使用HtmlAgilityPack抓取Ethereum Tokens信息
使用HtmlAgilityPack抓取Ethereum Tokens信息
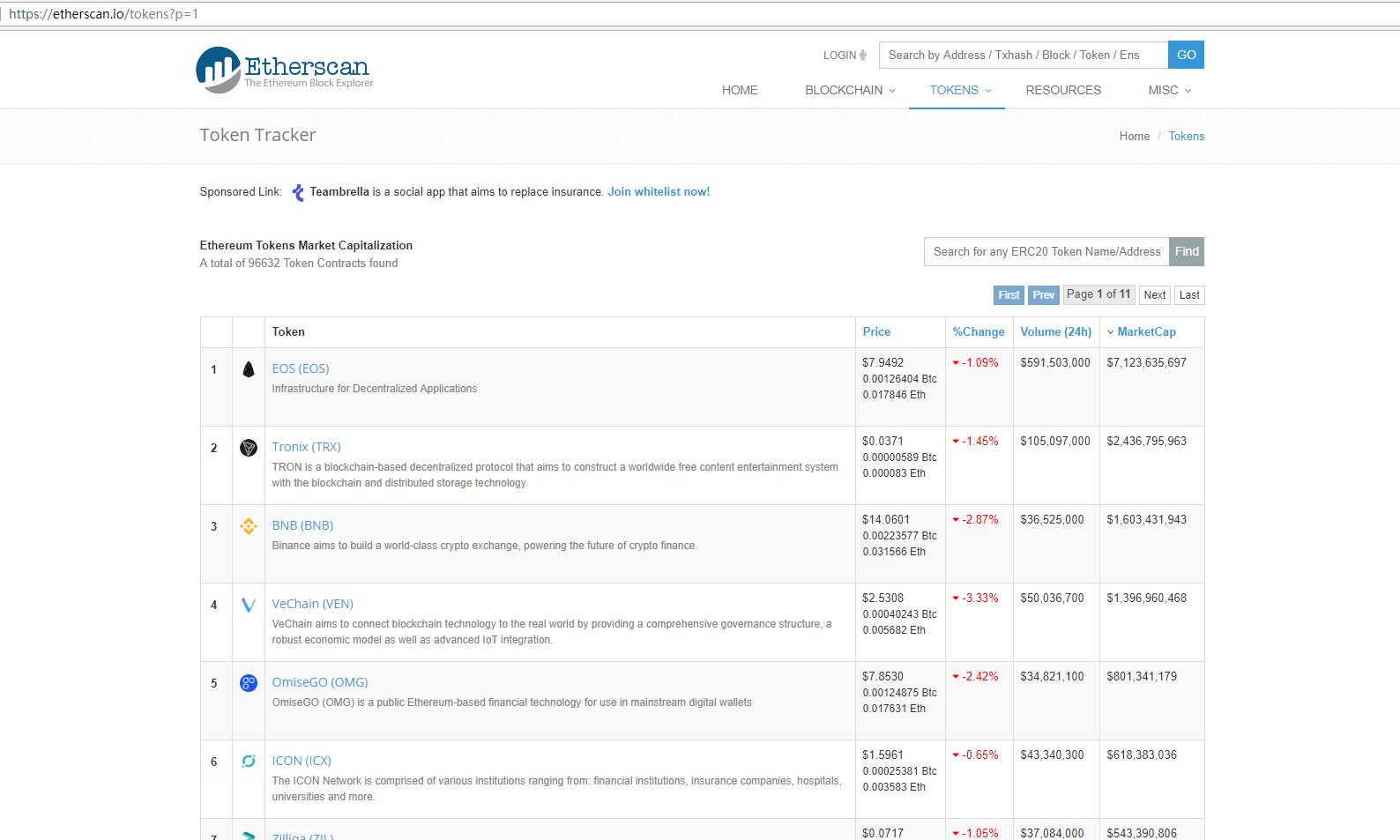
class Program
{
static void Main(string[] args)
{
try
{
for (int i = 1; i <= 11; i++)
{
string url = "https://etherscan.io/tokens?p="+i;
HtmlWeb webClient = new HtmlWeb();
HtmlDocument doc = webClient.Load(url); var tbody = doc.DocumentNode.SelectSingleNode("//*[@id='ContentPlaceHolder1_divresult']/table/tbody");
var trItems = tbody.SelectNodes("tr");
foreach (var tr in trItems)
{
try
{
var tdItems = tr.SelectNodes("td");
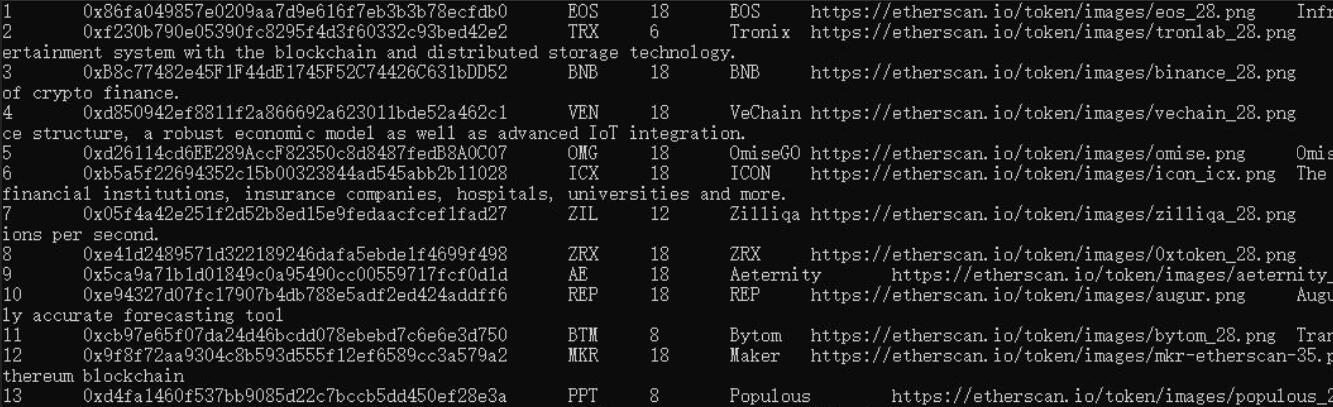
string id = tdItems[0].SelectSingleNode("b//span").InnerHtml.Replace(" ", "");
string contractAddress = tdItems[1].SelectSingleNode("a").Attributes["href"].Value.Replace("/token/", "");
string tokenLogo = "https://etherscan.io" + tdItems[1].SelectSingleNode("a/img").Attributes["src"].Value;
string temp = tdItems[2].SelectSingleNode("h5/a").InnerHtml;
string tokenName = temp.Substring(0, temp.IndexOf(" "));
string tokenSymbol = temp.Substring(temp.IndexOf("(") + 1, temp.IndexOf(")") - temp.IndexOf("(") - 1);
string tokenDescribe = tdItems[2].SelectSingleNode("small/font").InnerHtml; string tokenUrl = "https://etherscan.io/token/" + contractAddress;
HtmlWeb webtokenClient = new HtmlWeb();
HtmlDocument tokendoc = webtokenClient.Load(tokenUrl);
string tokenDecimal = tokendoc.DocumentNode.SelectSingleNode("/html[1]/body[1]/div[1]/div[5]/div[1]/div[2]/table[1]/tr[2]/td[2]").InnerHtml.Replace("\n", "");
Console.WriteLine($"{id}\t{contractAddress}\t{tokenSymbol}\t{tokenDecimal}\t{tokenName}\t{tokenLogo}\t{tokenDescribe}\t");
}
catch (Exception ex)
{ }
}
}
}
catch (Exception ex)
{
Console.WriteLine(ex);
}
Console.Read();
}
}
使用HtmlAgilityPack抓取Ethereum Tokens信息的更多相关文章
- HtmlAgilityPack 抓取页面的乱码处理
HtmlAgilityPack 抓取页面的乱码处理 用来解析 HTML 确实方便.不过直接读取网页时会出现乱码. 实际上,它是能正确读到有关字符集的信息,怎么会在输出时,没有取到正确内容. 因此,读两 ...
- Java广度优先爬虫示例(抓取复旦新闻信息)
一.使用的技术 这个爬虫是近半个月前学习爬虫技术的一个小例子,比较简单,怕时间久了会忘,这里简单总结一下.主要用到的外部Jar包有HttpClient4.3.4,HtmlParser2.1,使用的开发 ...
- Python爬虫实战---抓取图书馆借阅信息
Python爬虫实战---抓取图书馆借阅信息 原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息 前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约 ...
- 教您使用java爬虫gecco抓取JD全部商品信息
gecco爬虫 如果对gecco还没有了解可以参看一下gecco的github首页.gecco爬虫十分的简单易用,JD全部商品信息的抓取9个类就能搞定. JD网站的分析 要抓取JD网站的全部商品信息, ...
- scrapy抓取拉勾网职位信息(一)——scrapy初识及lagou爬虫项目建立
本次以scrapy抓取拉勾网职位信息作为scrapy学习的一个实战演练 python版本:3.7.1 框架:scrapy(pip直接安装可能会报错,如果是vc++环境不满足,建议直接安装一个visua ...
- 使用python抓取美团商家信息
抓取美团商家信息 import requests from bs4 import BeautifulSoup import json url = 'http://bj.meituan.com/' ur ...
- C# 使用HtmlAgilityPack抓取网页信息
前几天看到一篇博文:C# 爬虫 抓取小说 博主使用的是正则表达式获取小说的名字.目录以及内容. 下面使用HtmlAgilityPack来改写原博主的代码 在使用HtmlAgilityPack之前,可以 ...
- HtmlAgilityPack抓取搜房网数据简单示例
HtmlAgilityPack是一个开源的解析HTML元素的类库,最大的特点是可以通过XPath来解析HMTL,如果您以前用C#操作过XML,那么使用起HtmlAgilityPack也会得心应手.目前 ...
- 使用HtmlAgilityPack抓取网页数据
XPath 使用路径表达式来选取 XML 文档中的节点或节点集.节点是通过沿着路径 (path) 或者步 (steps) 来选取的. 下面列出了最有用的路径表达式: nodename:选取此节点的所有 ...
随机推荐
- AlexNet详解3
Reference. Krizhevsky A, Sutskever I, Hinton G E. ImageNet Classification with Deep Convolutional Ne ...
- 搭建一台deeplearning的服务器
在计算机时代的早期,一名极客的满足感很大程度上来源于能DIY一台机器.到了深度学习的时代,前面那句话仍然是对的. 缘起在2013年,MIT科技评论将深度学习列为当年十大科技突破之首.其原因在于,模型有 ...
- 实验5 IIC通讯与AD/接DA接口
1.利用单片机控制PCF8591的AD转换,控制AD0和AD1电位器,在数码光上显示DA转换的值. 2.利用单片机控制PCF8591的DA转换,让发光二极管D1由暗到亮变化,整个过程时间差不多2s左右 ...
- 工作随笔——elasticsearch 6.6.1安装(docker-compose方式)
docker-compose.yml: version: '2.2' services: es1: image: docker.elastic.co/elasticsearch/elasticsear ...
- python实现Telnet远程登陆到设备并执行命令
#encoding=utf-8 import telnetlib import time def do_telnet(Host, username, password, finish, command ...
- 调用notify()后,当前线程执行完synchronized块中的所有代码才会释放锁
package com.pinnet.test; public class Demo { public static void main(String[] args) { Demo demo = ne ...
- D02-R语言基础学习
R语言基础学习——D02 20190423内容纲要: 1.前言 2.向量操作 (1)常规操作 (2)不定长向量计算 (3)序列 (4)向量的删除与保留 3.列表详解 (1)列表的索引 (2)列表得元素 ...
- D3.js的基础部分之数组的处理 数组的排序和求值(v3版本)
操作数组 D3提供了将数组洗牌.合并等操作,使用起来是很方便的. d3.shuffle(array,[,lo[,ji]]) : //随机排列数组. d3.merge(arrays) : / ...
- Linux玩转redis从入门到放肆--1.缓存击穿
1. 缓存穿透在大多数互联网应用中,缓存的使用方式如下图所示: 1.当业务系统发起某一个查询请求时,首先判断缓存中是否有该数据:2.如果缓存中存在,则直接返回数据:3.如果缓存中不存在,则再查询数据库 ...
- sql server 2012 复制数据库向导出现TransferDatabasesUsingSMOTransfer()异常
Event Name: OnError Message: 传输数据时出错.有关详细信息,请参阅内部异常. StackTrace: 在 Microsoft.SqlServer.Management.Sm ...