Update(Stage4):sparksql:第5节 SparkSQL_出租车利用率分析案例
目录:
1. 业务
2. 流程分析
3. 数据读取
5. 数据清洗
6. 行政区信息
6.1. 需求介绍
6.2. 工具介绍
6.3. 具体实现
7. 会话统计
导读
本项目是 SparkSQL 阶段的练习项目, 主要目的是夯实同学们对于 SparkSQL 的理解和使用
- 数据集
-
2013年纽约市出租车乘车记录
- 需求
-
统计出租车利用率, 到某个目的地后, 出租车等待下一个客人的间隔
1. 业务
数据集介绍
业务场景介绍
和其它业务的关联
通过项目能学到什么
- 数据集结构
-
字段 示例 示意 hack_licenseBA96DE419E711691B9445D6A6307C170执照号, 可以唯一标识一辆出租车
pickup_datetime2013-01-01 15:11:48上车时间
dropoff_datetime2013-01-01 15:18:10下车时间
pickup_longitude-73.978165上车点
pickup_latitude40.757977上车点
dropoff_longitude-73.989838下车点
dropoff_latitude40.751171下车点
其中有三个点需要注意
hack_license是出租车执照, 可以唯一标识一辆出租车pickup_datetime和dropoff_datetime分别是上车时间和下车时间, 通过这个时间, 可以获知行车时间pickup_longitude和dropoff_longitude是经度, 经度所代表的是横轴, 也就是 X 轴pickup_latitude和dropoff_latitude是纬度, 纬度所代表的是纵轴, 也就是 Y 轴
- 业务场景
-
在网约车出现之前, 出行很大一部分要靠出租车和公共交通, 所以经常会见到一些情况, 比如说从东直门打车, 告诉师傅要去昌平, 师傅可能拒载. 这种情况所凸显的是一个出租车调度的难题, 所以需要先通过数据来看到问题, 后解决问题.
所以要统计出租车利用率, 也就是有乘客乘坐的时间, 和无乘客空跑的时间比例. 这是一个理解出租车的重要指标, 影响利用率的一个因素就是目的地, 比如说, 去昌平, 可能出租车师傅不确定自己是否要空放回来, 而去国贸, 下车几分钟内, 一定能有新的顾客上车.
而统计利用率的时候, 需要用到时间数据和空间数据来进行计算, 对于时间计算来说, SparkSQL 提供了很多工具和函数可以使用, 而空间计算仍然是一个比较专业的场景, 需要使用到第三方库.
我们的需求是, 在上述的数据集中, 根据时间算出等待时间, 根据地点落地到某个区, 算出某个区的平均等待时间, 也就是这个下车地点对于出租车利用率的影响.
- 技术点和其它技术的关系
-
数据清洗
数据清洗在几乎所有类型的项目中都会遇到, 处理数据的类型, 处理空值等问题
JSON 解析
JSON解析在大部分业务系统的数据分析中都会用到, 如何读取 JSON 数据, 如何把 JSON 数据变为可以使用的对象数据地理位置信息处理
地理位置信息的处理是一个比较专业的场景, 在一些租车网站, 或者像滴滴,
Uber之类的出行服务上, 也经常会处理地理位置信息探索性数据分析
从拿到一个数据集, 明确需求以后, 如何逐步了解数据集, 如何从数据集中探索对应的内容等, 是一个数据工程师的基本素质
会话分析
会话分析用于识别同一个用户的多个操作之间的关联, 是分析系统常见的分析模式, 在电商和搜索引擎中非常常见
- 在这个小节中希望大家掌握的知识
-
SparkSQL中对于类型的处理Scala中常见的JSON解析工具GeoJson的使用
2. 流程分析
分析的步骤和角度
流程
- 分析的视角
-
理解数据集
首先要理解数据集, 要回答自己一些问题
这个数据集是否以行作为单位, 是否是
DataFrame可以处理的, 大部分情况下都是这个数据集每行记录所代表的实体对象是什么, 例如: 出租车的载客记录
表达这个实体对象的最核心字段是什么, 例如: 上下车地点和时间, 唯一标识一辆车的
License
理解需求和结果集
小学的时候, 有一次考试考的比较差, 老师在帮我分析的时候, 告诉我, 你下次要读懂题意, 再去大题, 这样不会浪费时间, 于是这个信念贯穿了我这些年的工作.
按照我对开发工作的理解, 在一开始的阶段进行一个大概的思考和面向对象的设计, 并不会浪费时间, 即使这些设计可能会占用一些时间.
对代码的追求也不会浪费时间, 把代码写好, 会减少阅读成本, 沟通成本.
对测试的追求也不会浪费时间, 因为在进行回归测试的时候, 可以尽可能的减少修改对已有代码的冲击.
所以第一点, 理解需求再动手, 绝对不会浪费时间. 第二点, 在数据分析的任务中, 如何无法理解需求, 可能根本无从动手.
我们的需求是: 出租车在某个地点的平均等待客人时间
简单来说, 结果集中应该有的列: 地点, 平均等待时间
反推每一个步骤
结果集中, 应该有的字段有两个, 一个是地点, 一个是等待时间
地点如何获知? 其实就是乘客的下车点, 但是是一个坐标, 如何得到其在哪个区? 等待时间如何获知? 其实就是上一个乘客下车, 到下一个乘客上车之间的时间, 通过这两个时间的差值便可获知
- 步骤分析
-
读取数据集
数据集很大, 所以我截取了一小部分, 大概百分之一左右, 如果大家感兴趣的话, 可以将完整数据集放在集群中, 使用集群来计算 "大数据"
清洗
数据集当中的某些列名可能使用起来不方便, 或者数据集当中某些列的值类型可能不对, 或者数据集中有可能存在缺失值, 这些都是要清洗的动机, 和理由
增加区域列
由于最终要统计的结果是按照区域作为单位, 而不是一个具体的目的地点, 所以要在数据集中增加列中放置区域信息
既然是放置行政区名字, 应该现有行政区以及其边界的信息
通过上下车的坐标点, 可以判断是否存在于某个行政区中
这些判断坐标点是否属于某个区域, 这些信息, 就是专业的领域了
按照区域, 统计司机两次营运记录之间的时间差
数据集中存在很多出租车师傅的数据, 所以如何将某个师傅的记录发往一个分区, 在这个分区上完成会话分析呢? 这也是一个需要理解的点
3. 数据读取
工程搭建
数据读取
- 工程搭建
-
创建 Maven 工程
导入 Maven 配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>cn.itcast</groupId>
<artifactId>taxi</artifactId>
<version>0.0.1</version> <properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.2.0</spark.version>
<hadoop.version>2.7.5</hadoop.version>
<slf4j.version>1.7.16</slf4j.version>
<log4j.version>1.2.17</log4j.version>
<mysql.version>5.1.35</mysql.version>
<esri.version>2.2.2</esri.version>
<json4s.version>3.6.6</json4s.version>
</properties> <dependencies>
<!-- Scala 库 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang.modules</groupId>
<artifactId>scala-xml_2.11</artifactId>
<version>1.0.6</version>
</dependency> <!-- Spark 系列包 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency> <!-- 地理位置处理库 -->
<dependency>
<groupId>com.esri.geometry</groupId>
<artifactId>esri-geometry-api</artifactId>
<version>${esri.version}</version>
</dependency> <!-- JSON 解析库 -->
<dependency>
<groupId>org.json4s</groupId>
<artifactId>json4s-native_2.11</artifactId>
<version>${json4s.version}</version>
</dependency>
<dependency>
<groupId>org.json4s</groupId>
<artifactId>json4s-jackson_2.11</artifactId>
<version>${json4s.version}</version>
</dependency> <!-- 日志相关 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
</dependencies> <build>
<sourceDirectory>src/main/scala</sourceDirectory> <plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin> <plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
</plugins> </build>
</project>创建 Scala 源码目录
src/main/scala并且设置这个目录为
Source Root
- 创建文件, 数据读取
-
Step 1: 创建文件-
创建 Spark Application 主类
cn.itcast.taxi.TaxiAnalysisRunnerpackage cn.itcast.taxi object TaxiAnalysisRunner { def main(args: Array[String]): Unit = { }
} Step 2: 数据读取-
- 数据读取之前要做两件事
-
初始化环境, 导入必备的一些包
在工程根目录中创建
dataset文件夹, 并拷贝数据集进去
- 代码如下
-
object TaxiAnalysisRunner { def main(args: Array[String]): Unit = {
// 1. 创建 SparkSession
val spark = SparkSession.builder()
.master("local[6]")
.appName("taxi")
.getOrCreate() // 2. 导入函数和隐式转换
import spark.implicits._
import org.apache.spark.sql.functions._ // 3. 读取文件
val taxiRaw = spark.read
.option("header", value = true)
.csv("dataset/half_trip.csv") taxiRaw.show()
taxiRaw.printSchema()
}
} - 运行结果如下
-
root
|-- medallion: string (nullable = true)
|-- hack_license: string (nullable = true)
|-- vendor_id: string (nullable = true)
|-- rate_code: string (nullable = true)
|-- store_and_fwd_flag: string (nullable = true)
|-- pickup_datetime: string (nullable = true)
|-- dropoff_datetime: string (nullable = true)
|-- passenger_count: string (nullable = true)
|-- trip_time_in_secs: string (nullable = true)
|-- trip_distance: string (nullable = true)
|-- pickup_longitude: string (nullable = true)
|-- pickup_latitude: string (nullable = true)
|-- dropoff_longitude: string (nullable = true)
|-- dropoff_latitude: string (nullable = true)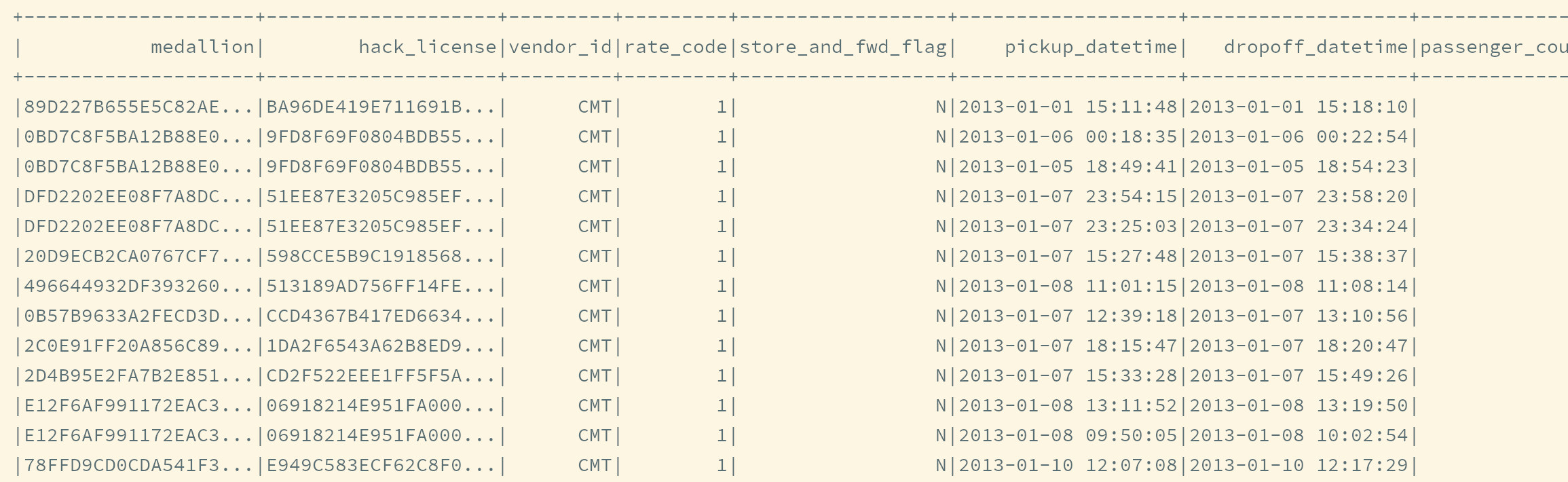
- 下一步
-
剪去多余列
现在数据集中包含了一些多余的列, 在后续的计算中并不会使用到, 如果让这些列参与计算的话, 会影响整体性能, 浪费集群资源
类型转换
可以看到, 现在的数据集中, 所有列类型都是
String, 而在一些统计和运算中, 不能使用String来进行, 所以要将这些数据转为对应的类型
5. 数据清洗
将
Row对象转为Trip处理转换过程中的报错
- 数据转换
通过 DataFrameReader 读取出来的数据集是 DataFrame, 而 DataFrame 中保存的是 Row 对象, 但是后续我们在进行处理的时候可能要使用到一些有类型的转换, 也需要每一列数据对应自己的数据类型, 所以, 需要将 Row 所代表的弱类型对象转为 Trip这样的强类型对象, 而 Trip 对象则是一个样例类, 用于代表一个出租车的行程
Step 1: 创建Trip样例类-
Trip是一个强类型的样例类, 一个Trip对象代表一个出租车行程, 使用Trip可以对应数据集中的一条记录object TaxiAnalysisRunner { def main(args: Array[String]): Unit = {
// 此处省略 Main 方法中内容
} } /**
* 代表一个行程, 是集合中的一条记录
* @param license 出租车执照号
* @param pickUpTime 上车时间
* @param dropOffTime 下车时间
* @param pickUpX 上车地点的经度
* @param pickUpY 上车地点的纬度
* @param dropOffX 下车地点的经度
* @param dropOffY 下车地点的纬度
*/
case class Trip(
license: String,
pickUpTime: Long,
dropOffTime: Long,
pickUpX: Double,
pickUpY: Double,
dropOffX: Double,
dropOffY: Double
) Step 2: 将Row对象转为Trip对象, 从而将DataFrame转为Dataset[Trip]-
首先应该创建一个新方法来进行这种转换, 毕竟是一个比较复杂的转换操作, 不能怠慢
object TaxiAnalysisRunner { def main(args: Array[String]): Unit = {
// ... 省略数据读取 // 4. 数据转换和清洗
val taxiParsed = taxiRaw.rdd.map(parse)
} /**
* 将 Row 对象转为 Trip 对象, 从而将 DataFrame 转为 Dataset[Trip] 方便后续操作
* @param row DataFrame 中的 Row 对象
* @return 代表数据集中一条记录的 Trip 对象
*/
def parse(row: Row): Trip = { }
} case class Trip(...) Step 3: 创建Row对象的包装类型-
因为在针对
Row类型对象进行数据转换时, 需要对一列是否为空进行判断和处理, 在Scala中为空的处理进行一些支持和封装, 叫做Option, 所以在读取Row类型对象的时候, 要返回Option对象, 通过一个包装类, 可以轻松做到这件事创建一个类
RichRow用以包装Row类型对象, 从而实现getAs的时候返回Option对象object TaxiAnalysisRunner { def main(args: Array[String]): Unit = {
// ... // 4. 数据转换和清洗
val taxiParsed = taxiRaw.rdd.map(parse)
} def parse(row: Row): Trip = {...} } case class Trip(...) class RichRow(row: Row) { def getAs[T](field: String): Option[T] = {
if (row.isNullAt(row.fieldIndex(field)) || StringUtils.isBlank(row.getAs[String](field))) {
None
} else {
Some(row.getAs[T](field))
}
}
} Step 4: 转换-
流程已经存在, 并且也已经为空值处理做了支持, 现在就可以进行转换了
首先根据数据集的情况会发现, 有如下几种类型的信息需要处理
字符串类型
执照号就是字符串类型, 对于字符串类型, 只需要判断空, 不需要处理, 如果是空字符串, 加入数据集的应该是一个
null时间类型
上下车时间就是时间类型, 对于时间类型需要做两个处理
转为时间戳, 比较容易处理
如果时间非法或者为空, 则返回
0L
Double类型上下车的位置信息就是
Double类型,Double类型的数据在数据集中以String的形式存在, 所以需要将String类型转为Double类型
总结来看, 有两类数据需要特殊处理, 一类是时间类型, 一类是
Double类型, 所以需要编写两个处理数据的帮助方法, 后在parse方法中收集为Trip类型对象object TaxiAnalysisRunner { def main(args: Array[String]): Unit = {
// ... // 4. 数据转换和清洗
val taxiParsed = taxiRaw.rdd.map(parse)
} def parse(row: Row): Trip = {
// 通过使用转换方法依次转换各个字段数据
val row = new RichRow(row)
val license = row.getAs[String]("hack_license").orNull
val pickUpTime = parseTime(row, "pickup_datetime")
val dropOffTime = parseTime(row, "dropoff_datetime")
val pickUpX = parseLocation(row, "pickup_longitude")
val pickUpY = parseLocation(row, "pickup_latitude")
val dropOffX = parseLocation(row, "dropoff_longitude")
val dropOffY = parseLocation(row, "dropoff_latitude") // 创建 Trip 对象返回
Trip(license, pickUpTime, dropOffTime, pickUpX, pickUpY, dropOffX, dropOffY)
} /**
* 将时间类型数据转为时间戳, 方便后续的处理
* @param row 行数据, 类型为 RichRow, 以便于处理空值
* @param field 要处理的时间字段所在的位置
* @return 返回 Long 型的时间戳
*/
def parseTime(row: RichRow, field: String): Long = {
val pattern = "yyyy-MM-dd HH:mm:ss"
val formatter = new SimpleDateFormat(pattern, Locale.ENGLISH) val timeOption = row.getAs[String](field)
timeOption.map( time => formatter.parse(time).getTime )
.getOrElse(0L)
} /**
* 将字符串标识的 Double 数据转为 Double 类型对象
* @param row 行数据, 类型为 RichRow, 以便于处理空值
* @param field 要处理的 Double 字段所在的位置
* @return 返回 Double 型的时间戳
*/
def parseLocation(row: RichRow, field: String): Double = {
row.getAs[String](field).map( loc => loc.toDouble ).getOrElse(0.0D)
}
} case class Trip(..) class RichRow(row: Row) {...}
- 异常处理
-
在进行类型转换的时候, 是一个非常容易错误的点, 需要进行单独的处理
Step 1: 思路-
parse方法应该做的事情应该有两件捕获异常
异常一定是要捕获的, 无论是否要抛给
DataFrame, 都要先捕获一下, 获知异常信息捕获要使用
try … catch …代码块返回结果
返回结果应该分为两部分来进行说明
正确, 正确则返回数据
错误, 则应该返回两类信息, 一 告知外面哪个数据出了错, 二 告知错误是什么
对于这种情况, 可以使用
Scala中提供的一个类似于其它语言中多返回值的Either.Either分为两个情况, 一个是Left, 一个是Right, 左右两个结果所代表的意思可有由用户来指定val process = (b: Double) => {
val a = 10.0
a / b
} def safe(function: Double => Double, b: Double): Either[Double, (Double, Exception)] = {
try {
val result = function(b)
Left(result)
} catch {
case e: Exception => Right(b, e)
}
} val result = safe(process, 0) result match {
case Left(r) => println(r)
case Right((b, e)) => println(b, e)
}一个函数, 接收一个参数, 根据参数进行除法运算 一个方法, 作用是让 process函数调用起来更安全, 在其中catch错误, 报错后返回足够的信息 (报错时的参数和报错信息)正常时返回 Left, 放入正确结果异常时返回 Right, 放入报错时的参数, 和报错信息外部调用 处理调用结果, 如果是 Right 的话, 则可以进行响应的异常处理和弥补 Either和Option比较像, 都是返回不同的情况, 但是Either的Right可以返回多个值, 而None不行如果一个
Either有两个结果的可能性, 一个是Left[L], 一个是Right[R], 则Either的范型是Either[L, R] Step 2: 完成代码逻辑-
加入一个 Safe 方法, 更安全
object TaxiAnalysisRunner { def main(args: Array[String]): Unit = {
// ... // 4. 数据转换和清洗
val taxiParsed = taxiRaw.rdd.map(safe(parse))
} /**
* 包裹转换逻辑, 并返回 Either
*/
def safe[P, R](f: P => R): P => Either[R, (P, Exception)] = {
new Function[P, Either[R, (P, Exception)]] with Serializable {
override def apply(param: P): Either[R, (P, Exception)] = {
try {
Left(f(param))
} catch {
case e: Exception => Right((param, e))
}
}
}
} def parse(row: Row): Trip = {...} def parseTime(row: RichRow, field: String): Long = {...} def parseLocation(row: RichRow, field: String): Double = {...}
} case class Trip(..) class RichRow(row: Row) {...} Step 3: 针对转换异常进行处理-
对于
Either来说, 可以获取Left中的数据, 也可以获取Right中的数据, 只不过如果当Either是一个 Right 实例时候, 获取Left的值会报错所以, 针对于
Dataset[Either]可以有如下步骤试运行, 观察是否报错
如果报错, 则打印信息解决报错
如果解决不了, 则通过
filter过滤掉Right如果没有报错, 则继续向下运行
object TaxiAnalysisRunner { def main(args: Array[String]): Unit = {
... // 4. 数据转换和清洗
val taxiParsed = taxiRaw.rdd.map(safe(parse))
val taxiGood = taxiParsed.map( either => either.left.get ).toDS()
} ...
} ...很幸运, 在运行上面的代码时, 没有报错, 如果报错的话, 可以使用如下代码进行过滤
object TaxiAnalysisRunner { def main(args: Array[String]): Unit = {
... // 4. 数据转换和清洗
val taxiParsed = taxiRaw.rdd.map(safe(parse))
val taxiGood = taxiParsed.filter( either => either.isLeft )
.map( either => either.left.get )
.toDS()
} ...
} ...
- 观察数据集的时间分布
-
观察数据分布常用手段是直方图, 直方图反应的是数据的
"数量"分布
通过这个图可以看到其实就是乘客年龄的分布, 横轴是乘客的年龄, 纵轴是乘客年龄的频数分布
因为我们这个项目中要对出租车利用率进行统计, 所以需要先看一看单次行程的时间分布情况, 从而去掉一些异常数据, 保证数据是准确的
绘制直方图的 "图" 留在后续的
DMP项目中再次介绍, 现在先准备好直方图所需要的数据集, 通过数据集来观察即可, 直方图需要的是两个部分的内容, 一个是数据本身, 另外一个是数据的分布, 也就是频数的分布, 步骤如下计算每条数据的时长, 但是单位要有变化, 按照分钟, 或者小时来作为时长单位
统计每个时长的数据量, 例如有
500个行程是一小时内完成的, 有300个行程是1 - 2小时内完成
- 统计时间分布直方图
-
- 使用
UDF的优点和代价 -
UDF是一个很好用的东西, 特别好用, 对整体的逻辑实现会变得更加简单可控, 但是有两个非常明显的缺点, 所以在使用的时候要注意, 虽然有这两个缺点, 但是只在必要的地方使用就没什么问题, 对于逻辑的实现依然是有很大帮助的UDF中, 对于空值的处理比较麻烦例如一个
UDF接收两个参数, 是Scala中的Int类型和Double类型, 那么, 在传入UDF参数的时候, 如果有数据为null, 就会出现转换异常使用
UDF的时候, 优化器可能无法对其进行优化UDF对于Catalyst是不透明的,Catalyst不可获知UDF中的逻辑, 但是普通的Function对于Catalyst是透明的,Catalyst可以对其进行优化
Step 1: 编写UDF, 将行程时长由毫秒单位改为小时单位-
定义
UDF, 在UDF中做两件事计算行程时长
将时长由毫秒转为分钟
object TaxiAnalysisRunner { def main(args: Array[String]): Unit = {
... // 5. 过滤行程无效的数据
val hours = (pickUp: Long, dropOff: Long) => {
val duration = dropOff - pickUp
TimeUnit.HOURS.convert(, TimeUnit.MILLISECONDS)
}
val hoursUDF = udf(hours)
} ...
} Step 2:统计时长分布-
第一步应该按照行程时长进行分组
求得每个分组的个数
最后按照时长排序并输出结果
object TaxiAnalysisRunner { def main(args: Array[String]): Unit = {
... // 5. 过滤行程无效的数据
val hours = (pickUp: Long, dropOff: Long) => {
val duration = dropOff - pickUp
TimeUnit.MINUTES.convert(, TimeUnit.MILLISECONDS)
}
val hoursUDF = udf(hours) taxiGood.groupBy(hoursUDF($"pickUpTime", $"dropOffTime").as("duration"))
.count()
.sort("duration")
.show()
} ...
}会发现, 大部分时长都集中在
1 - 19分钟内+--------+-----+
|duration|count|
+--------+-----+
| 0| 86|
| 1| 140|
| 2| 383|
| 3| 636|
| 4| 759|
| 5| 838|
| 6| 791|
| 7| 761|
| 8| 688|
| 9| 625|
| 10| 537|
| 11| 499|
| 12| 395|
| 13| 357|
| 14| 353|
| 15| 264|
| 16| 252|
| 17| 197|
| 18| 181|
| 19| 136|
+--------+-----+ Step 3:注册函数, 在 SQL 表达式中过滤数据-
大部分时长都集中在
1 - 19分钟内, 所以这个范围外的数据就可以去掉了, 如果同学使用完整的数据集, 会发现还有一些负的时长, 好像是回到未来的场景一样, 对于这种非法的数据, 也要过滤掉, 并且还要分析原因object TaxiAnalysisRunner { def main(args: Array[String]): Unit = {
... // 5. 过滤行程无效的数据
val hours = (pickUp: Long, dropOff: Long) => {
val duration = dropOff - pickUp
TimeUnit.MINUTES.convert(, TimeUnit.MILLISECONDS)
}
val hoursUDF = udf(hours) taxiGood.groupBy(hoursUDF($"pickUpTime", $"dropOffTime").as("duration"))
.count()
.sort("duration")
.show() spark.udf.register("hours", hours)
val taxiClean = taxiGood.where("hours(pickUpTime, dropOffTime) BETWEEN 0 AND 3")
taxiClean.show()
} ...
}
- 使用
6. 行政区信息
- 目标和步骤
-
- 目标
-
能够通过
GeoJSON判断一个点是否在一个区域内, 能够使用JSON4S解析JSON数据 - 步骤
-
需求介绍
工具介绍
解析
JSON读取
Geometry
- 总结
-
整体流程
JSON4S 介绍
ESRI 介绍
编写函数实现
经纬度 → Geometry转换
后续可以使用函数来进行转换, 并且求得时间差
6.1. 需求介绍
- 目标和步骤
-
- 目标
-
理解表示地理位置常用的 GeoJSON
- 步骤
-
思路整理
GeoJSON是什么GeoJSON的使用
- 思路整理
-
需求
项目的任务是统计出租车在不同行政区的平均等待时间, 所以源数据集和经过计算希望得到的新数据集大致如下
源数据集
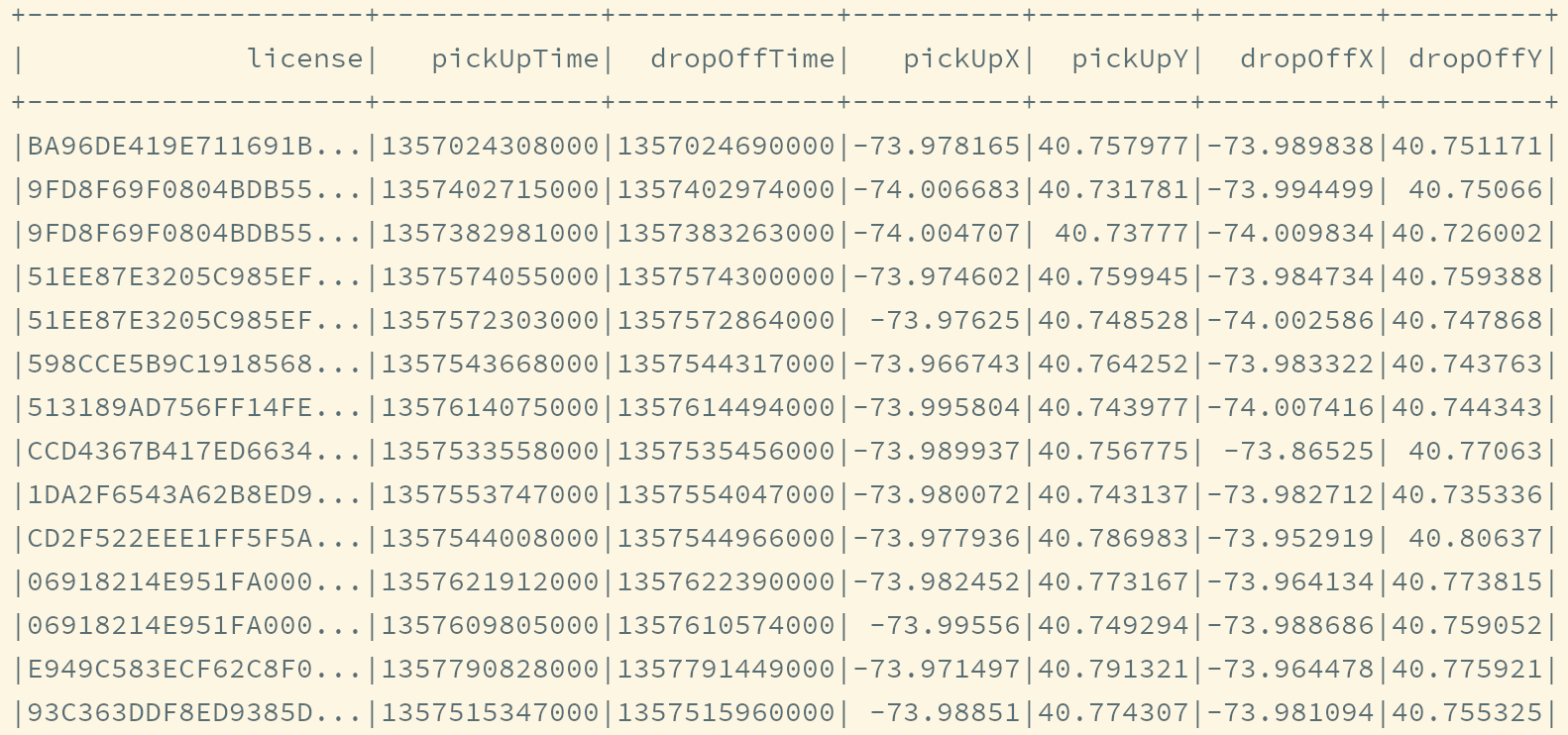
目标数据集

目标数据集分析
目标数据集中有三列,
borough,avg(seconds),stddev_samp(seconds)borough表示目的地行政区的名称avg(seconds)和stddev_samp(seconds)是seconds的聚合,seconds是下车时间和下一次上车时间之间的差值, 代表等待时间
所以有两列数据是现在数据集中没有
borough要根据数据集中的经纬度, 求出其行政区的名字seconds要根据数据集中上下车时间, 求出差值
步骤
求出
borough读取行政区位置信息
搜索每一条数据的下车经纬度所在的行政区
在数据集中添加行政区列
求出
seconds根据
borough计算平均等待时间, 是一个聚合操作
- GeoJSON 是什么
-
定义
GeoJSON是一种基于JSON的开源标准格式, 用来表示地理位置信息其中定了很多对象, 表示不同的地址位置单位
如何表示地理位置
类型 例子 点

{
"type": "Point",
"coordinates": [30, 10]
}线段

{
"type": "Point",
"coordinates": [30, 10]
}多边形
{
"type": "Point",
"coordinates": [30, 10]
}
{
"type": "Polygon",
"coordinates": [
[[35, 10], [45, 45], [15, 40], [10, 20], [35, 10]],
[[20, 30], [35, 35], [30, 20], [20, 30]]
]
}数据集
行政区范围可以使用
GeoJSON中的多边形来表示课程中为大家提供了一份表示了纽约的各个行政区范围的数据集, 叫做
nyc-borough-boundaries-polygon.geojson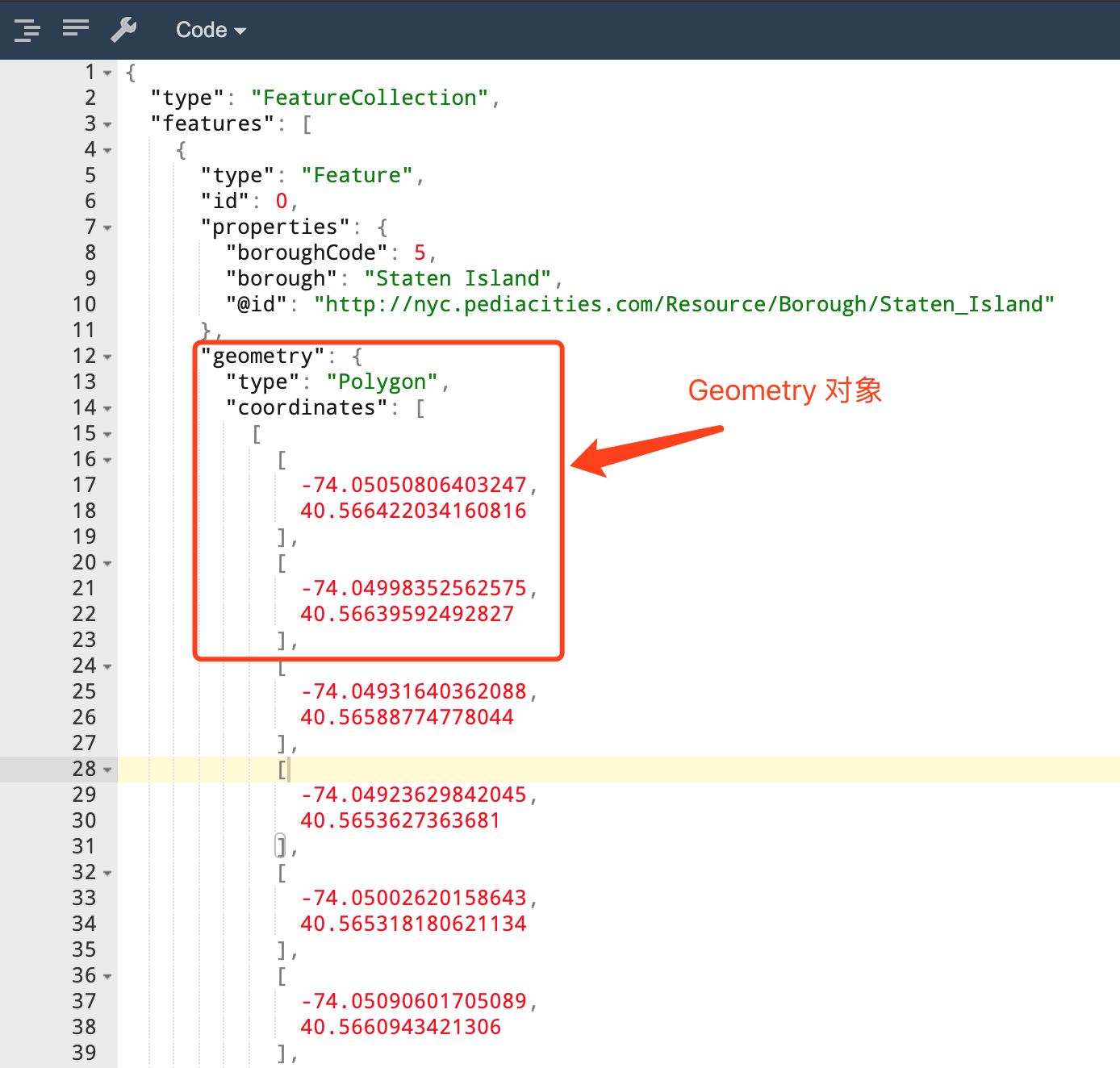
使用步骤
创建一个类型
Feature, 对应JSON文件中的格式通过解析
JSON, 创建Feature对象通过
Feature对象创建GeoJSON表示一个地理位置的Geometry对象通过
Geometry对象判断一个经纬度是否在其范围内
- 总结
-
思路
从需求出发, 设计结果集
推导结果集所欠缺的字段
补齐欠缺的字段, 生成结果集, 需求完成
后续整体上要做的事情
需求是查看出租车在不同行政区的等待客人的时间
需要补充两个点, 一是出租车下客点的行政区名称, 二是等待时间
本章节聚焦于行政区的信息补充
学习步骤
介绍
JSON解析的工具介绍读取
GeoJSON的工具JSON解析读取
GeoJSON
6.2. 工具介绍
- 目标和步骤
-
- 目标
-
理解
JSON解析和Geometry解析所需要的工具, 后续使用这些工具补充行政区信息 - 步骤
-
JSON4SESRI Geometry
- JSON4S 介绍
-
介绍
一般在
Java中, 常使用如下三个工具解析JSONGsonGoogle开源的JSON解析工具, 比较人性化, 易于使用, 但是性能不如Jackson, 也不如Jackson有积淀JacksonJackson是功能最完整的JSON解析工具, 也是最老牌的JSON解析工具, 性能也足够好, 但是API在一开始支持的比较少, 用起来稍微有点繁琐FastJson阿里巴巴的
JSON开源解析工具, 以快著称, 但是某些方面用起来稍微有点反直觉
什么是
JSON解析
读取
JSON数据的时候, 读出来的是一个有格式的字符串, 将这个字符串转换为对象的过程就叫做解析可以使用
JSON4S来解析JSON,JSON4S是一个其它解析工具的Scala封装以适应Scala的对象转换JSON4S支持Jackson作为底层的解析工具
Step 1: 导入
Maven依赖<!-- JSON4S -->
<dependency>
<groupId>org.json4s</groupId>
<artifactId>json4s-native_2.11</artifactId>
<version>${json4s.version}</version>
</dependency>
<!-- JSON4S 的 Jackson 集成库 -->
<dependency>
<groupId>org.json4s</groupId>
<artifactId>json4s-jackson_2.11</artifactId>
<version>${json4s.version}</version>
</dependency>Step 2: 解析
JSON- 步骤
-
解析
JSON对象序列化
JSON对象使用
Jackson反序列化Scala对象使用
Jackson序列化Scala对象
- 代码
-
import org.json4s._
import org.json4s.jackson.JsonMethods._
import org.json4s.jackson.Serialization.{read, write} case class Product(name: String, price: Double) val product =
"""
|{"name":"Toy","price":35.35}
""".stripMargin // 可以解析 JSON 为对象
val obj: Product = parse(product).extra[Product] // 可以将对象序列化为 JSON
val str: String = compact(render(Product("电视", 10.5))) // 使用序列化 API 之前, 要先导入代表转换规则的 formats 对象隐式转换
implicit val formats = Serialization.formats(NoTypeHints) // 可以使用序列化的方式来将 JSON 字符串反序列化为对象
val obj1 = read[Person](product) // 可以使用序列化的方式将对象序列化为 JSON 字符串
val str1 = write(Product("电视", 10.5))
- GeoJSON 读取工具的介绍
-
介绍
读取
GeoJSON的工具有很多, 但是大部分都过于复杂, 有一些只能Java中用有一个较为简单, 也没有使用底层
C语言开发的解析GeoJSON的类库叫做ESRI Geometry,Scala中也可以支持
使用
ESRI Geometry的使用比较的简单, 大致就如下这样调用即可val mg = GeometryEngine.geometryFromGeoJson(jsonStr, 0, Geometry.Type.Unknown)
val geometry = mg.getGeometry GeometryEngine.contains(geometry, other, csr)读取 JSON生成Geometry对象重点: 一个 Geometry对象就表示一个GeoJSON支持的对象, 可能是一个点, 也可能是一个多边形判断一个 Geometry中是否包含另外一个Geometry
- 总结
-
JSON解析FastJSON和Gson直接在Scala中使用会出现问题, 因为Scala的对象体系和Java略有不同最为适合
Scala的方式是使用JSON4S作为上层API,Jackson作为底层提供JSON解析能力, 共同实现JSON解析其使用方式非常简单, 两行即可解析
implicit val formats = Serialization.formats(NoTypeHints)
val obj = read[Person](product)GeoJSON的解析有一个很适合 Scala 的 GeoJSON 解析工具, 叫做
ESRI Geometry, 其可以将 GeoJSON 字符串转为 Geometry 对象, 易于使用
GeometryEngine.geometryFromGeoJson(jsonStr, 0, Geometry.Type.Unknown)后续工作
读取行政区的数据集, 解析
JSON格式, 将JSON格式的字符串转为对象使用
ESRI的GeometryEngine读取行政区的Geometry对象的JSON字符串, 生成Geometry对象使用上车点和下车点的坐标创建
Point对象 (Geometry的子类)判断
Point是否在行政区的Geometry的范围内 (行政区的Geometry其实本质上是子类Polygon的对象)
6.3. 具体实现
- 目标和步骤
-
- 目标
-
通过
JSON4S和ESRI配合解析提供的GeoJSON数据集, 获取纽约的每个行政区的范围 - 步骤
-
解析
JSON使用
ESRI生成表示行政区的一组Geometry对象
- 解析 JSON
-
步骤
对照
JSON中的格式, 创建解析的目标类解析
JSON数据转为目标类的对象读取数据集, 执行解析
Step 1: 创建目标类
GeoJSON{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"id": 0,
"properties": {
"boroughCode": 5,
"borough": "Staten Island",
"@id": "http:\/\/nyc.pediacities.com\/Resource\/Borough\/Staten_Island"
},
"geometry": {
"type": "Polygon",
"coordinates": [
[
[-74.050508064032471, 40.566422034160816],
[-74.049983525625748, 40.566395924928273]
]
]
}
}
]
}features是一个数组, 其中每一个Feature代表一个行政区目标类
case class FeatureCollection(
features: List[Feature]
) case class Feature(
id: Int,
properties: Map[String, String],
geometry: JObject
) case class FeatureProperties(boroughCode: Int, borough: String)
Step 2: 将
JSON字符串解析为目标类对象创建工具类实现功能
object FeatureExtraction { def parseJson(json: String): FeatureCollection = {
implicit val format: AnyRef with Formats = Serialization.formats(NoTypeHints)
val featureCollection = read[FeatureCollection](json)
featureCollection
}
}Step 3: 读取数据集, 转换数据
val geoJson = Source.fromFile("dataset/nyc-borough-boundaries-polygon.geojson").mkString
val features = FeatureExtraction.parseJson(geoJson)
- 解析 GeoJSON
-
步骤
转换
JSON为Geometry对象
表示行政区的 JSON 段在哪
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"id": 0,
"properties": {
"boroughCode": 5,
"borough": "Staten Island",
"@id": "http:\/\/nyc.pediacities.com\/Resource\/Borough\/Staten_Island"
},
"geometry": {
"type": "Polygon",
"coordinates": [
[
[-74.050508064032471, 40.566422034160816],
[-74.049983525625748, 40.566395924928273]
]
]
}
}
]
}geometry段即是Geometry对象的JSON表示通过
ESRI解析此段case class Feature(
id: Int,
properties: Map[String, String],
geometry: JObject
) { def getGeometry: Geometry = {
GeometryEngine.geoJsonToGeometry(compact(render(geometry)), 0, Geometry.Type.Unknown).getGeometry
}
}geometry对象需要使用ESRI解析并生成, 所以此处并没有使用具体的对象类型, 而是使用JObject表示一个JsonObject, 并没有具体的解析为某个对象, 节省资源将 JSON转为Geometry对象
- 在出租车 DataFrame 中增加行政区信息
-
步骤
将
Geometry数据集按照区域大小排序广播
Geometry信息, 发给每一个Executor创建
UDF, 通过经纬度获取行政区信息统计行政区信息
Step 1: 排序
Geometry动机: 后续需要逐个遍历
Geometry对象, 取得每条出租车数据所在的行政区, 大的行政区排在前面效率更好一些
val areaSortedFeatures = features.features.sortBy(feature => {
(feature.properties("boroughCode"), - feature.getGeometry.calculateArea2D())
})Step 2: 发送广播
动机:
Geometry对象数组相对来说是一个小数据集, 后续需要使用Spark来进行计算, 将Geometry分发给每一个Executor会显著减少IO通量
val featuresBc = spark.sparkContext.broadcast(areaSortedFeatures)Step 3: 创建
UDF动机: 创建 UDF, 接收每个出租车数据的下车经纬度, 转为行政区信息, 以便后续实现功能
val boroughLookUp = (x: Double, y: Double) => {
val features: Option[Feature] = featuresBc.value.find(feature => {
GeometryEngine.contains(feature.getGeometry, new Point(x, y), SpatialReference.create(4326))
})
features.map(feature => {
feature.properties("borough")
}).getOrElse("NA")
} val boroughUDF = udf(boroughLookUp)Step 4: 测试转换结果, 统计每个行政区的出租车数据数量
动机: 写完功能最好先看看, 运行一下
taxiClean.groupBy(boroughUDF('dropOffX, 'dropOffY))
.count()
.show()
- 总结
-
具体的实现分为两个大步骤
解析
JSON生成Geometry数据通过
Geometry数据, 取得每一条出租车数据的行政区信息
Geometry数据的生成又有如下步骤使用
JSON4S解析行政区区域信息的数据集取得其中每一个行政区信息的
Geometry区域信息, 转为ESRI的Geometry对象
查询经纬度信息, 获取其所在的区域, 有如下步骤
遍历
Geometry数组, 搜索经纬度所表示的Point对象在哪个区域内返回区域的名称
使用
UDF的目的是为了统计数据集, 后续会通过函数直接完成功能
7. 会话统计
- 目标和步骤
-
- 目标
-
统计每个行政区的所有行程, 查看每个行政区平均等候客人的时间
掌握会话统计的方式方法
- 步骤
-
会话统计的概念
功能实现
- 会话统计的概念
-
需求分析
需求
统计每个行政区的平均等客时间
需求可以拆分为如下几个步骤
按照行政区分组
在每一个行政区中, 找到同一个出租车司机的先后两次订单, 本质就是再次针对司机的证件号再次分组
求出这两次订单的下车时间和上车时间只差, 便是等待客人的时间
针对一个行政区, 求得这个时间的平均数
问题: 分组效率太低
分组的效率相对较低
分组是
Shuffle两次分组, 包括后续的计算, 相对比较复杂
解决方案: 分区后在分区中排序
按照
License重新分区, 如此一来, 所有相同的司机的数据就会在同一个分区中计算分区中连续两条数据的时间差
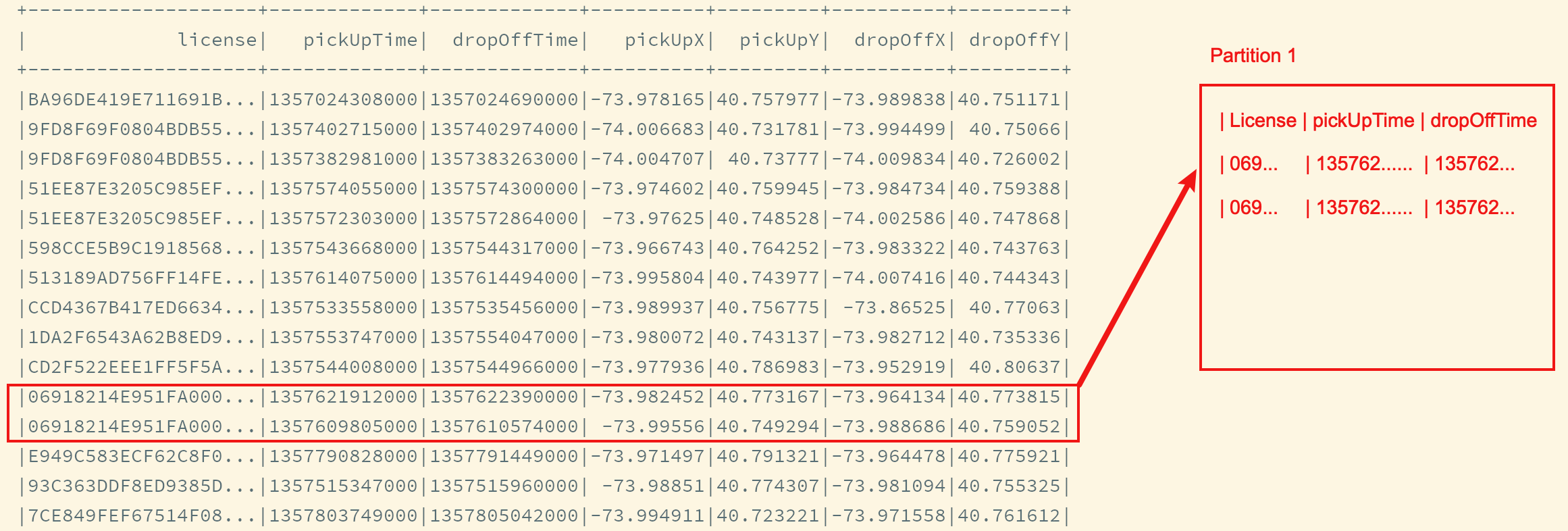
上述的计算存在一个问题, 一个分组会有多个司机的数据, 如何划分每个司机的数据边界? 其实可以先过滤一下, 计算时只保留同一个司机的数据 无论是刚才的多次分组, 还是后续的分区, 都是要找到每个司机的会话, 通过会话来完成功能, 也叫做会话分析
- 功能实现
-
步骤
过滤掉没有经纬度的数据
按照
License重新分区并按照License和pickUpTime排序求得每个司机的下车和下次上车的时间差
求得每个行政区得统计数据
Step 1: 过滤没有经纬度的数据
val taxiDone = taxiClean.where("dropOffX != 0 and dropOffY != 0 and pickUpX != 0 and pickUpY != 0")Step 2: 划分会话
val sessions = taxiDone.repartition('license)
.sortWithinPartitions('license, 'pickUpTime)Step 3: 求得时间差
处理每个分区, 通过
Scala的API找到相邻的数据sessions.mapPartitions(trips => {
val viter = trips.sliding(2)
})过滤司机不同的相邻数据
sessions.mapPartitions(trips => {
val viter = trips.sliding(2)
.filter(_.size == 2)
.filter(p => p.head.license == p.last.license)
})求得时间差
def boroughDuration(t1: Trip, t2: Trip): (String, Long) = {
val borough = boroughLookUp(t1.dropOffX, t1.dropOffY)
val duration = (t2.pickUpTime - t1.dropOffTime) / 1000
(borough, duration)
} val boroughDurations = sessions.mapPartitions(trips => {
val viter = trips.sliding(2)
.filter(_.size == 2)
.filter(p => p.head.license == p.last.license)
viter.map(p => boroughDuration(p.head, p.last))
}).toDF("borough", "seconds")
Step 4: 统计数据
boroughDurations.where("seconds > 0")
.groupBy("borough")
.agg(avg("seconds"), stddev("seconds"))
.show()
- 总结
-
其实会话分析的难点就是理解需求
需求是找到每个行政区的待客时间, 就是按照行政区分组
需求是找到待客时间, 就是按照司机进行分组, 并且还要按照时间进行排序, 才可找到一个司机相邻的两条数据
但是分组和统计的效率较低
可以把相同司机的所有形成发往一个分区
然后按照司机的
License和上车时间综合排序这样就可以找到同一个司机的两次行程之间的差值
Update(Stage4):sparksql:第5节 SparkSQL_出租车利用率分析案例的更多相关文章
- Update(Stage4):sparksql:第3节 Dataset (DataFrame) 的基础操作 & 第4节 SparkSQL_聚合操作_连接操作
8. Dataset (DataFrame) 的基础操作 8.1. 有类型操作 8.2. 无类型转换 8.5. Column 对象 9. 缺失值处理 10. 聚合 11. 连接 8. Dataset ...
- Update(Stage4):sparksql:第1节 SparkSQL_使用场景_优化器_Dataset & 第2节 SparkSQL读写_hive_mysql_案例
目标 SparkSQL 是什么 SparkSQL 如何使用 Table of Contents 1. SparkSQL 是什么 1.1. SparkSQL 的出现契机 1.2. SparkSQL 的适 ...
- Update(Stage4):spark_rdd算子:第2节 RDD_action算子_分区_缓存:缓存、Checkpoint
4. 缓存 概要 缓存的意义 缓存相关的 API 缓存级别以及最佳实践 4.1. 缓存的意义 使用缓存的原因 - 多次使用 RDD 需求: 在日志文件中找到访问次数最少的 IP 和访问次数最多的 IP ...
- Update(Stage4):spark_rdd算子:第2节 RDD_action算子_分区_缓存:算子和分区
一.reduce和reduceByKey: 二.:RDD 的算子总结 RDD 的算子大部分都会生成一些专用的 RDD map, flatMap, filter 等算子会生成 MapPartitions ...
- Update(Stage4):spark_rdd算子:第1节 RDD_定义_转换算子:深入RDD
一. 二.案例:详见代码.针对案例提出的6个问题: 假设要针对整个网站的历史数据进行处理, 量有 1T, 如何处理? 放在集群中, 利用集群多台计算机来并行处理 如何放在集群中运行? 简单来讲, 并行 ...
- Update(Stage4):Structured Streaming_介绍_案例
1. 回顾和展望 1.1. Spark 编程模型的进化过程 1.2. Spark 的 序列化 的进化过程 1.3. Spark Streaming 和 Structured Streaming 2. ...
- Update(Stage4):Spark原理_运行过程_高级特性
如何判断宽窄依赖: =================================== 6. Spark 底层逻辑 导读 从部署图了解 Spark 部署了什么, 有什么组件运行在集群中 通过对 W ...
- Update(Stage4):Spark Streaming原理_运行过程_高级特性
Spark Streaming 导读 介绍 入门 原理 操作 Table of Contents 1. Spark Streaming 介绍 2. Spark Streaming 入门 2. 原理 3 ...
- Update(Stage4):scala补充知识
1.惰性加载: 在企业的大数据开发中,有时候会编写非常复杂的SQL语句,这些SQL语句可能有几百行甚至上千行.这些SQL语句,如果直接加载到JVM中,会有很大的内存开销.如何解决? 当有一些变量保存的 ...
随机推荐
- 【做题笔记】UVA11988破损的键盘
本题可以在洛谷评测,但需要绑定账号 首先解释一下:Home键的作用是把光标移动,End键的作用是返回上次按Home键的地方 考虑朴素做法:输入为[时下一次插入在数组最前端,然后元素整体向后:同时令 l ...
- jmeter+influxdb+granfana+collectd监控cpu+mem+TPS
1.安装grafana #####gafana过期安装包安装报错 Error unpacking rpm package grafana-5.1.4-1.x86_64error: unpacking ...
- docker为镜像添加SSH服务
启动并进入容器中 这里用db1容器完成实验. 安装openssh服务和修改sshd配置文件 安装openssh yum install openssh-server openssh-clients - ...
- 快捷键(二):VSCode
1,打开命令板:F1或Ctrl+Chift+P 2,新建文件:Ctrl+N 3,文件间切换:Ctrl+Tab 4,新开界面:Ctrl+Shift+N 5,关闭当前窗口:Ctrl+W 6,关闭界面:Ct ...
- vue项目依赖的安装
npm install element-ui --save npm install vuex --save npm install axios --save npm install moment ...
- SQL过滤条件on和where
在使用left jion时,会生成一张中间的临时表,然后再将这张临时表返回给用户. on和where条件的区别如下:1. on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表 ...
- MSYS2与mingw32和mingw64的安装
由于编译OpenBLAS接触到MSYS2. 下载MSYS:https://mirror.tuna.tsinghua.edu.cn/help/msys2/ 安装,并按照下面的配置,然后可以安装mingw ...
- React的React.createContext()源码解析(四)
一.产生context原因 从父组件直接传值到孙子组件,而不必一层一层的通过props进行传值,相比较以前的那种传值更加的方便.简介. 二.context的两种实现方式 1.老版本(React16.x ...
- Java面向对象编程 -6.6
数组倒序 做法一:定义一个新的数组而后按照逆序的方式保存 public static void main(String[] args) { int arr[] = new int[] {1,2,3,4 ...
- Codeforces Round #624 (Div. 3) F
题意: 给出n的质点,带着初位置和速度: 如果中途两点可以相遇dis(i,j)=0: 如果不可以相遇,mindis(i,j): 求n个点的两两质点最小dis(i,j)之和 思路: 因为当初位置x和速度 ...