Rehash死锁的问题
为什么都说HashMap是线程不安全的呢?它在多线程环境下,又会发生什么情况呢?
resize死循环
我们都知道HashMap的初始容量是16,一般来说,当插入数据时,都会检查容量有没有超过设定的thredhold,如果超过容量,就需要增大Hash表的尺寸,但是这样一来,整个Hash表内的元素都需要被重新计算一次。这叫rehash,成本相当的大。
void resize(int newCapacity) {Entry[] oldTable = table;int oldCapacity = oldTable.length;if (oldCapacity == MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return;}Entry[] newTable = new Entry[newCapacity];transfer(newTable, initHashSeedAsNeeded(newCapacity));table = newTable;threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;for (Entry<K,V> e : table) {while(null != e) {Entry<K,V> next = e.next;if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);e.next = newTable[i];newTable[i] = e;e = next;}}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
大概看一下transfer:
对索引数组中的元素遍历
对链表上的每一个节点遍历:用 next 取得要转移那个元素的下一个,将 e 转移到新 Hash 表的头部,使用头插法插入节点。
循环2,直到链表节点全部转移
循环1,直到所有索引数组全部转移
经过这几步,我们会发现转移的时候是逆序的。假如转移前链表顺序是1->2->3,那么转移后就会变成3->2->1。这时候就有点头绪了,死锁问题不就是因为1->2的同时2->1造成的吗?所以,HashMap 的死锁问题就出在这个transfer()函数上。
单线程 rehash 详细演示
单线程情况下,rehash 不会出现任何问题:
假设hash算法就是最简单的 key mod table.length(即数组的长度)。
最上面的是old hash 表,其中的Hash表的 size = 2, 所以 key = 3, 7, 5,在 mod 2以后碰撞发生在 table[1]
接下来的三个步骤是 Hash表 resize 到4,并将所有的
多线程 rehash 详细演示
为了思路更清晰,我们只将关键代码展示出来:
while(null != e) {Entry<K,V> next = e.next;e.next = newTable[i];newTable[i] = e;e = next;}
- 1
- 2
- 3
- 4
- 5
- 6
1. Entry<K,V> next = e.next;——因为是单链表,如果要转移头指针,一定要保存下一个结点,不然转移后链表就丢了2. e.next = newTable[i];——e 要插入到链表的头部,所以要先用 e.next 指向新的 Hash 表第一个元素(为什么不加到新链表最后?因为复杂度是 O(N))3. newTable[i] = e;——现在新 Hash 表的头指针仍然指向 e 没转移前的第一个元素,所以需要将新 Hash 表的头指针指向 e4. e = next——转移 e 的下一个结点
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
假设这里有两个线程同时执行了put()操作,并进入了transfer()环节
while(null != e) {Entry<K,V> next = e.next; //线程1执行到这里被调度挂起了e.next = newTable[i];newTable[i] = e;e = next;}
- 1
- 2
- 3
- 4
- 5
- 6
那么现在的状态为:
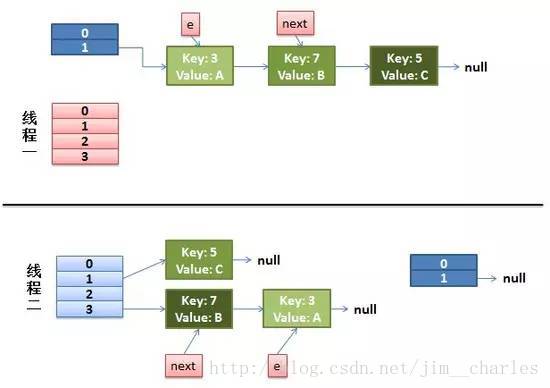
从上面的图我们可以看到,因为线程1的 e 指向了 key(3),而 next 指向了 key(7),在线程2 rehash 后,就指向了线程2 rehash 后的链表。
然后线程1被唤醒了:
执行e.next = newTable[i],于是 key(3)的 next 指向了线程1的新 Hash 表,因为新 Hash 表为空,所以e.next = null,
执行newTable[i] = e,所以线程1的新 Hash 表第一个元素指向了线程2新 Hash 表的 key(3)。好了,e 处理完毕。
执行e = next,将 e 指向 next,所以新的 e 是 key(7)
然后该执行 key(3)的 next 节点 key(7)了:
1. 现在的 e 节点是 key(7),首先执行Entry<K,V> next = e.next,那么 next 就是 key(3)了2. 执行e.next = newTable[i],于是key(7) 的 next 就成了 key(3)3. 执行newTable[i] = e,那么线程1的新 Hash 表第一个元素变成了 key(7)4. 执行e = next,将 e 指向 next,所以新的 e 是 key(3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这时候的状态图为:
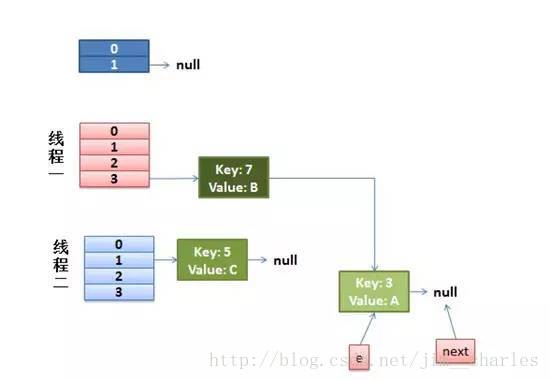
然后又该执行 key(7)的 next 节点 key(3)了:
1. 现在的 e 节点是 key(3),首先执行Entry<K,V> next = e.next,那么 next 就是 null2. 执行e.next = newTable[i],于是key(3) 的 next 就成了 key(7)3. 执行newTable[i] = e,那么线程1的新 Hash 表第一个元素变成了 key(3)4. 执行e = next,将 e 指向 next,所以新的 e 是 key(7)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这时候的状态如图所示:
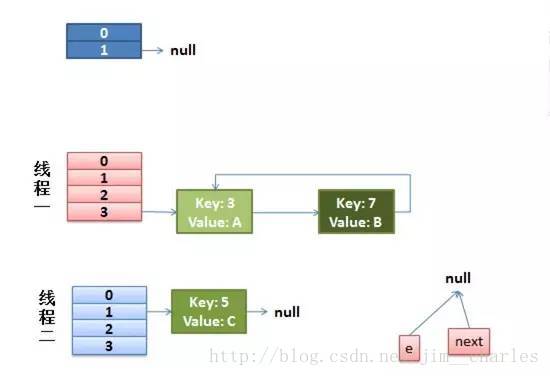
很明显,环形链表出现了!!当然,现在还没有事情,因为下一个节点是 null,所以transfer()就完成了,等put()的其余过程搞定后,HashMap 的底层实现就是线程1的新 Hash 表了。
fail-fast
如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast策略。
这个异常意在提醒开发者及早意识到线程安全问题,具体原因请查看ConcurrentModificationException的原因以及解决措施
顺便再记录一个HashMap的问题:
为什么String, Interger这样的wrapper类适合作为键? String, Interger这样的wrapper类作为HashMap的键是再适合不过了,而且String最为常用。因为String是不可变的,也是final的,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不可变性还有其他的优点如线程安全。如果你可以仅仅通过将某个field声明成final就能保证hashCode是不变的,那么请这么做吧。因为获取对象的时候要用到equals()和hashCode()方法,那么键对象正确的重写这两个方法是非常重要的。如果两个不相等的对象返回不同的hashcode的话,那么碰撞的几率就会小些,这样就能提高HashMap的性能。
Rehash死锁的问题的更多相关文章
- Java基础:HashMap假死锁问题的测试、分析和总结
前言 前两天在公司的内部博客看到一个同事分享的线上服务挂掉CPU100%的文章,让我联想到HashMap在不恰当使用情况下的死循环问题,这里做个整理和总结,也顺便复习下HashMap. 直接上测试代码 ...
- HashMap之原理及死锁
一.HashMap原理 1.HashMap的本质就是数组和链表.table是一个entry数组,每一个数组元素保存一个Entry节点,而Entry节点内部又连接着同样key的下一个Entry节点,就构 ...
- 什么是hashMap,初始长度,高并发死锁,java8 hashMap做的性能提升
问题1:HashM安排的初始长度,为什么? 初始长度是 16,每次扩展或者是手动初始化,长度必须是 2的幂. 因为: index = HashCode(Key) & (length - 1), ...
- java集合之hashMap,初始长度,高并发死锁,java8 hashMap做的性能提升
众所周知,HashMap是一个用于存储Key-Value键值对的集合,每一个键值对也叫做Entry.这些个键值对(Entry)分散存储在一个数组当中,这个数组就是HashMap的主干. HashMap ...
- JDK1.7HashMap死锁
JDK1.7HashMap多线程问题 Java技术交流群:737698533 在看之前可以先看看JDK1.7的Hashmap的源码 HashMap在多线程情况下是不安全的,一个是数据的准确性问题,一个 ...
- 查看w3wp进程占用的内存及.NET内存泄露,死锁分析
一 基础知识 在分析之前,先上一张图: 从上面可以看到,这个w3wp进程占用了376M内存,启动了54个线程. 在使用windbg查看之前,看到的进程含有 *32 字样,意思是在64位机器上已32位方 ...
- Android 死锁和重入锁
死锁的定义: 1.一般的死锁 一般的死锁是指多个线程的执行必须同时拥有多个资源,由于不同的线程需要的资源被不同的线程占用,最终导致僵持的状态,这就是一般死锁的定义. package com.cxt.t ...
- mysql 行级锁的使用以及死锁的预防
一.前言 mysql的InnoDB,支持事务和行级锁,可以使用行锁来处理用户提现等业务.使用mysql锁的时候有时候会出现死锁,要做好死锁的预防. 二.MySQL行级锁 行级锁又分共享锁和排他锁. 共 ...
- MySql 死锁时的一种解决办法
转自:http://blog.csdn.net/mchdba/article/details/38313881 之前也遇到一次,今天又遇到了这个问题,所以这次必须解决,网上找到这篇文章帮了大忙,方便以 ...
随机推荐
- 【JVM】jvm虚拟机参数解析
转载:https://blog.csdn.net/see__you__again/article/details/51998038不管是YGC还是Full GC,GC过程中都会对导致程序运行中中断,正 ...
- mysql再探
select子句及其顺序 select from where group by having order by limit 创建表 create table student(id int not nu ...
- MySQL--查看内存信息
常见查看内存信息命令 ## 使用free -m命令查看 free -m ## 使用cat /proc/meminfo 查看 cat /proc/meminfo ## 使用dmidecode命令查看 d ...
- 利用反射C#获取事件列表
在程序设计中有时候需要动态订阅客户自己的事件,调用完成后又要删除以前订阅的事件.因为如果不删除,有时会造成事件是会重复订阅,导致程序运行异常.一个办法是用反射来控件事件列表.清空方法代码如下: /// ...
- xmtech-3516默认环境变量
xmtech # print bootcmd=setenv setargs setenv bootargs ${bootargs};run setargs;sf probe ;sf read ;squ ...
- 自动化部署--shell脚本--1
传统部署方式1.纯手工scp2.纯手工登录git pull .svn update3.纯手工xftp往上拉4.开发给打一个压缩包,rz上去.解压 传统部署缺点:1.全程运维参与,占用大量时间2.上线速 ...
- MD5 SHA1 SHA256 SHA512 SHA1WithRSA 的区别
MD5 SHA1 SHA256 SHA512 这4种本质都是摘要函数,不通在于长度 MD5 是 128 位,SHA1 是 160 位 ,SHA256 是 256 位,SHA512 是512 位. ...
- centos7使用163 yum源
一般是下载 .repo 源即可,但有时候我们需要安装一些额外的包,就需要下载 Extra Packages for Enterprise Linux (EPEL) 源, 比如我们需要用 yum 安装 ...
- chrome自定义ua(批处理文件方式)
新建bat文件,输入如下代码: @echo off start chrome.exe --user-agent="你自定义的ua字符串" EXIT 保存后运行bat文件. 这个时候 ...
- OpenCV几种访问cv::Mat数据的方法
一般来说,如果是遍历数据的话用指针ptr比用at要快.特别是在debug版本下.因为debug中,OpenCV会对at中的坐标检查是否有溢出,这是非常耗时的. 代码如下 #include <op ...