pandas操作mysql从放弃到入门
- 什么是Pandas
- 一、如何读取数据库-read_sql
- 二、如何筛选数据
- 三、如何连表-merge
- 四、如何删除一行或一列-drop
- 五、如何分组统计-groupyby
- 六、如何排序-sort_values/sort_index
- 七、如何重建索引-groupby(as_index=False)/reset_index
- 八、如何翻转dataframe-T
- 九、如何重命名列-rename
- 十、如何强制转换类型-astype
- 十一、如何在只有一列的情况下groupby并count-size
- 十二、如何操作时间-.dt.
- 十三、如何操作字符串-.str.
- 十四、如何进行数据透视-pivot/pivot_table
- 十五、如何进行可视化-plot
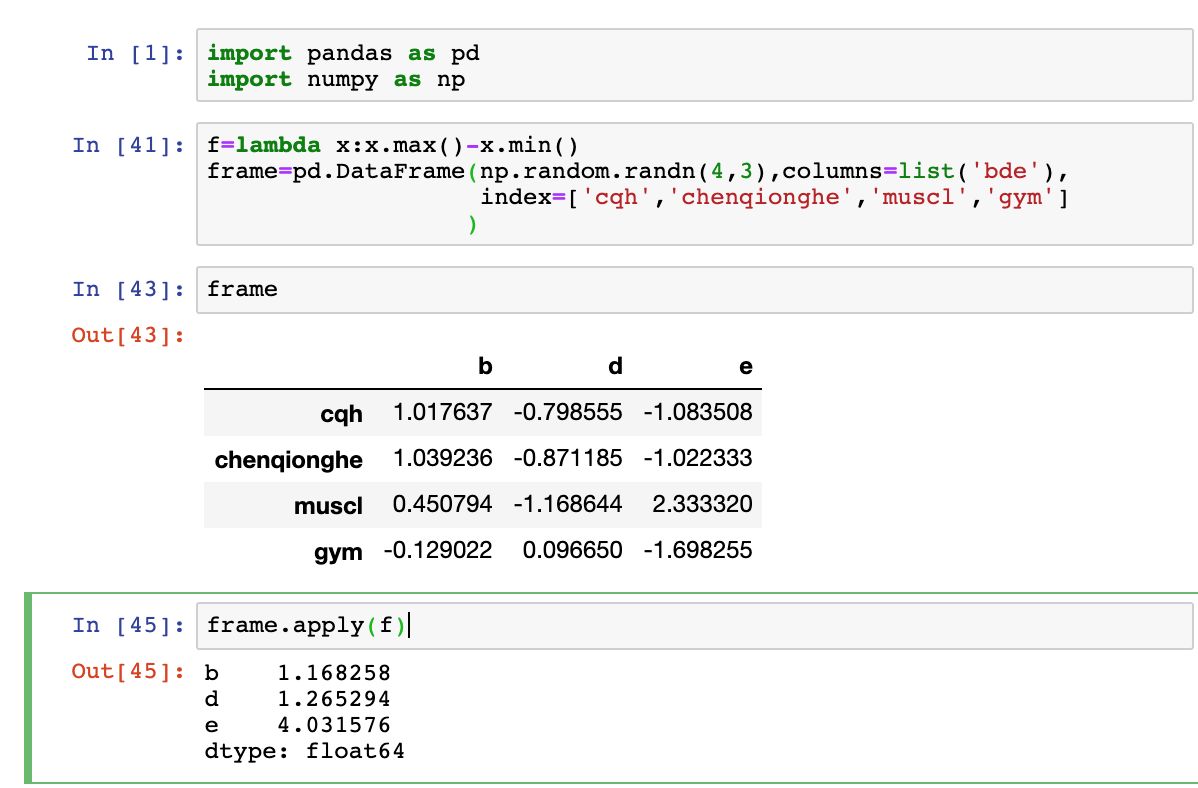
- 十六、如何应用函数和映射
- 十七、如何处理缺失数据
- 十八、如何使用多级索引
- 十九、如何删除重复数据-drop_duplicated
- 二十、如何替换值-replace
- 二十一、如何连接两个dataframe-concat
- 二十二、如何重新设置索引-reindex
- 二十二、如何重新采样-resample
- 二十三、如何打补丁-combine_first
- 二十四、如何进行排名-rank
- 二十五、如何应用函数修改原dataframe-指定参数inplace
什么是Pandas
Pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
Pandas纳入了大量库和一些标准的数据模型,提供了大量能使我们快速便捷地处理数据的函数和方法。
主要包含两种数据类型:Series和DataFrame
- Series可以理解为dict的升级版本,主数组存放numpy数据类型,index数据存放索引
- DataFrame相当于多维的Series,有两个索引数组,分别是行索引和列索引,可以理解成Series组成的字典
相关帮助文档
一、如何读取数据库-read_sql
示例代码如下
from sqlalchemy import create_engine
import pandas as pd
username = '用户名'
password = '密码'
host = '连接地址'
db = '数据库'
port = 端口号
link = f'''mysql+pymysql://{username}:{password}@{host}:{port}/{db}?charset=utf8'''
engine = create_engine(link, pool_recycle=3600)
核心方法read_sql
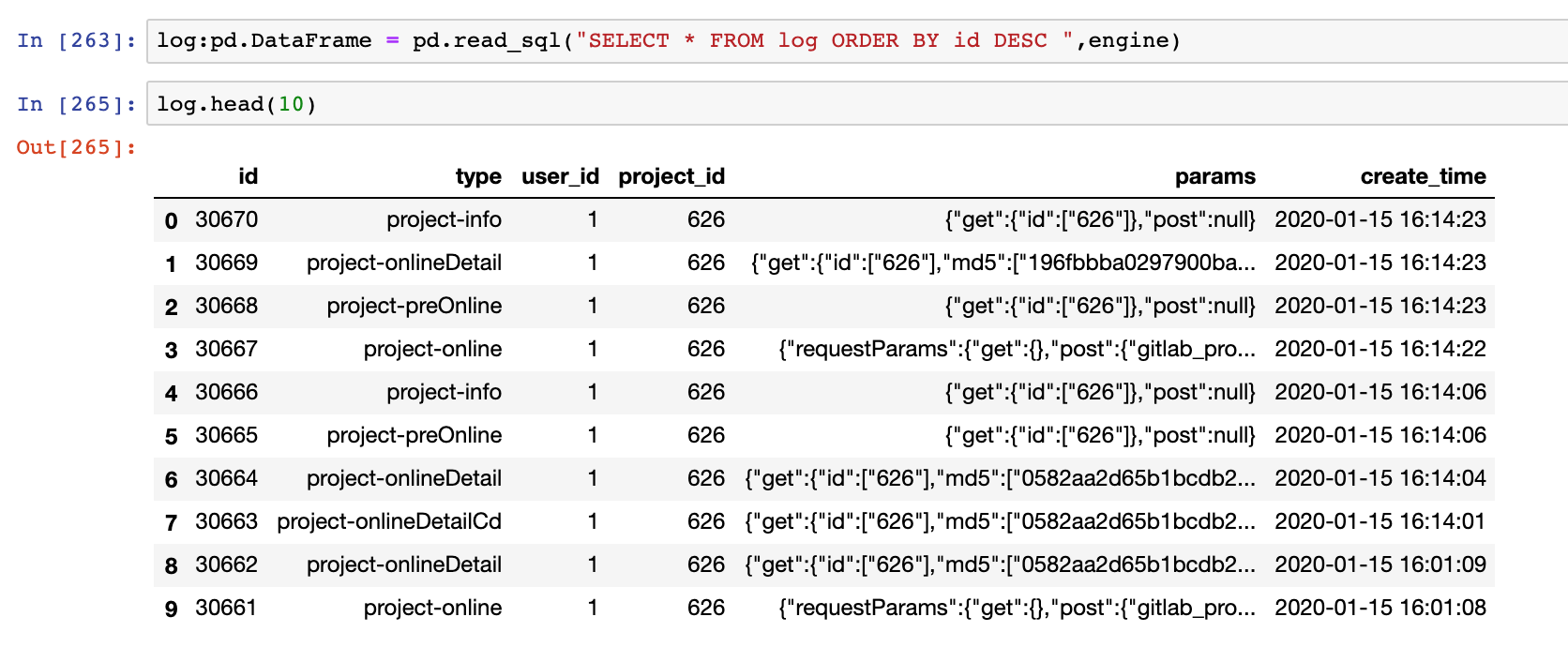
log:pd.DataFrame = pd.read_sql("SELECT * FROM log ORDER BY id DESC ",engine)
执行结果如下
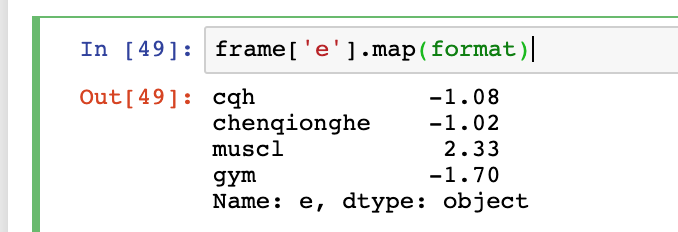
二、如何筛选数据
- 筛选创建时间大于某个时间点的记录
import datetime
log[log['create_time'] > '2020-01-15 16:14:22']

- 筛选指定列的DataFrame
直接传递数组给给DataFrame
logs[['user_id','type']]

- 获取一列Series
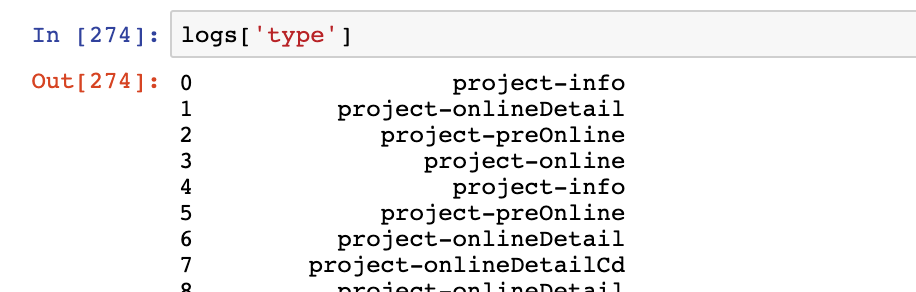
logs['type']
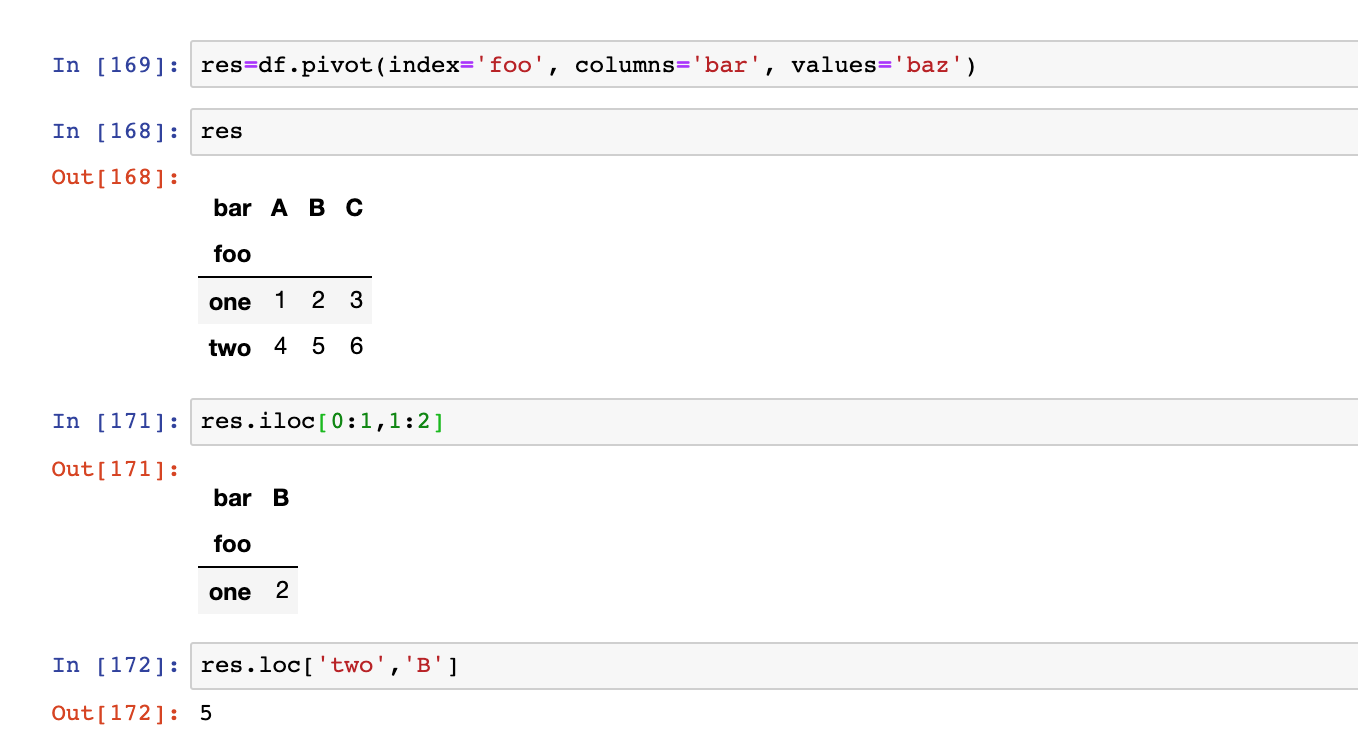
- iloc和loc
iloc[行,列]是根据行号和列号获取,loc[行索引 ,列索引]是根据索引名获取
三、如何连表-merge
现在我需要将user_id对应的用户名找出来,示例代码如下
#查询出所有的用户,以便将log和users做join
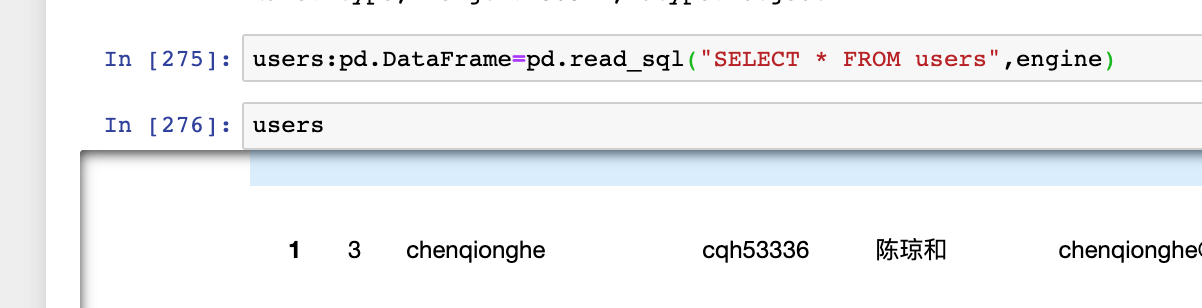
users:pd.DataFrame=pd.read_sql("SELECT * FROM users",engine)
users
*
users和log的字段太多,先做一下筛选
log=log[['type','user_id','project_id','create_time']]
users=users[['id','username','real_name']]
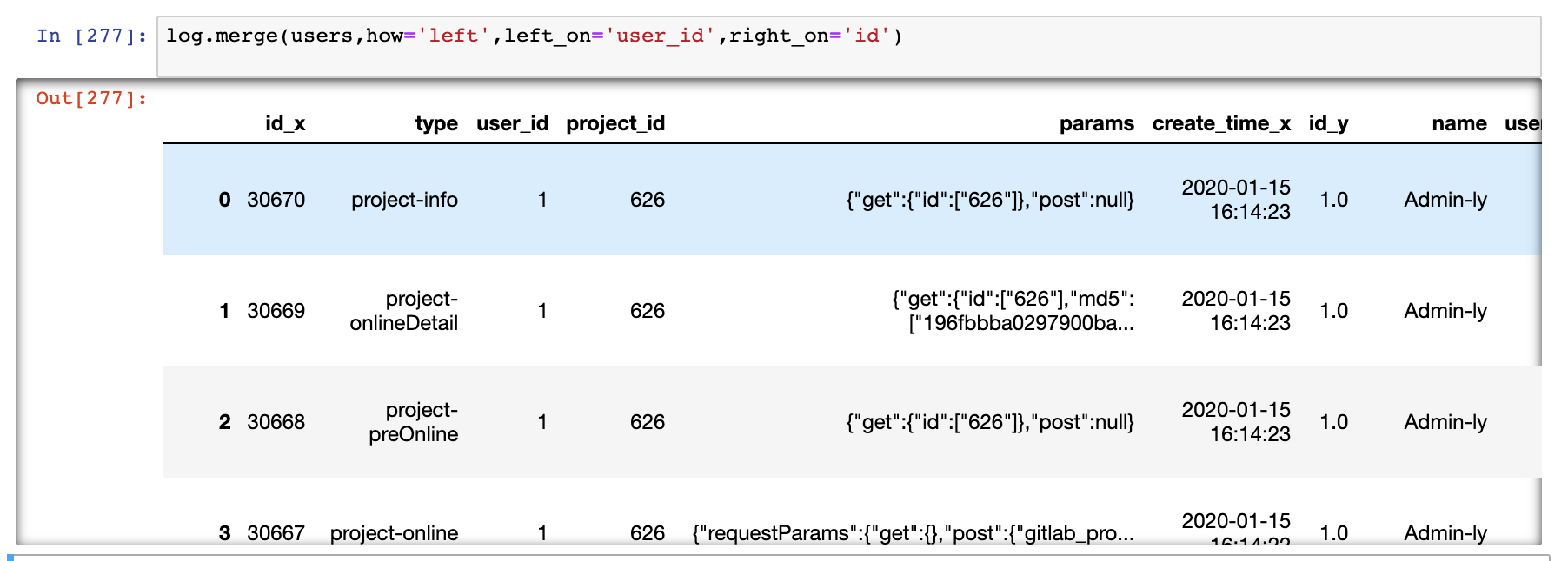
执行join,使用merge方法,how指定左连,left_on指定左表使用的字段, right_on指定右表使用的字段
log.merge(users,how='left',left_on='user_id',right_on='id')
四、如何删除一行或一列-drop
drop方法,axis为0代表行,1代表列
renameRes.drop('创建时间',axis=1)
五、如何分组统计-groupyby
dropRes.groupby(['type','real_name']).count()
groupby也可以可以传入一个能够访问索引上字段的函数
rng=pd.date_range('1/1/2020',periods=100,freq='D')
ts=pd.Series(np.random.randn(len(rng)),index=rng)
ts.groupby(lambda x:x.month).mean()
2020-01-31 0.182420
2020-02-29 0.200134
2020-03-31 -0.108818
2020-04-30 -0.187426
Freq: M, dtype: float64
六、如何排序-sort_values/sort_index
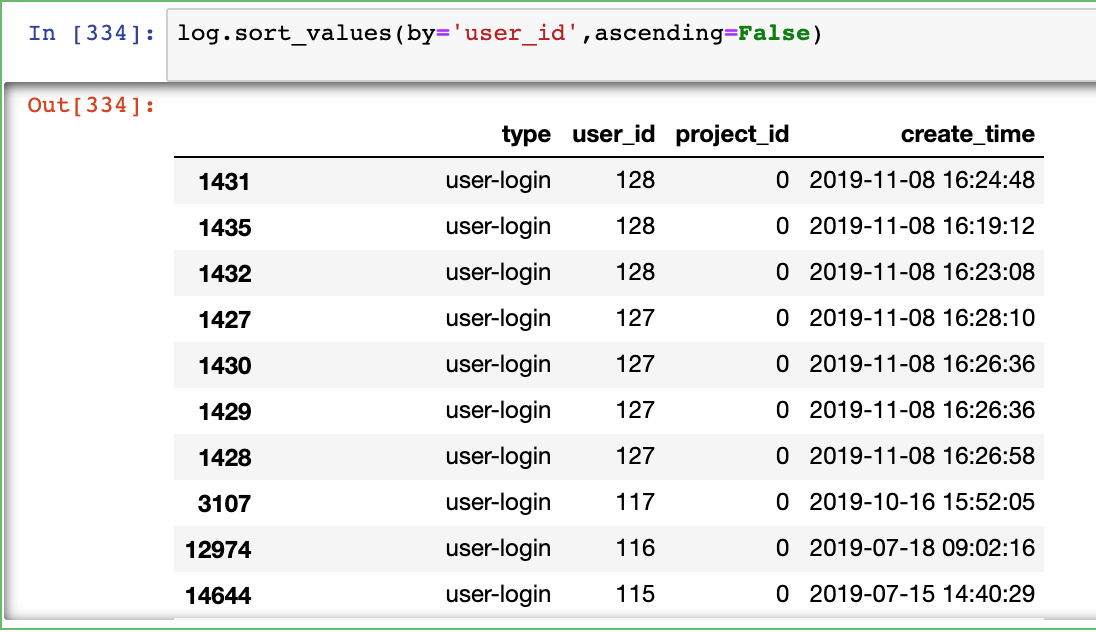
by指定字段,ascending指定升序还是降序
log.sort_values(by='user_id',ascending=False)
七、如何重建索引-groupby(as_index=False)/reset_index
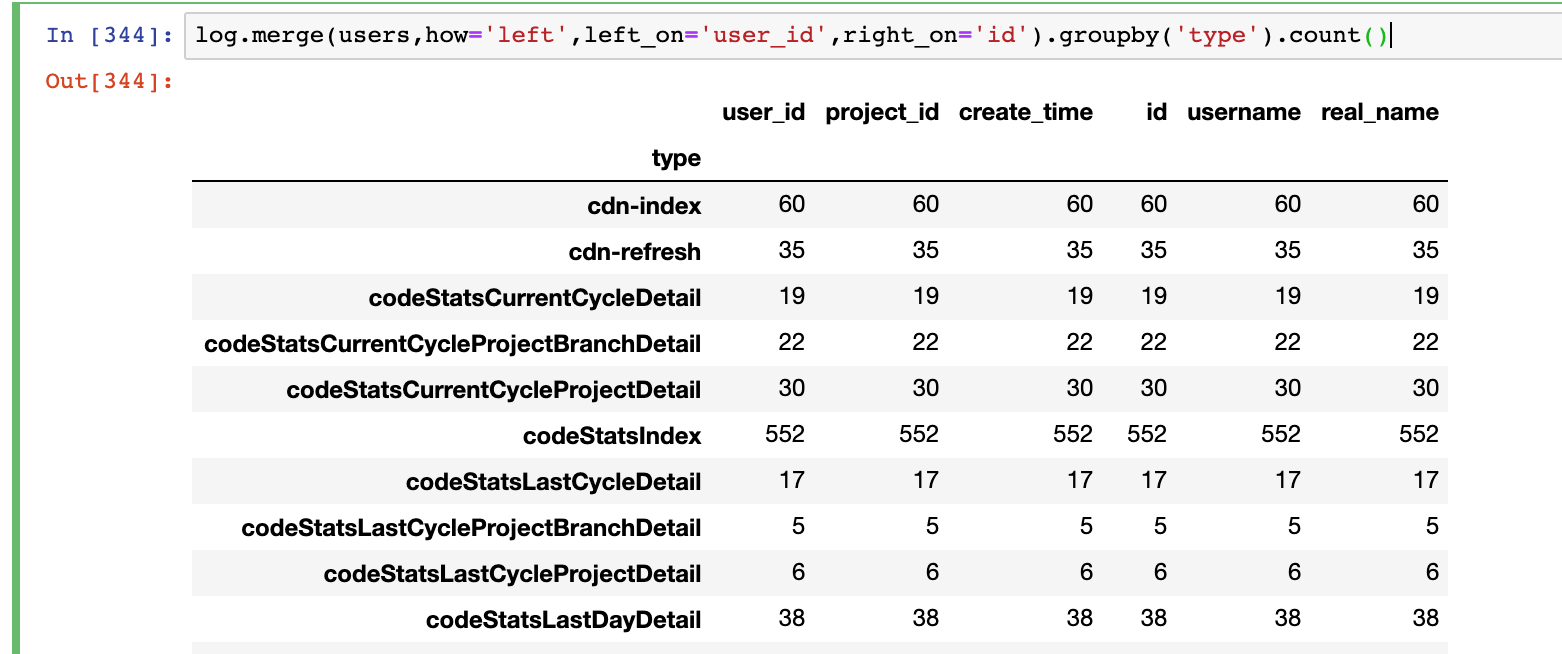
默认groupby后的结果是行索引是groupby的字段
log.merge(users,how='left',left_on='user_id',right_on='id').groupby('type').count()
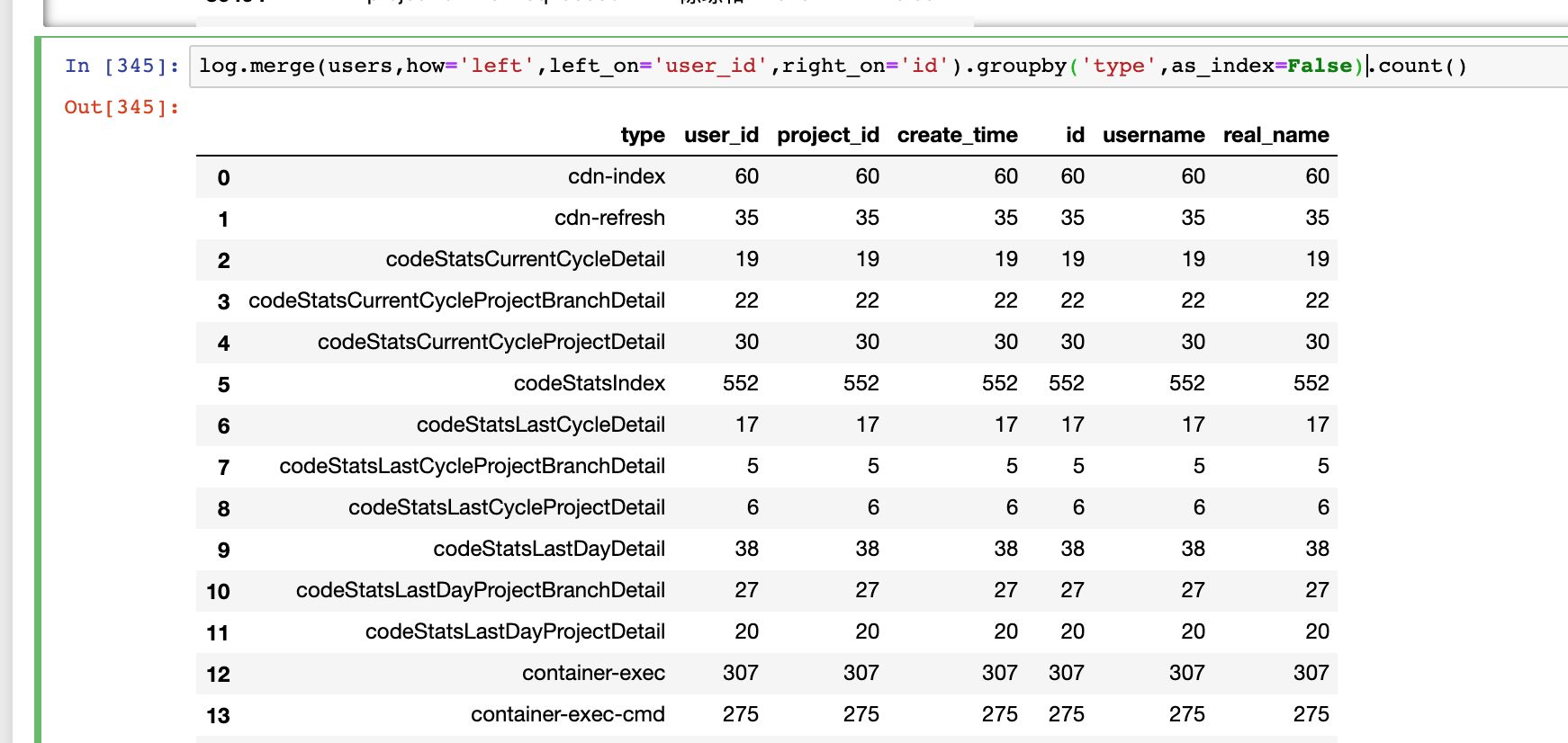
groupby指定参数as_index
log.merge(users,how='left',left_on='user_id',right_on='id').groupby('type',as_index=False).count()
另外,还可以count完后直接调用reset_index方法
log.merge(users,how='left',left_on='user_id',right_on='id').groupby('type').count().reset_index()
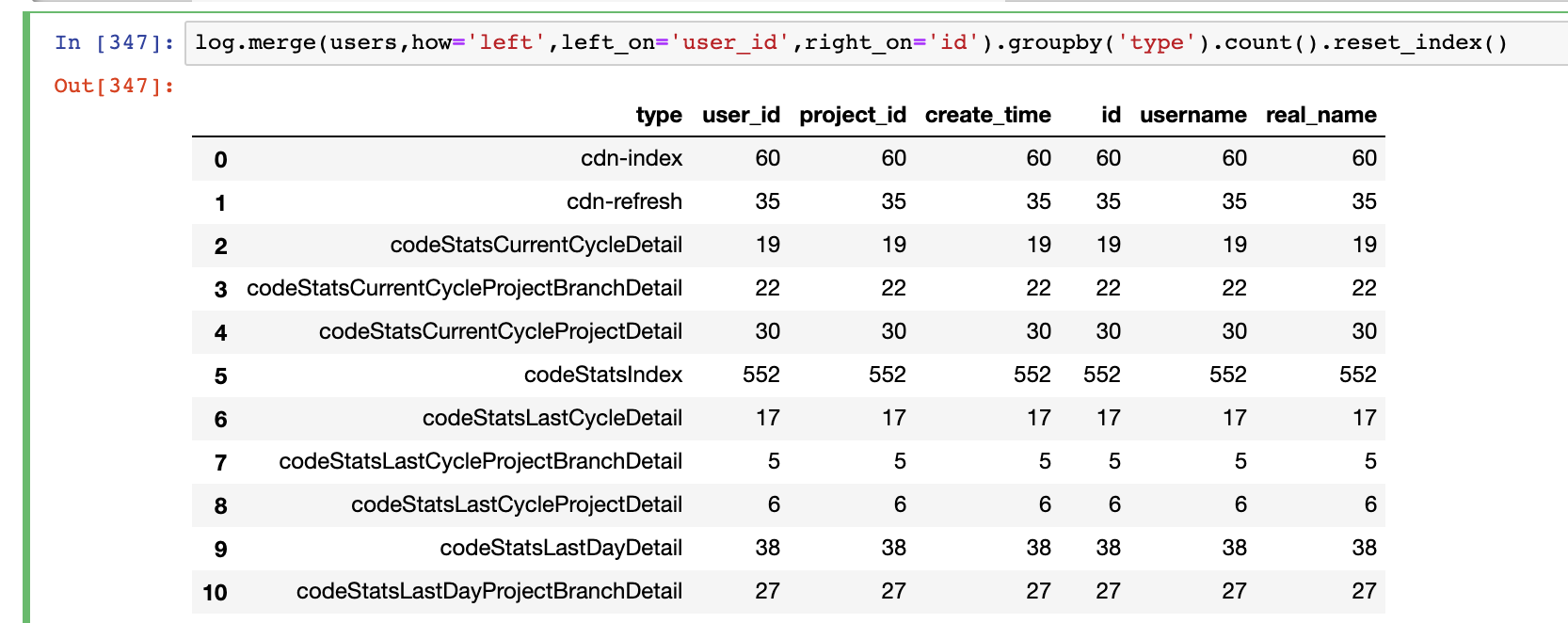
八、如何翻转dataframe-T
log.T
九、如何重命名列-rename
使用rename方法,传递一个字典即可,如下
pd.DataFrame = res[['type','username','real_name','create_time']].rename({'create_time':'创建时间'},axis=1)
十、如何强制转换类型-astype
log['create_time'].astype(str)
十一、如何在只有一列的情况下groupby并count-size
count是必须依赖其他列做统计的,当只有一列的时候如何还使用count,是看不出统计字段的,正确的方法应该是使用size
test4=pd.read_sql("SELECT `type` FROM log LIMIT 100",engine)
test4.groupby('type').size()

十二、如何操作时间-.dt.
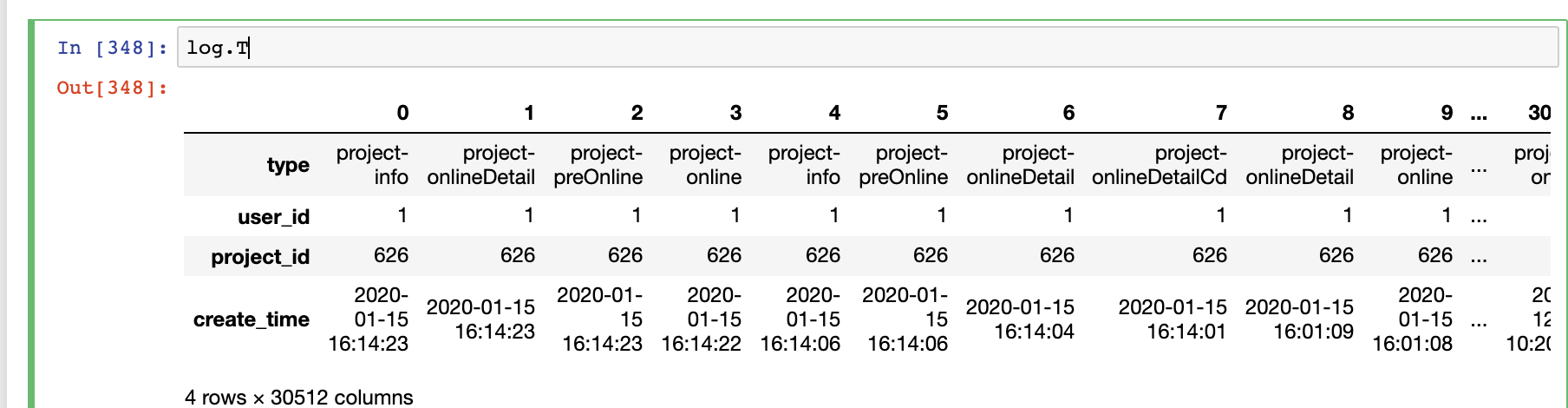
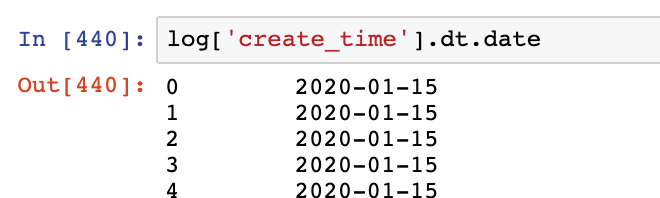
例如,要将create_time转为YY-MM-DD格式,可以使用函数.dt.date
log['create_time'].dt.date
具体方法可以参考Series的API文档的Datetime操作
十三、如何操作字符串-.str.
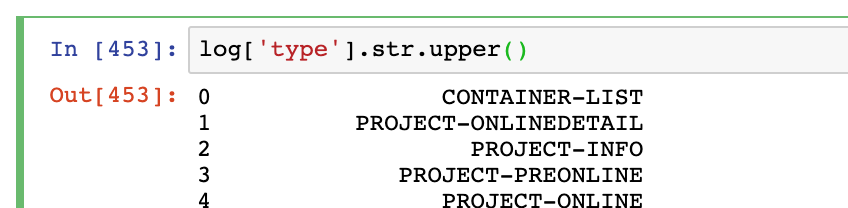
例如,转为大写
log['type'].str.upper()
具体方法可以参考Series的API文档的字符串操作
十四、如何进行数据透视-pivot/pivot_table
简单的理解就是一个更高级的groupby功能
df = pd.DataFrame({'foo': ['one', 'one', 'one', 'two', 'two',
'two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6],
'zoo': ['x', 'y', 'z', 'q', 'w', 't']})
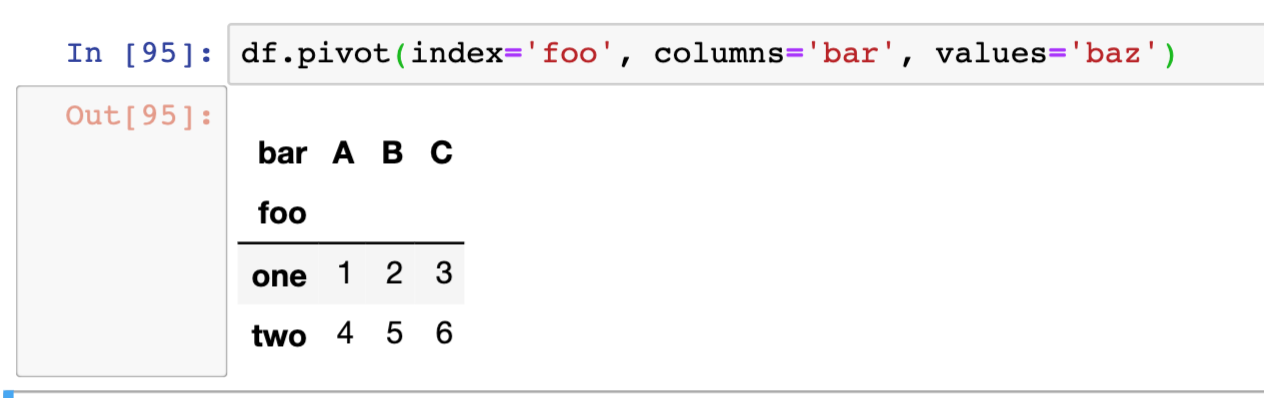
df.pivot(index='foo', columns='bar', values='baz')
pivot_table支持分组后再聚合操作
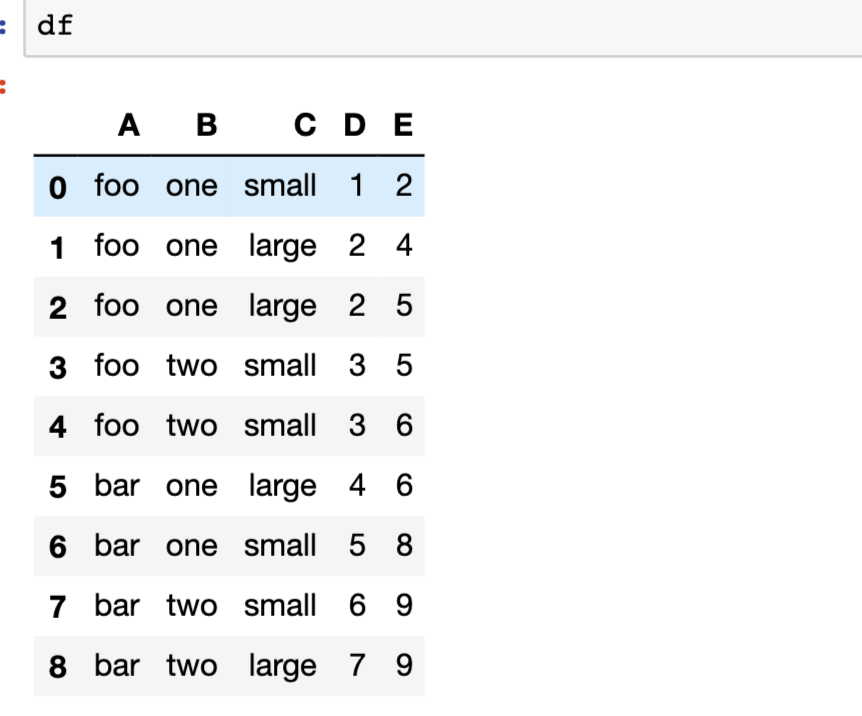
df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo",
"bar", "bar", "bar", "bar"],
"B": ["one", "one", "one", "two", "two",
"one", "one", "two", "two"],
"C": ["small", "large", "large", "small",
"small", "large", "small", "small",
"large"],
"D": [1, 2, 2, 3, 3, 4, 5, 6, 7],
"E": [2, 4, 5, 5, 6, 6, 8, 9, 9]}
)
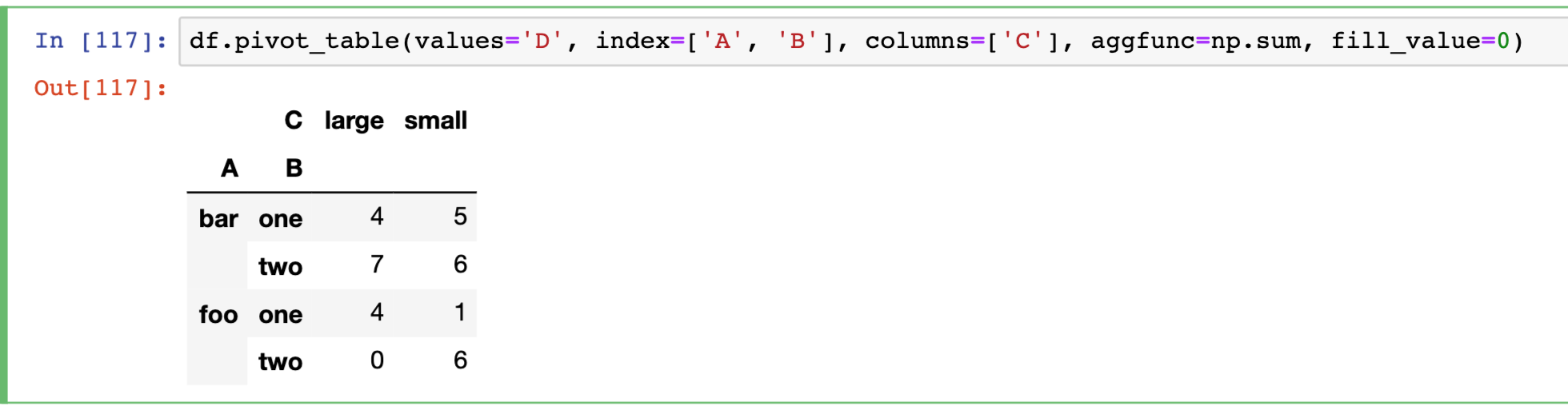
根据ABC分组,计算D的值,AB为行索引,C为列索引再使用sum函数,如下
df.pivot_table(values='D', index=['A', 'B'], columns=['C'], aggfunc=np.sum, fill_value=0)
十五、如何进行可视化-plot
一般使用matplotlib进行绘图
例如,统计所有的操作日志最多的前10个绘制直方图
先取出这些数据,如下
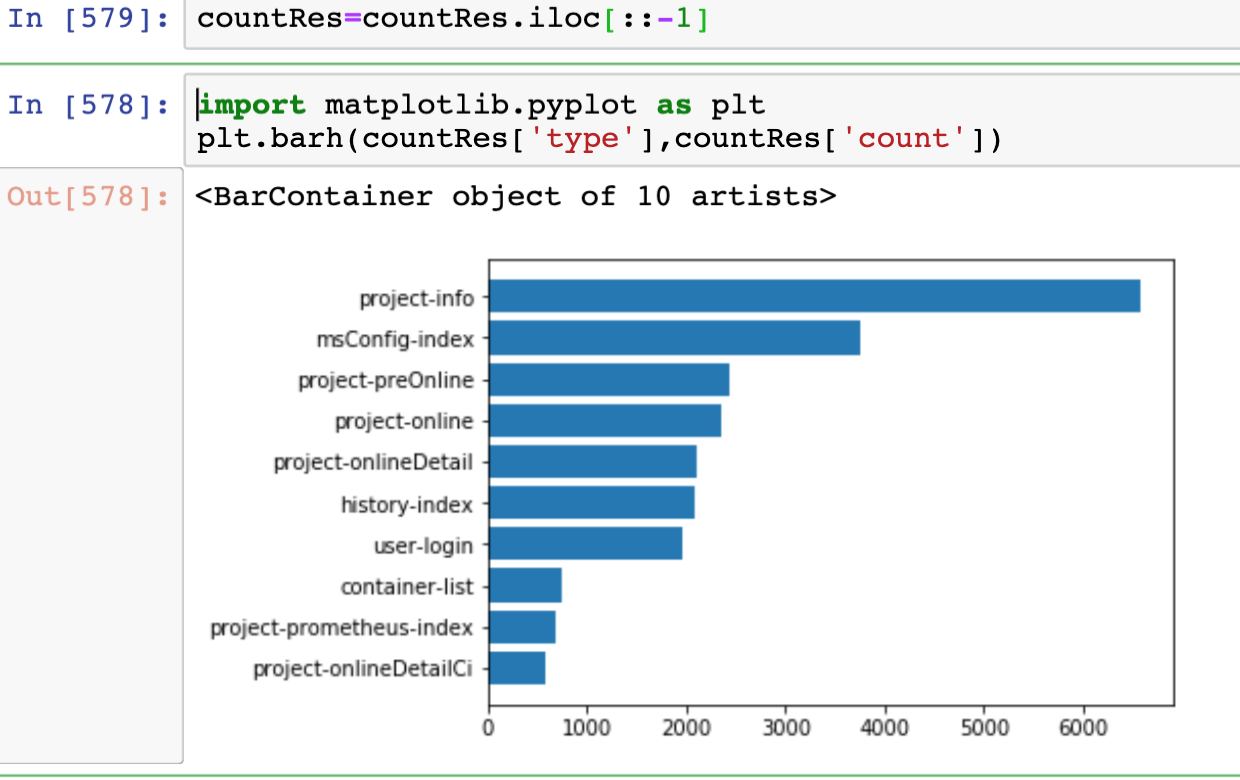
#获取所有操作类型最多的10条数据
countRes=log.groupby('type',as_index=False).count().drop(['create_time','project_id'],axis=1).rename({'user_id':'count'},axis=1).sort_values(by='count',ascending=False).head(10)

为了让图是递增的状态,我们反转一下
countRes=countRes.iloc[::-1]
再使用matplotlib绘制直方图
import matplotlib.pyplot as plt
plt.barh(countRes['type'],countRes['count'])
十六、如何应用函数和映射
apply(DataFrame)
DataFrame的函数,apply将函数应用到由各列或行所形成的一维数组上,默认是传入列的Series,可以指定axis=1传入行
applymap(DataFrame)
DataFrame的函数,对每个元素应用函数

map/apply(Series)
对应Dataframe的applymap
十七、如何处理缺失数据
pands使用NaN(Not a Number)表示缺失数据,处理方法有
- dropna:对轴标签进行过滤
- fillna:用指定值或插值方法(如ffill或bfill)填充缺失数据
- isnull:返回一个含有布尔值的对象
- notnull:isnull的否定形式
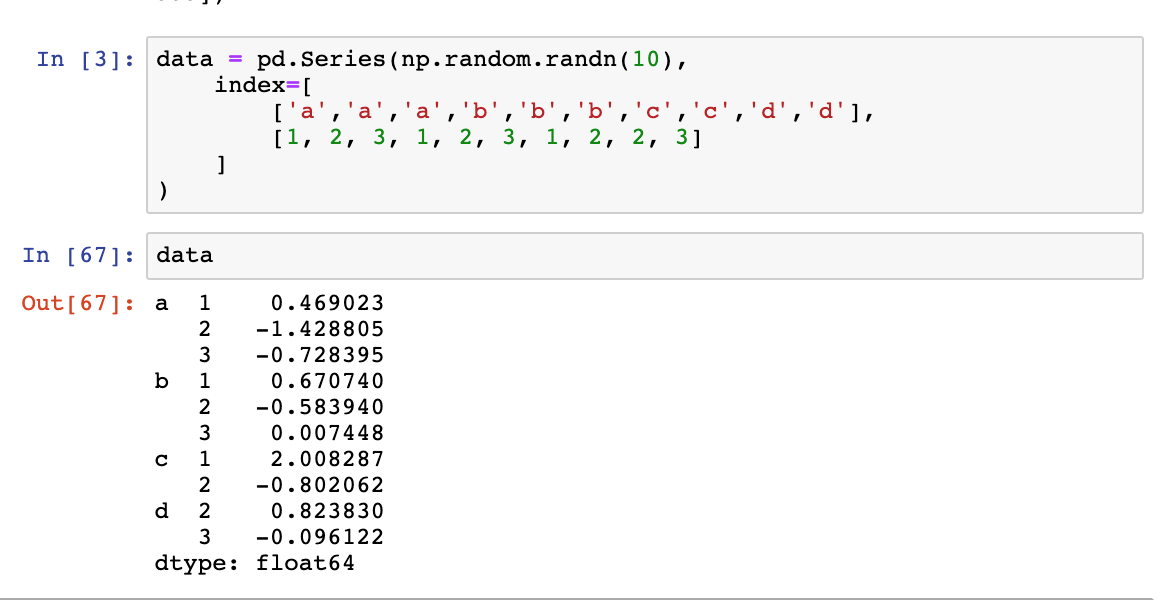
十八、如何使用多级索引
- Series多级索引
data = pd.Series(np.random.randn(10),
index=[
['a','a','a','b','b','b','c','c','d','d'],
[1, 2, 3, 1, 2, 3, 1, 2, 2, 3]
]
)
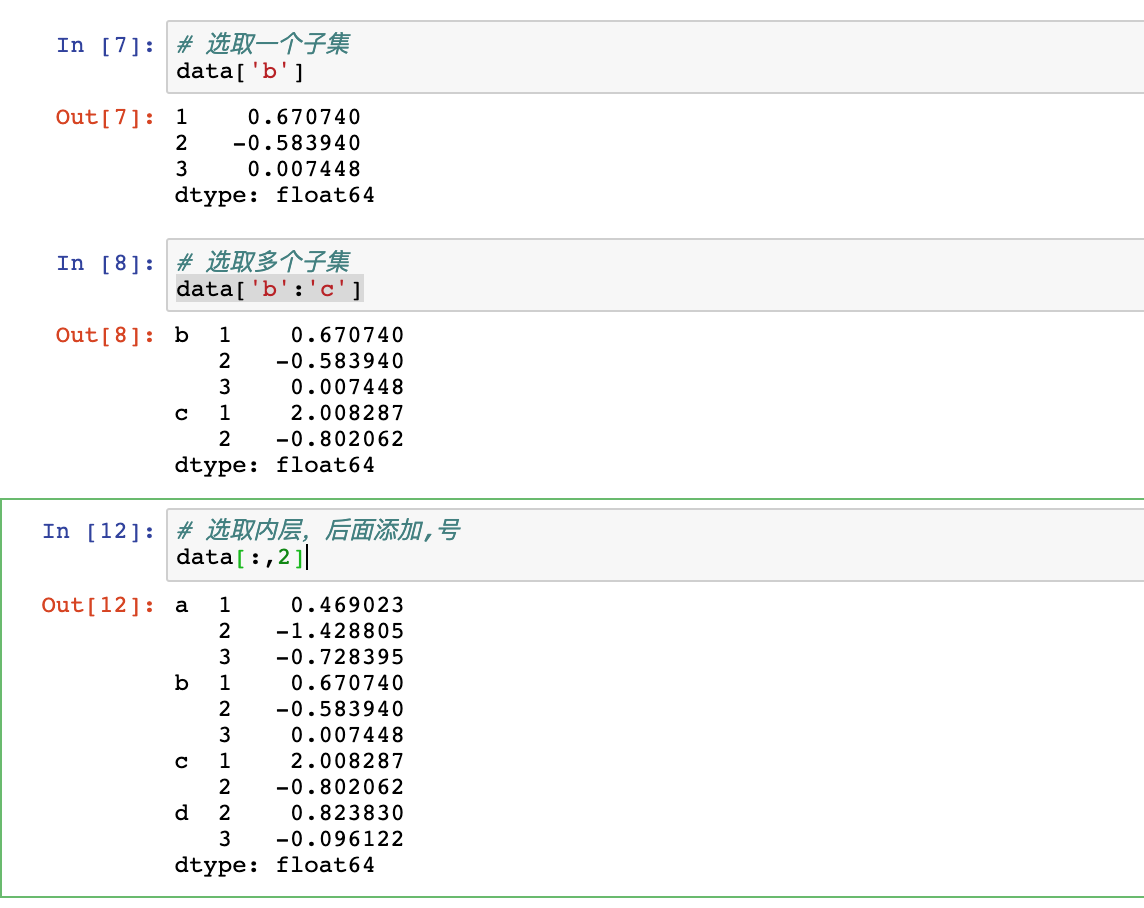
选取一个子集
data['b']
选取多个子集
data['b':'c']
选取内层:,号后面添加行号
data[:,2]
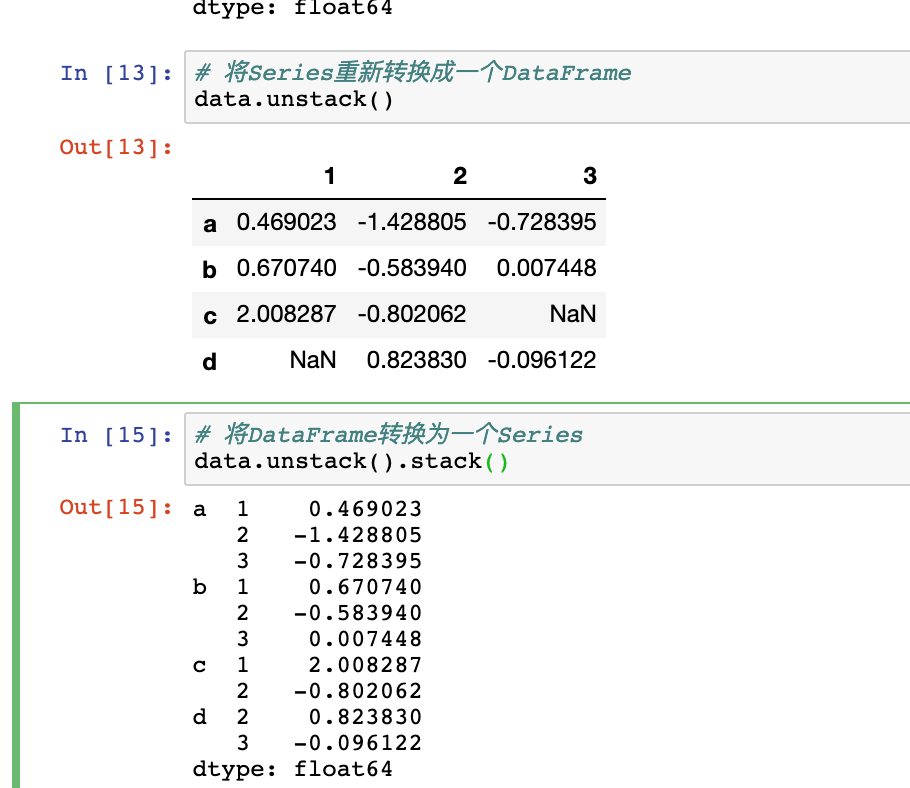
- Series和DataFrame互转
#Series转换为DataFrame
data.unstack()
#将DataFrame转换为一个Series
data.unstack().stack()
- DataFrame的多级索引
frame=pd.DataFrame(np.arange(12).reshape((4,3)),
index=[
['a','a','b','b'],
[1,2,1,2]
],
columns=[
['Ohio','Ohio','Colorado'],
['Green','Red','Green']
],
)
- 给索引命名
frame.index.names=['key1','key2']
frame.columns.names=['state','color']

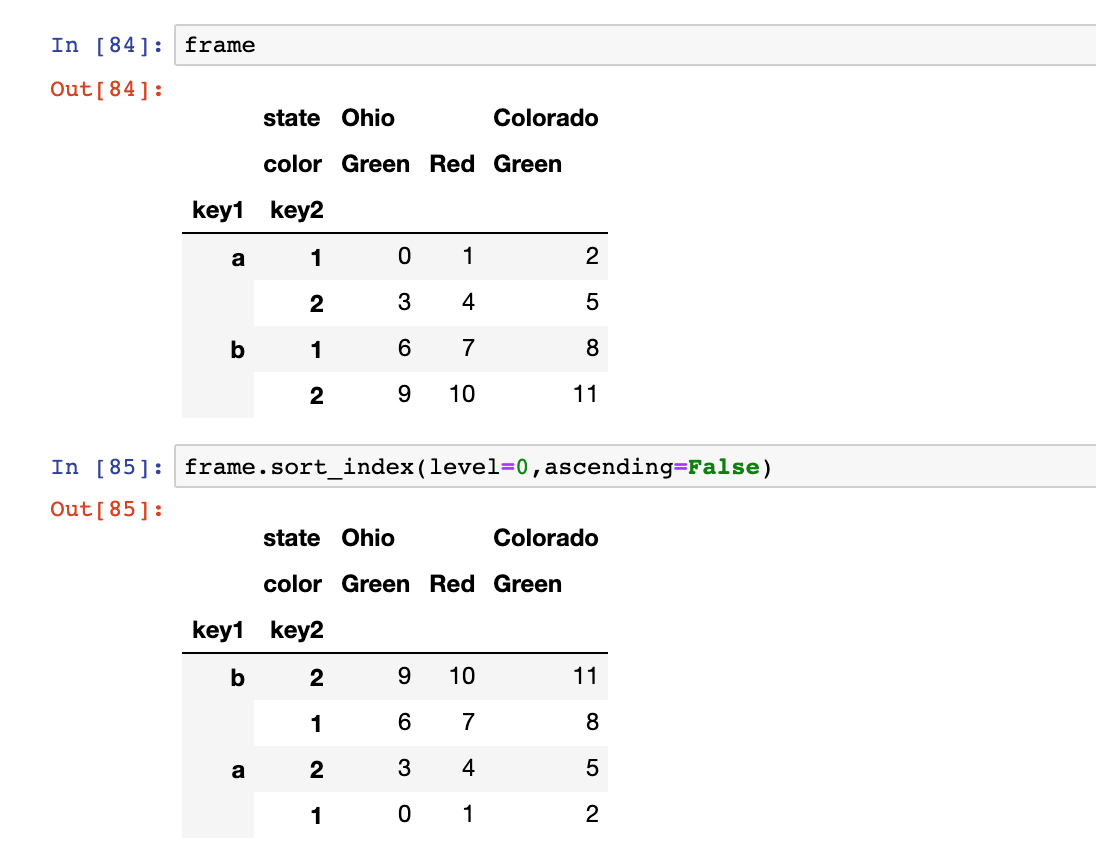
- swaplevel:重排分级顺序,互换级别的对象
frame.swaplevel('key1','key2')

- sort_index:根据单个级别中的值对数据进行反序
frame.sort_index(level=0,ascending=False)
- set_index:将其一个或多个列转换为行索引,并创建一个新的DataFrame
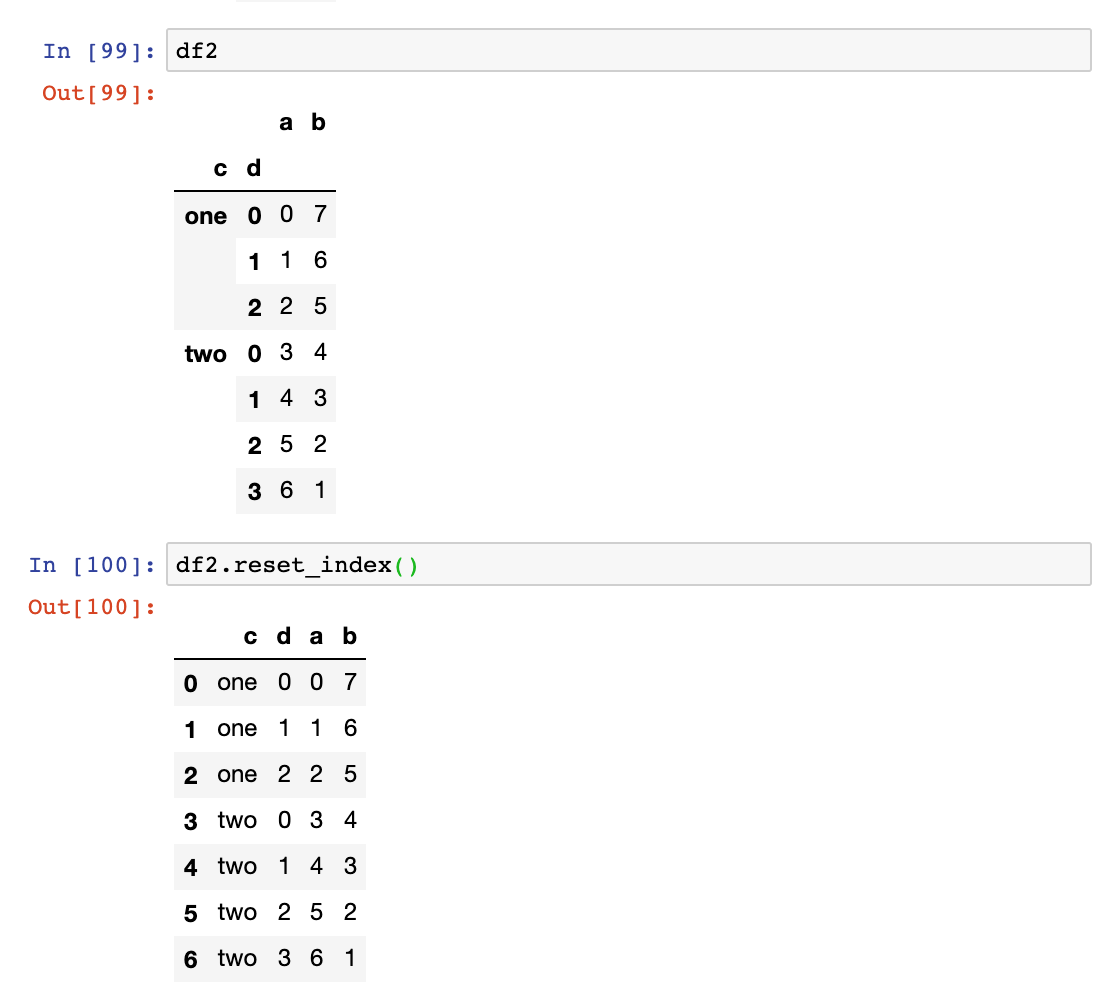
df=pd.DataFrame({
'a':range(7),
'b':range(7,0,-1),
'c':['one','one','one','two','two','two','two'],
'd':[0,1,2,0,1,2,3]
})
df.set_index(['c','d'])

- reset_index:功能和set_index相反,层次化索引的级别会被转移到列里面
十九、如何删除重复数据-drop_duplicated
data=pd.DataFrame({
'k1':['one']*3 + ['two']*4,
'kw':[1,1,2,3,3,4,4]
})

data.drop_duplicates()

二十、如何替换值-replace
df = pd.DataFrame({'foo': ['one', 'one', 'one', 'two', 'two',
'two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6],
'zoo': ['x', 'y', 'z', 'q', 'w', 't']})
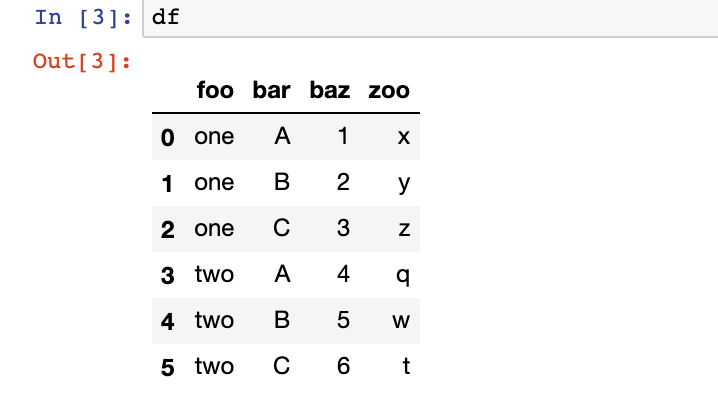
替换A和B为chenqionghe,第一个参数为查找值,第二个参数为替换的值
df.replace(['A','B'],'chenqionghe')

也可以传入字典,替换多个值
df.replace({'A':'cqh','B':'chenqionghe'})

二十一、如何连接两个dataframe-concat
df1=DataFrame(np.arange(6).reshape(3,2),
index=list('abc'),
columns=['one','two']
)
df2=DataFrame(5+np.arange(4).reshape(2,2),
index=list('ac'),
columns=['three','four']
)

列拼接
pd.concat([df1,df2],sort=False)

行拼接
pd.concat([df1,df2],axis=1,sort=False)

二十二、如何重新设置索引-reindex
frame=pd.DataFrame(np.arange(9).reshape((3,3)),
index=['a','b','c'],
columns=['light','weight','baby']
)
#默认修改行索引
frame2=frame.reindex(['a','b','c','d'])
#同时修改行索引和列索引
frame.reindex(index=['a','b','c','d'],columns=['light','gym','muscle'])
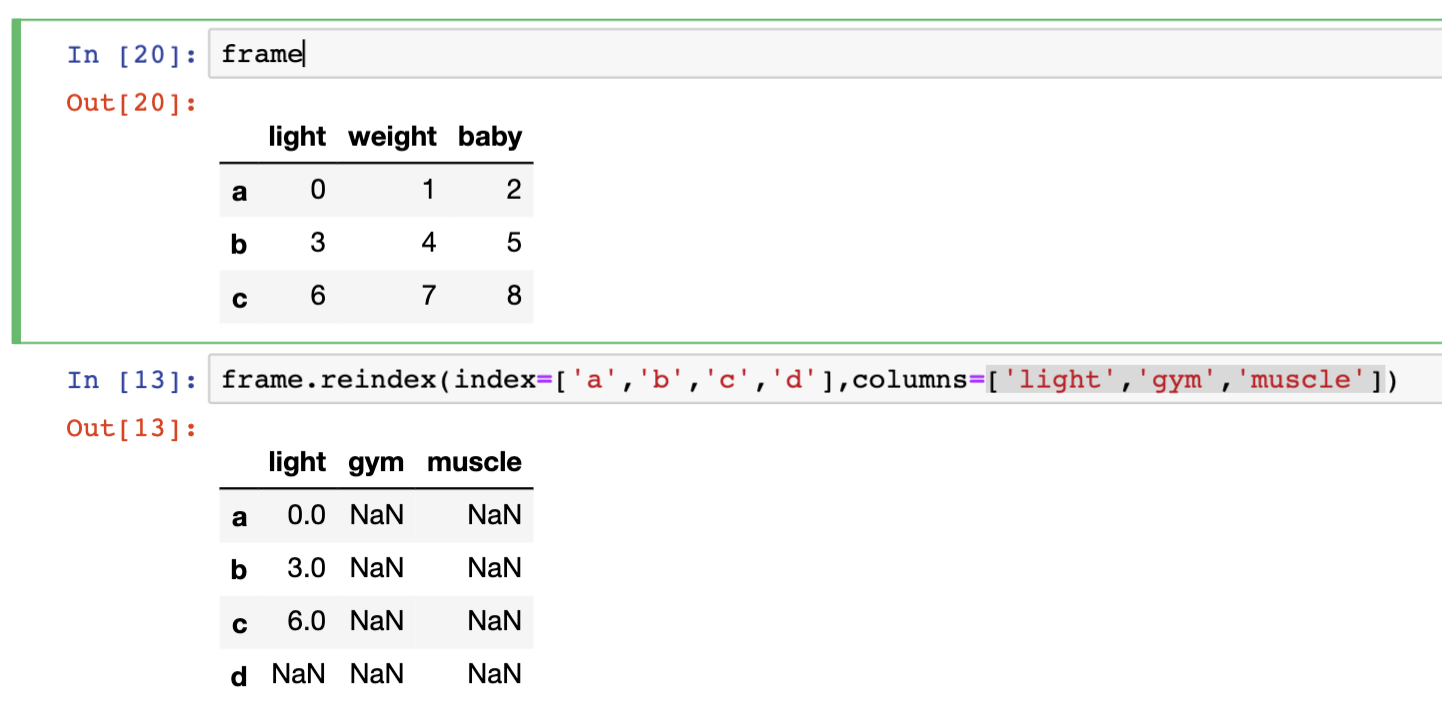
二十二、如何重新采样-resample
创建3个周三的时间序列
ts1=pd.Series(
np.random.randn(3),
index=pd.date_range('2020-6-13',periods=3,freq='W-WED')
)
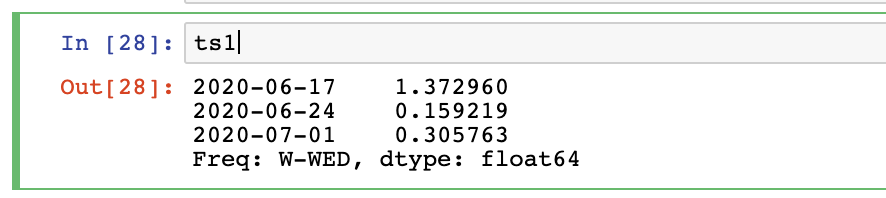
升采样转为每个工作日
ts1.resample('B').asfreq()
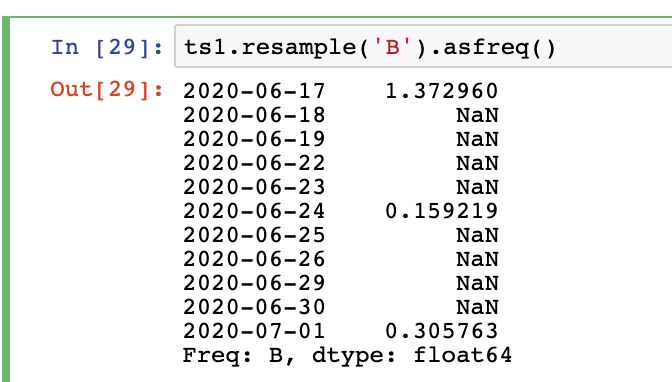
指定为ffill的填充
ts1.resample('B').ffill()
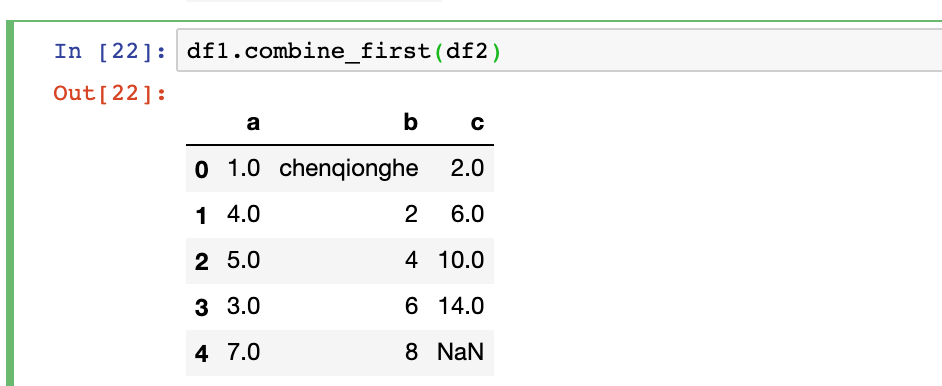
二十三、如何打补丁-combine_first
combine_first相当于用参数对象中的数据为调用者对象的缺失数据”打补丁“
df1=pd.DataFrame({
'a':[1,np.nan,5,np.nan],
'b':[np.nan,2,np.nan,6],
'c':range(2,18,4)
})
df2=pd.DataFrame({
'a':[5,4,np.nan,3,7],
'b':['chenqionghe',3,4,6,8]
})
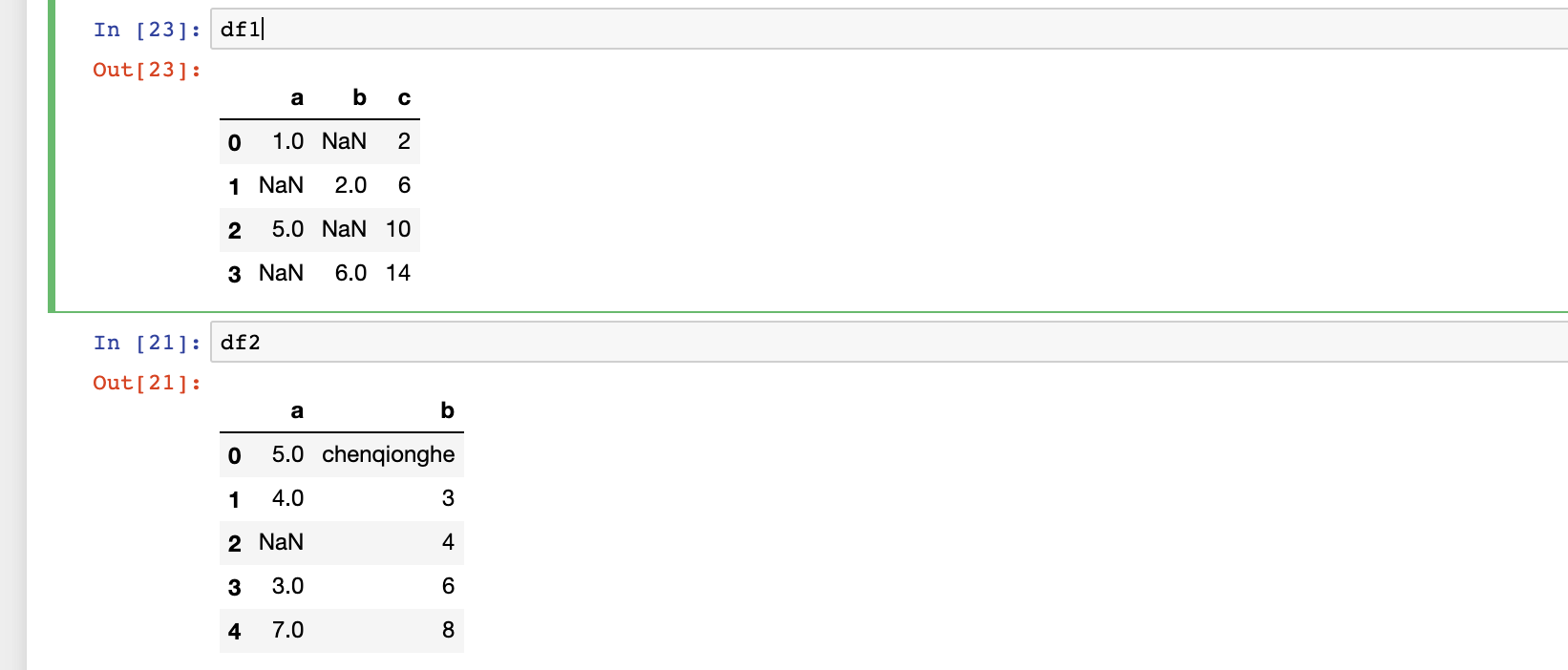
然后我们可以用df2的值给d1打补丁,如下
df1.combine_first(df2)
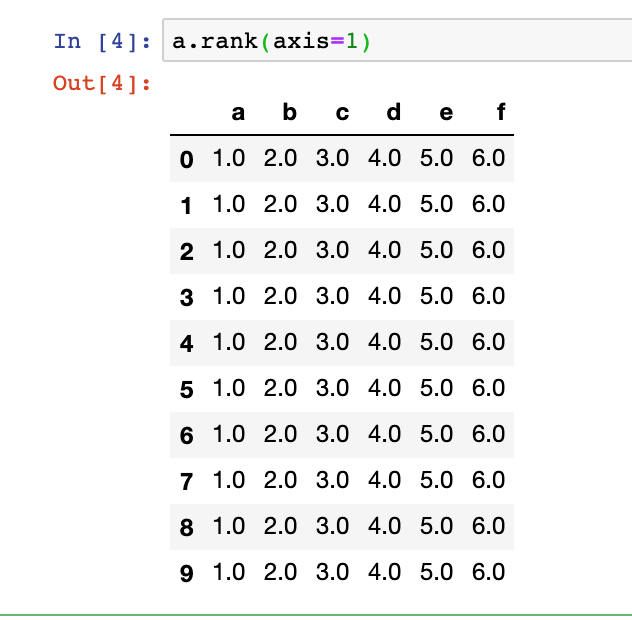
二十四、如何进行排名-rank
a=pd.DataFrame(np.arange(60).reshape(10,6),columns=['a','b','c','d','e','f'])
默认是对行进行排序,如下
a.rank()

可以传axis=1对列进行排序
a.rank(axis=1)
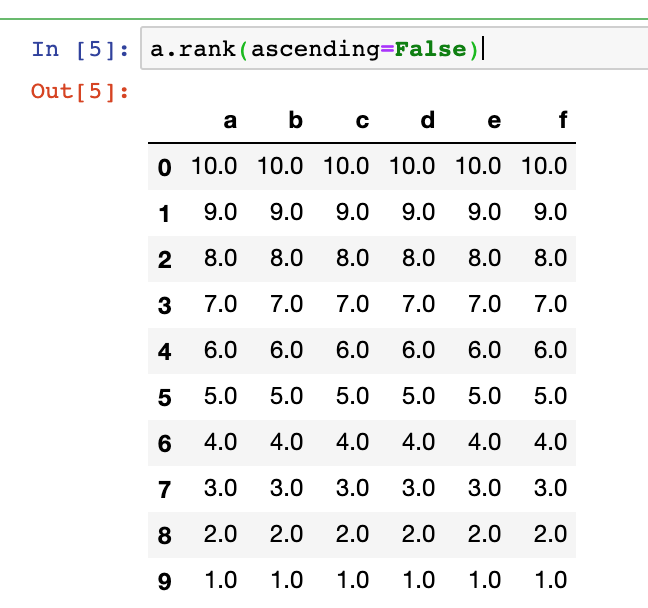
默认是升序,可以传入ascending=False进行降序
a.rank(ascending=False)
二十五、如何应用函数修改原dataframe-指定参数inplace
pandas 中 inplace 参数在很多函数中都会有,它的作用是:是否在原对象基础上进行修改
- inplace = True:不创建新的对象,直接对原始对象进行修改;
- inplace = False:对数据进行修改,创建并返回新的对象承载其修改结果。
默认是False,即创建新的对象进行修改,原对象不变,和深复制和浅复制有些类似。
pandas操作mysql从放弃到入门的更多相关文章
- python数据库操作 - MySQL入门【转】
python数据库操作 - MySQL入门 python学院 2017-02-05 16:22 PyMySQL是Python中操作MySQL的模块,和之前使用的MySQLdb模块基本功能一致,PyMy ...
- 2-MySQL DBA笔记-MySQL安装部署和入门
第2章 MySQL安装部署和入门 第1章介绍了MySQL的一些基础知识,本章将为读者介绍MySQL的部署.安装及一些常用命令和参数的设置.2.1 如何选择MySQL版本 在选择MySQL的版本时,要根 ...
- python & pandas链接mysql数据库
Python&pandas与mysql连接 1.python 与mysql 连接及操作,直接上代码,简单直接高效: import MySQLdb try: conn = MySQLdb.con ...
- .Net Core在Ubuntu上操作MySql折腾实录
.Net Core 2.0 发布也这么久了,一直想着折腾着玩玩,无奈一直没时间,这几天准备开始好好学习下C#在跨平台方面的应用,记录下来以备自己以后回忆.学习. 本篇博客的主要内容: MySql在Ub ...
- python操作mysql——mysql.connector
连接mysql, 需要mysql connector, conntector是一种驱动程序,python连接mysql的驱动程序,mysql官方给出的名称为connector/python, 可参考m ...
- 转:C++操作mysql方法总结(1)
原文:http://www.cnblogs.com/joeblackzqq/p/4332945.html C++通过mysql的c api和通过mysql的Connector C++ 1.1.3操作m ...
- python&pandas 与mysql 连接
1. python 与mysql 连接及操作,直接上代码,简单直接高效: import MySQLdb try: conn = MySQLdb.connect(host='localhost',use ...
- 使用php的mysqli扩展库操作mysql数据库
简单介绍mysqli: 1.mysqli(mysql improve mysql扩展库的增强版) mysql扩展库和mysqli扩展库的区别 1.mysqli的稳定性 安全性 和 执行效率有所提高 ...
- C++操作mysql方法总结(1)
C++通过mysql的c api和通过mysql的Connector C++ 1.1.3操作mysql的两种方式 使用vs2013和64位的msql 5.6.16进行操作 项目中使用的数据库名为boo ...
随机推荐
- 程序中打开IE浏览器并访问指定地址
最简单的方法 Process.Start("iexplore.exe"); //直接打开IE浏览器(打开默认首页) Process.Start(" ...
- 如何检查linux是否安装了php
方法一.在终端通过php -v命令来查看一下当前php的版本.如果没有安装php,一般会提示没有php这个命令的. 2 方法二.在终端查询安装的包中是否有php,以redhat为例,则可以执行如下命令 ...
- win10 uwp 在 Canvas 放一个超过大小的元素会不会被裁剪
我尝试在一个宽度200高度200的 Canvas 放了一个宽度 300 高度 300 的元素,这个元素会不会被 Canvas 裁剪了? 经过我的测试,发现默认是不会被裁剪 火火问了我一个问题,如果有一 ...
- springboot aop的使用 学习总结
版权声明:本文为博主武伟峰原创文章,转载请注明地址http://blog.csdn.net/tianyaleixiaowu. aop是spring的两大功能模块之一,功能非常强大,为解耦提供了非常优秀 ...
- python基础数据类型汇总
list和dict 在循环一个列表和字典时,最好不要删除其中的元素,这样会使索引发生改变,从而报错! lis = [11, 22, 33, 44, 55] for i in range(len(lis ...
- tf.train.string_input_producer()
处理从文件中读数据 官方说明 简单使用 示例中读取的是csv文件,如果要读tfrecord的文件,需要换成 tf.TFRecordReader import tensorflow as tf file ...
- H3C 聚合链路负载分担原理
- Javascript 防扒站,防止镜像网站
自己没日没夜敲出来的站,稍微漂亮一点,被人看上了就难逃一扒,扒站是难免的,但不能让他轻轻松松就扒了: 前些天有个朋友做的官网被某不法网站镜像,严重影响到 SEO,当时的解决方法是通过屏蔽目标 IP 来 ...
- 个人笔记-快速搭建k8s-1.16.0
1.阿里云购买4台实例 4核16G 120G云盘 centos7.6 固定带宽1M(双主双从) https://www.aliyun.com/ 2.安装dockeryum remove docker ...
- 百度人脸识别集成错误:Build command failed. Error while executing process F:\dev\Android\Sdk\cmake\3.6.4111459\bin\cmake.exe with arguments
大概是这么个错误 Build command failed. Error while executing process F:\dev\Android\Sdk\cmake\3.6.4111459\bi ...