R实战 第八篇:重塑数据(reshape2)
数据重塑通常使用reshape2包,reshape2包用于实现对宽数据及长数据之间的相互转换,由于reshape2包不在R的默认安装包列表中,在第一次使用之前,需要安装和引用:
install.packages("reshape2")
library(reshape2)
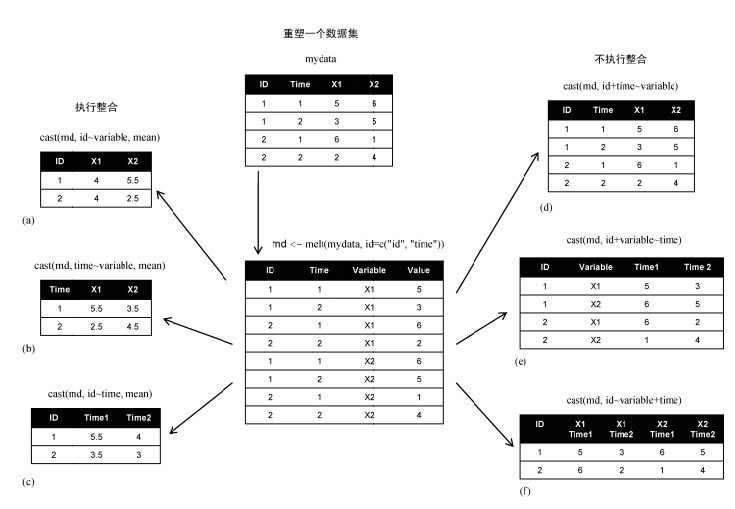
重塑数据,首先把宽数据融合(melt),以使每一行都只表示一个变量,然后把数据重塑(cast)为想要的任何形状。在重塑过程中,可以使用任何函数对数据进行整合,也可以把长格式转换为宽格式,这种操作类似于Excel的透视和逆透视。
一,认识宽数据
在同一行,标识变量(一列或多列)能够唯一标识两个或多个变量的值,这种数据显示叫做数据的宽格式,也叫做宽数据:

创建示例数据,ID和Time的组合是唯一的,X1和X2是该行的观测变量值,
> ID <- c(1,1,2,2)
> Time <- c(1,2,1,2)
> X1 <- c(5,3,6,2)
> X2 <-c(6,5,1,4)
> mydata <- data.frame(ID,Time,X1,X2)
如下所示宽格式的数据,ID和Time的组合是唯一的,同一行有两个变量X1和X2,通过ID和Time能够唯一确定变量X1和X2的值:
ID Time X1 X2
二,融合数据
数据的融合是指把数据集重塑为特定的格式,使得每个观测变量独占一行,每行都有唯一确定每个观测变量所需要的标识变量。融合之后的数据,称作长格式,也叫作长数据。
原始数据中,主键列唯一确定variable1和variable2的值,在融合之后,如下图所示,主键列和variable列(变量名)唯一确定value列的值。

在R语言中,使用melt()函数来融合数据:
melt(data,id.vars,measure.vars,variable.name='variable',...,na.rm=FALSE,value.name='value',factorAsStrings=TRUE)
参数注释:
- data:融合的数据框
- id.vars:由标识变量构成的向量,用于标识观测的变量
- measure.vars :由观测变量构成的向量
- variable.name:用于保存原始变量名的变量的名称
- value.name:用于保存原始值的名称
示例,标识变量是ID和Time,X1和X2作为观测变量:
md <- melt(mydata,id=c("ID","Time"),measure=c("X1","X2"))
数据融合之后,变成长数据,长数据的特征是 ID列(多列或单列)+ 变量名 唯一确定变量的值,并且每一行只能确定一个变量的值。
ID Time variable value
X1
X1
X1
X1
X2
X2
X2
X2
注意:必须指定唯一确定每个观测所需的变量(ID和Time),而表示观测变量名的变量(X1和X2)由程序自动创建,从结果中可以看出,函数自动创建了两个变量:variable和value,这两个变量名称是默认的,这可以在melt()函数中,通过参数 variable.name="new_variable_name"和 value.name="new_value_name"来自定义。
md <- melt(mydata,id=c("ID","Time"),measure=c("X1","X2"),variable.name = "MeasuredVariable",value.name = "IntValue")
三,重塑数据
dcast()函数用于读取已融合的数据框(d是指data frame),并使用formula和用于整合数据的函数把数据集重塑成任意形状:
dcast(data, formula, fun.aggregate = NULL, ..., margins = NULL,
subset = NULL, fill = NULL, drop = TRUE, value.var = guess_value(data))
参数注释:
- data:已融合的数据框
- formula:用于指定输出的结果集格式
- fun.aggregate:用于指定聚合函数,对已聚合的数据执行聚合运算
- margins:相当于透视表中的行总计和列总计
- subset:选取满足一些特定值的数据,相当于Excel透视表的筛选。例如, subset =.(variable ==“length”)
- fill:用于填充结构缺失的值,默认为将fun.aggregate应用于0长度向量的值
- value:value列的名称
参数formula的格式是:
rowvar1 + rowvar2 +... ~ colvar1 + colvar2 +...
在该公式中,rowvar 定义了保留的变量名,以唯一确定各行的内容;colvar定义了需要重塑的变量名,以确定各列的值。重塑的含义是:按照rowvar,展开colvar,对value进行聚合运算(当fun.aggregate为聚合函数时)。
1,展开colvar
展开colvar的过程,实际上是把列值转换为列名称的过程,这种展开操作是由formula参数决定的。
重塑操作中的特例是数据融合的逆操作,把数据的长格式转化为数据的宽格式,即,把已融合的数据转换为原始数据格式,对于这种操作,formula参数的格式是固定的:标识变量~variable。
> dcast(md,ID+Time~variable)
ID Time X1 X2
1 1 1 5 6
2 1 2 3 5
3 2 1 6 1
4 2 2 2 4
2,对观测变量进行聚合运算
按照ID,计算观测变量的平均值:
> dcast(md,ID~variable,mean)
ID X1 X2
1 1 4 5.5
2 2 4 2.5
这种操作,类似于分组聚合:按照ID进行分组,分别计算变量X1和X2的聚合值。
3,添加总计列
计算按照ID分组的X1和X2的均值,并对重塑的结果按照ID计算各列均值,按照X1和X2计算各行的均值。
> dcast(md,ID~variable,mean,margins = c("ID","variable"))
ID X1 X2 (all)
5.5 4.75
2.5 3.25
(all) 4.0 4.00
计算的过程是:
按照ID计算各列的均值: X1的值是(5.5+2.5)/2=4
按照变量计算各行的均值:第一行的均值是 (4+5.5)/2=4.75
示例图:
参考文档:
R实战 第八篇:重塑数据(reshape2)的更多相关文章
- R实战 第六篇:数据变换(aggregate+dplyr)
数据分析的工作,80%的时间耗费在处理数据上,而数据处理的主要过程可以分为:分离-操作-结合(Split-Apply-Combine),也就是说,首先,把数据根据特定的字段分组,每个分组都是独立的:然 ...
- R实战 第三篇:数据处理(基础)
数据结构用于存储数据,不同的数据结构对应不同的操作方法,对应不同的分析目的,应选择合适的数据结构.在处理数据时,为了便于检查数据对象,可以通过函数attributes(x)来查看数据对象的属性,str ...
- Spring Cloud实战 | 最八篇:Spring Cloud +Spring Security OAuth2+ Axios前后端分离模式下无感刷新实现JWT续期
一. 前言 记得上一篇Spring Cloud的文章关于如何使JWT失效进行了理论结合代码实践的说明,想当然的以为那篇会是基于Spring Cloud统一认证架构系列的最终篇.但关于JWT另外还有一个 ...
- R实战 第三篇:数据处理
在实际分析数据之前,必须对数据进行清理和转化,使数据符合相应的格式,提高数据的质量.数据处理通常包括增加新的变量.处理缺失值.类型转换.数据排序.数据集的合并和获取子集等. 一,增加新的变量 通常需要 ...
- R实战 第五篇:绘图(ggplot2)
ggplot2包实现了基于语法的.连贯一致的创建图形的系统,由于ggplot2是基于语法创建图形的,这意味着,它由多个小组件构成,通过底层组件可以构造前所未有的图形.ggplot2可以把绘图拆分成多个 ...
- R实战 第七篇:绘图文本表
文本表是显示数据的重要图形,一个文本表按照区域划分为:列标题,行标题,数据区,美学特征有:前景样式.背景央视.字体.网格线等. 一,使用ggtexttable绘图文本表 载入ggpubr包,可以使用g ...
- R实战 第十一篇:处理缺失值
在真实的世界中,缺失数据是经常出现的,并可能对分析的结果造成影响.在R中,经常使用VIM(Visualization and Imputation of Missing values)包来对缺失值进行 ...
- R绘图 第八篇:绘制饼图(ggplot2)
geom_bar()函数不仅可以绘制条形图,还能绘制饼图,跟绘制条形图的区别是坐标系不同,绘制饼图使用的坐标系polar,并且设置theta="y": coord_polar(th ...
- R实战 第十篇:列联表和频数表
列联表是观测数据按两个或更多属性(定性变量)分类时所列出的频数分布表,它是由两个以上的变量进行交叉分类的频数分布表.交互分类的目的是将两变量分组,然后比较各组的分布状况,以寻找变量间的关系. 按两个变 ...
随机推荐
- 下载 VM 模板
使用门户或 PowerShell 在 Azure 中创建 VM 时,系统会自动创建一个 Resource Manager 模板. 可以使用此模板快速复制部署. 该模板包含有关资源组中所有资源的信息. ...
- 红帽7配置samba文件共享服务
samba软件主要功能是为客户机提供共享使用的文件夹. 使用的协议是SMB(TCP 139).CIFS(TCP445). 所需的软件包:samba 系统服务:smb 1.安装samba服务 ~]#yu ...
- [MySQL复制] SQL_ERROR 1032解决办法(non-gtid env)
一.缘由: 在主主同步的测试环境,由于业务侧没有遵循同一时间只写一个点的原则,造成A库上删除了一条数据,B库上在同时更新这条数据. 由于异步和网络延时,B的更新event先到达A端执行,造成A端找不到 ...
- MySQL客户端连接方式
MySQL连接方式MySQL除了最常见的TCP连接方式外,还提供SOCKET(LINUX默认连接方式).PIPE和SHARED MEMORY连接方式.各连接方式的服务器.客户端启动选项,及连接默认值见 ...
- Python初学者第三天 运算符、while循环
3day Python基础语法 1.运算符:算数运算符.比较运算符.赋值运算符.逻辑运算符 A.算数运算符:a=10,b=3 + 加 a+b - 减 a-b * 乘 a*b / 除 a/b ...
- HTTP学习---TCP三次握手和四次挥手
IP协议 首先我们看 IP(Internet Protocol)协议.IP 协议提供了主机和主机间的通信. 为了完成不同主机的通信,我们需要某种方式来唯一标识一台主机,这个标识,就是著名的IP地址.通 ...
- MongoDB之 复制集搭建
MongoDB复制集搭建步骤,本次搭建使用3台机器,一个是主节点,一个是从节点,一个是仲裁者. 主节点负责与前台客户端进行数据读写交互,从节点只负责容灾,构建高可用,冗余备份.仲裁者的作用是当主节点宕 ...
- Docker容器学习与分享04
Docker容器的基本操作(2) 基于docker分享03的centos容器,接着学习docker容器的基本操作. docker分享03中创建了一个centos镜像,如果想要查看容器的具体信息就要使用 ...
- 用JS制作《飞机大作战》游戏_第4讲(创建敌方飞机、敌方飞机发射子弹、玩家子弹击中敌方小飞机,小飞机死亡)-陈远波
一.创建敌方飞机 1.思考创建思路: 创建敌方飞机思路与创建玩家飞机思路一样: (1)思考敌方飞机具备什么属性: 敌方飞机的图片.坐标.飞行速度.状态(是否被击中) 设置小飞机被击中时消失时间.飞机可 ...
- CJOJ 【DP合集】最长上升序列2 — LIS2
题面 已知一个 1 ∼ N 的排列的最长上升子序列长度为 K ,求合法的排列个数. 好题(除了我想不出来我应该找不到缺点), 想一想最长上升子序列的二分做法, 接在序列后面或者替换. 所以对于每一个位 ...