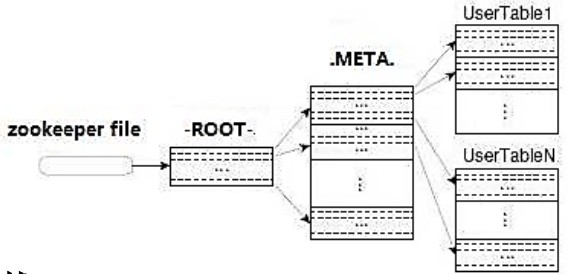
HRegion 分配与寻址
- 哪些Region 已经分配到哪些Region Server中
- 哪些Region server 可用
- 哪些Region 尚未分配
<表名,startRowkey,创建时间>, 如:quote_data,,
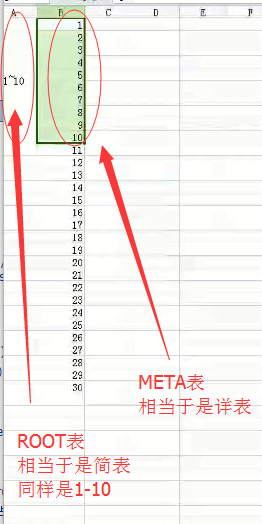
- .META.表
- -ROOT-表

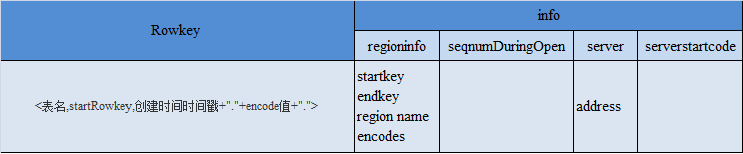

- startKey,region的开始key,第一个region的startKey是空字符串;
- endKey,region的结束key,最后一个region的endKey是空字符串;
- encode值,该值会作为hdfs文件系统的一个目录,假设encode值为: da1aec29c13725e29786e920bcc2d7b0 ,存放如下如图:
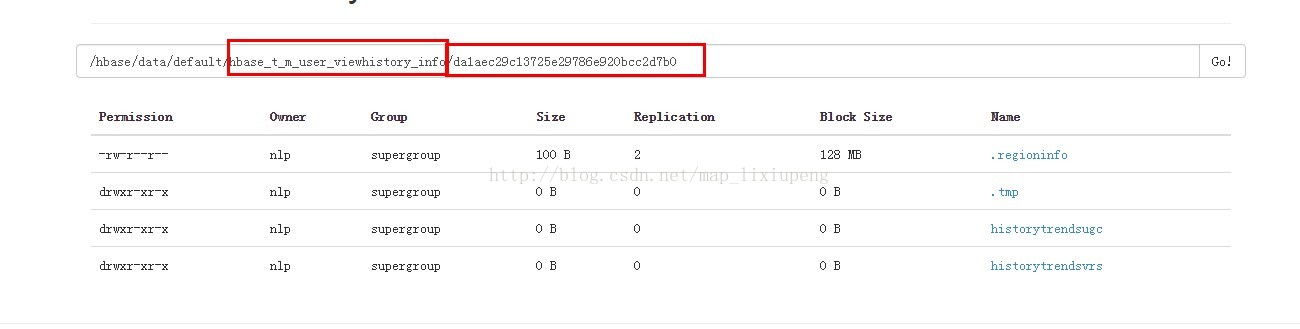
- 用来存放region的文件夹的名字是region name的哈希值,因为region的name中有startkey,所以可能含有非法字符,所以取它的hash值来作为目录名称存放region文件。
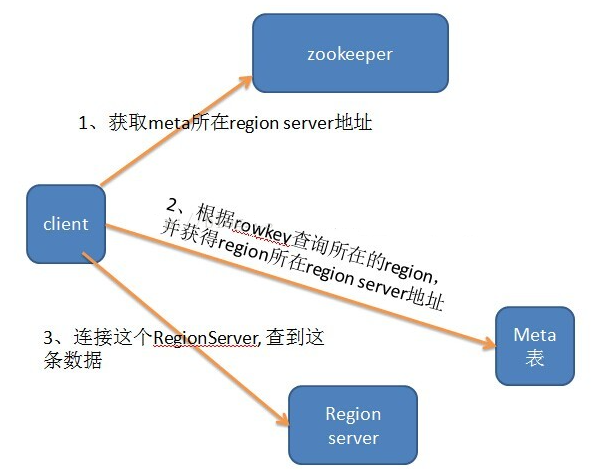
HRegion是按照表名+开始/结束主键,即表名+主键范围来区分的。由于主键范围是连续的,所以一般用开始主键就可以表示相应的HRegion了。 不过,因为我们有合并和分隔操作,此时,如果正好在执行这些操作的过程中出现死机,那么就可能存在多份表名和开始主键相同的数据,这样的话,只有光靠开始主键就不够了, 这就需要通过HBase的元数据信息来区分哪一份才是正确的数据文件。 为此,为了区分这样的情况,每个HRegion都有一个'regionId'来标识它的唯一性。所以一个HRegion的表达符,最终是:表名+开始主键+唯一Id,
即tablename+startkey+regionId。 用户表的region名中regionId使用时间戳标识的,.META.表的region名的regionId是直接用数字标记的。
HRegion 分配与寻址的更多相关文章
- HBase 原理
遗留问题: 数据在更新时首先写入Log(WAL log)和内存(MemStore)中,MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并且将老的 ...
- HBase 底层原理详解(深度好文,建议收藏)
HBase简介 HBase 是一个分布式的.面向列的开源数据库.建立在 HDFS 之上.Hbase的名字的来源是 Hadoop database,即 Hadoop 数据库.HBase 的计算和存储能力 ...
- 【转】Linux设备驱动之I/O端口与I/O内存
原文网址:http://www.cnblogs.com/geneil/archive/2011/12/08/2281367.html 一.统一编址与独立编址 该部分来自于:http://blog.ch ...
- DMA内存申请--dma_alloc_coherent 及 寄存器与内存【转】
转自:https://blog.csdn.net/ic_soc_arm_robin/article/details/8203933 在项目驱动过程中会经常用到dma传输数据,而dma需要的内存有自己的 ...
- I/O 端口和 I/O 内存
每个外设都是通过读写它的寄存器来控制. 大部分时间一个设备有几个寄存器, 并且在连 续地址存取它们, 或者在内存地址空间或者在 I/O 地址空间. 在硬件级别上, 内存区和 I/O 区域没有概念上的区 ...
- 我终于看懂了HBase,太不容易了...
前言 只有光头才能变强. 文本已收录至我的GitHub精选文章,欢迎Star:https://github.com/ZhongFuCheng3y/3y 在我还不了解分布式和大数据的时候已经听说过HBa ...
- CSAPP =2= 信息的表示和处理
思维导图 预计阅读时间:30min 阅读书籍 <深入理解计算机系统 第五版> 参考视频 [精校中英字幕]2015 CMU 15-213 CSAPP 深入理解计算机系统 课程视频 参考文章 ...
- 每个线程分配一个stack,每个进程分配一个heap;heap没有结构,因此寻址慢(转)
学习编程的时候,经常会看到stack这个词,它的中文名字叫做"栈". 理解这个概念,对于理解程序的运行至关重要.容易混淆的是,这个词其实有三种含义,适用于不同的场合,必须加以区分. ...
- Linux内核笔记--内存管理之用户态进程内存分配
内核版本:linux-2.6.11 Linux在加载一个可执行程序的时候做了种种复杂的工作,内存分配是其中非常重要的一环,作为一个linux程序员必然会想要知道这个过程到底是怎么样的,内核源码会告诉你 ...
随机推荐
- FastAdmin CMS 内容管理插件标签文档
FastAdmin CMS 内容管理插件标签文档 在CMS插件中的前端视图模板中有大量使用了自定义标签,我们在修改或制作模板的时候可以方便快捷的使用自定义标签来调用我们相关的数据. 标签库位于/add ...
- Java练习 SDUT-3328_JAVA判断合法标识符
JAVA判断合法标识符 Time Limit: 1000 ms Memory Limit: 65536 KiB Problem Description 输入若干行字符串,判断每行字符串是否可以作为JA ...
- Python 官方文档:入门教程
https://pythoncaff.com/docs/tutorial/3.7.0 官方入门教程,从这里开始你的 Python 之旅,将长久维护 基础信息 翻译说明 关于本教程 已完成 正文 1. ...
- Datanodes-心跳机制
- vscode golang vue配置
{ "files.autoSave": "off", "window.title": "${dirty}${activeEdito ...
- 洛谷 2152 [SDOI2009]SuperGCD
Description Sheng bill有着惊人的心算能力,甚至能用大脑计算出两个巨大的数的GCD(最大公约 数)!因此他经常和别人比赛计算GCD.有一天Sheng bill很嚣张地找到了你,并要 ...
- jq获取单选框、复选框、下拉菜单的值
1.<input type="radio" name="testradio" value="jquery获取radio的值" /> ...
- Android 动态设置控件获取焦点
之前写过一篇博客,简单的介绍了Android 隐藏EditText的焦点,之所以要隐藏EditText的焦点,是因为当应用在第一次进入某个Activity时,由于该页面中的EditText获取了焦点, ...
- 洛谷P1288 取数游戏II 题解 博弈论
题目链接:https://www.luogu.org/problem/P1288 首先,如果你的一边的边是 \(0\) ,那么你肯定走另一边. 那么你走另一边绝对不能让这条边有剩余,因为这条边有剩余的 ...
- Python--day68--Django ORM的字段参数、元信息
字段参数 null 用于表示某个字段可以为空. unique 如果设置为unique=True 则该字段在此表中必须是唯一的 . db_index 如果db_index=True 则代表着为此字段设置 ...