MySQL8.0 InnoDB并行执行
概述
MySQL经过多年的发展已然成为最流行的数据库,广泛用于互联网行业,并逐步向各个传统行业渗透。之所以流行,一方面是其优秀的高并发事务处理的能力,另一方面也得益于MySQL丰富的生态。MySQL在处理OLTP场景下的短查询效果很好,但对于复杂大查询则能力有限。最直接一点就是,对于一个SQL语句,MySQL最多只能使用一个CPU核来处理,在这种场景下无法发挥主机CPU多核的能力。MySQL没有停滞不前,一直在发展,新推出的8.0.14版本第一次引入了并行查询特性,使得check table和select count(*)类型的语句性能成倍提升。虽然目前使用场景还比较有限,但后续的发展值得期待。
使用方式
通过配置参数innodb_parallel_read_threads来设置并发线程数,就能开始并行扫描功能,默认这个值为4。我这里做一个简单的实验,通过sysbench导入2亿条数据,分别配置innodb_parallel_read_threads为1,2,4,8,16,32,64,测试并行执行的效果。测试语句为select count(*) from sbtest1;
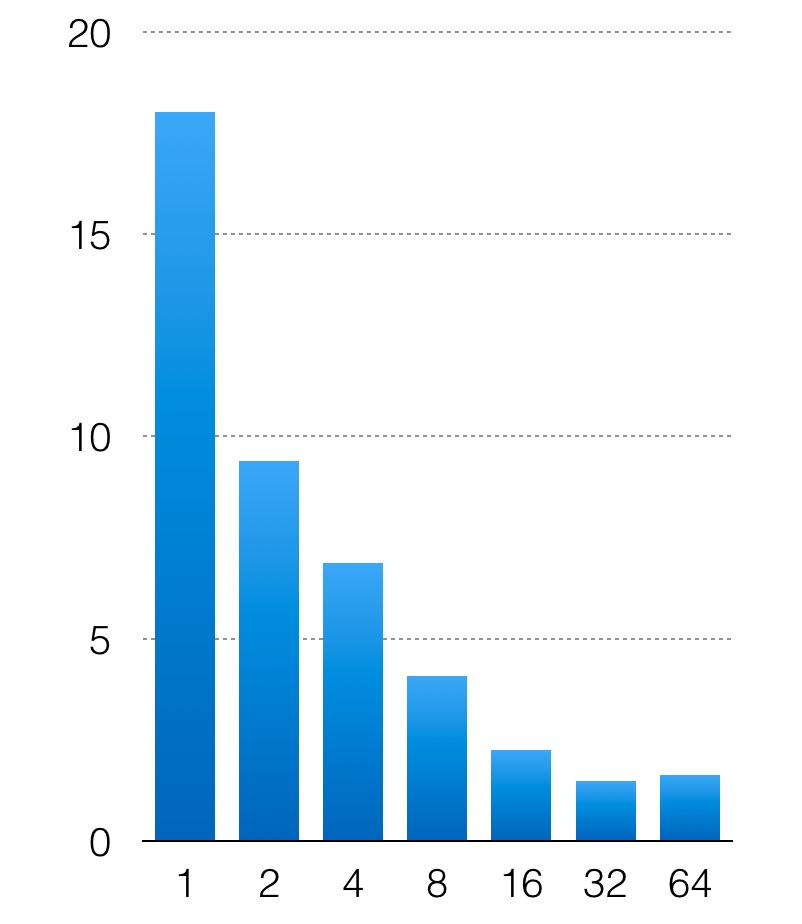
横轴是配置并发线程数,纵轴是语句执行时间。从测试结果来看,整个并行表现还是不错的,扫描2亿条记录,从单线程的18s,下降到32线程的1s。后面并发开再多,由于数据量有限,多线程的管理消耗超过了并发带来的性能提升,不能再继续缩短SQL执行时间。
MySQL并行执行
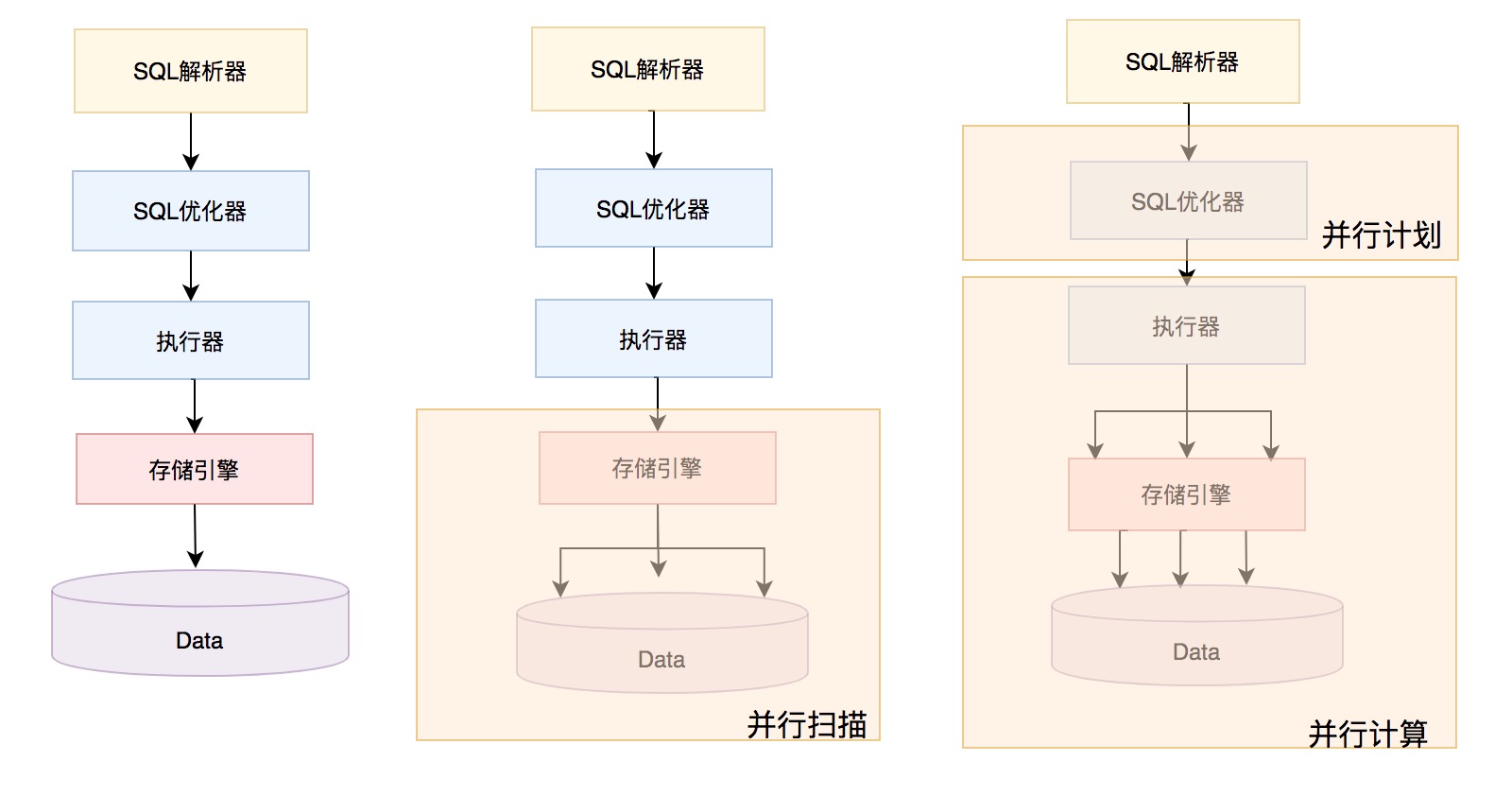
实际上目前MySQL的并行执行还处于非常初级阶段,如下图所示,左边是之前MySQL串行处理单个SQL形态;中间的是目前MySQL版本提供的并行能力,InnoDB引擎并行扫描的形态;最右边的是未来MySQL要发展的形态,优化器根据系统负载和SQL生成并行计划,并将分区计划下发给执行器并行执行。并行执行不仅仅是并行扫描,还包括并行聚集,并行连接,并行分组,以及并行排序等。目前版本MySQL的上层的优化器以及执行器并没有配套的修改。因此,下文的讨论主要集中在InnoDB引擎如何实现并行扫描,主要包括分区,并行扫描,预读以及与执行器交互的适配器类。
分区
并行扫描的一个核心步骤就是分区,将扫描的数据划分成多份,让多个线程并行扫描。InnoDB引擎是索引组织表,数据以B+tree的形式存储在磁盘上,节点的单位是页面(block/page),同时缓冲池中会对热点页面进行缓存,并通过LRU算法进行淘汰。分区的逻辑就是,从根节点页面出发,逐层往下扫描,当判断某一层的分支数超过了配置的线程数,则停止拆分。在实现时,实际上总共会进行两次分区,第一次是按根节点页的分支数划分分区,每个分支的最左叶子节点的记录为左下界,并将这个记录记为相邻上一个分支的右上界。通过这种方式,将B+tree划分成若干子树,每个子树就是一个扫描分区。经过第一次分区后,可能出现分区数不能充分利用多核问题,比如配置了并行扫描线程为3,第一次分区后,产生了4个分区,那么前3个分区并行做完后,第4个分区至多只有一个线程扫描,最终效果就是不能充分利用多核资源。
二次分区
为了解决这个问题,8.0.17版本引入了二次分区,对于第4个分区,继续下探拆分,这样多个子分区又能并发扫描,InnoDB引擎并发扫描的最小粒度是页面级别。具体判断二次分区的逻辑是,一次分区后,若分区数大于线程数,则编号大于线程数的分区,需要继续进行二次分区;若分区数小于线程数且B+tree层次很深,则所有的分区都需要进行二次分区。相关代码如下:
split_point = ;
if (ranges.size() > max_threads()) {
//最后一批分区进行二次分区
split_point = (ranges.size() / max_threads()) * max_threads();
} else if (m_depth < SPLIT_THRESHOLD) {
/* If the tree is not very deep then don't split. For smaller tables
it is more expensive to split because we end up traversing more blocks*/
split_point = max_threads();
} else {
//如果B+tree的层次很深(层数大于或等于3,数据量很大),则所有分区都需要进行二次分区
}
无论是一次分区,还是二次分区,分区边界的逻辑都一样,以每个分区的最左叶子节点的记录为左下界,并且将这个记录记为相邻上一个分支的右上界。这样确保分区足够多,粒度足够细,充分并行。下图展示了配置为3的并发线程,扫描进行二次分区的情况。

相关代码如下:
create_ranges(size_t depth, size_t level)
一次分区:
parallel_check_table
add_scan
partition(scan_range, level=) /* start at root-page */
create_ranges(scan_range, depth=, level=)
create_contexts(range, index >= split_point)
二次分区:
split()
partition(scan_range, level=)
create_ranges(depth=,level)
并行扫描
在一次分区后,将每个分区扫描任务放入到一个lock-free队列中,并行的worker线程从队列中获取任务,执行扫描任务,如果获取的任务带有split属性,这个时候worker会将任务进行二次拆分,并投入到队列中。这个过程主要包括两个核心接口,一个是工作线程接口,另外一个是遍历记录接口,前者从队列中获取任务并执行,并维护统计计数;后者根据可见性获取合适的记录,并通过上层注入的回调函数处理,比如计数等。
Parallel_reader::worker(size_t thread_id)
{
1.从ctx-queue提取ctx任务
2.根据ctx的split属性,确定是否需要进一步拆分分区(split())
3.遍历分区所有记录(traverse())
4.一个分区任务结束后,维护m_n_completed计数
5.如果m_n_compeleted计数达到ctx数目,唤醒所有worker线程结束
6.根据traverse接口,返回err信息。
}
Parallel_reader::Ctx::traverse()
{
1.根据range设置pcursor
2.找到btree,将游标定位到range的起始位置
3.判断可见性(check_visibility)
4.如果可见,根据回调函数计算(比如统计)
5.向后遍历,若达到了页面的最后一条记录,启动预读机制(submit_read_ahead)
6.超出范围后结束
}
同时在8.0.17版本还引入了预读机制,避免因为IO瓶颈导致并行效果不佳的问题。目前预读的线程数不能配置,在代码中硬编码为2个线程。每次预读的单位是一个簇(InnoDB文件通过段,簇,页三级结构管理,一个簇是一组连续的页),根据页面配置的大小,可能为1M或者2M。对于常见的16k页面配置,每次预读1M,也就是64个页面。worker线程在进行扫描时,会先判断相邻的下一个页面是否为簇的第一个页面,如果是,则发起预读任务。预读任务同样通过lock-free 队列缓存,worker线程是生产者,read-ahead-worker是消费者。由于所有分区页面没有重叠,因此预读任务也不会重复。
执行器交互(适配器)
实际上,MySQL已经封装了一个适配器类Parallel_reader_adapter来供上层使用,为后续的更丰富的并行执行做准备。首先这个类需要解决记录格式的问题,将引擎层扫描的记录转换成MySQL格式,这样做到上下层解耦,执行器不用感知引擎层格式,统一按MySQL格式处理。整个过程是一个流水线,通过一个buffer批量存储MySQL记录,worker线程不停的将记录从引擎层上读上来,同时有记录不停的被上层处理,通过buffer可以平衡读取和处理速度的差异,确保整个过程流动起来。缓存大小默认是2M,根据表的记录行长来确定buffer可以缓存多少个MySQL记录。核心流程主要在process_rows接口中,流程如下
process_rows
{
1.将引擎记录转换成MySQL记录
2.获取本线程的buffer信息(转换了多少mysql记录,发送了多少给上层)
3.将MySQL记录填充进buffer,自增统计m_n_read
4.调用回调函数处理(比如统计,聚合,排序等),自增统计m_n_send
}
对于调用者来说,需要设置表的元信息,以及注入处理记录回调函数,比如处理聚集,排序,分组的工作。回调函数通过设置m_init_fn,m_load_fn和m_end_fn来控制。
总结
MySQL8.0引入了并行查询虽然还比较初级,但已经让我们看到了MySQL并行查询的潜力,从实验中我们也看到了开启并行执行后,SQL语句执行充分发挥了多核能力,响应时间急剧下降。相信在不久的将来,8.0的会支持更多并行算子,包括并行聚集,并行连接,并行分组以及并行排序等。
参考文档
https://dev.mysql.com/worklog/task/?id=11720
https://dev.mysql.com/worklog/task/?id=12978
https://yq.aliyun.com/articles/691516?utm_content=g_1000045831
http://mysql.taobao.org/monthly/2019/10/02/
https://www.percona.com/blog/2019/01/17/using-parallel-query-with-amazon-aurora-for-mysql/
MySQL8.0 InnoDB并行执行的更多相关文章
- mysql8.0发布新特性
2018年4月21日 14:36:42 https://dev.mysql.com/doc/relnotes/mysql/8.0/en/news-8-0-11.html#mysqld-8-0-11-b ...
- MySQL8.0 原子DDL
Edit MySQL8.0 原子DDL 简介 MySQL8.0 开始支持原子 DDL(atomic DDL),数据字典的更新,存储引擎操作,写二进制日志结合成了一个事务.在没有原子DDL之前,DROP ...
- 深入解读MySQL8.0 新特性 :Crash Safe DDL
前言 在MySQL8.0之前的版本中,由于架构的原因,mysql在server层使用统一的frm文件来存储表元数据信息,这个信息能够被不同的存储引擎识别.而实际上innodb本身也存储有元数据信息.这 ...
- mysql-8.0 安装教程(自定义配置文件,密码方式已修改)
下载zip安装包: MySQL8.0 For Windows zip包下载地址:https://dev.mysql.com/downloads/file/?id=476233,进入页面后可以不登录.后 ...
- MySQL下载与MySQL安装图解(MySQL5.7与MySQL8.0)
MySQL下载与MySQL安装图解(MySQL5.7与MySQL8.0) 1.MySQL下载(MySQL8.0社区版) mysql下载方法,请根据风哥以下步骤与图示来下载mysql8.0最新社区版本: ...
- windows10安装mysql-8.0.13(zip安装)
安装环境说明 系统版本:windows10 mysql版本:mysql-8.0.13-winx64.zip 下载地址:http://mirrors.163.com/mysql/Downloads/My ...
- mysql8.0绿色版安装及mysqldump备份
1.下载mysql绿色版压缩包https://dev.mysql.com/downloads/mysql/ 2.解压到安装目录后,在根目录创建data文件夹 3.把mysql下的bin目录添加到环境变 ...
- mysql8.0.15二进制安装
mysql8.0.15二进制安装 今天有幸尝试安装了社区版本的mysql8.0.15,记录下来,供以后方便使用.特此感谢知数堂的叶老师,提供了配置文件的模板. # 第一部分:系统配置 # 1.安装系统 ...
- MySQL8.0
序言 my.ini [mysqld] # 设置3306端口 port=3306 # 设置mysql的安装目录 basedir=D:\\DataBase\\mysql-8.0.12-winx64 # 设 ...
随机推荐
- 微信小程序点击图片放大
WXML: <view class='imgList'> <view class='imgList-li' wx:for='{{imgArr}}'> <image cla ...
- cogs 176. [USACO Feb07] 奶牛聚会 dijkstra
176. [USACO Feb07] 奶牛聚会 ★☆ 输入文件:sparty.in 输出文件:sparty.out 简单对比时间限制:3 s 内存限制:16 MB 译: zqzas N ...
- 【LC_Lesson7】---将两个有序链表合成新的一个有序链表
将两个有序链表合并为一个新的有序链表并返回.新链表是通过拼接给定的两个链表的所有节点组成的. 示例: 输入:1->2->4, 1->3->4 输出:1->1->2- ...
- vue vuex开发中遇到的问题及解决小技巧
1.在vue的开发中,如果使用了vuex,数据的组装,修改时在mutations中,页面是建议修改变量值的,如果强制修改,控制台就会出现错误.如下: 这种错误虽然不会影响结果,但是是vuex不提倡的方 ...
- ELK学习实验018:filebeat收集docker日志
Filebeat收集Docker日志 1 安装docker [root@node4 ~]# yum install -y yum-utils device-mapper-persistent-data ...
- 一起来学习XPATH,来看看除了正则表达式我们还能怎么抓取数据
参考学习的网站链接http://www.w3school.com.cn/xpath/xpath_intro.asp 首先理清楚一些常识 以此为例 <?xml version="1.0& ...
- 9.Break和Continue
Break直接跳出循环和Continue略过本次循环,循环继续执行: Break在任何循坏语句的主体部分,均可用break控制循环的流程.break用于强制退出循环,不执行循环体中的语句,后边语句继续 ...
- SpringMVC简单使用教程
一.SpringMVC简单入门,创建一个HelloWorld程序 1.首先,导入SpringMVC需要的jar包. 2.添加Web.xml配置文件中关于SpringMVC的配置 <!--conf ...
- 「 从0到1学习微服务SpringCloud 」13 断路器Hystrix
背景与功能 在微服务架构中,很多情况下,各个服务之间是相互依赖,一个服务可能会调用了好几个其他服务,假设其中有一个服务故障,便会产生级联故障,最终导致整个系统崩溃无法使用(这称为雪崩效应),Sprin ...
- 《Sequence Models》课堂笔记
Lesson 5 Sequence Models 这篇文章其实是 Coursera 上吴恩达老师的深度学习专业课程的第五门课程的课程笔记. 参考了其他人的笔记继续归纳的. 符号定义 假如我们想要建立一 ...