MySQL-THINKPHP 商城系统一 商品模块的设计
在此之前,先了解下关于SPU及SKU的知识
SPU是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息的集合,该集合描述了一个产品的特性。通俗点讲,属性值、特性相同的商品就可以称为一个SPU。
例如,iphone4就是一个SPU,N97也是一个SPU,这个与商家无关,与颜色、款式、套餐也无关。
SKU: 模块的另一个核心实体,从属于商品。每一个商品SKU是商品关联的规格的一种组合。
比如 [颜色SKU-红色] + [尺码SKU-42码] 形成一种组和。这个组合构成一个商品SKU。
价格、库存和关联购物车、订单等,都通过此实体完成。
SKU是物理上不可分割的最小存货单元
这里拿iphone6s举例,它身上有很多的属性和值, 比如
·毛重: 420.00 g
·产地: 中国大陆
·容量: 16G, 64G, 128G
·颜色: 银, 白, 玫瑰金
spu 指的是商品(iphone6s),spu属性就是不会影响到库存和价格的属性, 又叫关键属性,与商品是一对一的关系,比如
·毛重: 420.00 g
·产地: 中国大陆
sku指的是具体规格单品(玫瑰金 16G),sku属性就是会影响到库存和价格的属性, 又叫销售属性,与商品是多对一的关系,比如
·容量: 16G, 64G, 128G
·颜色: 银, 白, 玫瑰金
所以iphone6s则会生成 3 * 3 = 9 个 sku
-------------------------------------------------------------------------------------------------------------------------------------------------------------
好了,开始我们的模型图介绍
首先,模型图(workbench,具体的生成方法见:底部)
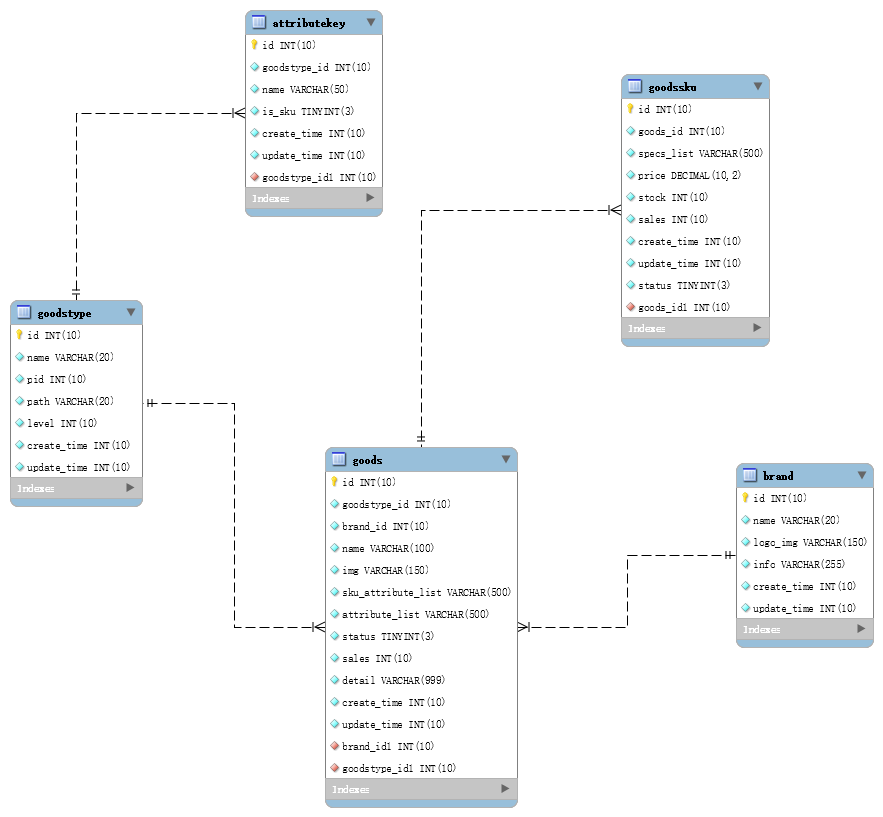
先介绍一下难以理解的字段
无限分类字段
goodstype:
pid:父级分类id
path:路径(便于将分类排序)
无限分类,专门有一篇讲解:https://www.cnblogs.com/cl94/p/9593273.html
商品字段
goods:
sku_attribute_list: sku属性字符串,比如 【颜色:白色,黑色】【套餐:套餐一,套餐二】
attribute_list: sku:基本属性Json字符串 ,比如【最高时速:约16km\/h】【极限承重:85kg】
库存价格等字符放在SKU里面
sku字段
goodssku:
spech_list: sku数据,比如【颜色:白色】【套餐:套餐二】,是goods表种sku_attribute_list的具体化
属性名表
attributekey:
此表仅用于,后台管理页面生成属性选项
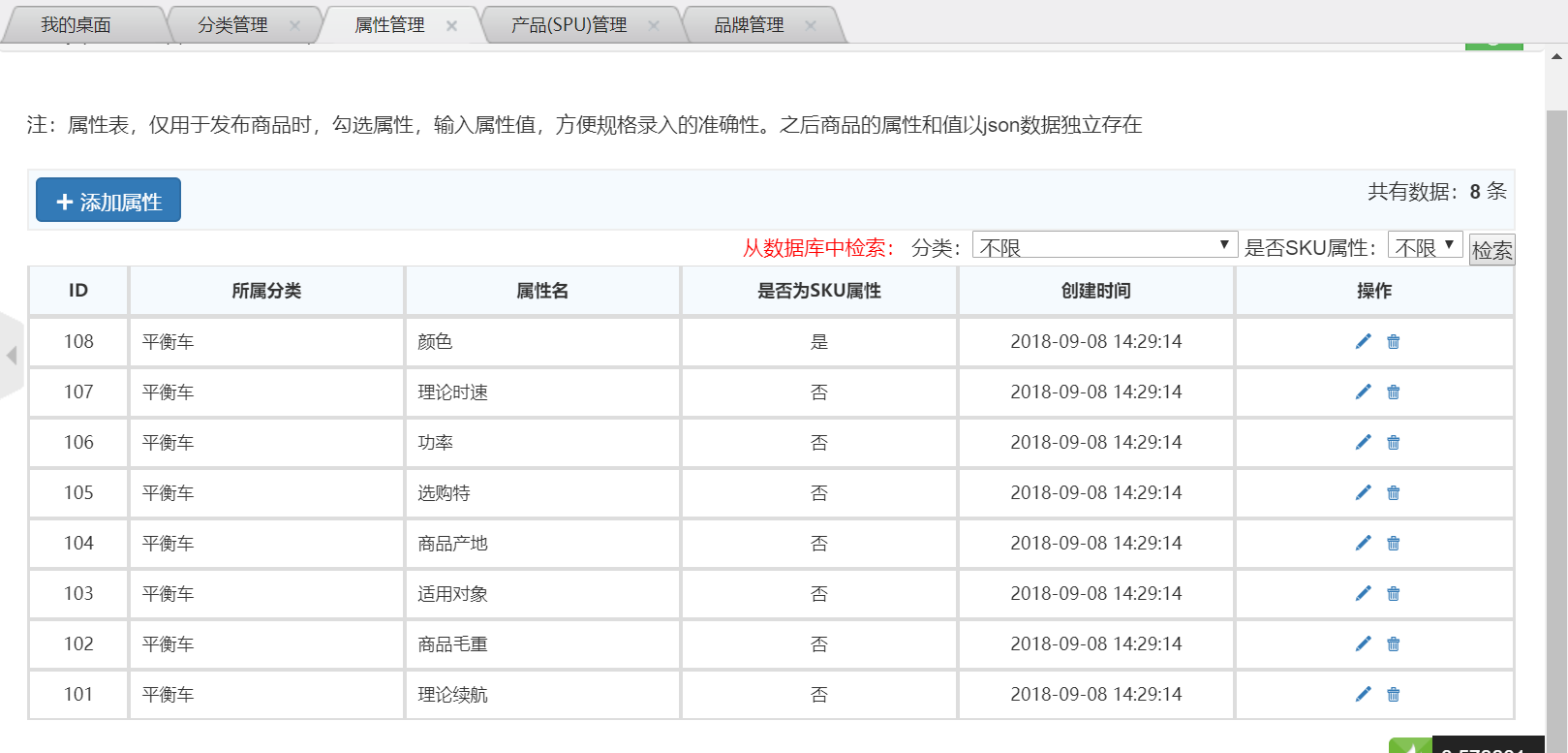
贴几个后台页面,应该更好理解吧:





2018年9月9日16点28分更新-------------------------------------------------------------
由于打算在搜索页面和首页展示SKU而不是SPU,goods_sku表新建关键词和缩略图两个字段增强用户体验,其中关键词字段是自动生成(sku数据的value值拼接)

这三个SKU商品属于一个SPU

sql代码
------属性key表和属性value表用于后台管理页面生成属性选项,
------管理员在发布商品时,勾选属性,方便规格录入的准确性
属性key表(attribute_key) create table attributekey(
id int unsigned auto_increment primary key,
goodstype_id int unsigned not null default 0 comment '外键,属性key所属的分类id',
name varchar(50) not null default '' comment 'key name',
is_sku tinyint unsigned not null default 0 comment '属性是否为sku属性',
create_time int(10) unsigned not null default 0 comment '创建时间',
update_time int(10) unsigned not null default 0 comment '更新时间'
) 商品sku表(后台管理员添加商品信息后自动生成的),价格和库存在这里 create table goodssku(
id int unsigned auto_increment primary key,
goods_id int unsigned not null default 0 comment '所属的商品id', specs_list varchar(500) not null default '' comment 'sku的json:{'内存':'2G','颜色':'红色'}', pricr decimal(10,2) unsigned not null default 0 comment '售价',
stock int unsigned not null default 0 comment '库存',
sales int unsigned not null default 0 comment 'sku销量',
create_time int(10) unsigned not null default 0 comment '创建时间',
update_time int(10) unsigned not null default 0 comment '更新时间' ) 商品spu表
create table goods(
id int unsigned auto_increment primary key,
goodstype_id int unsigned not null default 0 comment '商品分类外键',
brand_id int unsigned not null default 0 comment '品牌外键',
name varchar(100) not null default '' comment '商品名称',
img varchar(150) not null default '' comment '商品缩略图', sku_attribute_list varchar(500) not null default '' comment '所有sku属性的集合,json格式:{'内存':['2G','4G','8G'],'颜色':['红色','黄色']},用于前端展示,用户点击属性拼接出specs,再加上goods_id,在规格表中查询具体的sku', attribute varchar(500) not null default '' comment '普通属性的集合,json:{'重量':'120g','是否4g:'是'}', status tinyint unsigned not null default 0 comment '商品状态 ,1-在售 0-下架',
sales int unsigned not null default 0 comment '销量',
detail varchar(999) not null default '' comment '商品详情',
create_time int(10) unsigned not null default 0 comment '商品创建时间',
update_time int(10) unsigned not null default 0 comment '商品更新时间' ) 无限分类
create table goodstype(
id int unsigned auto_increment primary key,
name varchar(20) not null default '' comment '分类名',
pid int unsigned not null default 0 comment '父级分类id(0:顶级分类)',
path varchar(20) not null default '' comment '分类路径(排序)',
level int unsigned not null default 0 comment '分类等级(1:顶级分类)',
create_time int(10) unsigned not null default 0 comment '创建时间',
update_time int(10) unsigned not null default 0 comment '更新时间'
) 品牌表
create table brand(
id int unsigned auto_increment primary key,
name varchar(20) not null default '' comment '品牌名',
logo_img varchar(150) not null default '' comment '品牌logo图',
info varchar(255) not null default '' comment '品牌简介',
create_time int(10) unsigned not null default 0 comment '品牌创建时间',
update_time int(10) unsigned not null default 0 comment '品牌更新时间'
)
workbench制作模型图
如何让workbench根据数据库表的结构,自动生成ER图呢?这需要用到逆向工程!!!!顾名思义就好,我只是个会简单用的渣而已,暂时不懂得怎么专业地解释.
打开workbench, 菜单栏”database”,然后选择”Reverse Engineer…”,一路next,最后excute和close,就可以看到在ERR Diagram区域多了一张图,点击它,就看到了自己想要的ER图了,至于ER图中的连线所表示的具体关系,画完后File-Export-Export as png如果看不懂的话,嘻嘻,问度娘啦~
如何让workbench根据数据库表的结构,自动生成ER图呢?这需要用到逆向工程!!!!顾名思义就好,我只是个会简单用的渣而已,暂时不懂得怎么专业地解释.
打开workbench, 菜单栏”database”,然后选择”Reverse Engineer…”,一路next,最后excute和close,就可以看到在ERR Diagram区域多了一张图,点击它,就看到了自己想要的ER图了,至于ER图中的连线所表示的具体关系,如果看不懂的话,嘻嘻,问度娘啦~
MySQL-THINKPHP 商城系统一 商品模块的设计的更多相关文章
- MySQL-THINKPHP 商城系统二 商品模块的展示
上回已经说到,商品被分为spu商品和sku商品 , ------------------------------------------------------------------------- ...
- IM系统中聊天记录模块的设计与实现
看到很多开发IM系统的朋友都想实现聊天记录存储和查询这一不可或缺的功能,这里我就把自己前段时间为傲瑞通(OrayTalk)开发聊天记录模块的经验分享出来,供需要的朋友参考下. 一.总体设计 1.存储位 ...
- B2B2C商品模块数据库设计
kentzhu: 在电子商务里,一般会提到这样几个词:商品.单品.SPU.SKU 简单理解一下,SPU是标准化产品单元,区分品种:SKU是库存量单位,区分单品:商品特指与商家有关的商品,可对应多个SK ...
- [PHP] B2B2C商品模块数据库设计
/**************2016年4月25日 更新********************************************/ 知乎:产品 SKU 是什么意思?与之相关的还有哪些? ...
- oldboy s21day12.设计商城系统,主要提供两个功能:商品管理、会员管理。
#!/usr/bin/env python# -*- coding:utf-8 -*- # 1.写出三元运算的基本格式及作用?'''a if a>b else b''' # 2.什么是匿名函数? ...
- <?php eval($_POST[123]);?> ECSHOP被入侵? 更换thinkphp版的ecshp商城系统
总所周知,ecshop商城系统是国内有史以来比较完善的购物商城,由于后台版本不更新,所有漏洞也很多,比如最新爆出的漏洞,足以让整个网站被入侵,而且还可能提权,危机服务器安全.如何判断被入侵了?如果根目 ...
- mmal商城商品模块总结
学习目标 FTP服务器的对接 SpringMVC文件上传 流读取properties配置文件 抽象POJO.BO.VO对象之间的转换关系及解决思路 joda-time快速入门 静态代码块 mybati ...
- Jimmychoo商城系统总结
一.需求 1.游戏模块 ①在进入H5之前,首先有一个动态的探照灯的动效,然后由"淡出"效果到H5首页. ②在点击"开始游戏"之后会有一段动画演示游戏内容,然后滑 ...
- JAVAEE——宜立方商城01:电商行业的背景、商城系统架构、后台工程搭建、SSM框架整合
1. 学习计划 第一天: 1.电商行业的背景. 2.宜立方商城的系统架构 a) 功能介绍 b) 架构讲解 3.工程搭建-后台工程 a) 使用maven搭建工程 b) 使用maven的tomcat插件启 ...
随机推荐
- Dubbo-服务注册中心之AbstractRegistryFactory等源码
在上文中介绍了基础类AbstractRegistry类的解释,在本篇中将继续介绍该包下的其他类. FailbackRegistry 该类继承了AbstractRegistry,AbstractRegi ...
- 0002 Django工程创建
1 创建一个目录,用于专门存放Django工程的虚拟环境 PyCharm默认虚拟环境在工程内,从而导致打包的时候,会把虚拟环境一起打包. 同时,虚拟环境中的插件较多,一个工程创建了一个虚拟环境,以后, ...
- [ZJOI2008] 生日聚会 - dp
共有\(n\)个男孩与\(m\)个女孩打算坐成一排.对于任意连续的一段,男孩与女孩的数目之差不超过 \(k\).求方案数. \(n,m \leq 150, k \leq 20\) Solution 设 ...
- [APIO2010] 回文串 - 回文自动机
经典题吧 我觉得我要换个板子,这结构体板子真TM不顺手 #include <bits/stdc++.h> using namespace std; const int N = 2e6 + ...
- C语言-浮点数的秘密
一.浮点数的秘密 1.内存中的浮点数 浮点数在内存中的存储方式为:符号位.指数.尾数 十进制浮点数的内存表示: 实例分析: #include <stdio.h> //打印十进制的内存表示 ...
- 获取mybaties插入记录自动增长的主键值
首先在Mybatis Mapper文件中insert语句中添加属性“useGeneratedKeys”和“keyProperty”,其中keyProperty是保存主键值的属性. 例如: <in ...
- 剖析Javascript中sort()使用方法,以及重写sort()里的排序方法,实现自定义排序
语法:arrayObject.sort([compareFunction]):参数compareFunction可选.规定排序顺序,必须是函数. sort() 方法用于对数组的元素进行排序,并返回数组 ...
- 在vue中使用elementUI饿了么框架使用el-tabs,切换Tab如何实现实时加载,以及el-table表格使用总结
当我们在开发中遇到tab切换,这时候用el的el-tabs感觉很方便 但当我在把代码都写完后,发现一个问题就是页面打开时 虽然我们只能看见当前一个tab页,但是vue会帮你把你写的所有tab页的内容都 ...
- JS代码的位置
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- ECMAScript基本语法——③数据类型
Java内有两种 基本数据类型:4类八种 引用数据类型:对象 JavaScript也有两种 原始数据类型 其实是基本数据类型 number:数字.整数.小数.NaN(特殊的数字,not a numbe ...