【笔记】机器学习 - 李宏毅 - 5 - Classification
Classification: Probabilistic Generative Model 分类:概率生成模型
如果说对于分类问题用回归的方法硬解,也就是说,将其连续化。比如 \(Class 1\) 对应的目标输出为 1, \(Class 2\) 对应 -1。
则在测试集上,结果更接近1的归为\(Class 1\),反之归为\(Class 2\)。
这样做存在的问题:如果有Error数据的干扰,会影响分类的结果。
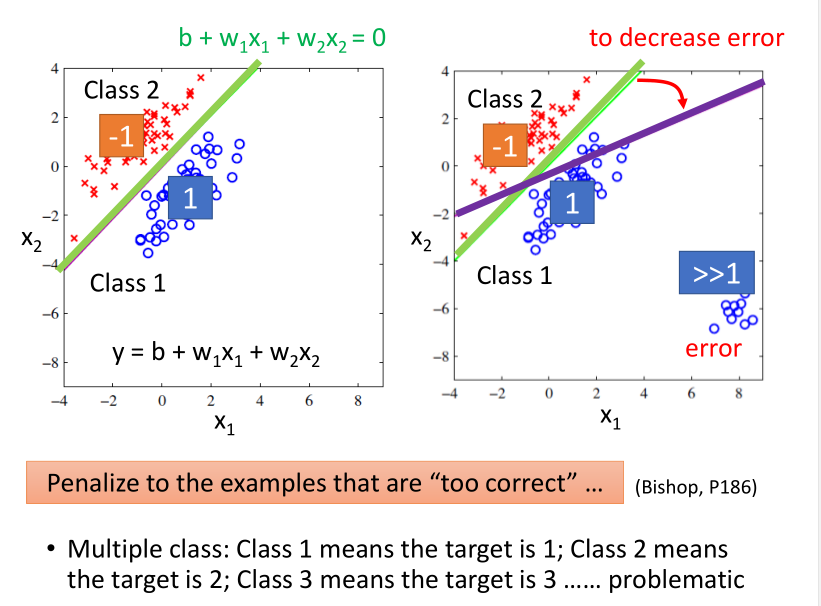
还有就是,如果是多分类问题,则在各类之间增加了线性关系,比如认为 \(Class 3\) 比 $ Class 4$ 离 \(Class 1\) 更近,这是不对的。
另一种方法是,用\(if\)函数,不过这样的话,虽然分类更合理,但损失函数无法微分计算。

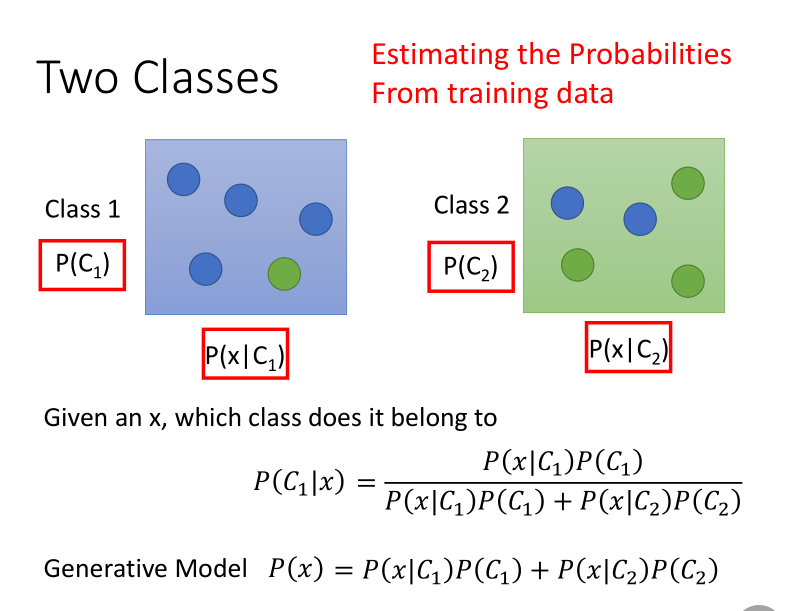
比较好的模型是概率生成模型,通过概率方式计算,(贝叶斯公式)。
其中\(P(C_1)\)和\(P(C_2)\)是先验概率。
高斯分布,最大似然估计
这里选用高斯分布(其他合理的分布也可以,比如对于二元分类来说,可以假设是符合 Bernoulli distribution(伯努利分布))。
从概率上讲,任何高斯分布都可以产生样本数据,但我们需要的是最大可能性的那种分布,求出它的期望 \(\mu\) 和协方差矩阵 \(\sum\)。
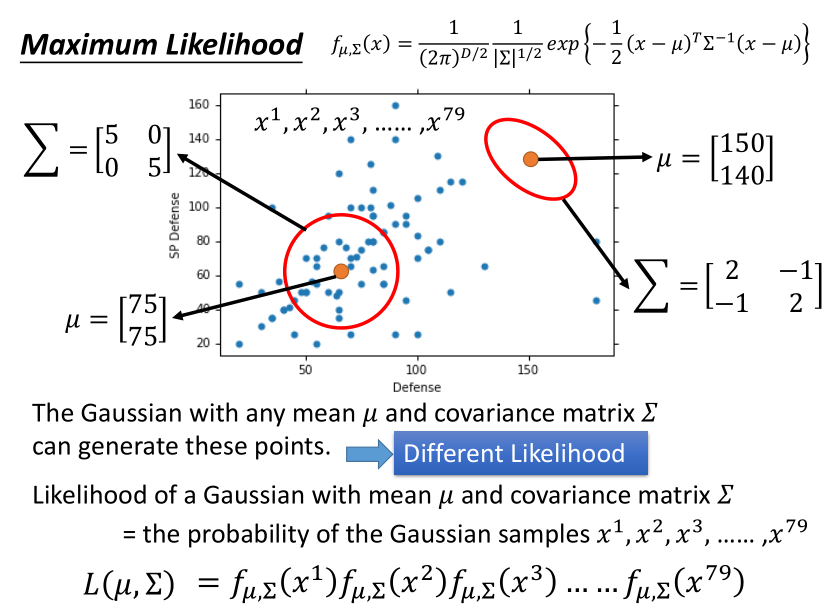
求解方法就是对 \(\mu\)和\(\sum\)分别关于\(L(\mu, \sum)\)求偏微分。

最后得到的结果不是很好,只有47%正确率,即使考虑更多的参数(Overfitting),提升到7维,也只有54%。
如果说,给两个高斯分布相同的协方差矩阵(求加权平均值)的话,效果会好很多,达到了73%。因为分界线是直线,所以也把这种分类叫做线性模型。

分类问题的机器学习三步骤:

此外,假设每一个维度用概率分布模型产生出来的几率是相互独立的,所以可以将 \(P(x|C_1)\)拆解,可以认为每个 \(P(x_k|C_1)\)产生的概率都符合一维的高斯分布。
也就是此时P(x|C1)的高斯分布的协方差是对角型的(不是对角线的地方值都是0),这样就可以减少参数的量。但是结果显示这种做法不好。
这种假设所有的feature都是相互独立产生的分类叫做 Naive Bayes Classifier(朴素贝叶斯分类器)。

后验概率


经过一系列数学推导后,最后在形式上转换为了 \(w · x + b\),然后再套一个\(sigmoid\)函数就得到了最后的结果。
所以,在训练时可以直接去求w和b,这在形式上和回归模型又统一了。
【笔记】机器学习 - 李宏毅 - 5 - Classification的更多相关文章
- 深度学习课程笔记(二)Classification: Probility Generative Model
深度学习课程笔记(二)Classification: Probility Generative Model 2017.10.05 相关材料来自:http://speech.ee.ntu.edu.tw ...
- 机器学习笔记P1(李宏毅2019)
该博客将介绍机器学习课程by李宏毅的前两个章节:概述和回归. 视屏链接1-Introduction 视屏链接2-Regression 该课程将要介绍的内容如下所示: 从最左上角开始看: Regress ...
- 【笔记】机器学习 - 李宏毅 - 10 - Tips for Training DNN
神经网络的表现 在Training Set上表现不好 ----> 可能陷入局部最优 在Testing Set上表现不好 -----> Overfitting 过拟合 虽然在机器学习中,很容 ...
- 【笔记】机器学习 - 李宏毅 - 1 - Introduction & next step
Machine Learning == Looking for a Function AI过程的解释:用户输入信息,计算机经过处理,输出反馈信息(输入输出信息的形式可以是文字.语音.图像等). 因为从 ...
- 【笔记】机器学习 - 李宏毅 - 13 - Why Deep
当参数一样多的时候,神经网络变得更高比变宽更有效果.为什么会这样呢? 其实和软件行业的模块化思想是一致的. 比如,如果直接对这四种分类进行训练,长发的男孩数据较少,那么这一类训练得到的classifi ...
- 【笔记】机器学习 - 李宏毅 - 12 - CNN
Convolutional Neural Network CNN 卷积神经网络 1. 为什么要用CNN? CNN一般都是用来做图像识别的,当然其他的神经网络也可以做,也就是输入一张图的像素数组(pix ...
- 【笔记】机器学习 - 李宏毅 - 11 - Keras Demo2 & Fizz Buzz
1. Keras Demo2 前节的Keras Demo代码: import numpy as np from keras.models import Sequential from keras.la ...
- 【笔记】机器学习 - 李宏毅 - 9 - Keras Demo
3.1 configuration 3.2 寻找最优网络参数 代码示例: # 1.Step 1 model = Sequential() model.add(Dense(input_dim=28*28 ...
- 【笔记】机器学习 - 李宏毅 - 8 - Backpropagation
反向传播 反向传播主要用到是链式法则. 概念: 损失函数Loss Function是定义在单个训练样本上的,也就是一个样本的误差. 代价函数Cost Function是定义在整个训练集上的,也就是所有 ...
随机推荐
- Codeforces_801
A.直接暴力就行了,先把能组合的按线性组合掉,再枚举剩下相邻没用过的. #include<bits/stdc++.h> using namespace std; string s; ] = ...
- js dom一些操作,记录一下自己写的没有意义,可以简略翻过 第八章
第八章,一些dom操作,和几个常用的函数 var s= document.getElementById("new"); console.log(s.length); var a= ...
- 曹工说Spring Boot源码(17)-- Spring从xml文件里到底得到了什么(aop:config完整解析【中】)
写在前面的话 相关背景及资源: 曹工说Spring Boot源码(1)-- Bean Definition到底是什么,附spring思维导图分享 曹工说Spring Boot源码(2)-- Bean ...
- TCP协议三次握手(通信)
在<计算机网络>一书中其中有提到,三次握手的目的是“为了防止已经失效的连接请求报文段突然又传到服务端,因而产生错误”,这种情况是:一端(client)A发出去的第一个连接请求报文并没有丢失 ...
- 一个"/"引发的惨案
今天行云流水写了一个接口,正想着写完就睡觉了,结果访问的时候一直报错404,找不到路径,我反复检查了好久,确定路径名字没写错,百思不得其解,瞬间有想砸电脑的冲动,于是准备洗洗睡了,明天再搞 洗玩脚回到 ...
- redis说明及部署
一.reids 概述 redis全称REmote DIctionary Server.一个基于KV的持久化分布式数据库.所编写的语言为C.与另一个分布式缓存Memcached有几分相似 但是redis ...
- 导出Chrome浏览器中保存的密码
title: 导出Chrome浏览器中保存的密码 date: 2018-02-11 17:54:51 tags: --- 导出Chrome浏览器中保存的密码 先知看到的,挺有意思,记录一下 不同浏览器 ...
- Rust入坑指南:步步为营
俗话说:"测试写得好,奖金少不了." 有经验的开发人员通常会通过单元测试来保证代码基本逻辑的正确性.如果你是一名新手开发者,并且还没体会到单元测试的好处,那么建议你先读一下我之前的 ...
- pytorch之 regression
import torch import torch.nn.functional as F import matplotlib.pyplot as plt # torch.manual_seed(1) ...
- IP multicast IP多播
https://networklessons.com/multicast/multicast-routing/ IP多播有两种模式,密集模式和稀疏模式: Dense Mode Sparse Mode ...