kafka数据祸福和failover
k

CAP帽子理论。
consistency:一致性 Availability:可用性 partition tolerance:分区容忍型


CA :mysql oracle(抛弃了网络分区)
CP:hbase redis mongodb(抛弃了可用性)
AP:cassandra simpleDB(抛弃了强一致性,采用弱一致性或者最终一致性,不定时一致性)
一致性的方案

master-slave(hadoop)
WNR 读取后还得判断哪个数据是最新的。常用做法(版本号或者时间戳)

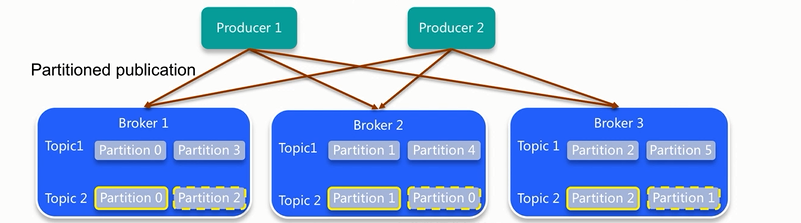

平时读取数据是从leader上读取,follower是为了防止leader宕机进行可用性保证。数据是follower从leader拉取,类似consumer

kafka既不是同步也不是异步机制,而是采用了isr机制。(kafka一旦数据进行commit就必须保证所有的数据都被commit)
一旦发现follower和leader相距的数据过大,就会进行节点移除。差距过大的条件为时间或者条目数:

这是kafka区别与其他系统一个亮点,既不采用同步复制也不采用异步,而且采用了中间的动态控制的设计。
min,insync.replicas是kafka备份的选取,通常是2比较安全一些
request.required.acks
0:这意味着生产者producer不等待来自broker同步完成的确认继续发送下一条(批)消息。此选项提供最低的延迟但最弱的耐久性保证(当服务器发生故障时某些数据会丢失,如leader已死,但producer并不知情,发出去的信息broker就收不到)。
1:这意味着producer在leader已成功收到的数据并得到确认后发送下一条message。此选项提供了更好的耐久性为客户等待服务器确认请求成功(被写入死亡leader但尚未复制将失去了唯一的消息)。
-1:这意味着producer在follower副本确认接收到数据后才算一次发送完成。
此选项提供最好的耐久性,我们保证没有信息将丢失,只要至少一个同步副本保持存活。
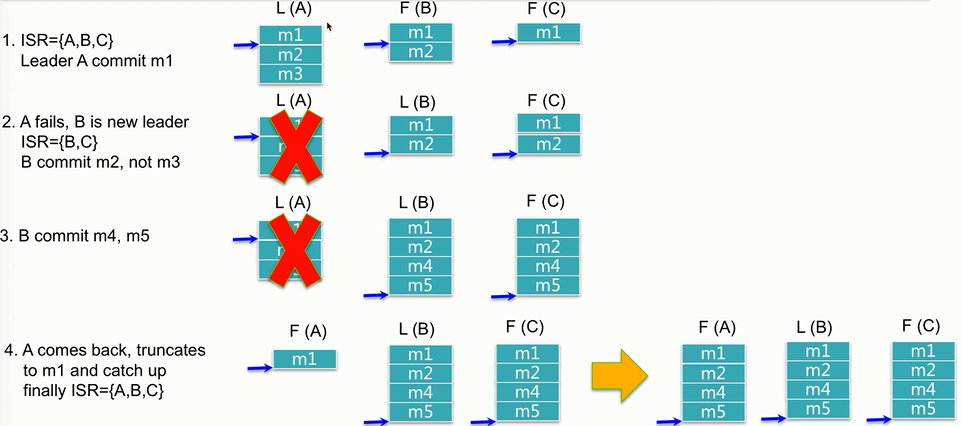
从上图可以看出kafka只有commit的数据才会可以被消费。比如3---4时候M3数据会丢失,因为leader宕机的时候M3从来没被commit过,所以数据在默认retry还没成功就会丢失,但是如果retry成功后会插入M5之后,顺序性也就变了(所以kafka的顺序性是comit顺序而不是发送顺序,而且处理不好也会存在数据丢失的情况),一旦宕机节点恢复就需要check out所有落后数据,直到isr设置的临界点(比如4K条目)才会被加入到ISR列表中。

有选项可以配置全部节点挂掉时候,是恢复isr中的列表,还是全部机器无论在不在ISR中(默认选项)

备份数目不能超过broker数量

默认kafka的replicas和leader都会尽量均匀分配。因为读写都是通过leader所以需要尽量性能均匀些
kafka数据祸福和failover的更多相关文章
- Kafka数据辅助和Failover
数据辅助与Failover CAP理论(它具有一致性.可用性.分区容忍性) CAP理论:分布式系统中,一致性.可用性.分区容忍性最多只可同时满足两个.一般分区容忍性都要求有保障,因此很多时候在可用性与 ...
- Gobblin采集kafka数据
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 找时间记录一下利用Gobblin采集kafka数据的过程,话不多说,进入正题 一.Gobblin ...
- java spark-streaming接收TCP/Kafka数据
本文将展示 1.如何使用spark-streaming接入TCP数据并进行过滤: 2.如何使用spark-streaming接入TCP数据并进行wordcount: 内容如下: 1.使用maven,先 ...
- Flink消费Kafka数据并把实时计算的结果导入到Redis
1. 完成的场景 在很多大数据场景下,要求数据形成数据流的形式进行计算和存储.上篇博客介绍了Flink消费Kafka数据实现Wordcount计算,这篇博客需要完成的是将实时计算的结果写到redis. ...
- 工具篇-Spark-Streaming获取kafka数据的两种方式(转载)
转载自:https://blog.csdn.net/weixin_41615494/article/details/7952173 一.基于Receiver的方式 原理 Receiver从Kafka中 ...
- spark streaming从指定offset处消费Kafka数据
spark streaming从指定offset处消费Kafka数据 -- : 770人阅读 评论() 收藏 举报 分类: spark() 原文地址:http://blog.csdn.net/high ...
- Spark Streaming接收Kafka数据存储到Hbase
Spark Streaming接收Kafka数据存储到Hbase fly spark hbase kafka 主要参考了这篇文章https://yq.aliyun.com/articles/60712 ...
- flume 读取kafka 数据
本文介绍flume读取kafka数据的方法 代码: /************************************************************************* ...
- Kafka数据安全性、运行原理、存储
直接贴面试题: 怎么保证数据 kafka 里的数据安全? 答: 生产者数据的不丢失kafka 的 ack 机制: 在 kafka 发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够 ...
随机推荐
- 手写代码注意点 -- HashMap
1.定义 HashMap<String,String> hashMap = new HashMap<>(); <String,String>只需要写一遍 2.获取k ...
- [JZOJ3402] 【GDOI2014模拟】Pty的字符串
题目 给你一棵每条边从父亲指向儿子的树,每条边上面有一个字母. 从树上的任意一点出发,走出的路径就是对应一个子串. (这不是\(Trie\),因为每个父亲可能会连出字母相同的边) 再给你一个字符串\( ...
- JavaScript工作原理
HTML代码所表示的文档是一种静态文档,几乎没有交互功能,很难使页面成为动态页面.增加脚本语言,可使数据发送到服务器之前先进行处理和校验,动态地创建新的Web内容,更重要的是,引入脚本语言使我们有了事 ...
- spring整合shiro框架
上一篇文章已经对shiro框架做了一定的介绍,这篇文章讲述使用spring整合shiro框架,实现用户认证已经权限控制 1.搭建环境 这里不在赘述spring环境的搭建,可以简单的搭建一个ssm框架, ...
- BZOJ 1296(SCOI 2009) 粉刷匠
1296: [SCOI2009]粉刷匠 Time Limit: 10 Sec Memory Limit: 162 MB Submit: 2544 Solved: 1466 [Submit][Statu ...
- spss modeler出现使用错误提
spss modeler出现使用错误提 1.对字段"compensation汇总导出"指定的类型不充分 问题: 为了分析需要,我加了一个"字段选项"--&quo ...
- VUE的组件为什么要EXPORT DEFAULT 转载
Vue的组件为什么要export default Vue 的模块机制 Vue 是通过 webpack 实现的模块化,因此可以使用 import 来引入模块,例如: 此外,你还可以在 bulid/w ...
- AtCoder ABC 129F Takahashi's Basics in Education and Learning
题目链接:https://atcoder.jp/contests/abc129/tasks/abc129_f 题目大意 给定一个长度为 L ,首项为 A,公差为 B 的等差数列 S,将这 L 个数拼起 ...
- FastJson使用方法
FastJson是阿里的一款开源框架,用来快速实现Java的序列化和反序列化. 官方地址:https://github.com/alibaba/fastjson 使用方法演示: 下载jar包,使用ID ...
- Mybatis功能架构及执行流程
原文地址:http://blog.51cto.com/12222886/2052647 一.功能架构设计 功能架构讲解: 我们把Mybatis的功能架构分为三层: (1) API接口层:提供给外部使用 ...