【Python3爬虫】突破反爬之应对前端反调试手段
一、前言
在我们爬取某些网站的时候,会想要打开 DevTools 查看元素或者抓包分析,但按下 F12 的时候,却出现了下面这一幕:

此时网页暂停加载,自动跳转到 Source 页面并打开了一个 JS 文件,在右侧可以看到 “Debugger paused”,在 Call Stack 中还有一些调用信息,如下图:
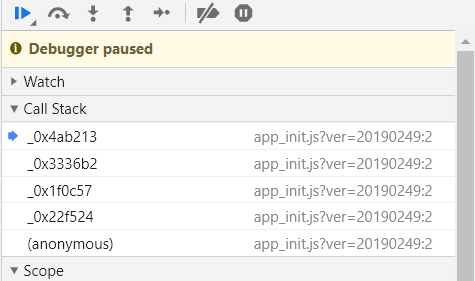
对于有的网站,如果你继续运行文件,会不停地有调用信息出现在 Call Stack 中,同时不断地消耗内存,最终导致浏览器卡死崩溃。为什么会有这种情况呢?这是前端工程师们做了一点手脚,避免他人进行调试。那就没有解决办法了吗?还是有的,至于怎么做,往下看吧。
二、反调试
1.关于调试
我们在了解代码的功能的时候,一般使用 JavaScript 调试工具(例如 DevTools)通过设置断点的方式来中断或阻止脚本代码的执行,而断点也是代码调试中最基本的了。
2.关于反调试
反调试就是在检测到用户打开 DevTools 的时候,就会调用相应的函数,以阻止用户进行调试。在反调试中,有时候会将函数进行重定义,并且改变其行为,就会将某些信息隐藏起来或者改变其中的一部分信息。
三、示例
1.示例一
第一个简单的例子就是直接使用 debugger 的,一打开 DevTools 就无限 debugger:
setInterval(function() {
debugger
}, 100);
这种问题解决起来还是很容易的,总结起来就是四个字:禁止断点。
在 Source 页面右侧按钮找到“Deactivate breakpoints”,或者使用快捷键 Ctrl + F8,如下图:

除了这种解决方案,还可以找到 debugger 那一行,然后右键选择“Never pause here”,就会出现一盒黄色的箭头,如下图:
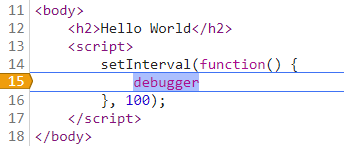
设置完之后,继续运行代码就行了。
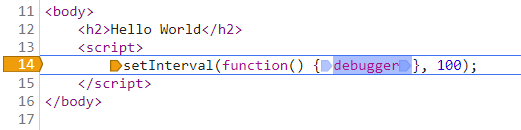
不过这种方案和代码的编写风格有关系,例如下面这种情况,设置“Never pause here”就没用了。
2.示例二
第二个稍微复杂一点,不是直接在代码中加入 debugger 了,而是将其隐藏起来,这样就不会很轻易地被人发现了:
function t() {
try {
var a = ["r", "e", "g", "g", "u", "b", "e", "d"].reverse().join("");
! function e(n) {
(1 !== ("" + n / n).length || 0 === n) && function() {}
.constructor(a)(),
e(++n)
}(0)
} catch (a) {
setTimeout(t, 500)
}
}
这段代码首先是设置变量 a 表示字符串“debugger”,然后使用 constructor() 来实现调用 debugger 方法,再使用 setTimeout 实现每0.5秒中断一次。
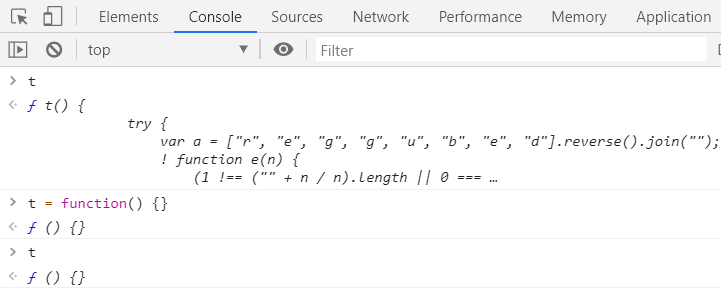
要解决这种问题,除了使用前面说的禁止断点,还可以将反调试具名函数重新定义一遍,然后重新打开 DevTools,就能进行调试了。对于上面的例子,可以在控制台中输入以下内容:
t = function() {}
通过下面的截图可以发现我们确实已经修改了对于 t 的定义,因而也就不会进入 debugger 了:
四、实战
1.目标站点
淘大象:https://taodaxiang.com/credit2
2.页面分析
打开 DevTools,出现“Paused in debugger”,并自动跳转到相应代码位置,如下:

此时按下 Ctrl + F8 禁止断点,然后 F8 继续运行,网页退出 debugger 并正常加载,切换到 NetWork 选项再选择 XHR,可以找到如下请求:
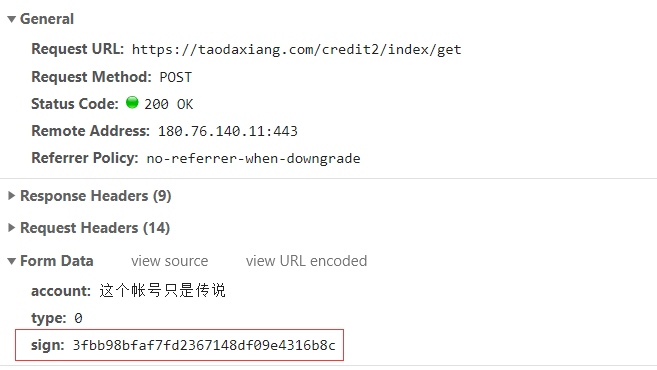
很明显这个 sign 是经过加密的,全局搜索“sign”看能不能找到可疑内容,出现了四个结果,其中有三个是 JS 文件:

通过一番查找,可以在 app_init.js 中找到如下内容:

这是一个发送请求的方法,包含了请求地址“url”、请求方式“type”和数据内容“data”等,而“data”中的内容也和前面的截图相对应,因此可以确定就是这个了。接下来就是解密得到这个 sign 值了。
3.解密过程
首先要找到定义 “_0x5219a6” 的地方:
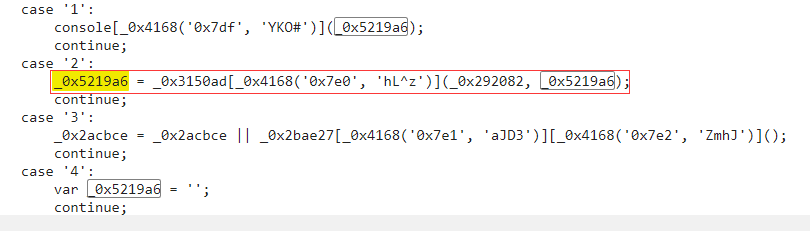
然后可以知道“_0x4168('0x7e0', 'hL^z')”的结果是"dPfhd",再找到“_0x3150ad”的定义:
因而得到“_0x3150ad[_0x4168('0x7e0', 'hL^z')]”对应的结果为:
function _0x242913(_0x3e2093, _0xbed53d) {return _0x3e2093(_0xbed53d);}
经过查找可以知道“_0x292082”对应为 md5,加密方法在一个 JS 文件中,该文件地址为:https://taodaxiang.com/core/modules/common/statics/js/md5.min.js?ver=20190249。
那括号里的“_0x5219a6”又是什么呢?需要定位到这几段代码:
case '10':
for (var _0x125187 = 0x0; _0x3150ad[_0x4168('0x80b', 'qt7#')](_0x125187, 0x20); _0x125187++) {
_0x5219a6 += _0x3150ad[_0x4168('0x80c', 'F#Im')](_0x3150ad[_0x4168('0x80d', 'VFJz')](_0x3150ad[_0x4168('0x80e', 'TwUd')](_0x3150ad[_0x4168('0x80f', 'Uua%')](_0x55322f[_0x4168('0x810', 'E3]P')](_0x125187), _0x3150ad[_0x4168('0x811', 'B([!')](_0x3150ad[_0x4168('0x812', 'LGls')](_0x55322f[_0x4168('0x813', '28mt')](_0x125187), _0x55322f[_0x4168('0x814', 'YKO#')](_0x125187)), 0x20)), _0x3d3ded[_0x4168('0x815', '(]pS')](_0x125187)), _0x3150ad[_0x4168('0x816', 'ONTj')](_0x125187, _0x125187)), 0x9);
}
continue;
case '11':
var _0x3d3ded = _0x3150ad[_0x4168('0x817', 'yN7^')](_0x292082, _0x3150ad[_0x4168('0x818', '^^9o')](_0x3150ad[_0x4168('0x819', '#a#K')](_0x3150ad[_0x4168('0x81a', '!Ior')](_0x2acbce, _0x55322f), _0x2acbce), _0x2bae27[_0x4168('0x81b', '0!ku')]));
continue;
这里得先求“_0x3d3ded”的值,经过一番调试知道“_0x3d3ded”是通过md5加密得到的,加密的字符串的结构为:
account + 7176a337dffebf0ff2d30d65fda5af78 + account + type
最终得到的“_0x3d3ded”的值如下:
f81765c208bcc1a6892863af77bb4fae
将这个值带入前面的代码中进行运算就能得到“_0x5219a6”了,最后再用 md5 加密一下,就得到我们需要的 sign 了!
【Python3爬虫】突破反爬之应对前端反调试手段的更多相关文章
- 【Python3爬虫】反反爬之解决前端反调试问题
一.前言 在我们爬取某些网站的时候,会想要打开 DevTools 查看元素或者抓包分析,但按下 F12 的时候,却出现了下面这一幕: 此时网页暂停加载,也就没法运行代码了,直接中断掉了,难道这就能阻止 ...
- 常见的反爬措施:UA反爬和Cookie反爬
摘要:为了屏蔽这些垃圾流量,或者为了降低自己服务器压力,避免被爬虫程序影响到正常人类的使用,开发者会研究各种各样的手段,去反爬虫. 本文分享自华为云社区<Python爬虫反爬,你应该从这篇博客开 ...
- python3 爬虫教学之爬取链家二手房(最下面源码) //以更新源码
前言 作为一只小白,刚进入Python爬虫领域,今天尝试一下爬取链家的二手房,之前已经爬取了房天下的了,看看链家有什么不同,马上开始. 一.分析观察爬取网站结构 这里以广州链家二手房为例:http:/ ...
- python3爬虫-快速入门-爬取图片和标题
直接上代码,先来个爬取豆瓣图片的,大致思路就是发送请求-得到响应数据-储存数据,原理的话可以先看看这个 https://www.cnblogs.com/sss4/p/7809821.html impo ...
- python3爬虫-使用requests爬取起点小说
import requests from lxml import etree from urllib import parse import os, time def get_page_html(ur ...
- 【Python3 爬虫】14_爬取淘宝上的手机图片
现在我们想要使用爬虫爬取淘宝上的手机图片,那么该如何爬取呢?该做些什么准备工作呢? 首先,我们需要分析网页,先看看网页有哪些规律 打开淘宝网站http://www.taobao.com/ 我们可以看到 ...
- 【Python3爬虫】我爬取了七万条弹幕,看看RNG和SKT打得怎么样
一.写在前面 直播行业已经火热几年了,几个大平台也有了各自独特的“弹幕文化”,不过现在很多平台直播比赛时的弹幕都基本没法看的,主要是因为网络上的喷子还是挺多的,尤其是在观看比赛的时候,很多弹幕不是喷选 ...
- python3 [爬虫实战] selenium 爬取安居客
我们爬取的网站:https://www.anjuke.com/sy-city.html 获取的内容:包括地区名,地区链接: 安居客详情 一开始直接用requests库进行网站的爬取,会访问不到数据的, ...
- python3爬虫-通过requests爬取图虫网
import requests from fake_useragent import UserAgent from requests.exceptions import Timeout from ur ...
随机推荐
- 用户注册页的布局及js逻辑实现(正则,注册按钮)
文章地址:https://www.cnblogs.com/sandraryan/ 先写一个简单的静态页面,然后对用户输入的内容进行验证,判断输入的值是否符合规则,符合规则进行注册 先上静态页面 < ...
- 【原生JS】滑动门效果
效果图: 思路:通过每次鼠标移动至目标上使所有图片重置为初始样式再向左移动目标及其左侧每个图片隐藏部分距离即实现. HTML: <!DOCTYPE html> <html> & ...
- 前后端结合的 WAF
前言 之前介绍了一些前后端结合的中间人攻击方案.由于 Web 程序的特殊性,前端脚本的参与能大幅弥补后端的不足,从而达到传统难以实现的效果. 攻防本为一体,既然能用于攻击,类似的思路同样也可用于防御. ...
- 安装node-sass时出现的错误解决方案(Mac自用,也可以借鉴)
安装node-sass时出现一下错误: gyp ERR! configure error gyp ERR! stack Error: EACCES: permission denied, mkdir ...
- printk函数 用查询来调试
前面一节描述了 printk 是任何工作的以及怎样使用它. 没有谈到的是它的缺点. 大量使用 printk 能够显著地拖慢系统, 即便你降低 cosole_loglevel 来避免加载控制 台设备, ...
- Executor线程池的最佳线程数量计算
如果是IO密集型应用,则线程池大小设置为2N+1: 如果是CPU密集型应用,则线程池大小设置为N+1: N代表CPU的核数. 假设我的服务器是4核的,且一般进行大数据运算,cpu消耗较大,那么线程池数 ...
- C# 如何写 DEBUG 输出
本文来告诉大家一个规范,如何去写 DEBUG 的输出. 经常在代码中,需要使用 DEBUG 来输出一些奇怪的东西来进行测试.但是输出的窗口只有一个,如果有一个逗比在不停输出,那么就会让输出窗口看不到自 ...
- 个人脚手架搭建 -- charmingsong-cli
个人脚手架搭建 -- charmingsong-cli 目的 为了解决多次构建相同功能的项目,在一定程度上需要定制化以及私有化设置 设计 问题 为什么不用现成的脚手架生成? 如果利用vue或者reac ...
- 2018-4-12-win10-uwp-使用油墨输入
title author date CreateTime categories win10 uwp 使用油墨输入 lindexi 2018-04-12 14:19:58 +0800 2018-2-13 ...
- 判断移动端还是PC端
window.onload=function(){ var sUserAgent = navigator.userAgent.toLowerCase(); var bIsIpad = sUserAge ...