nova-api源码分析(APP的创建)
目录结构如下:

上面介绍了nova-api发布所用到的一些lib库,有了上面的基础知识,再来分析nova-api的发布流程,就比较轻松了。nova-api可以提供多种api服务:ec2, osapi_compute, osapi_volume, metadata。可以通过配置项enabled_apis来设置启动哪些服务,默认情况下,四种服务都是启动的。从nova-api的可执行脚本中,可以看出每个nova-api服务都是通过nova.service.WSGIService来管理的:
class WSGIService(object): def __init__(self, name, loader=None):
self.name = name
self.manager = self._get_manager()
self.loader = loader or wsgi.Loader()
self.app = self.loader.load_app(name)
self.host = getattr(FLAGS, '%s_listen' % name, "0.0.0.0")
self.port = getattr(FLAGS, '%s_listen_port' % name, 0)
self.workers = getattr(FLAGS, '%s_workers' % name, None)
self.server = wsgi.Server(name, #这里通过eventlet来启动服务
self.app,
host=self.host,
port=self.port) def start(self):
if self.manager:
self.manager.init_host()
self.server.start()
.......
从上可知,WSGIService使用self.app = self.loader.load_app(name)来加载wsgi app,app加载完成后,使用nova.wsgi.Server来发布服务。Server首先用指定ip和port实例化一个监听socket,并使用wsgi.server以协程的方式来发布socket,并将监听到的http请求交给app处理。下面我们主要来分析处理HTTP请求的wsgi app是如何构建的,对于每一个请求,它是如何根据url和请求方法将请求分发到具体的具体函数处理的。
1、 composite:osapi_compute
上个语句self.loader.load_app(name)中的loader是nova.wsgi.Loader的实例。Loader.load_app(name)执行下面指令,使用deploy来加载wsgi app:
deploy.loadapp("config:%s" % self.config_path, name=name)
self.config_path为api-paste.ini文件路径,一般为/etc/nova/api-paste.ini。name为ec2, osapi_compute, osapi_volume, metadata之一,根据指定的name不同来加载不同的wsgi app。下面以name=“osapi_compute”时,加载提供openstack compute API服务的wsgi app作为具体分析。osapi_compute的配置如下
[composite:osapi_compute]
use = call:nova.api.openstack.urlmap:urlmap_factory
/: oscomputeversions
/v2: openstack_compute_api_v2
osapi_compute是调用urlmap_factory函数返回的一个nova.api.openstack.urlmap.URLMap实例,nova.api.openstack.urlmap.URLMap继承paste.urlmap.URLMap,它提供了wsgi调用接口,所以该实例为wsgi app。但是函数nova.api.openstack.urlmap.urlmap_factory与paste.urlmap.urlmap_factory定义完全一样,不过由于它们所在的module不同,使得它们所用的URLMap分别为与它处于同一module的URLMap。paste.urlmap.URLMap实现的功能很简单:根据配置将url映射到特定wsgi app,并根据url的长短作一个优先级排序,url较长的将优先进行匹配。所以/v2将先于/进行匹配。URLMap在调用下层的wsgi app前,会更新SCRIPT_NAME和PATH_INFO。nova.api.openstack.urlmap.URLMap继承了paste.urlmap.URLMap,并写了一堆代码,其实只是为了实现对请求类型的判断,并设置environ['nova.best_content_type']:如果url的后缀名为json(如/xxxx.json),那么environ['nova.best_content_type']=“application/json”。如果url没有后缀名,那么将通过HTTP headers的content_type字段中mimetype判断。否则默认environ['nova.best_content_type']=“application/json”。
2、composite:openstack_compute_api_v2
经上面配置加载的osapi_compute为一个URLMap实例,wsgi server接受的HTTP请求将直接交给该实例处理。它将url为'/v2'的请求将交给openstack_compute_api_v2,url为'/'的请求交给oscomputerversions处理(它直接返回系统版本号)。其它的url请求,则返回NotFound。下面继续分析openstack_compute_api_v2,其配置如下:
[composite:openstack_compute_api_v2]
use = call:nova.api.auth:pipeline_factory
noauth = faultwrap sizelimit noauth ratelimit osapi_compute_app_v2
keystone = faultwrap sizelimit authtoken keystonecontext ratelimit osapi_compute_app_v2
keystone_nolimit = faultwrap sizelimit authtoken keystonecontext osapi_compute_app_v2
openstack_compute_api_v2是调用nova.api.auth.pipeline_factory()返回的wsgi app。pipeline_factory()根据配置项auth_strategy来加载不同的filter和最终的osapi_compute_app_v2。filter的大概配置如下:
[filter:faultwrap]
paste.filter_factory = nova.api.openstack:FaultWrapper.factory
filter在nova中对应的是nova.wsgi.Middleware,它的定义如下:
class Middleware(Application): @classmethod
def factory(cls, global_config, **local_config):
def _factory(app):
return cls(app, **local_config)
return _factory
def __init__(self, application):
self.application = application
def process_request(self, req):
return None
def process_response(self, response):
return response
@webob.dec.wsgify(RequestClass=Request)
def __call__(self, req):
response = self.process_request(req)
if response:
return response
response = req.get_response(self.application)
return self.process_response(response)
Middleware初始化接收一个wsgi app,在调用wsgi app之前,执行process_request()对请求进行预处理,判断请求是否交给传入的wsgi app,还是直接返回,或者修改些req再给传入的wsgi app处理。wsgi app返回的response再交给process_response()处理。例如,对于进行验证的逻辑,可以放在process_request中,如果验证通过则继续交给app处理,否则返回“Authentication required”。不过查看nova所有Mddlerware的编写,似乎都不用这种定义好的结构,而是把处理逻辑都放到__call__中,这样导致__call__变得复杂,代码不够整洁。当auth_strategy=“keystone”时,openstack_compute_api_v2=FaultWrapper-> RequestBodySizeLimiter-> auth_token-> NovaKeystoneContext-> RateLimitingMiddleware-> osapi_compute_app_v2。所以HTTP请求需要经过五个Middleware的处理,才能到达osapi_compute_app_v2。这五个Middleware分别完成:
1)异常捕获,防止服务内部处理异常导致wsgi server挂掉;
2)限制HTTP请求body大小,对于太大的body,将直接返回BadRequest;
3)对请求keystone对header中token id进行验证;
4)利用headers初始化一个nova.context.RequestContext实例,并赋给req.environ['nova.context'];
5)限制用户的访问速度。
注意以上filter是正序调用,逆序返回。即正序处理请求,逆序处理结果!
3、app:osapi_compute_app_v2
当HTTP请求经过上面五个Middlerware处理后,最终交给osapi_compute_app_v2,它是怎么继续处理呢?它的配置如下:
[app:osapi_compute_app_v2]
paste.app_factory = nova.api.openstack.compute:APIRouter.factory
osapi_compute_app_v2是调用nova.api.openstack.compute.APIRouter.factory()返回的一个APIRouter实例。具体的请求会调用APIRouter的__call__函数。大致为,app加载主要是构造APIRouter,调用__init__函数,然后发散开去构造其他的Resource(或者Controller),走这一条线索;而请求的处理主要是调用APIRouter的__call__函数,然后匹配到相应的Controller,调用Controller的函数,走这一条线索。可以参考:
http://www.choudan.net/2013/07/30/OpenStack-API%E5%88%86%E6%9E%90(%E4%B8%80).html
先看看这部分的类关系,如下图所示:
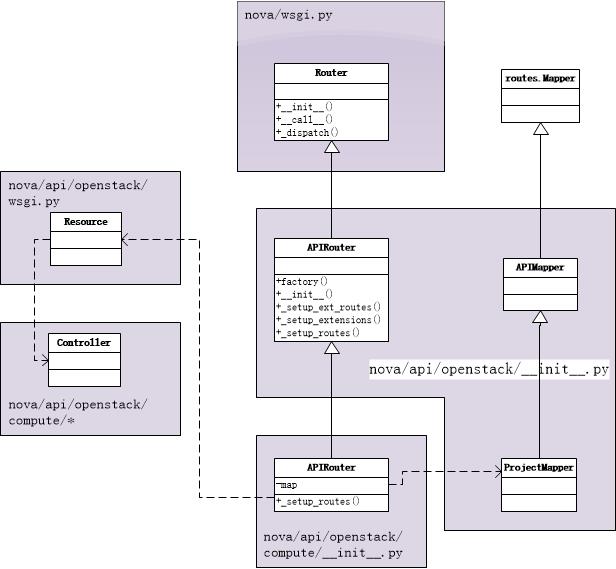
3.1 首先分析APIRouter的构造
nova/api/openstack/__init__.py
APIRouter类:
def __init__(self, ext_mgr=None, init_only=None):
if ext_mgr is None:
if self.ExtensionManager:
ext_mgr = self.ExtensionManager()
else:
raise Exception(_("Must specify an ExtensionManager class")) mapper = ProjectMapper()
self.resources = {}
self._setup_routes(mapper, ext_mgr, init_only)
self._setup_ext_routes(mapper, ext_mgr, init_only)
self._setup_extensions(ext_mgr)
super(APIRouter, self).__init__(mapper)
nova/wsgi.py
Router类:
def __init__(self, mapper):
self.map = mapper
self._router = routes.middleware.RoutesMiddleware(self._dispatch,
self.map)
APIRouter通过它的成员变量self.map(mapper)来建立和维护url与controller之间的映射,该mapper是nova.api.openstack.ProjectMapper的实例,它继承nova.api.openstack.APIMapper(routes.Mapper)。APIMapper将每个url的format限制为json或xml,对于其它扩展名的url将返回NotFound。ProjectMapper在每个请求url前面加上一个project_id,这样每个请求的url都需要带上用户所属的project id,所以一般请求的url为/v2/project_id/resources。
APIRouter通过self._setup_routes,self._setup_ext_routes,self._setup_extensions三个函数对mapper进行设置,下面会进行详细分析。其中使用到的ExtensionManager实例,该实例的构造可以参见:http://www.cnblogs.com/littlebugfish/p/4049853.html,此处不再详述,ExtensionManager中会有属性索引到扩展模块中对应的扩展类的实例。最后调用父类Router的__init__函数,其中self._router是routes.middleware.RoutesMiddleware的实例,使用self._dispatch和self.map来初始化的。
3.1.1 _setup_routes分析(核心Resource)
class APIRouter(nova.api.openstack.APIRouter):
ExtensionManager = extensions.ExtensionManager
def _setup_routes(self, mapper, ext_mgr):
self.resources['servers'] = servers.create_resource(ext_mgr)
mapper.resource("server", "servers",
controller=self.resources['servers'])
self.resources['ips'] = ips.create_resource()
mapper.resource("ip", "ips", controller=self.resources['ips'],
parent_resource=dict(member_name='server',
collection_name='servers'))
.......
APIRouter通过调用routes.Mapper.resource()函数建立RESTFUL API,也可以通过routes.Mapper.connect()来建立url与controller的映射。如上所示,servers相关请求的controller设为servers.create_resource(ext_mgr),该函数返回的是一个用nova.api.openstack.compute.servers.Controller()作为初始化参数的nova.api.openstack.wsgi.Resource实例,ips相关请求的controller设为由nova.api.openstack.ips.Controller()初始化的nova.api.openstack.wsgi.Resource实例。因为调用mapper.resource建立ips的url映射时,添加了一个parent_resource参数,使得请求ips相关api的url形式为/v2/project_id/servers/server_id/ips。对于limits、flavors、metadata等请求情况类似。
3.1.2 _setup_ext_routes分析(扩展Resource)
def _setup_ext_routes(self, mapper, ext_mgr, init_only):
for resource in ext_mgr.get_resources():
LOG.debug(_('Extended resource: %s'),
resource.collection) if init_only is not None and resource.collection not in init_only:
continue inherits = None
if resource.inherits:
inherits = self.resources.get(resource.inherits)
if not resource.controller:
resource.controller = inherits.controller
wsgi_resource = wsgi.Resource(resource.controller,
inherits=inherits)
self.resources[resource.collection] = wsgi_resource
kargs = dict(
controller=wsgi_resource,
collection=resource.collection_actions,
member=resource.member_actions) if resource.parent:
kargs['parent_resource'] = resource.parent mapper.resource(resource.collection, resource.collection, **kargs) if resource.custom_routes_fn:
resource.custom_routes_fn(mapper, wsgi_resource)
首先会调用ExtensionManager的get_resources函数,该函数会遍历调用注册在ExtensionManager中的扩展类实例的get_resources函数(即nova/api/openstack/compute/contrib中每个文件里面对应文件名的类的get_resources函数),从而获取一个nova.api.openstack.ResourceExtension对象列表。接着将这些ResourceExtension对象的controller封装成nova.api.openstack.wsgi.Resource对象,最后使用mapper.resource函数构建URL到这些Resource的映射。
3.1.3 _setup_extensions分析(扩展Controller)
def _setup_extensions(self, ext_mgr):
for extension in ext_mgr.get_controller_extensions():
collection = extension.collection
controller = extension.controller msg_format_dict = {'collection': collection,
'ext_name': extension.extension.name}
if collection not in self.resources:
LOG.warning(_('Extension %(ext_name)s: Cannot extend '
'resource %(collection)s: No such resource'),
msg_format_dict)
continue LOG.debug(_('Extension %(ext_name)s extending resource: '
'%(collection)s'),
msg_format_dict) resource = self.resources[collection]
resource.register_actions(controller)
resource.register_extensions(controller)
首先会调用ExtensionManager的get_controller_extensions函数,该函数会遍历调用注册在ExtensionManager中的扩展类实例的get_controller_extensions函数(即nova/api/openstack/compute/contrib中每个文件里面对应文件名的类的get_controller_extensions函数),从而获取一个nova.api.openstack. ControllerExtension对象列表。接着获取每个ControllerExtension中collection对应的nova.api.openstack.wsgi.Resource资源,向该资源注册ControllerExtension中controller的各个函数。
nova-api源码分析(APP的创建)的更多相关文章
- dubbo源码分析1-reference bean创建
dubbo源码分析1-reference bean创建 dubbo源码分析2-reference bean发起服务方法调用 dubbo源码分析3-service bean的创建与发布 dubbo源码分 ...
- Openstack Nova 源码分析 — 使用 VCDriver 创建 VMware Instance
目录 目录 前言 流程图 nova-compute vCenter 前言 在上一篇Openstack Nova 源码分析 - Create instances (nova-conductor阶段)中, ...
- requests库核心API源码分析
requests库是python爬虫使用频率最高的库,在网络请求中发挥着重要的作用,这边文章浅析requests的API源码. 该库文件结构如图: 提供的核心接口在__init__文件中,如下: fr ...
- MapReduce新版客户端API源码分析
使用MapReduce新版客户端API提交MapReduce Job需要使用 org.apache.hadoop.mapreduce.Job 类.JavaDoc给出以下使用范例. // Create ...
- 源码分析netty服务器创建过程vs java nio服务器创建
1.Java NIO服务端创建 首先,我们通过一个时序图来看下如何创建一个NIO服务端并启动监听,接收多个客户端的连接,进行消息的异步读写. 示例代码(参考文献[2]): import java.io ...
- dubbo源码分析3-service bean的创建与发布
dubbo源码分析1-reference bean创建 dubbo源码分析2-reference bean发起服务方法调用 dubbo源码分析3-service bean的创建与发布 dubbo源码分 ...
- Spring IOC 容器源码分析 - 创建原始 bean 对象
1. 简介 本篇文章是上一篇文章(创建单例 bean 的过程)的延续.在上一篇文章中,我们从战略层面上领略了doCreateBean方法的全过程.本篇文章,我们就从战术的层面上,详细分析doCreat ...
- Spring IOC 容器源码分析 - 创建单例 bean 的过程
1. 简介 在上一篇文章中,我比较详细的分析了获取 bean 的方法,也就是getBean(String)的实现逻辑.对于已实例化好的单例 bean,getBean(String) 方法并不会再一次去 ...
- Java源码分析之LinkedList
LinkedList与ArrayList正好相对,同样是List的实现类,都有增删改查等方法,但是实现方法跟后者有很大的区别. 先归纳一下LinkedList包含的API 1.构造函数: ①Linke ...
- dubbo源码分析6-telnet方式的管理实现
dubbo源码分析1-reference bean创建 dubbo源码分析2-reference bean发起服务方法调用 dubbo源码分析3-service bean的创建与发布 dubbo源码分 ...
随机推荐
- (幼儿园毕业)Javascript小学级随机生成四则运算
软件工程第二次结对作业四则运算自动生成器网页版 一.题目要求 本次作业要求两个人合作完成,驾驶员和导航员角色自定,鼓励大家在工作期间角色随时互换,这里会布置两个题目,请各组成员根据自己的爱好任选一题. ...
- 【原创】梵高油画用深度卷积神经网络迭代10万次是什么效果? A neural style of convolutional neural networks
作为一个脱离了低级趣味的码农,春节假期闲来无事,决定做一些有意思的事情打发时间,碰巧看到这篇论文: A neural style of convolutional neural networks,译作 ...
- Oracle实用地址
1.详细安装教程 https://jingyan.baidu.com/article/3c48dd34be2a32e10be35881.html
- OpenGL(3)-三角形
写在前面 从这节开始,会接触到很多基本概念,原书我也是读了很多遍,一遍一遍去理解其中的意思,以及他们之间的关系. 概念 顶点数组对象:VAO 顶点缓冲对象:VBO 索引缓冲对象:EBO|IBO Ope ...
- Mistakes I Made(as a developer)...大龄程序员的忠告...(部分转...)
在2006年,我开始了编程工作.当意识到来到了十年这个重要的时间关口时,我觉得有必要回顾一下这十年间所犯下的错误,做一做经验总结,并且给正在这个职业上奋斗的人们提出我的一些忠告.开发行业变化得很快,我 ...
- java算法面试题
前言:线上面试题与大家分享,并记录求职道路的酸甜苦辣,特此留念. 李雷和韩梅梅坐前后排,上课想说话怕被老师发现,所以改为传小纸条.为了不被老师发现他们纸条上说的是啥,他们约定了如下方法传递信息:将26 ...
- Apache Ignite 学习笔记(一): Ignite介绍、部署安装和REST/SQL客户端使用
Apache Ignite 介绍 Ignite是什么呢?先引用一段官网关于Ignite的描述: Ignite is memory-centric distributed database, cachi ...
- 2-Twelfth Scrum Meeting20151212
任务安排 成员 今日完成 明日任务 闫昊 获取视频播放的进度 获取视频播放进度 唐彬 解决handler可能引起的内存泄露问题 阅读IOS代码+阅读上届网络核心代码 史烨轩 下载service开发 ...
- 《Linux内核分析》第三周学习报告
<Linux内核分析>第三周学习报告 ——构造一个简单的Linux系统MenuOS 姓名:王玮怡 学号:201351 ...
- C++:派生类的构造函数和析构函数的调用顺序
一.派生类 在C++编程中,我们在编写一个基类的派生类时,大致可以分为四步: • 吸收基类的成员:不论是数据成员还是函数成员,派生类吸收除基类的构造函数和析构函数之外的全部成员. • 改造基类函数:在 ...