunJar.run(RunJar.java:)
at org.apache.hadoop.util.RunJar.main(RunJar.java:)
Caused by: java.lang.ClassNotFoundException: scala.collection.Iterable
at java.net.URLClassLoader.findClass(URLClassLoader.java:)
at java.lang.ClassLoader.loadClass(ClassLoader.java:)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:)
at java.lang.ClassLoader.loadClass(ClassLoader.java:)
这是因为hive无法加载spark的jar包,解决办法为:
$HIVE_HOME/bin/hive
在执行hive之前添加下面的语句,把spark的jar包添加到hive的class path中
SPARK_HOME=/home/workspace/software/spark-2.0.
for f in ${SPARK_HOME}/jars/*.jar; do
CLASSPATH=${CLASSPATH}:$f;
done
本人添加的位置为:

或者直接把$SPARK_HOME/jars/spark*复制到$HIVE_HOME/lib下,
cp $SPARK_HOME/jars/spark* $HIVE_HOME/lib
个人感觉修改hive启动脚本更好一些。
14 参考资料
https://www.jianshu.com/p/a7f75b868568
spark 2.0.0集群安装与hive on spark配置的更多相关文章
- 菜鸟玩云计算之十九:Hadoop 2.5.0 HA 集群安装第2章
菜鸟玩云计算之十九:Hadoop 2.5.0 HA 集群安装第2章 cheungmine, 2014-10-26 在上一章中,我们准备好了计算机和软件.本章开始部署hadoop 高可用集群. 2 部署 ...
- 菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章
菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章 cheungmine, 2014-10-25 0 引言 在生产环境上安装Hadoop高可用集群一直是一个需要极度耐心和体力的细致工作 ...
- Kafka0.10.2.0分布式集群安装
一.依赖文件安装 1.1 JDK 参见博文:http://www.cnblogs.com/liugh/p/6623530.html 1.2 Scala 参见博文:http://www.cnblogs. ...
- hadoop 2.2.0集群安装详细步骤(简单配置,无HA)
安装环境操作系统:CentOS 6.5 i586(32位)java环境:JDK 1.7.0.51hadoop版本:社区版本2.2.0,hadoop-2.2.0.tar.gz 安装准备设置集群的host ...
- Redis Cluster 4.0.9 集群安装搭建
Redis Cluster 4.0.9集群搭建步骤:yum install -y gcc g++ gcc-c++ make openssl cd redis-4.0.9 make mkdir -p / ...
- Spark On YARN 分布式集群安装
一.导读 最近开始学习大数据分析,说到大数据分析,就必须提到Hadoop与Spark.要研究大数据分析,就必须安装这两个软件,特此记录一下安装过程.Hadoop使用V2版本,Hadoop有单机.伪分布 ...
- Apache Hadoop集群安装(NameNode HA + SPARK + 机架感知)
1.主机规划 序号 主机名 IP地址 角色 1 nn-1 192.168.9.21 NameNode.mr-jobhistory.zookeeper.JournalNode 2 nn-2 ).HA的集 ...
- Spark2.1.0分布式集群安装
一.依赖文件安装 1.1 JDK 参见博文:http://www.cnblogs.com/liugh/p/6623530.html 1.2 Hadoop 参见博文:http://www.cnblogs ...
- redis4.0.1集群安装部署
安装环境 序号 项目 值 1 OS版本 Red Hat Enterprise Linux Server release 7.1 (Maipo) 2 内核版本 3.10.0-229.el7.x86_64 ...
随机推荐
- java 中,for、for-each、iterator 区别
java 中,for.for-each.iterator 区别: 无论是在数组中还是在集合中,for-Each加强型for循环都是它们各自的普通for循环的一种"简写方式",即两者 ...
- ssh证书免认证登录
思路: 客户端私钥存放于客户端,/root/.ssh/id_rsa 将客户端公钥存放于要远程控制服务器上:将客户在公钥id_rsa.pub内容追加到 /root/.ssh/authorized_key ...
- Redis 基础命令
1. 进入redis目录,启动redis cd src ./redis-server 2. 进入redis目录,启动redis客户端 cd src ./redis-cli 3. info命令 4. ...
- mybatis异常:Caused by: java.lang.IllegalArgumentException: Result Maps collection already contains value for。。。。。。
框架环境:ssm 昨天下午技术经理更新了下表结构,多加了一个字段. 之后我根据新的mapper.xml文件写了增删改查的操作.重新启动之后不是这个错就是那个错,一大堆错误,头疼. 像类似于NoSuch ...
- ML平台_饿了么实践
(转载至:https://zhuanlan.zhihu.com/p/28592540) 说到机器学习.大数据,大家听到的是 Hadoop 和 Spark 居多,它们跟 TensorFlow 是一个什么 ...
- 关于bool 与boolean
关于bool的介绍,整理如下: bool 关键字是 System.Boolean 的别名.它用于声明变量来存储布尔值 true 和 false. 如果需要一个也可以有 null 值的布尔型变量,请使用 ...
- inf 启动
How to install an INF file using Delphi If you need to install an "inf" file using Delphi, ...
- C#实现根据日期计算星期
/// <summary> /// 根据日期返回 星期(返回结果为英文) /// </summary> /// <param name="date"& ...
- dom响应事件
DOMsubtreeModified.DOMNodeInserted.DOMNodeRemoved.DOMAttrModified.DOMCharacterDataModified 当底层DOM结构发 ...
- 黄聪:如何高效率存储微信中的 access_token
众所周知,在微信开发中,获取access_token 的接口每天的调用次数是有限制的,2000次应该是. 不过其实这些完全够用了,除非你不小心写了个循环,在1秒中内用完了. 每个access_toke ...