jvm gc 调优 实战
非常不错的文章们 转自:
中文:http://blog.csdn.net/dragonassassin/article/details/51010947
http://josh-persistence.iteye.com/blog/2161848?utm_source=tuicool&utm_medium=referral
英文:超级超级超级无敌棒的Gc问题调优五部曲
https://www.cubrid.org/blog/understanding-java-garbage-collection
https://www.cubrid.org/blog/how-to-monitor-java-garbage-collection/
https://www.cubrid.org/blog/how-to-tune-java-garbage-collection
https://www.cubrid.org/blog/maxclients-in-apache-and-its-effect-on-tomcat-during-full-gc
https://www.cubrid.org/blog/the-principles-of-java-application-performance-tuning
前提概要:
JDK本身提供了很多方便的JVM性能调优监控工具,除了集成式的VisualVM和jConsole外,还有jps、jstack、jmap、jhat、jstat、hprof等小巧的工具,每一种工具都有其自身的特点,用户可以根据你需要检测的应用或者程序片段的状况,适当的选择相应的工具进行检测。接下来的两个专题分别会讲VisualVM的具体应用。
现实企业级Java开发中,有时候我们会碰到下面这些问题:
OutOfMemoryError,内存不足
内存泄露
线程死锁
锁争用(Lock Contention)
Java进程消耗CPU过高
......
这些问题在日常开发中可能被很多人忽视(比如有的人遇到上面的问题只是重启服务器或者调大内存,而不会深究问题根源),但能够理解并解决这些问题是Java程序员进阶的必备要求。
一、 jps(Java Virtual Machine Process Status Tool) : 基础工具
实际中这是最常用的命令,下面要介绍的小工具更多的都是先要使用jps查看出当前有哪些Java进程,获取该Java进程的id后再对该进程进行处理。
jps主要用来输出JVM中运行的进程状态信息。语法格式如下:
- jps [options] [hostid]
如果不指定hostid就默认为当前主机或服务器。
命令行参数选项说明如下:
- -q 不输出类名、Jar名和传入main方法的参数
- -m 输出传入main方法的参数
- -l 输出main类或Jar的全限名
- -v 输出传入JVM的参数
比如
1、我现在有一个WordCountTopo的Strom程序正在本机运行。
2、使用java -jar deadlock.jar & 启动一个线程死锁的程序
- wangsheng@WANGSHENG-PC /E
- $ jps -ml
- 14200 deadlock.jar
- 13952 com.wsheng.storm.topology.WordCountTopo D://input/ 3
- 13248 sun.tools.jps.Jps -ml
- 9728
二、 jstack jstack主要用来查看某个Java进程内的线程堆栈信息。语法格式如下:
- jstack [option] pid
- jstack [option] executable core
- jstack [option] [server-id@]remote-hostname-or-ip
- 命令行参数选项说明如下:
- -l long listings,会打印出额外的锁信息,在发生死锁时可以用<strong>jstack -l pid</strong>来观察锁持有情况
- -m mixed mode,不仅会输出Java堆栈信息,还会输出C/C++堆栈信息(比如Native方法)
jstack可以定位到线程堆栈,根据堆栈信息我们可以定位到具体代码,所以它在JVM性能调优中使用得非常多。
下面我们来一个实例:
找出某个Java进程中最耗费CPU的Java线程并定位堆栈信息,用到的命令有ps、top、printf、jstack、grep。
第一步: 先找出Java进程ID,服务器上的Java应用名称为wordcount.jar:
- [root@storm-master home]# ps -ef | grep wordcount | grep -v grep
- root 2860 2547 13 02:09 pts/0 00:02:03 java -jar wordcount.jar /home/input 3
得到进程ID为2860,
第二步:找出该进程内最耗费CPU的线程,可以使用如下3个命令,这里我们使用第3个命令得出如下结果:
- 1)ps -Lfp pid : 即 ps -Lfp 2860
- 2)ps -mp pid -o THREAD, tid, time :即 ps -mp 2860 -o THREAD,tid,time
- 3)top -Hp pid: 即 <strong>top -Hp 2860</strong>
- 用第三个,输出如下:

TIME列就是各个Java线程耗费的CPU时间,显然CPU时间最长的是ID为2968的线程,用
- printf "%x\n" 2968
得到2968的十六进制值为b98,下面会用到。
第三步:终于轮到jstack上场了,它用来输出进程2860的堆栈信息,然后根据线程ID的十六进制值grep,如下:
- [root@storm-master home]# jstack 2860 | grep b98
- "SessionTracker" prio=10 tid=0x00007f55a44e4800 nid=0xb53 in Object.wait() [0x00007f558e06c000
可以看到CPU消耗在SessionTracker这个类的Object.wait(),于是就能很容易的定位到相关的代码了。
三、 jmap(Memory Map)和 jhat(Java Heap Analysis Tool):
jmap导出堆内存,然后使用jhat来进行分析
jmap用来查看堆内存使用状况,一般结合jhat使用。
jmap语法格式如下:
- jmap [option] pid
- jmap [option] executable core
- jmap [option] [server-id@]remote-hostname-or-ip
如果运行在64位JVM上,由于linux操作系统的不同,可能需要指定-J-d64命令选项参数。
1、打印进程的类加载器和类加载器加载的持久代对象信息: jmap -permstat pid
个人感觉这个不是太有用
输出:类加载器名称、对象是否存活(不可靠)、对象地址、父类加载器、已加载的类大小等信息,如图:

2、查看进程堆内存使用情况:包括使用的GC算法、堆配置参数和各代中堆内存使用:jmap -heap pid
比如下面的例子
- [root@storm-master home]# jmap -heap 2860
- Attaching to process ID 2860, please wait...
- Debugger attached successfully.
- Server compiler detected.
- JVM version is 20.45-b01
- using thread-local object allocation.
- Mark Sweep Compact GC
- Heap Configuration:
- MinHeapFreeRatio = 40
- MaxHeapFreeRatio = 70
- MaxHeapSize = 257949696 (246.0MB)
- NewSize = 1310720 (1.25MB)
- MaxNewSize = 17592186044415 MB
- OldSize = 5439488 (5.1875MB)
- NewRatio = 2
- SurvivorRatio = 8
- PermSize = 21757952 (20.75MB)
- MaxPermSize = 85983232 (82.0MB)
- Heap Usage:
- New Generation (Eden + 1 Survivor Space):
- capacity = 12189696 (11.625MB)
- used = 6769392 (6.4557952880859375MB)
- free = 5420304 (5.1692047119140625MB)
- 55.53372290826613% used
- Eden Space:
- capacity = 10878976 (10.375MB)
- used = 6585608 (6.280525207519531MB)
- free = 4293368 (4.094474792480469MB)
- 60.53518272307982% used
- From Space:
- capacity = 1310720 (1.25MB)
- used = 183784 (0.17527008056640625MB)
- free = 1126936 (1.0747299194335938MB)
- 14.0216064453125% used
- To Space:
- capacity = 1310720 (1.25MB)
- used = 0 (0.0MB)
- free = 1310720 (1.25MB)
- 0.0% used
- tenured generation:
- capacity = 26619904 (25.38671875MB)
- used = 15785896 (15.054603576660156MB)
- free = 10834008 (10.332115173339844MB)
- 59.30110040967841% used
- Perm Generation:
- capacity = 33554432 (32.0MB)
- used = 33323352 (31.779624938964844MB)
- free = 231080 (0.22037506103515625MB)
- 99.31132793426514% used
3、查看堆内存中的对象数目、大小统计直方图,如果带上live则只统计活对象:jmap -histo[:live] pid
- [root@storm-master Desktop]# jmap -histo 2860
- num #instances #bytes class name
- ----------------------------------------------
- 1: 13917 11432488 [B
- 2: 6117 6181448 <instanceKlassKlass>
- 3: 39520 6004504 <constMethodKlass>
- 4: 6117 5517072 <constantPoolKlass>
- 5: 39520 5383280 <methodKlass>
- 6: 5148 3150944 <constantPoolCacheKlass>
- 7: 29954 2810640 [C
- 8: 50179 2469272 <symbolKlass>
- 9: 42122 1791704 [Ljava.lang.Object;
- 10: 1804 961464 <methodDataKlass>
- 11: 11747 941200 [Ljava.util.HashMap$Entry;
- 12: 28786 921152 java.lang.String
- 13: 6347 660088 java.lang.Class
- 14: 7374 625616 [S
- 15: 11740 563520 java.util.HashMap
- 16: 23447 562728 clojure.lang.PersistentHashMap$BitmapIndexedNode
- 17: 10980 351360 clojure.lang.Symbol
- 18: 8544 341760 java.lang.ref.SoftReference
- 19: 8028 336632 [[I
- 20: 3944 283968 java.lang.reflect.Constructor
- 21: 4744 227712 java.nio.HeapByteBuffer
- 22: 6854 219328 java.util.AbstractList$Itr
- 23: 2185 195192 [I
- 24: 3854 184992 java.nio.HeapCharBuffer
- 25: 5500 176000 java.util.concurrent.ConcurrentHashMap$HashEntry
class name是对象类型,说明如下:
- B byte
- C char
- D double
- F float
- I int
- J long
- Z boolean
- [ 数组,如[I表示int[]
- [L+类名 其他对象
4、还有一个很常用的情况是:用jmap把进程内存使用情况dump到文件中,再用jhat分析查看。需要注意的是 dump出来的文件还可以用MAT、VisualVM等工具查看。
jmap进行dump命令格式如下:
- <strong>jmap -dump:format=b,file=dumpFileName pid</strong>
我一样地对上面进程ID为2860进行Dump:
- [root@storm-master Desktop]# jmap -dump:format=b,file=/home/dump.dat 2860
- Dumping heap to /home/dump.dat ...
- Heap dump file created
然后使用jhat来对上面dump出来的内容进行分析
- [root@storm-master Desktop]# jhat -port 8888 /home/dump.dat
- Reading from /home/dump.dat...
- Dump file created Sat Aug 01 04:21:12 PDT 2015
- Snapshot read, resolving...
- Resolving 411123 objects...
- Chasing references, expect 82 dots..................................................................................
- Eliminating duplicate references..................................................................................
- Snapshot resolved.
- Started HTTP server on port 8888
- Server is ready.
注意如果Dump文件太大,可能需要加上-J-Xmx512m参数以指定最大堆内存,即jhat -J-Xmx512m -port 8888 /home/dump.dat。然后就可以在浏览器中输入主机地址:8888查看了:

点击每一个蓝色的超链接,你都会看到其相关更具体的信息,而最后一项更是支持OQL(对象查询语言)。
四、jstat(JVM统计监测工具): 看看各个区内存和GC的情况
语法格式如下:
- jstat [ generalOption | outputOptions vmid [interval[s|ms] [count]] ]
vmid是Java虚拟机ID,在Linux/Unix系统上一般就是进程ID。interval是采样时间间隔。count是采样数目。比如下面输出的是GC信息,采样时间间隔为250ms,采样数为6:
- [root@storm-master Desktop]# jstat -gc 2860 250 6

要明白上面各列的意义,先看JVM堆内存布局:
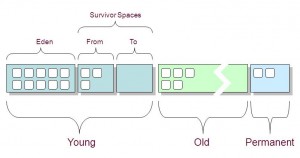
可以看出:
- 堆内存 = 年轻代 + 年老代 + 永久代
- 年轻代 = Eden区 + 两个Survivor区(From和To)
现在来解释各列含义:
- S0C、S1C、S0U、S1U:Survivor 0/1区容量(Capacity)和使用量(Used)
- EC、EU:Eden区容量和使用量
- OC、OU:年老代容量和使用量
- PC、PU:永久代容量和使用量
- YGC、YGT:年轻代GC次数和GC耗时
- FGC、FGCT:Full GC次数和Full GC耗时
- GCT:GC总耗时
五、hprof(Heap/CPU Profiling Tool): hprof能够展现CPU使用率,统计堆内存使用情况。
HPROF: 一个Heap/CPU Profiling工具:J2SE中提供了一个简单的命令行工具来对java程序的cpu和heap进行 profiling,叫做HPROF。HPROF实际上是JVM中的一个native的库,它会在JVM启动的时候通过命令行参数来动态加载,并成为 JVM进程的一部分。若要在java进程启动的时候使用HPROF,用户可以通过各种命令行参数类型来使用HPROF对java进程的heap或者 (和)cpu进行profiling的功能。HPROF产生的profiling数据可以是二进制的,也可以是文本格式的。这些日志可以用来跟踪和分析 java进程的性能问题和瓶颈,解决内存使用上不优的地方或者程序实现上的不优之处。二进制格式的日志还可以被JVM中的HAT工具来进行浏览和分析,用 以观察java进程的heap中各种类型和数据的情况。在J2SE 5.0以后的版本中,HPROF已经被并入到一个叫做Java Virtual Machine Tool Interface(JVM TI)中。
语法格式如下:
- java -agentlib:hprof[=options] ToBeProfiledClass
- java -Xrunprof[:options] ToBeProfiledClass
- javac -J-agentlib:hprof[=options] ToBeProfiledClass
完整的命令选项如下:
- Option Name and Value Description Default
- --------------------- ----------- -------
- heap=dump|sites|all heap profiling all
- cpu=samples|times|old CPU usage off
- monitor=y|n monitor contention n
- format=a|b text(txt) or binary output a
- file=<file> write data to file java.hprof[.txt]
- net=<host>:<port> send data over a socket off
- depth=<size> stack trace depth 4
- interval=<ms> sample interval in ms 10
- cutoff=<value> output cutoff point 0.0001
- lineno=y|n line number in traces? y
- thread=y|n thread in traces? n
- doe=y|n dump on exit? y
- msa=y|n Solaris micro state accounting n
- force=y|n force output to <file> y
- verbose=y|n print messages about dumps y
- Get sample cpu information every 20 millisec, with a stack depth of 3:
java -agentlib:hprof=cpu=samples,interval=20,depth=3 classname
- Get heap usage information based on the allocation sites:
java -agentlib:hprof=heap=sites classname
上面每隔20毫秒采样CPU消耗信息,堆栈深度为3,生成的profile文件名称是java.hprof.txt,在当前目录。
默认情况下,java进程profiling的信息(sites和dump)都会被 写入到一个叫做java.hprof.txt的文件中。大多数情况下,该文件中都会对每个trace,threads,objects包含一个ID,每一 个ID代表一个不同的观察对象。通常,traces会从300000开始。 默认,force=y,会将所有的信息全部输出到output文件中,所以如果含有 多个JVMs都采用的HRPOF enable的方式运行,最好将force=n,这样能够将单独的JVM的profiling信息输出到不同的指定文件。 interval选项只在 cpu=samples的情况下生效,表示每隔多少毫秒对java进程的cpu使用情况进行一次采集。 msa选项仅仅在Solaris系统下才有效, 表示会使用Solaris下的Micro State Accounting功能
第二部分: 实例部分:
该部分将使用相关的实例和前面提到的JVM性能调优工具来进行性能诊断。
1、使用jstack来分析死锁问题:
上面说明中提到 jstack主要用来查看某个Java进程内的线程堆栈信息,您可以使用它查明问题。jstack [-l] <pid>,pid可以通过使用jps命令来查看当前Java程序的pid值,-l是可选参数,它可以显示线程阻塞/死锁情况
- package com.wsheng.aggregator.thread.performance;
- import org.springframework.stereotype.Component;
- /**
- * Dead lock example
- *
- * @author Josh Wang(Sheng)
- *
- * @email josh_wang23@hotmail.com
- */
- @Component
- public class DeadLock {
- public static void main(String[] args) {
- System.out.println(" start the example ----- ");
- final Object obj_1 = new Object(), obj_2 = new Object();
- Thread t1 = new Thread("t1") {
- @Override
- public void run() {
- synchronized (obj_1) {
- try {
- System.out.println("thread t1 start...");
- Thread.sleep(3000);
- } catch (InterruptedException e) {e.printStackTrace();}
- synchronized (obj_2) {
- System.out.println("thread t1 done....");
- }
- }
- }
- };
- Thread t2 = new Thread("t2") {
- @Override
- public void run() {
- synchronized (obj_2) {
- try {
- System.out.println("thread t2 start...");
- Thread.sleep(3000);
- } catch (InterruptedException e) {e.printStackTrace();}
- synchronized (obj_1) {
- System.out.println("thread t2 done...");
- }
- }
- }
- };
- t1.start();
- t2.start();
- }
- }
以上DeadLock类是一个死锁的例子,假使在我们不知情的情况下,运行DeadLock后,发现等了N久都没有在屏幕打印线程完成信息。这个时候我们就可以使用jps查看该程序的pid值和使用jstack来生产堆栈结果问题。
- java -jar deadlock.jar <span style="font-size: 1em; line-height: 1.5;">com.wsheng.aggregator.thread.performance.</span><span style="font-size: 1em; line-height: 1.5;">DeadLock & </span>
- $ jps
- 3076 Jps
- 448 DeadLock
- $ <strong>jstack -l 448 > deadlock.jstack</strong>
结果文件deadlock.jstack内容如下:
- 2014-11-29 13:31:06
- Full thread dump Java HotSpot(TM) 64-Bit Server VM (24.65-b04 mixed mode):
- "Attach Listener" daemon prio=5 tid=0x00007fd9d4002800 nid=0x440b waiting on condition [0x0000000000000000]
- java.lang.Thread.State: RUNNABLE
- Locked ownable synchronizers:
- - None
- "DestroyJavaVM" prio=5 tid=0x00007fd9d4802000 nid=0x1903 waiting on condition [0x0000000000000000]
- java.lang.Thread.State: RUNNABLE
- Locked ownable synchronizers:
- - None
- "t2" prio=5 tid=0x00007fd9d30ac000 nid=0x5903 waiting for monitor entry [0x000000011da46000]
- java.lang.Thread.State: BLOCKED (on object monitor)
- at DeadLock$2.run(DeadLock.java:38)
- - waiting to lock <0x00000007aaba7e58> (a java.lang.Object)
- - locked <0x00000007aaba7e68> (a java.lang.Object)
- Locked ownable synchronizers:
- - None
- "t1" prio=5 tid=0x00007fd9d30ab800 nid=0x5703 waiting for monitor entry [0x000000011d943000]
- java.lang.Thread.State: BLOCKED (on object monitor)
- at DeadLock$1.run(DeadLock.java:23)
- - waiting to lock <0x00000007aaba7e68> (a java.lang.Object)
- - locked <0x00000007aaba7e58> (a java.lang.Object)
- Locked ownable synchronizers:
- - None
- "Service Thread" daemon prio=5 tid=0x00007fd9d2809000 nid=0x5303 runnable [0x0000000000000000]
- java.lang.Thread.State: RUNNABLE
- Locked ownable synchronizers:
- - None
- "C2 CompilerThread1" daemon prio=5 tid=0x00007fd9d304e000 nid=0x5103 waiting on condition [0x0000000000000000]
- java.lang.Thread.State: RUNNABLE
- Locked ownable synchronizers:
- - None
- "C2 CompilerThread0" daemon prio=5 tid=0x00007fd9d2800800 nid=0x4f03 waiting on condition [0x0000000000000000]
- java.lang.Thread.State: RUNNABLE
- Locked ownable synchronizers:
- - None
- "Signal Dispatcher" daemon prio=5 tid=0x00007fd9d3035000 nid=0x4d03 runnable [0x0000000000000000]
- java.lang.Thread.State: RUNNABLE
- Locked ownable synchronizers:
- - None
- "Finalizer" daemon prio=5 tid=0x00007fd9d2013000 nid=0x3903 in Object.wait() [0x000000011d18d000]
- java.lang.Thread.State: WAITING (on object monitor)
- at java.lang.Object.wait(Native Method)
- - waiting on <0x00000007aaa85608> (a java.lang.ref.ReferenceQueue$Lock)
- at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:135)
- - locked <0x00000007aaa85608> (a java.lang.ref.ReferenceQueue$Lock)
- at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:151)
- at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:209)
- Locked ownable synchronizers:
- - None
- "Reference Handler" daemon prio=5 tid=0x00007fd9d2012000 nid=0x3703 in Object.wait() [0x000000011d08a000]
- java.lang.Thread.State: WAITING (on object monitor)
- at java.lang.Object.wait(Native Method)
- - waiting on <0x00000007aaa85190> (a java.lang.ref.Reference$Lock)
- at java.lang.Object.wait(Object.java:503)
- at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:133)
- - locked <0x00000007aaa85190> (a java.lang.ref.Reference$Lock)
- Locked ownable synchronizers:
- - None
- "VM Thread" prio=5 tid=0x00007fd9d5011000 nid=0x3503 runnable
- "GC task thread#0 (ParallelGC)" prio=5 tid=0x00007fd9d200b000 nid=0x2503 runnable
- "GC task thread#1 (ParallelGC)" prio=5 tid=0x00007fd9d200b800 nid=0x2703 runnable
- "GC task thread#2 (ParallelGC)" prio=5 tid=0x00007fd9d200c800 nid=0x2903 runnable
- "GC task thread#3 (ParallelGC)" prio=5 tid=0x00007fd9d200d000 nid=0x2b03 runnable
- "GC task thread#4 (ParallelGC)" prio=5 tid=0x00007fd9d200d800 nid=0x2d03 runnable
- "GC task thread#5 (ParallelGC)" prio=5 tid=0x00007fd9d200e000 nid=0x2f03 runnable
- "GC task thread#6 (ParallelGC)" prio=5 tid=0x00007fd9d200f000 nid=0x3103 runnable
- "GC task thread#7 (ParallelGC)" prio=5 tid=0x00007fd9d200f800 nid=0x3303 runnable
- "VM Periodic Task Thread" prio=5 tid=0x00007fd9d3033800 nid=0x5503 waiting on condition
- JNI global references: 114
- <strong>Found one Java-level deadlock:</strong>
- =============================
- <strong>"t2":
- waiting to lock monitor 0x00007fd9d30aebb8 (object 0x00000007aaba7e58, a java.lang.Object),
- which is held by "t1"
- "t1":
- waiting to lock monitor 0x00007fd9d28128b8 (object 0x00000007aaba7e68, a java.lang.Object),
- which is held by "t2"
- Java stack information for the threads listed above:</strong>
- ===================================================
- "t2":
- at DeadLock$2.run(DeadLock.java:38)
- - waiting to lock <0x00000007aaba7e58> (a java.lang.Object)
- - locked <0x00000007aaba7e68> (a java.lang.Object)
- "t1":
- at DeadLock$1.run(DeadLock.java:23)
- - waiting to lock <0x00000007aaba7e68> (a java.lang.Object)
- - locked <0x00000007aaba7e58> (a java.lang.Object)
- Found 1 deadlock.
从这个结果文件我们一看到发现了一个死锁,具体是线程t2在等待线程t1,而线程t1在等待线程t2造成的,同时也记录了线程的堆栈和代码行数,通过这个堆栈和行数我们就可以去检查对应的代码块,从而发现问题和解决问题。
可通过下面的代码解决死锁问题:
- import java.util.concurrent.locks.Lock;
- import java.util.concurrent.locks.ReentrantLock;
- /**
- * Dead lock example
- *
- * @author Josh Wang(Sheng)
- *
- * @email josh_wang23@hotmail.com
- */
- public class DeadLock2Live {
- public static void main(String[] args) {
- System.out.println(" start the example ----- ");
- final Lock lock = new ReentrantLock();
- Thread t1 = new Thread("t1") {
- @Override
- public void run() {
- try {
- lock.lock();
- Thread.sleep(3000);
- System.out.println("thread t1 done.");
- } catch (InterruptedException e) {
- e.printStackTrace();
- } finally {
- lock.unlock();
- }
- }
- };
- Thread t2 = new Thread("t2") {
- @Override
- public void run() {
- try {
- lock.lock();
- Thread.sleep(3000);
- System.out.println("thread t2 done.");
- } catch (InterruptedException e) {
- e.printStackTrace();
- } finally {
- lock.unlock();
- }
- }
- };
- t1.start();
- t2.start();
- }
- }
2、继续使用jstack来分析HashMap在多线程情况下的死锁问题:
对于如下代码,使用10个线程来处理提交的2000个任务,每个任务会分别循环往hashmap中分别存入和取出1000个数,通过测试发现,程序并不能完整执行完成。[PS:该程序能不能成功执行完,有时也取决于所使用的服务器的运行状况,我在笔记本上测试的时候,大多时候该程序不能成功执行完成,有时会出现CPU转速加快,发热等情况]
- import java.util.HashMap;
- import java.util.Map;
- import java.util.concurrent.Callable;
- import java.util.concurrent.ExecutionException;
- import java.util.concurrent.ExecutorService;
- import java.util.concurrent.Executors;
- /**
- * @author Josh Wang(Sheng)
- *
- * @email josh_wang23@hotmail.com
- */
- public class HashMapDeadLock implements Callable<Integer> {
- private static ExecutorService threadPool = Executors.newFixedThreadPool(10);
- private static Map<Integer, Integer> results = new HashMap<>();
- @Override
- public Integer call() throws Exception {
- results.put(1, 1);
- results.put(2, 2);
- results.put(3, 3);
- for (int i = 0; i < 1000; i++) {
- results.put(i, i);
- }
- Thread.sleep(1000);
- for (int i= 0; i < 1000; i++) {
- results.remove(i);
- }
- System.out.println(" ---- " + Thread.currentThread().getName() + " " + results.get(0));
- return results.get(1);
- }
- public static void main(String[] args) throws InterruptedException, ExecutionException {
- try {
- for (int i = 0; i < 2000; i++) {
- HashMapDeadLock hashMapDeadLock = new HashMapDeadLock();
- // Future<Integer> future = threadPool.submit(hashMapDeadLock);
- // future.get();
- threadPool.submit(hashMapDeadLock);
- }
- } catch (Exception e) {
- e.printStackTrace();
- } finally {
- threadPool.shutdown();
- }
- }
- }
1) 使用jps查看线程可得:
- 43221 Jps
- 30056
- 43125 HashMapDeadLock
2)使用jstack导出多线程栈区信息:
- jstack -l 43125 > hash.jstack
3) hash.jstack的内容如下:
- 2014-11-29 18:14:22
- Full thread dump Java HotSpot(TM) 64-Bit Server VM (24.65-b04 mixed mode):
- "Attach Listener" daemon prio=5 tid=0x00007f83ee08a000 nid=0x5d07 waiting on condition [0x0000000000000000]
- java.lang.Thread.State: RUNNABLE
- Locked ownable synchronizers:
- - None
- "DestroyJavaVM" prio=5 tid=0x00007f83eb016800 nid=0x1903 waiting on condition [0x0000000000000000]
- java.lang.Thread.State: RUNNABLE
- Locked ownable synchronizers:
- - None
- "pool-1-thread-10" prio=5 tid=0x00007f83ec80a000 nid=0x6903 runnable [0x000000011cd19000]
- java.lang.Thread.State: RUNNABLE
- at java.util.HashMap.transfer(HashMap.java:601)
- at java.util.HashMap.resize(HashMap.java:581)
- at java.util.HashMap.addEntry(HashMap.java:879)
- at java.util.HashMap.put(HashMap.java:505)
- <span style="color: #ff0000;"><strong>at HashMapDeadLock.call(HashMapDeadLock.java:30)
- at HashMapDeadLock.call(HashMapDeadLock.java:1)</strong></span>
- at java.util.concurrent.FutureTask.run(FutureTask.java:262)
- at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
- at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
- at java.lang.Thread.run(Thread.java:745)
- Locked ownable synchronizers:
- - <0x00000007aaba84c8> (a java.util.concurrent.ThreadPoolExecutor$Worker)
- "Service Thread" daemon prio=5 tid=0x00007f83eb839800 nid=0x5303 runnable [0x0000000000000000]
- java.lang.Thread.State: RUNNABLE
- Locked ownable synchronizers:
- - None
- "C2 CompilerThread1" daemon prio=5 tid=0x00007f83ee002000 nid=0x5103 waiting on condition [0x0000000000000000]
- java.lang.Thread.State: RUNNABLE
- Locked ownable synchronizers:
- - None
- "C2 CompilerThread0" daemon prio=5 tid=0x00007f83ee000000 nid=0x4f03 waiting on condition [0x0000000000000000]
- java.lang.Thread.State: RUNNABLE
- Locked ownable synchronizers:
- - None
- "Signal Dispatcher" daemon prio=5 tid=0x00007f83ec04c800 nid=0x4d03 runnable [0x0000000000000000]
- java.lang.Thread.State: RUNNABLE
- Locked ownable synchronizers:
- - None
- "Finalizer" daemon prio=5 tid=0x00007f83eb836800 nid=0x3903 in Object.wait() [0x000000011bc58000]
- java.lang.Thread.State: WAITING (on object monitor)
- at java.lang.Object.wait(Native Method)
- - waiting on <0x00000007aaa85608> (a java.lang.ref.ReferenceQueue$Lock)
- at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:135)
- - locked <0x00000007aaa85608> (a java.lang.ref.ReferenceQueue$Lock)
- at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:151)
- at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:209)
- Locked ownable synchronizers:
- - None
- "Reference Handler" daemon prio=5 tid=0x00007f83eb01a800 nid=0x3703 in Object.wait() [0x000000011bb55000]
- java.lang.Thread.State: WAITING (on object monitor)
- at java.lang.Object.wait(Native Method)
- - waiting on <0x00000007aaa85190> (a java.lang.ref.Reference$Lock)
- at java.lang.Object.wait(Object.java:503)
- at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:133)
- - locked <0x00000007aaa85190> (a java.lang.ref.Reference$Lock)
- Locked ownable synchronizers:
- - None
- "VM Thread" prio=5 tid=0x00007f83ed808800 nid=0x3503 runnable
- "GC task thread#0 (ParallelGC)" prio=5 tid=0x00007f83ec80d800 nid=0x2503 runnable
- "GC task thread#1 (ParallelGC)" prio=5 tid=0x00007f83ec80e000 nid=0x2703 runnable
- "GC task thread#2 (ParallelGC)" prio=5 tid=0x00007f83ec001000 nid=0x2903 runnable
- "GC task thread#3 (ParallelGC)" prio=5 tid=0x00007f83ec002000 nid=0x2b03 runnable
- "GC task thread#4 (ParallelGC)" prio=5 tid=0x00007f83ec002800 nid=0x2d03 runnable
- "GC task thread#5 (ParallelGC)" prio=5 tid=0x00007f83ec003000 nid=0x2f03 runnable
- "GC task thread#6 (ParallelGC)" prio=5 tid=0x00007f83ec003800 nid=0x3103 runnable
- "GC task thread#7 (ParallelGC)" prio=5 tid=0x00007f83ec004800 nid=0x3303 runnable
- "VM Periodic Task Thread" prio=5 tid=0x00007f83ec814800 nid=0x5503 waiting on condition
- JNI global references: 134
4)从红色高亮部分可看出,代码中的30行出问题了,即往hashmap中写入数据出问题了:
- results.put(i, i);
很快就明白因为Hashmap不是线程安全的,所以问题就出在这个地方,我们可以使用线程安全的map即
ConcurrentHashMap后者HashTable来解决该问题:
- import java.util.Map;
- import java.util.concurrent.Callable;
- import java.util.concurrent.ConcurrentHashMap;
- import java.util.concurrent.ExecutionException;
- import java.util.concurrent.ExecutorService;
- import java.util.concurrent.Executors;
- /**
- *
- */
- /**
- * @author Josh Wang(Sheng)
- *
- * @email josh_wang23@hotmail.com
- */
- public class HashMapDead2LiveLock implements Callable<Integer> {
- private static ExecutorService threadPool = Executors.newFixedThreadPool(10);
- private static Map<Integer, Integer> results = new ConcurrentHashMap<>();
- @Override
- public Integer call() throws Exception {
- results.put(1, 1);
- results.put(2, 2);
- results.put(3, 3);
- for (int i = 0; i < 1000; i++) {
- results.put(i, i);
- }
- Thread.sleep(1000);
- for (int i= 0; i < 1000; i++) {
- results.remove(i);
- }
- System.out.println(" ---- " + Thread.currentThread().getName() + " " + results.get(0));
- return results.get(1);
- }
- public static void main(String[] args) throws InterruptedException, ExecutionException {
- try {
- for (int i = 0; i < 2000; i++) {
- HashMapDead2LiveLock hashMapDeadLock = new HashMapDead2LiveLock();
- // Future<Integer> future = threadPool.submit(hashMapDeadLock);
- // future.get();
- threadPool.submit(hashMapDeadLock);
- }
- } catch (Exception e) {
- e.printStackTrace();
- } finally {
- threadPool.shutdown();
- }
- }
- }
改成ConcurrentHashMap后,重新执行该程序,你会发现很快该程序就执行完了。
jvm gc 调优 实战的更多相关文章
- JVM 性能调优实战之:一次系统性能瓶颈的寻找过程
玩过性能优化的朋友都清楚,性能优化的关键并不在于怎么进行优化,而在于怎么找到当前系统的性能瓶颈.性能优化分为好几个层次,比如系统层次.算法层次.代码层次…JVM 的性能优化被认为是底层优化,门槛较高, ...
- JVM 性能调优实战之:使用阿里开源工具 TProfiler 在海量业务代码中精确定位性能代码
本文是<JVM 性能调优实战之:一次系统性能瓶颈的寻找过程> 的后续篇,该篇介绍了如何使用 JDK 自身提供的工具进行 JVM 调优将 TPS 由 2.5 提升到 20 (提升了 7 倍) ...
- JVM GC调优一则--增大Eden Space提高性能
版权声明:本文为横云断岭原创文章,未经博主同意不得转载.微信公众号:横云断岭的专栏 https://blog.csdn.net/hengyunabc/article/details/24924843 ...
- JVM GC调优一则–增大Eden Space提高性能
缘起 线上有Tomcat升级到7.0.52版,然后有应用的JVM FullGC变频繁,在高峰期socket连接数,Cpu使用率都暴增. 思路 思路是Tomcat本身的代码应该是没有问题的,有问题的可能 ...
- JVM调优之---一次GC调优实战
某系统反馈『性能抖动,响应时间会突然飙高,TP999 MAX会到3000+』,初步怀疑是JVM FULL GC导致的 STW,观察FULL GC日志默认的JVM参数: -Xms4096m -Xmx40 ...
- 深入理解JVM(6)——JVM性能调优实战
如何在高性能服务器上进行JVM调优:以便充分利用高性能服务器的硬件资源,有两种JVM调优方案. 一. 采用64位操作系统,并为JVM分配大内存 分析:如果JVM中堆内存太小,那么就会频繁 ...
- JVM 自带性能监测调优工具 (jstack、jstat)及 JVM GC 调优
1. jstack:占用最多资源(CPU 内存)的Java代码 https://www.cnblogs.com/chengJAVA/p/5821218.html https://blog.csdn.n ...
- ifeve.com 南方《JVM 性能调优实战之:使用阿里开源工具 TProfiler 在海量业务代码中精确定位性能代码》
https://blog.csdn.net/defonds/article/details/52598018 多次拉取 JStack,发现很多线程处于这个状态: at jrockit/vm/Al ...
- JVM 调优之 Eclipse 启动调优实战
本文是我12年在学习<深入理解Java虚拟机:JVM高级特性与最佳实践>时,做的一个 JVM 简单调优实战笔记,版本都有些过时,不过调优思路和过程还是可以分享给大家参考的. 环境基础配置 ...
随机推荐
- [Effective Java 读书笔记] 第8章 通用程序设计
本章主要讲了以下几条基本的JAVA编程原则: 1.将局部变量的作用域控制在最小,在使用时才定义 2.for-each优于for循环 有三个例外(1,2点主旨就是,for each只能用于读取,不能用于 ...
- javascript 防止多次提交或执行(在规定时间段内只允许执行一次) 默认 3000ms
"use strict" class Func{ constructor(){} isRun(id, time){//防止多次提交或执行(在规定时间段内只允许执行一次) 默认 30 ...
- ls-remote -h -t git://github.com/adobe-webplatform/eve.git
npm WARN deprecated bfj-node4@5.3.1: Switch to the `bfj` package for fixes and new features! npm WAR ...
- Day17-18前端学习之路——常用语句资料库
一.var 与 let 的区别 var: 可以先初始化再声明该变量; 可以根据需要多次声明相同名称的变量 var myName = 'Chris'; var myName = 'Bob'; let m ...
- asp.net MVC项目开发之统计图的使用(前言)
接触这个项目,是项目组长已经完成了多数需求,并且有2个项目需要完工的情况下,让我加入,给了我2个表格,让我去设计出统计图. 第一次做统计图,可以说没有任何经验,不知道该如何下手,表格的数据量 ...
- centos7安装Elasticsearch及Es-head插件详细教程(图文)
懒惰了很久,今天来写一下Elasticsearch在centos7上安装教程以及安装过程中可能出现的报错解决方式,有不对的地方,烦请各位看官多多指教! 一.ES安装 1.环境检查 确保有java环境, ...
- 11.Android-Xml读写
android中写XML时,需要用到XmlSerializer类 解析XML时,则需要用到XmlPullParser类 1.XmlSerializer类介绍 通过Xml.newSerializer() ...
- 邓 【PHP大全】
获取对应的时间戳(只保存月底的时间戳) function getTimeDate($timeType, $time, $count) { switch ($timeType) { case 'MONT ...
- List保持顺序去重
Map<String, List<Bean>> orderMap = list.stream().collect(Collectors.groupingBy(Bean::get ...
- akka设计模式系列-消息模型(续)
在之前的akka设计模式系列-消息模型中,我们介绍了akka的消息设计方案,但随着实践的深入,发现了一些问题,这里重新梳理一下设计方法,避免之前的错误.不当的观点给大家带来误解. 命令和事件 我们仍然 ...