elastic search book [ ElasticSearch book es book]
谁在使用ELK
维基百科, github都使用 ELK (ElasticSearch es book)
es安装
Elasticsearch 7.x 最详细安装及配置==>https://www.cnblogs.com/Alandre/p/11386178.html
遇见异常
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
在 /etc/sysctl.conf文件最后添加一行 vm.max_map_count=262144
ElasticSearch入门
Elasticsearch入门,这一篇就够了==>https://www.cnblogs.com/sunsky303/p/9438737.html
docker下载并启动ElasticSearch
# 下载
docker pull docker.io/elasticsearch:6.5.1
# 安装
docker run -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -d -p 9200:9200 -p 9300:9300 --name myELK elkImageId
ElasticSearch默认2个G堆内存, 为了防止虚拟机内存不够,要手动指定elk启动参数 -e ES_JAVA_OPTS="-Xms256m -Xmx256m" , 9200是elk暴露的RestFUL HTTP服务端口, 9300是java客户端调用的端口.
在启动时遇到异常: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] , 意为ElasticSearch用户虚拟机能使用的虚拟内存区域太小,需要调大到262144以上 , 按如下操作:
# 修改配置文件
vi /etc/sysctl.conf
# 最后一行添加
vm.max_map_count=655300
# 重载该配置文件
sysctl -p
附非docker, 纯linux版启停命令
注意: 纯linux版启动不能以root身份启动
#停止Elasticsearch进程
$kill `ps -ef | grep Elasticsearch | grep -v grep | awk '{print $2}'`
#启动Elasticsearch进程
$/elasticsearch-5.4.3/bin/elasticsearch -d
访问
http://ip:9200/ 返回如下信息表示成功启动
{
"name" : "vcabSCo",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "LPiwCqIYQACz5Eir5P1qBQ",
"version" : {
"number" : "6.5.1",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "8c58350",
"build_date" : "2018-11-16T02:22:42.182257Z",
"build_snapshot" : false,
"lucene_version" : "7.5.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
http://ip:9200/index/type/id 为查询指定id
http://ip:9200/index/type/_search 为查询所有
ElasticSearch 各组件概念
索引 = mysql数据库
类型 = mysql数据表
文档 = mysql表字段内容 ( ES中使用json数据保存 )

processon地址: https://www.processon.com/diagraming/5ceb8caee4b0899ed43db40e
ElasticSearch和Mysql对应关系
| 技术 | 库名 | 表 | 行 | 列 | |
| mysql | Databases | Tables | Rows | Columns | |
| ElasticSearch | Indices | Types | Documents | Fields |
java连接ELK有两种方式
方式一: jest
jest是用于直联ElasticSearch服务的, 就好像redisClient 直联redis服务一样.
默认jest是不生效的, 需要导入jest的工具包(io.searchbox.client.JestClient) , 注意jest的大版本号和ES的大版本号要一致.
该模式的自动配置类为: JestAutoConfiguration
pom.xml导依赖
导入之后JestAutoConfiguration里的内容就不会报红色错误了, 但是发现高版本springboot好像不导也正常.
<!--取消spring-boot-starter-data-elasticsearch依赖-->
<!--<dependency>-->
<!--<groupId>org.springframework.boot</groupId>-->
<!--<artifactId>spring-boot-starter-data-elasticsearch</artifactId>-->
<!--</dependency>--> <dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>5.3.3</version>
</dependency>
遇到错误,Jest无法存数据到ElasticSearch中, java后台不报错, ElasticSearch也不报错, 也没有日志显示错误 ,
目前jest5.3.3对ElasticSearch5.6.12 可以正常交互 , 但jest5.3.3对ElasticSearch6 或jest6对ElasticSearch6无法正常交互.
方式二: SpringData ElasticSearch
通过使用Spring工具类转发,步骤如下
1. pom.xml导入spring-boot-starter-data-elasticsearch依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
2. 需要在application.properties中配置clusterNodes;clusterName
#使用springData连接ES
#集群名,访问 http://centos:9200/ 后返回的cluster_name即是节点名
spring.data.elasticsearch.cluster-name=elasticsearch
#IP:9300, 用的是9300通信
spring.data.elasticsearch.cluster-nodes=centos:9300
3. 编写ElasticsearchRepository子接口来操作ES (就好像hibernateTemplate一样, 和JPA用法一致)
4. ElasticSearchTemplate 操作ES , 就好像(jdbcTemplate, 一样, 未实验, 只做了Repository的实验)
另外特别注意在使用SpringData elasticSearch 和 elasticSearch对接时的要注意版本问题 , 如何找版本匹配参考下图流程 , 懒人直接打开 https://github.com/spring-projects/spring-data-elasticsearch
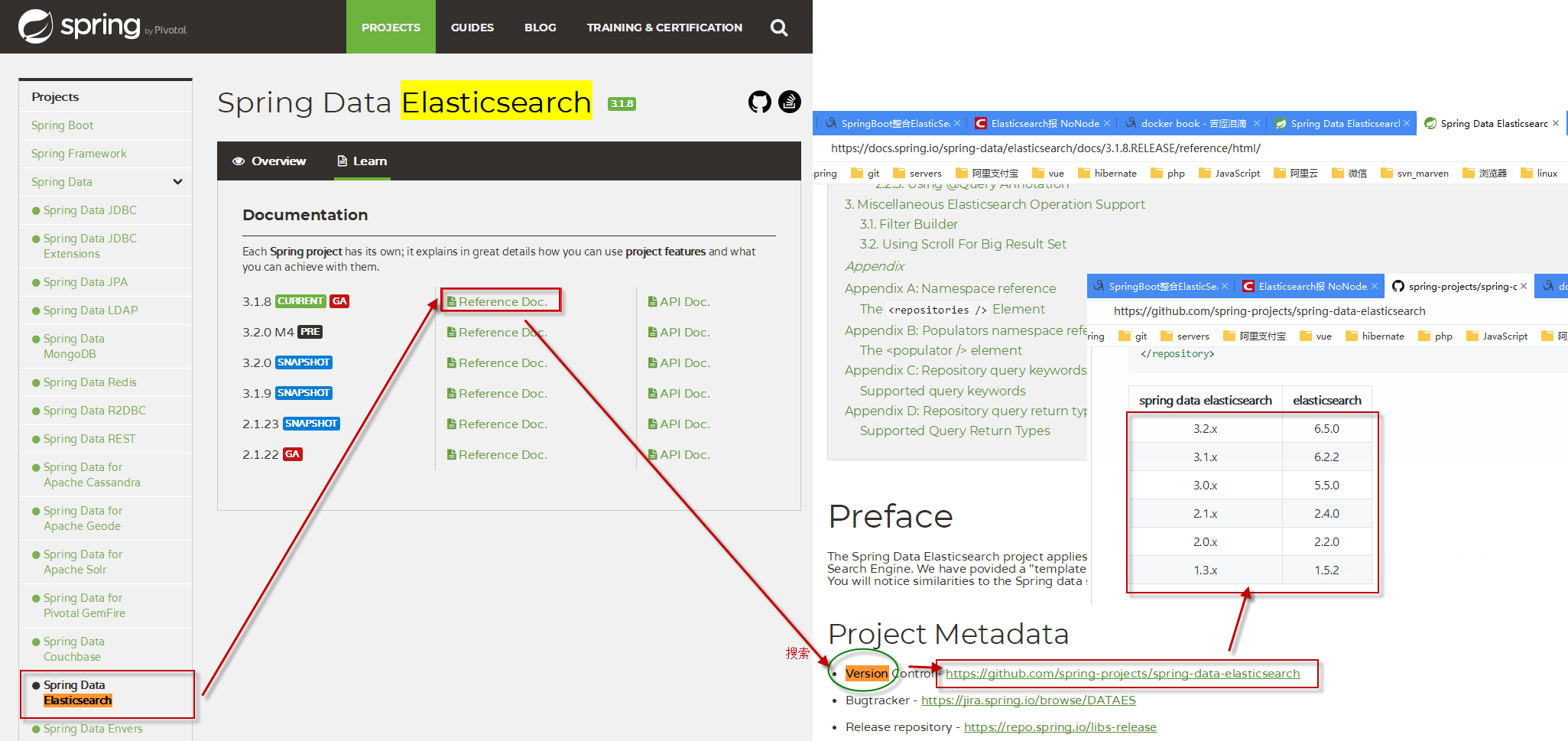
遇上版本不匹配的概率较高, 会发生异常"NoNodeAvailableException[None of the configured nodes are available: [{#transport#-1}{3mA3x7OSSjustRG1_ZytWg}{centos}{192.168.2.106:9300}]" 一般有两种处理方式
1. 调整springboot的版本(不建议)
2. 调整ElasticSearch的版本(建议)
方式三 RestHighLevelClient
RestHighLevelClient 创建索引:
public String createDocument() throws Exception {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("nexus.isoftstones.com", 9201, "http")));
// 3. 增加文档(如果类注释推荐使用org.elasticsearch.client.Requests来创建类,最好用他推荐的方式)
IndexRequest request = Requests.indexRequest("person");
request.id("docid2");// 指定ID
request.source("personid", "2",
"name", "jack",
"birthday","2012-02-16");// 支持多种方式
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse);
return "创建成功";
}
RestHighLevelClient 查询索引:
@RequestMapping({"/searchSomePerson"})
public List<Person> searchSomePerson() throws Exception {
List<Person> personList = new ArrayList<>();
SearchRequest searchRequest = new SearchRequest("person");//qqq
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//aaa
// int newFrom = PaginationTool.firstResult(1 , PaginationTool.PAGE_SIZE);
// sourceBuilder.from(newFrom);
// sourceBuilder.size(PaginationTool.PAGE_SIZE);
//他们之间默认是 or 的关系, name 包含 xxx or address 包含 xxx , 另注意multiMatchQuery()和matchQuery()两个方法中的参数位置是互反的
QueryBuilder queryBuilder = QueryBuilders.multiMatchQuery("jack", "name", "address");
sourceBuilder.query(queryBuilder);//传入QueryBuilder
System.out.println("实际请求elastic search的json报文" + sourceBuilder.toString());
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);//bbb
searchResponse.getHits().forEach(hit -> {
System.out.println(hit.getSourceAsString());
Person person = JSONObject.parseObject(hit.getSourceAsString(), Person.class);
personList.add(person);
});
System.out.println(personList);
return personList;
}
以上代码位于https://gitee.com/KingBoBo/springboot-04-elastic-search.git
笔记1 : QueryBuilders.multiMatchQuery ------- 相对于matchQuery,multiMatchQuery针对的是多个field,也就是说,当multiMatchQuery中,fieldNames参数只有一个时,其作用与matchQuery相当;
而当fieldNames有多个参数时,如field1和field2,那查询的结果中,要么field1中包含text,要么field2中包含text (field1包含text OR field2 包含 text)。(本句话引用自: 分布式搜索Elasticsearch——QueryBuilders.multiMatchQuery==>https://blog.csdn.net/geloin/article/details/8934951 )
public static MultiMatchQueryBuilder multiMatchQuery(Object text, String... fieldNames) {
return new MultiMatchQueryBuilder(text, fieldNames); // BOOLEAN is the default
}
笔记2: boolQueryBuilder.should(qb1).must(qb2);//如果直接使用should().must()组合,那么should()会无效化 , 因为就算把should(qb1)前置 , 有时候还是会被must抢先,
当然这并非主要原因 , 根据json报文实测发现 , 只要must和shoud同级别共存, should就会失效, 其它文章也有提及: elasticsearch6.6版本 es填坑之路 解决:QueryBuilder同时使用should must时,会影响should的筛选结果!==>https://blog.csdn.net/q18810146167/article/details/89404901
以下为实际RESTFUL发送的报文:
{
"query": {
"bool": {
"must": [{
"wildcard": {
"name": {
"wildcard": "rose",
"boost": 1.0
}
}
}],
"should": [{
"wildcard": {
"name": {
"wildcard": "jack",
"boost": 1.0
}
}
}],
"adjust_pure_negative": true,
"boost": 1.0
}
}
}
BoolQueryBuilder联合查询
//模糊查询
WildcardQueryBuilder queryBuilder1 = QueryBuilders.wildcardQuery("name", "*jack*");//搜索名字中含有jack的文档
WildcardQueryBuilder queryBuilder2 = QueryBuilders.wildcardQuery("name", "*rose*");//搜索名字中含有rose的文档 BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//name中必须含有jack,name中必须含有rose,相当于and
boolQueryBuilder.must(queryBuilder1);
boolQueryBuilder.must(queryBuilder2);
//模糊查询
WildcardQueryBuilder queryBuilder1 = QueryBuilders.wildcardQuery("name", "*jack*");//搜索名字中含有jack的文档
WildcardQueryBuilder queryBuilder2 = QueryBuilders.wildcardQuery("name", "*rose*");//搜索名字中含有rose的文档 BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//name中必须含有jack,name中必须含有rose,相当于and
boolQueryBuilder.should(queryBuilder1);
boolQueryBuilder.should(queryBuilder2);
Elasticsearch——QueryBuilder简单查询==>https://www.cnblogs.com/sbj-dawn/p/8891419.html
强制elasticSearch指定目录的jdk (未亲测)
即修改elasticsearch的启动脚本(elasticsearch_HOME/bin/elasticsearch)
[root@master01 elasticsearch-6.0.0]# vim bin/elasticsearch
# 添加以下代码
export JAVA_HOME=/home/elsearch/jdk1.8.0_121/ (此处配置的为刚下的1.8的配置目录)
export PATH=$JAVA_HOME/bin:$PATH if [ -x "$JAVA_HOME/bin/java" ]; then
JAVA="/home/elsearch/jdk1.8.0_121/bin/java"
else
JAVA=`which java`
fi
elk使用like查询
使用wildcard进行查询
dsl语法
{
"query": {
"wildcard": {
"intf": "*measure*"
}
}
}
java 客户端语法
wildcardQuery("description", "*"+searchStr.toLowerCase()+"*")
需要注意的是wildcard不识别大写,需要将查询的词转为小写。
插件安装
安装插件时也不能以root身份安装, 不然涉及权限问题,以下为安装图型化界面elasticsearch-sql命令
[root]#su es
[es]$ ./bin/elasticsearch-plugin install https://github.com/NLPchina/elasticsearch-sql/releases/download/7.1.1.0/elasticsearch-sql-7.1.1.0.zip
es6.3+开始 , 在elasticsearch/bin目录下调用./elasticsearch-sql-cli 进入命令行 (https://www.jianshu.com/p/66ba200520ed)
默认情况下elasticsearch-sql-cli会尝试连接localhost:9200, 如果你修改了ES的端口,需要指定新的ES访问地址,比如 你的ES端口设置成 8888, 那么需要输入下列命令来打开./elasticsearch-sql-cli http://localhost:8888
如果生产环境无法连接外网, 需要在windows上下载好zip文件后, 上传到生产服务器, 再在命令中的install后追加file:以执行安装
./bin/elasticsearch-plugin install file:/opt/elasticsearch-7.1.1.0/elasticsearch-sql-7.1.1.0.zip
客户端工具
ElasticHD windows桌面客户端
chrome插件 ElasticSearch Head
官方的模拟工具是控制台的curl,不是很直观,可以在chrome浏览器中安装head插件来作为请求的工具:head插件的地址:https://chrome.google.com/webstore/detail/elasticsearch-head/ffmkiejjmecolpfloofpjologoblkegm/
Dejavu (使用中)
版本问题
随着 7.0 版本的即将发布,type 的移除也是越来越近了,在 6.0 的时候,已经默认只能支持一个索引一个 type 了,7.0 版本新增了一个参数 include_type_name ,即让所有的 API 是 type 相关的,这个参数在 7.0 默认是 true,不过在 8.0 的时候,会默认改成 false,也就是不包含 type 信息了,这个是 type 用于移除的一个开关。
让我们看看最新的使用姿势吧,当 include_type_name 参数设置成 false 后:
- 索引操作:PUT {index}/{type}/{id}
需要修改成PUT {index}/_doc/{id} - Mapping 操作:
PUT {index}/{type}/_mapping则变成PUT {index}/_mapping - 所有增删改查搜索操作返回结果里面的关键字
_type都将被移除 - 父子关系使用
join字段来构建
RESTFUL请求
$$$$$ElasticSearch入门3: 高级查询==>https://www.cnblogs.com/liuxiaoming123/p/8124969.html
#创建索引
PUT twitter
{
"mappings": {
"_doc": {
"properties": {
"type": { "type": "keyword" },
"name": { "type": "text" },
"user_name": { "type": "keyword" },
"email": { "type": "keyword" },
"content": { "type": "text" },
"tweeted_at": { "type": "date" }
}
}
}
} #修改索引
PUT twitter/_doc/user-kimchy
{
"type": "user",
"name": "Shay Banon",
"user_name": "kimchy",
"email": "shay@kimchy.com"
} #搜索
GET twitter/_search
{
"query": {
"bool": {
"must": {
"match": {
"user_name": "kimchy"
}
},
"filter": {
"match": {
"type": "tweet"
}
}
}
}
} #重建索引
POST _reindex
{
"source": {
"index": "twitter"
},
"dest": {
"index": "new_twitter"
}
}
本小节引用自: Elasticsearch 移除 type 之后的新姿势==>https://elasticsearch.cn/article/601
异常
es无法启动,配置内存大小(好像无用)
修改 /data/elasticsearch/bin/elasticsearch export ES_HEAP_SIZE=512m
The Java High Level REST Client
使用Java High Level REST Client操作elasticsearch==>https://www.cnblogs.com/ginb/p/8716485.html
Elasticsearch技术解析与实战(四)shard&replica机制==>https://www.cnblogs.com/cnki/p/7497222.html
参考
SpringBoot整合ElasticSearch实现多版本的兼容==>https://www.cnblogs.com/xuwujing/p/8998168.html
elasticsearch安装之各种坑==>https://www.cnblogs.com/gudulijia/p/6761231.html
RestHighLevelClient
$$$Elasticsearch Java API的基本使用==>https://www.jianshu.com/p/5cb91ed22956
$$$$$Elasticsearch笔记(八):客户端连接==>https://blog.csdn.net/alex_xfboy/article/details/85332370
查询知识点
【转载】Elasticsearch--java操作之QueryBuilders构建搜索Query==>https://www.cnblogs.com/wbl001/p/11645044.html
使用Java High Level REST Client操作elasticsearch==>https://www.cnblogs.com/ginb/p/8716485.html
分词
ES 自带了很多默认的分词器,比如Standard、Keyword、Whitespace等等,默认是Standard
ElasticSearch入门 第七篇:分词==>https://www.cnblogs.com/ljhdo/p/5012510.html
掌握 analyze API,一举搞定 Elasticsearch 分词难题==>https://baijiahao.baidu.com/s?id=1609869808965712860&wfr=spider&for=pc
嘉媛参考文档
自己转载的备份
ElasticSearch 7.1.1 集群环境搭建【转】==>https://www.cnblogs.com/whatlonelytear/p/11623882.html
Elasticsearch入门,这一篇就够了【纯转】==>https://www.cnblogs.com/whatlonelytear/p/11811827.html
高级进阶
Elasticsearch Pipeline 详解==>https://blog.csdn.net/chunqiqian1285/article/details/100977188
ElasticSearch11:_version和external version进行乐观锁并发控制==>https://blog.csdn.net/m0_37557582/article/details/78922713 (默认自带INTERNAL内部版本锁, 也可以使用EXTERNAL外部版本锁)
Removal of mapping types映射类型mapping==>https://www.cnblogs.com/Neeo/articles/10393961.html#important
优化
【ElasticSearch系列(三)】性能优化之==》https://blog.csdn.net/zhanyu1/article/details/88927194
我的项目git地址
https://gitee.com/KingBoBo/springboot-04-elastic-search
elastic search book [ ElasticSearch book es book]的更多相关文章
- aws ec2 安装Elastic search 7.2.0 kibana 并配置 hanlp 分词插件
文章大纲 Elastic search & kibana & 分词器 安装 版本控制 下载地址 Elastic search安装 kibana 安装 分词器配置 Elastic sea ...
- [elastic search][redis] 初试 ElasticSearch / redis
现有项目组,工作需要. http://www.cnblogs.com/xing901022/p/4704319.html Elastic Search权威指南(中文版) https://es.xiao ...
- Elastic Search快速上手(2):将数据存入ES
前言 在上手使用前,需要先了解一些基本的概念. 推荐 可以到 https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.htm ...
- elastic search&logstash&kibana 学习历程(一)es基础环境的搭建
elastic search 6.1.x 常用框架: 1.Lucene Apache下面的一个开源项目,高性能的.可扩展的工具库,提供搜索的基本架构: 如果开发人员需用使用的话,需用自己进行开发,成本 ...
- 初识Elastic search—附《Elasticsearch权威指南—官方guide的译文》
本文作为Elastic search系列的开篇之作,简要介绍其简要历史.安装及基本概念和核心模块. 简史 Elastic search基于Lucene(信息检索引擎,ES里一个index—索引,一个索 ...
- elastic search(以下简称es)
参考博客园https://www.cnblogs.com/Neeo/p/10304892.html#more 如何学好elasticsearch 除了万能的百度和Google 之外,我们还有一些其他的 ...
- Elastic search集群新增节点(同一个集群,同一台物理机,基于ES 7.4)
一开始,在电脑上同一个集群新增节点(node)怎么试也不成功,官网guide又语焉不详?集群健康值yellow(表示主分片全部可用,部分复制分片不可用) 最后,在stackoverflow上找到了答案 ...
- elastic search(es)安装
全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选. 它可以快速地储存.搜索和分析海量数据.维基百科.Stack Overflow.Gi ...
- elastic search使用总结
1. elasticsearch安装 官方下载地址:https://www.elastic.co/downloads/elasticsearch 解压文件 elasticsearch-2.4.0.zi ...
随机推荐
- 分享一个百度大牛的Python视频系列下载
好像是百度资深大数据工程师 在录制Python视频课程讲课,包括Python基础入门.数据分析.网络爬虫.大数据处理.机器学习.推荐系统等系列,他还在不停地录制,课程感觉很不错,视频网盘分享给大家 学 ...
- netcore进程内(InProcess)托管和进程外(out-of-Process)托管
当一个 ASP.NET Core 应用程序执行的时候,.NET 运行时会去查找 Main()方法,因为它是这个应用程序的起点. 然后,Main()方法调用静态类WebHost中的静态方法CreateD ...
- python3没有了xrange
升级到python3的同学应该会注意到以前经常用的xrange没了! 是的,python3的range就是xrange.直接看效果! Python 2.7.13 (v2.7.13:a06454b1 ...
- mysql 登录的时候设置编码 utf8
很多时候 导入sql 的时候需要命令行导入 但是有的时候容易出现乱码 因为字符集的问题 所以 尽量在登录的时候就设置编码 就不容易出错了 例如: mysql -uroot -p –default-ch ...
- pc端拖拽
var move=document.getElementsByClassName("page1_2")[0]; var startX=0; var startY=0; var x= ...
- call(this)自记
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Idea代理设置与Java程序的代理设置
最近在学习WebService的过程中,为了弄清楚发送和接收的包的数据结构,使用Fiddler抓取包的数据.开始先配置了Idea的代理设置,但执行Java代码发送请求时,依然无法在Fiddler中抓取 ...
- mybatis深入理解(七)-----MyBatis缓存机制的设计与实现
缓存设计 MyBatis将数据缓存设计成两级结构,分为一级缓存.二级缓存: 一级缓存是Session会话级别的缓存,位于表示一次数据库会话的SqlSession对象之中,又被称之为本地缓存.一级缓存是 ...
- spring cloud深入学习(一)-----什么是微服务?什么是rpc?spring cloud简介
近年来,微服务非常的流行,那么为什么是它?简单介绍一下. 为什么是微服务? 微服务架构是一种将单应用程序作为一套小型服务开发的方法,每种应用程序都在其自己的进程中运行,并与轻量级机制(通常是HTTP资 ...
- 深入了解MVC(转)
MVC无人不知,可很多程序员对MVC的概念的理解似乎有误,换言之他们一直在错用MVC,尽管即使如此软件也能被写出来,然而软件内部代码的组织方式却是不科学的,这会影响到软件的可维护性.可移植性,代码的可 ...