Python 基本数据类型(2)
知识内容:
一、python对象模型
1.python对象模型
对象是python语言中最基本的概念,在python中的所有的一切都可以称为对象。python中有许多内置对象供开发者使用,例如数字、字符串、列表、字典、集合等等,还有大量的内置函数(前面提到的print()和type())
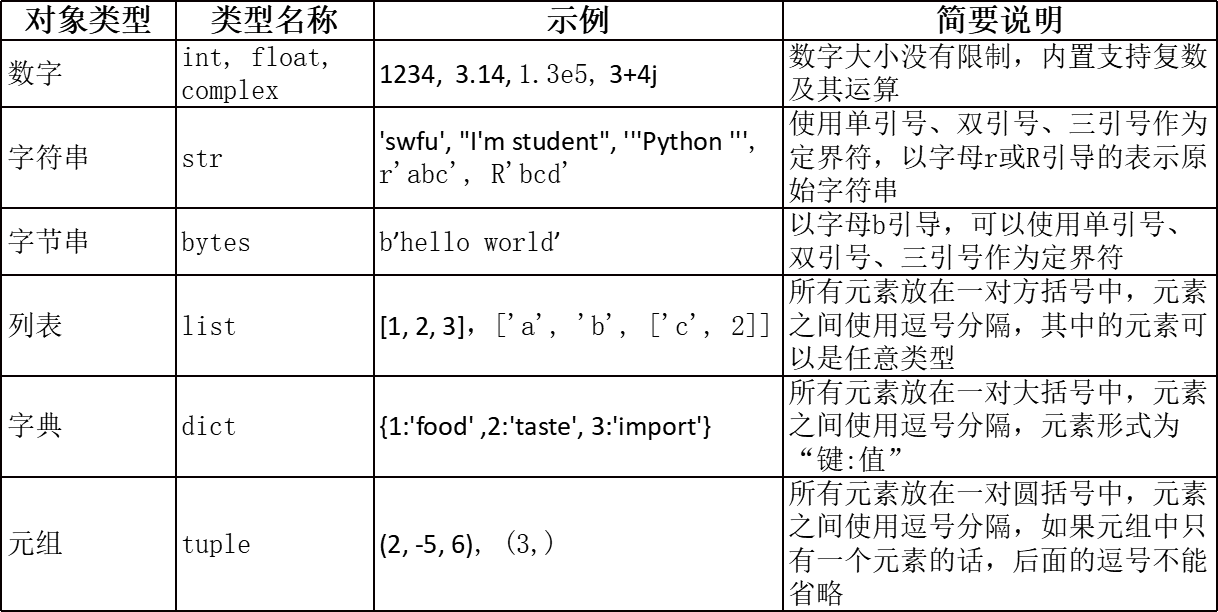
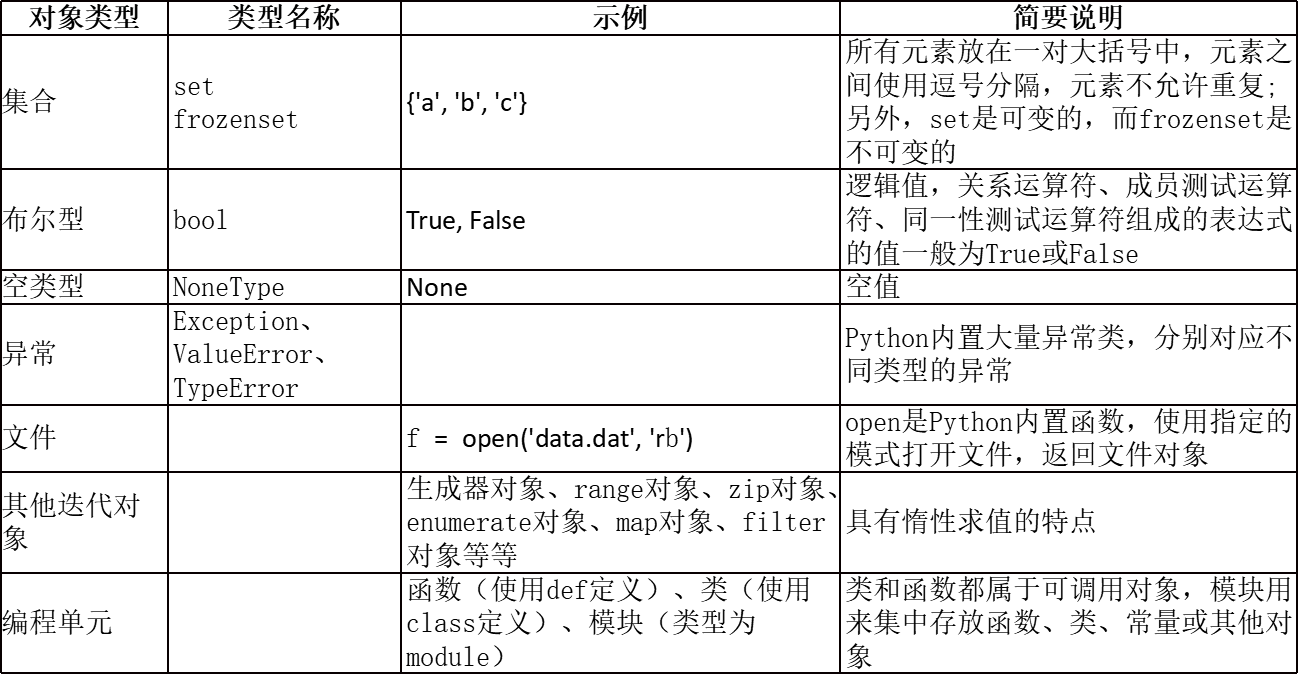
2.python内置对象
3.可变、不可变数据类型和hash
(1)可变数据类型和不可变数据类型
python中的数据类型可以分为可变数据类型和不可变数据类型
可变数据类型: 列表、字典、集合(set)
不可变数据类型: 数字、字符串、元组
从内存角度看列表和数字的变与不变:
>>> l = [1, 2, 3, 4]
>>> id(l)
84221264
>>> l[1] = 1.5
>>> id(l)
84221264
>>> l
[1, 1.5, 3, 4]
>>> print("列表是可变数据类型")
列表是可变数据类型
>>> a = 1
>>> id(a)
494523440
>>> a = 3
>>> a
3
>>> id(a)
494523472
>>> print("数字是不可变类型")
数字是不可变类型
列表中某项赋新值之后id值未变,在内存上还是原来的列表,所以说列表是可变类型,而数字赋新值后id发生了改变说明数字是不可变类型
字符串是不可变类型
>>> s = 'hello' >>> s[1] = 'a' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment >>> s = 'hello' >>> id(s) 58865760 >>> s += 'python' >>> s 'hellopython' >>> id(s) 58886128
字符串可以向列表一样使用索引操作,但是不能像修改列表一样来修改字符串的值,当我们对字符串进行拼接时,原理和整数一样,id值已经发生了改变,
相当于变成了另一个字符串,所以说字符串也是一个不可变类型
元组-不允许修改值,也是不可变类型
>>> t = (1, 2, 3, 4) >>> t[1] = 1.5 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment
(2)hash
hash的定义: Hash,一般翻译做“散列”,是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数
特征: hash值的计算过程是依据值的特征来计算,这就要求被hash的值必须固定,也就是说被hash的值必须是不可变的
注: 可变类型不可hash,不可变类型可hash
应用: 文件签名、MD5加密、密码验证
>>> hash("你猜我是谁")
1186796725
>>> hash("wyb")
1957863783
>>> hash((1,2,3))
-378539185
二、数字
1.数字属于不可变对象
修改整形变量值的时候并不是真的修改这个变量的值而是先把值存放到内存中,然后修改变量使其指向新的内存地址,浮点数、复数等数字类型以及其他类型的变量均具有同样的特点
示例:
x = 3 print(id(x)) x = 5 print(id(x)) # id(): 返回一个整数,代表变量在内存中的地址 # 以上两个id返回的值明显不一样,说明变量值的地址是不一样的
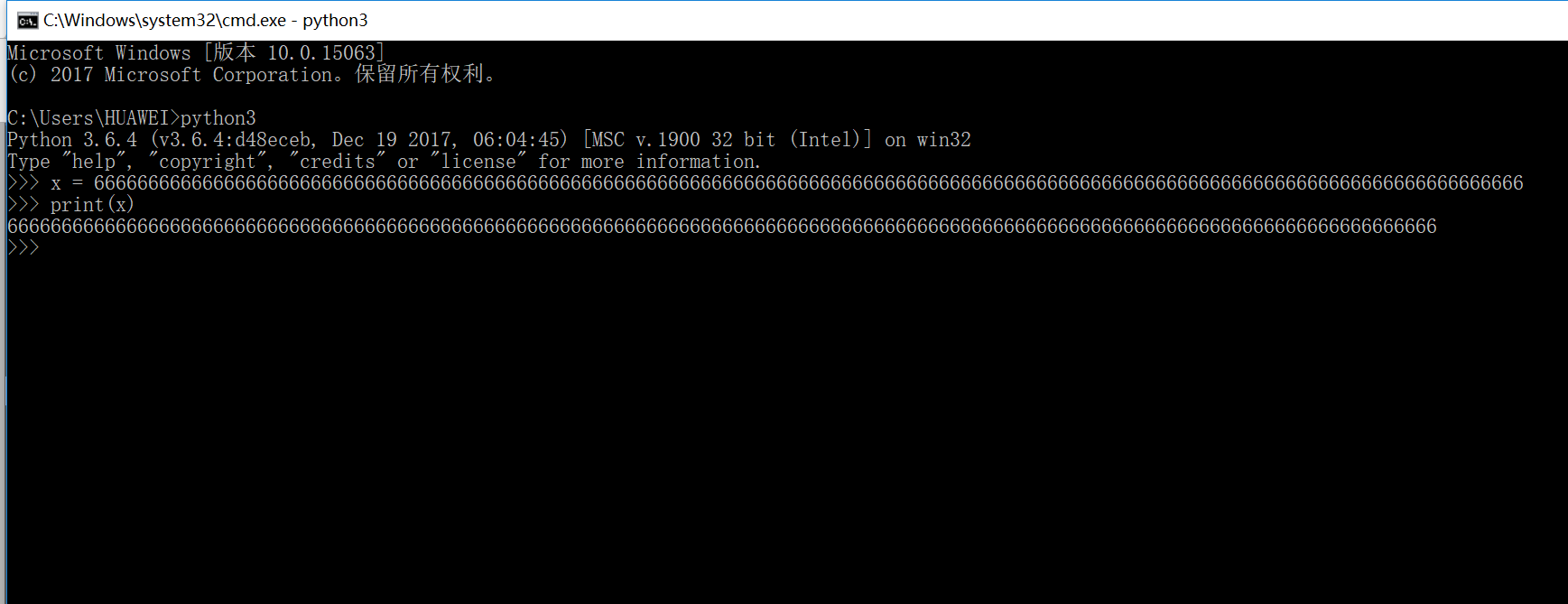
2.数字可以表示任意大的数值
在python中数字可以表示任意大的数值,在命令行中测试如下:
3.数字类型
(1)int(整数)
整数可以分为十进制数、十六进制数、八进制数、二进制数,十进制数就是普通的整数,十六进制数以0x或0X开头,八进制数以0o或0O开头,二进制数以0b或0B开头
注: 在python2中整数分为int和long两种,但是在python3中只有int一种
(2)float(浮点数)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型
注: 浮点数的取值范围和精度一般无限制,但是浮点数运算可能存在误差,也就是可能有不确定尾数
>>> 0.1+0.2 0.30000000000000004 >>> 0.1+0.2 == 0.3 False >>> round(0.1+0.2)==0.3 False >>> round(0.1+0.2, 1)==0.3 True 不确定尾数
不确定尾数
(3)complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数
示例:
x = 2 # 整数 print(type(x)) y = 3.6 # 浮点数 print(type(y)) c = 3 + 4j # 复数 print(type(c)) print(c.real) # 复数的实部 print(c.imag) # 复数的虚部 # 输出结果: # <class 'int'> # <class 'float'> # <class 'complex'> # 3.0 # 4.0
数字类型其他相关操作:
# 数据类型 - Numbers
# python3 支持int、float、bool、complex(复数)这些Numbers类型
# int类型:
a = 33333333333333333333333333333333333333333333333333
print(type(a))
# float类型:
a = 3.333333333333333333333333333333333333333333333333
print(type(a))
# bool类型: True\False
a = True
print(type(a))
# complex(复数)类型:
a = 87 + 3j
print(type(a))
# Numbers有关的操作符:
# 算术操作符: + - * / % ** // not > < == >= <=
# 比特操作符: ~ & | ^ >> <<
a = 2
b = 3
# 算术操作符: + - * / % ** // not > < == >= <=
print("a = 2")
print("b = 3")
print("a+b = ", a+b)
print("a-b = ", a-b)
print("a*b = ", a*b)
print("a/b = ", a/b) # 真正的除法
print("a%b = ", a % b) # 求余数
print("a**b = ", a**b) # 乘方
print("a//b = ", a//b) # 地板除法(去掉小数位)
print("not a = ", not a) # 取反
print("a==b = ", a == b) # 判等
print("a>b = ", a > b)
print("a<b = ", a < b)
print("a>=b = ", a >= b)
print("a<=b = ", a <= b)
# 比特操作符: ~ & | ^ >> <<
# ~: 按二进制取反;按照补码规则,结果数字为-(A+1)
# &: 并操作: 只有两个比特位都为1时结果中的对应比特位才设为1,否则设为0
# |: 或操作: 只要两个比特位有一个为1,结果中的对应比特位设为1,否则设为0
# ^: 异或操作:如果两个比特位相同则结果中的相应比特位设为0,否则设为1
# >>:按比特位右移
# <<:按比特位左移
# 并 - 或 - 异或的比特位操作如下所示:
# A B &(并) |(或) ^(异或)
# 0 0 0 0 0
# 0 1 0 1 1
# 1 0 0 1 1
# 1 1 1 1 0
a = ~30 # 按二进制取反,结果为-31
b = 3 & 3 # 二进制并操作,结果为3
c = 3 & 1 # 二进制并操作,结果为1
d = 3 ^ 1 # 二进制异或操作,结果为2
e = 3 << 1 # 二进制按比特位左移操作,结果为6
print(a)
print(b)
print(c)
print(d)
print(e)
# 和Numbers类型有关的的内置函数:
# (1)通用函数:
# str(A) --> 将参数转换成可显示的字符串
# type(A) --> 返回参数的类型对象
# bool(A) --> 将参数转换成bool类型
# int(A) --> 将参数转换成int类型
# float(A) --> 将参数转换成float类型
# complex(A)--> 将参数转换成complex类型
# (2)数值类型特定函数:
# abs(A) --> 取绝对值
# divmod(A,B)-->除模操作: 生成一个元祖,形式为(A/B,A%B)
# pow(A,B) --> 幂操作符: 结果为"A的B次方"
# round(A) --> 返回参数的四舍五入结果
# hex(A) --> 将A转换成用十六进制表示的字符串
# oct(A) --> 将A转换成用八进制表示的字符串
# chr(A) --> 将A转换成ASCII字符,要求0<=A<=255
# ord(A) --> chr(A)的反函数
4.bool(布尔型)
bool型在python中有两个值: True(真)和False(假),两者值分别为1和0,主要用来做逻辑判断
>>> a = 3 >>> b = 5 >>> a > b # 不成立就是False,即假 False >>> a < b # 成立就是True,即真 True
三、字符串
1.字符串的表示
(1)用单引号、双引号或三引号括起来的符号系列称为字符串, 并且单引号、双引号、三单引号、三双引号可以互相嵌套,用来表示复杂字符串
"wyb", 'Hello, World', "python", '''Tom said, "Let's go"'''都是字符串
(2)空串表示为'', ""
# 下面是空串: msg = '' name = ""
(3)三引号表示的字符串可以换行,支持排版较为复杂的字符串;三引号还可以在程序中表示较长的注释
msg = ''' 我是谁 我在哪 我在干什么 ''' print(msg) # 字符串换行
''' 三引号中可以写多行注释 这里可以写多行注释 '''
(4)不加引号的字符串会被系统认为是变量
>>> name = jack Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'jack' is not defined >>> jack = "wyb" >>> name = jack >>> name 'wyb'
2.字符串的常用操作
(1)字符串拼接:
+: 直接将两个字符串相加 *: 字符串复制多次
join(seq) 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串
>>> name = "wyb" >>> age = "21" >>> name + age 'wyb21' >>> name*3 'wybwybwyb'
>>>''.join("python")
'python'
>>>'123'.join("python")
'p123y123t123h123o123n'
注: 字符串只能与字符串进行拼接,不能与其他数据类型一起拼接!
>>> name = "wyb" >>> age = 21 >>> name + age Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: must be str, not int
(2)大小写:
capitalize() 将字符串的第一个字符转换为大写
swapcase() 将字符串中大写转换为小写,小写转换成大写
upper() 转换字符串中所有小写字母为大写
lower() 转换字符串中所有大写字符为小写
title() 返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写
>>> s = "python web framework" >>> s.capitalize() 'Python web framework' >>> s 'python web framework' >>> s.upper() 'PYTHON WEB FRAMEWORK' >>> s.lower() 'python web framework' >>> s.title() 'Python Web Framework' >>> s = "ABCDefg" >>> s.swapcase() 'abcdEFG'
(3)字符串填充:
center(width, fillchar) 返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格
ljust(width[, fillchar]) 返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。
rjust(width,[, fillchar]) 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串
zfill (width) 返回长度为 width 的字符串,原字符串右对齐,前面填充0
>>> s = "python" >>> s.center(20, '*') '*******python*******' >>> s.ljust(10, '*') 'python****' >>> s.rjust(10, '*') '****python' >>> s.zfill(10) '0000python'
(4)数值计算:
len(string) 返回字符串长度
count(str, beg= 0,end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数,str可以是一个字符也可以是多个字符
>>> s = "python"
>>> len(s)
6
>>> s = "111222abcdefga"
>>> s.count(1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: must be str, not int
>>> s.count(')
3
>>> s.count(')
0
>>> s.count(')
1
>>> s.count('a')
2
(5)查找:
find(str, beg=0 end=len(string)) 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1
rfind(str, beg=0,end=len(string)) 类似于 find()函数,不过是从右边开始查找
index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在字符串中会报一个异常 rindex( str, beg=0, end=len(string)) 类似于 index(),不过是从右边开始
max(str) 返回字符串 str 中最大的字母 min(str)返回字符串 str 中最小的字母
>>> s = "this is a string"
>>> s.find('str')
10
>>> s.rfind('str')
10
>>> s.index('str')
10
>>> s.rindex('str')
10
# 查找的子串不在字符串中:
>>> s.find('adsfasd')
-1
>>> s.index('adsfasd')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
>>> max("python")
'y'
>>> min("python")
'h'
(6)判断字符串:
isalnum() 如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False
isalpha() 如果字符串至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False
isdigit() 如果字符串只包含数字则返回 True 否则返回 False..
islower() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False
isnumeric() 如果字符串中只包含数字字符,则返回 True,否则返回 False
isspace() 如果字符串中只包含空白,则返回 True,否则返回 False.
istitle() 如果字符串是标题化的(见 title())则返回 True,否则返回 False
isupper() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False
isdecimal() 检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。
startswith(str, beg=0,end=len(string)) 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查
endswith(suffix, beg=0, end=len(string)) 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False
(7)映射:
maketrans() 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。
translate(table, deletechars="") 根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中、
>>>table = ''.maketrans("abcdef123", "uvwxyz@#$")
>>>s = "python is a good programming language"
>>>s.translate(table)
'python is u goox progrumming lunguugy'
(8)替换:
replace(old, new [, max]) 把字符串中的 old替换成 new,如果 max 指定,则替换不超过 max 次
>>> s = "python is a good language"
>>> s.replace(')
'python is 666 good l666ngu666ge'
>>> s
'python is a good language'
>>> s.replace(', 1)
'python is 666 good language'
>>> s
'python is a good language'
(9)字符串分割:
split(str="", num=string.count(str)) 以str分割字符串最多分割num个,num默认为str在字符串中的个数,返回一个列表
rsplit(str="", num=strring.count(str)) 也是以str分割字符串最多分割num个,num默认为str在字符串中的个数,返回一个列表,不过rsplit()是从右边开始分割
splitlines([keepends]) 按照行('\r', '\r\n', '\n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
partition() 和rpartition()都接收一个分割字符串作为参数,将目标字符串分割为两个部分,返回一个三元元组(head,sep,tail),包含分割符,partition()从左边开始分割,rpartition()从右边开始分割
>>> s = "adgsdfadgsdakhjidadfd"
>>> s.split('a')
['', 'dgsdf', 'dgsd', 'khjid', 'dfd']
>>> s.rsplit('a')
['', 'dgsdf', 'dgsd', 'khjid', 'dfd']
>>> s.split('a', 1)
['', 'dgsdfadgsdakhjidadfd']
>>> s.rsplit('a', 1)
['adgsdfadgsdakhjid', 'dfd']
>>> s.partition('a')
('', 'a', 'dgsdfadgsdakhjidadfd')
>>> s.rpartition('a')
('adgsdfadgsdakhjid', 'a', 'dfd')
(11)去掉开头或结尾字符:
strip([chars]) 在字符串上执行 lstrip()和 rstrip() lstrip() 截掉字符串左边的空格或指定字符。 rstrip() 删除字符串字符串末尾的空格
>>> s = " python " >>> s.strip() 'python' >>> s ' python ' >>> s.lstrip() 'python ' >>> s.rstrip() ' python'
(12)字符串转换
eval(): 将任意字符串转换成python表达式并求值
>>> eval("3+5")
8
>>> eval("3**2")
9
>>> eval("9")
9
3.字符串的格式化
字符串格式化是指按规定的规则连接、替换字符串并返回新的符合要求的字符串,字符串格式化有以下两种方法:
(1)使用%进行格式化
语法格式:
"%[-][+][0][m][.n]格式字符" %x # []中的为可选
解释:
第一个%: 格式标志,表示格式开始
-: 指定左对齐输出
+: 对正数加正号
0: 指定空位填0
m: 指定最小宽度
n: 指定精度
python中的格式字符:
%c 格式化字符及其ASCII码 %s 格式化字符串 %d 格式化整数 %u 格式化无符号整型 %o 格式化无符号八进制数 %x 格式化无符号十六进制数 %X 格式化无符号十六进制数(大写) %f 格式化浮点数字,可指定小数点后的精度 %e 用科学计数法格式化浮点数 %E 作用同%e,用科学计数法格式化浮点数 %g %f和%e的简写 %G %f 和 %E 的简写 %p 用十六进制数格式化变量的地址
格式化输出:
name = input("name: ")
age = int(input("age: "))
job = input("job: ")
hometown = input("hometown: ")
infos = """
----------- info of %s ----------
Name: %s
Age: %d
Job: %s
Hometown: %s
---------- end ------------------
""" % (name, name, age, job, hometown)
print(infos)
(2)使用字符串的format方法进行格式化
更推荐使用formath方法,该方法不仅灵活,不仅可以使用位置进行格式化,还支持使用与位置无关的参数名字来进行格式化。并且支持序列解包格式化字符串,为程序员提供了极大的方便
用法: <模板字符串>.format(<逗号分割的参数>)
format 函数可以接受不限个参数,位置可以不按顺序,实例:
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world'
>>> "{0} {1}".format("hello", "world") # 设置指定位置
'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'
format函数也可以进行数字的格式化,实例:
>>> print("{:.2f}".format(3.1415926))
3.14
模板字符串中的格式控制:



示例:
# (1)使用%的字符串格式化:
# format_string % string_to_convert
# format_string % (string_to_convert1,string_to_convert2,、、、)
# format_string为格式标记字符串,期中包括固定的内容和待替换的内容,
# 待替换的内容用格式化符号标明;
# string_to_convert为要格式化的字符串,如果是两个以上,则需要用小括号括起来
print("my name is %s and my age is %d" % ("wyb", 21))
# 将charA的内容以字符形式替换在要显示的字符串中
print("ASCII码65代表: %c" % charA)
# 将charB的内容以数字形式替换在要显示的字符串中
print("ASCII码%d代表: B" % charB)
# (2)format函数字符串格式化:
print("format函数字符串{}很好用".format('格式化'))
print("format{} + {} + {}".format(1, 2, 3))
字符串格式化的两种方法
字符串格式化的两种方法
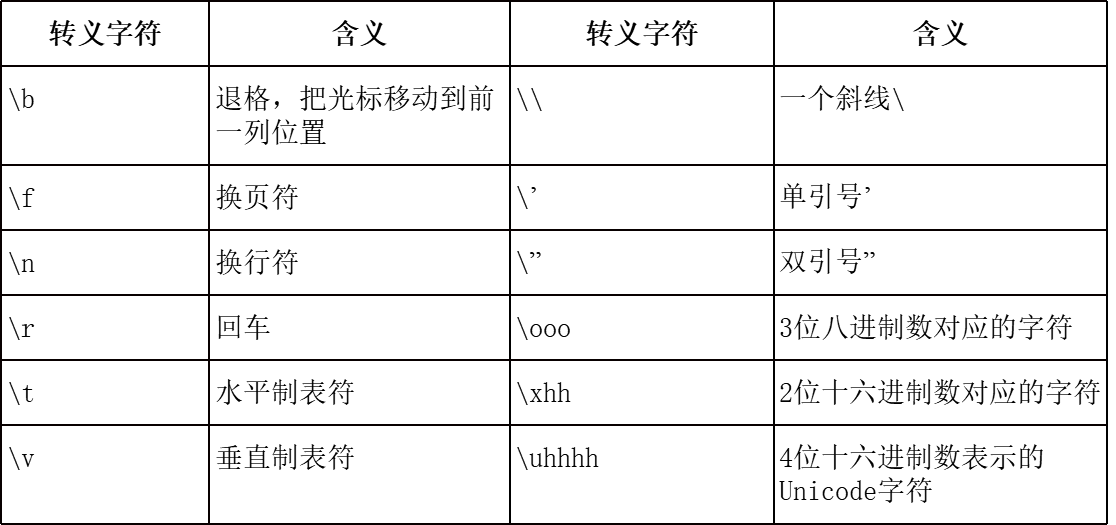
4.关于转义字符
(1)python支持的常用转义字符:
(2)需要特别注意:
在字符串界定符(也就是引号)前加上r或R表示原始字符串,其中的特殊字符不进行转义,但是字符串的最后一个字符不能是'\'符号。原始字符串主要用于正则表达式中,也可以用来简化文件路径或者url的输入
示例:
# __author__ = "wyb" # date: 2018/3/7 path = 'C:\Windows\notepad.exe' print(path) # 字符\n被转义为换行符 path = r'C:\Windows\notepad.exe' # 原始字符串,任何字符都不转义 print(path) # 输出结果: # C:\Windows # otepad.exe # C:\Windows\notepad.exe
四、列表与元组
1.列表的创建
(1)直接创建列表:
>>> L1 = [] # 创建空列表 >>> L2 = [1, 2, 3] # 创建一个普通列表 >>> L3 = [4, ["python", 'c']] # 列表的嵌套定义 >>> >>> L4 = list() # 通过list()创建列表 >>> print(L1) [] >>> print(L2) [1, 2, 3] >>> print(L3) [4, ['python', 'c']] >>> print(L4) []
(2)使用list()将元组、range对象、字符串或其他类型的可迭代对象的数据转换成列表
# 使用list()创建列表:
a_list = list((3, 5, 6, 7, 9))
print(a_list)
b_list = list(range(10))
print(b_list)
c_list = list('python')
print(c_list)
# 输出结果:
# [3, 5, 6, 7, 9]
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# ['p', 'y', 't', 'h', 'o', 'n']
注: 关于range函数 原型: range([start, ]stop[, step])
第一个参数start表示起始,没有设置时默认表示从0开始(即从第一个开始), 第二个参数表示终止(结果中不含这个值),第三个参数表示步长(默认为1) , 该函数在python3中
返回一个range可迭代对象,而在python2中是返回一个包含若干整数的列表。
2.列表的基本操作
(1)查询(索引)
# 列表索引 name_list = ['wyb', 'zl', 'k'] print(name_list[0]) # 列表索引从0开始 print(name_list[1]) print(name_list[-2]) # 列表索引可以为负数表示从最后一个开始的倒数第几个 # 输出结果: # wyb # zl # zl
(2)追加: append() insert() extend()
# 列表追加: append() insert() extend()
name_list = ['wyb', 'zl', 'k']
name_list.append('add') # 将数据直接添加到最后
print(name_list)
name_list.insert(0, 'first') # 将数据添加到指定位置
print(name_list)
# 输出结果:
# ['wyb', 'zl', 'k', 'add']
# ['first', 'wyb', 'zl', 'k', 'add']
# append()与extend()的区别:
# list.append(object) 向列表中添加一个对象object
# list.extend(sequence) 把一个序列seq的内容一个个地添加到列表中
list_first = ['s', 'k', 'z']
list_last = [1, 3, 9]
list_first.append(list_last)
print(list_first)
list_a = ['sdf', 'sd', 'fff']
list_b = [']
list_a.extend(list_b)
print(list_a)
# 输出结果:
# ['s', 'k', 'z', [1, 3, 9]]
# ['sdf', 'sd', 'fff', '123', '666', '333']
(3)删除: remove() pop() del()
# 列表删除: remove() pop() del() a = ['a', 'b', 'c', 'd'] a.remove(a[0]) print(a) b = a.pop(1) print(a) del a[0] print(a) del a # print(a) # 删除a后这条语句将会报错 # 输出结果: # ['b', 'c', 'd'] # ['b', 'd'] # ['d']
(4)修改
# 列表修改 list_one = [1, 2, 3] list_one[0] = 'wyb' # 修改第一个元素 list_one[-1] = 'zl' # 修改最后一个元素 print(list_one) # 输出结果: # ['wyb', 2, 'zl']
(5)长度: len()
# 列表长度: len() name_list = ['wyb', 'zl', 'k'] print(len(name_list)) # 输出结果: 3
(6)循环
# 列表的多重循环
names = ['wyb', 'woz', 'jay']
ages = [20, 21, 30]
for name, age in zip(names, ages):
print(name, age)
# 输出结果:
# wyb 20
# woz 21
# jay 30
(7)拷贝: copy() 列表深浅拷贝
# 列表拷贝 name_list = ['wyb', 'tim', 'tom', 'alex'] name_copy = name_list.copy() print(name_copy) # 输出结果: ['wyb', 'tim', 'tom', 'alex']
(8)统计: count()
# 列表统计
name_list = ['wyb', 'tim', 'tom', 'alex', 'tim']
print(name_list.count('tim'))
# 输出结果: 2
(9)排序及翻转: sort() reverse()
# 列表排序及翻转 x = [4, 6, 2, 1, 7, 9] x.sort(reverse=True) print(x) a = ['wyb', 'jx', 'tm', 'tom', 'x', 'k'] a.reverse() print(a) a = ['wyb', 'jx', 'tm', 'tom', 'x', 'k'] a.sort() print(a) # 输出结果: # [9, 7, 6, 4, 2, 1] # ['k', 'x', 'tom', 'tm', 'jx', 'wyb'] # ['jx', 'k', 'tm', 'tom', 'wyb', 'x']
(10)获取下标: index()
# 获取下标
name_list = ['wyb', 'tim', 'tom', 'alex', 'tim']
print(name_list.index('wyb'))
print(name_list.index('tom'))
print(name_list.index('tim'))
# 输出结果:
#
#
#
(11)切片:

3.元组
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表
元组创建:
(1)直接创建元组:
name_tuple = ('wyb', 'xyz', 'k') 注: 如果要创建一个只包含一个元素的元组,需在这个元素后加上逗号","
(2)使用tuple()将其他类型转换成元组
char_tuple = tuple("abcdefg")
name_tuple = tuple(['wyb', 'xyz', 'k'])
元组的方法:
count() , index()
# __author__ = "wyb" # date: 2018/3/10 # 在python语言中tuple的元素在初始化后不能修改 # 开发时的常量一般可以存储在tuple中 t1 = (1, 2, "python", 8.88) # 元组切片: print(t1[1:]) print(t1[0:5]) # 不能修改元组内容但是可以对元组变量重新赋值 t2 = (3, 'you and me') t1 = t1 + t2 print(t1) # 元组里的数据不能被修改,所以又被叫做只读列表 tup = (1,) # 一个元素,需要在元素后面添加逗号 tuple1 = (1, 2, 3) # 三个元素 tuple2 = () # 空元组 print(tuple1[1:3]) # 元组切片 print(tuple1.count(1)) # 元组的count()方法 print(tuple1.index(3)) # 元组的index()方法
注:
(1)对于元组而言只能使用del命令删除整个元组对象,而不能单独删除元组中的部分元素,因为元组属于不可变序列
(2)虽然元组属于不可变序列,但是如果元组中的元素值为可变序列,则情况就发生了一点了改变,如下:
>>> x = ([0, 1], 3)
>>> x
([0, 1], 3)
>>> x[0][0] = 666
>>> x
([666, 1], 3)
>>> x[0].append(')
>>> x
([666, 1, '], 3)
4.元组与列表的区别
(1)可变与不可变
列表是可变序列,可以对某个元素进行赋值修改,也可以随意地添加删除元素,而元组是不可变序列,不能对某个元素进行赋值修改,更不能随意地添加删除元素
(2)访问处理速度
元组地访问处理速度比列表更快,如果需要定义一系列常量,只是对它们进行遍历或其他类似用途,而不需要对其元素进行任何修改,那么一般建议使用元组
五、字典与集合
1.字典的定义
字典一种key - value 的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容
示例:
info = {
'stu01': "ming",
'stu02': "wyb",
'stu03': "tom",
}
2.字典的特性
字典是无序可变的序列
字典中每个元素包括两部分: 键(key)和值(value)
key必须可hash也就是必须为不可变的数据类型(数字、字符串),并且必须是唯一的
可存放任意多个值、可修改、可以不唯一
无序
3.字典相关操作
(1)增加及修改
info = {
'stu01': "ming",
'stu02': "wyb",
'stu03': "tom",
}
# 字典增加
info['stu_add'] = "add_student"
print(info)
# 字典修改
info['stu_add'] = "修改"
print(info)
# 输出结果:
# {'stu01': 'ming', 'stu02': 'wyb', 'stu03': 'tom', 'stu_add': 'add_student'}
# {'stu01': 'ming', 'stu02': 'wyb', 'stu03': 'tom', 'stu_add': '修改'}
(2)删除
# 字典删除
info = {
'stu01': "ming",
'stu02': "wyb",
'stu03': "tom",
}
info.pop('stu03')
print(info)
del info['stu01']
print(info)
# 输出结果:
# {'stu01': 'ming', 'stu02': 'wyb'}
# {'stu02': 'wyb'}
(3)查找
# 字典查找
info = {
'stu01': "ming",
'stu02': "wyb",
'stu03': "tom",
}
result = info.get('stu01')
print(result)
result = info.get('not') # 即使key不存在也不会报错而是输出None
print(result)
result = info['stu01'] # 查找不存在的key就会报错
print(result)
# 结果:
# ming
# None
# ming
(4)多级字典嵌套及操作
av_catalog = {
"欧美":{
"www.youporn.com": ["很多免费的,世界最大的","质量一般"],
"www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"],
"letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"],
"x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"]
},
"日韩":{
"tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"]
},
"大陆":{
":["全部免费,真好,好人一生平安","服务器在国外,慢"]
}
}
av_catalog["][1] += ",可以用爬虫爬下来"
"])
#ouput
['全部免费,真好,好人一生平安', '服务器在国外,慢,可以用爬虫爬下来']
(5)循环
#方法1
for key in info:
print(key,info[key])
#方法2
for k,v in info.items(): #会先把dict转成list,数据里大时莫用
print(k,v)
(6)其他:
dict(): 用于创建字典 具体使用: 点这里
update(): 将另一个字典里的键值对一次性全部添加到当前字典对象中
clear(): 一次性删除字典中所有元素
popitem(): 删除并返回字典中的一个元素
keys(): 返回字典中的所有键
values(): 返回字典中的所有值
setdefault(): 设置字典中的值
items(): 以列表返回可遍历的(键, 值) 元组数组
d1 = dict(name="woz", age=20, work="student")
d2 = {1: 'python', 2: 'java', 3: 'ruby'}
d1.update(d2)
print(d1)
print(d1.popitem())
print(d1.popitem())
print(d1.popitem())
print(d1.keys())
print(d1.values())
print(d1.items())
d1.setdefault("coding", "utf-8")
print(d1)
4.集合
(1)集合的定义与分类
集合: 相互之间无序的一组对象集合,分为普通集合(通过set定义)和不可变集合(通过frozenset定义)
普通集合在初始化后支持并集补集交集,不可变集合初始化后就不能改变
# 普通集合
s = {'wyb', 'zzz', 'xyz'}
print(s)
print(type(s))
# 不可变集合
k = frozenset({'asf', 'sdf', 'df'})
print(k)
print(type(k))
(2)集合特性
- 确定性: 元素必须可hash,必须为不可变元素
- 互异性(去重)
- 无序性: 元素没有先后之分,{1,2,3}和{3,2,1}算做同一个集合
(3)集合的作用
去重,把一个列表变成一个集合便会自动去重(集合中的元素是无序的,不可以有重复的对象,所以可以通过集合把重复的数据去除)
关系测试,测试两组数据之间的交集、差集、并集等关系
# 集合: 集合中的元素是无序的,不可以有重复的对象,所以可以通过集合把重复的数据去除 s = ['] res = set(s) print(res)
集合去重
# 集合的关系运算
s1 = {'iphone', 'hw', 'honor', 'x'}
s2 = {'vivo', 'jli', 'old_phone', 'x', 'hw'}
# 集合的交
print(s1.intersection(s2))
print(s1 & s2)
# 集合的并
print(s1.union(s2))
print(s1 | s2)
# 集合的差 -> 只在s1不在s2
print(s1.difference(s2))
print(s1 - s2)
# 集合的对称差集 -> 只在s1或只在s2
print(s1.symmetric_difference(s2))
print(s1 ^ s2)
# 集合的包含关系
print(s1.isdisjoint(s2)) # 判断两个集合是否相交
print(s1.issuperset(s2)) # 判断集合是不是包含其他集合,等同于a>=b
print(s1.issubset(s2)) # 判断集合是不是被其他集合包含,等同于a<=b
集合的关系运算
集合的关系运算
(4)集合的常用操作
单个元素的增加: add()
对序列的增加: update()
删除: discard() remove() pop() clear()
# 集合的操作符:
# in, not in, ==, != , <, <=, >, >=, &, |, -, ^, |=, &=, -=, ^=
# in: 判断包含关系
# not in: 判断不包含关系
# ==: 判断等于
# !=: 判断不等于
# <: 判断绝对子集关系
# <=:判断非绝对子集关系
# >:判断绝对超集关系
# >=:判断非绝对超集关系
# -:差运算
# 集合的操作符的示例:
mylist = [4, 6, -1, 'English', 0, 'python']
s1 = set(mylist)
s2 = frozenset([6, 'English', 9])
print(6 in s1) # 判断包含关系
print(s1 >= s2) # 判断子集关系
print(s1 - s2) # 差运算
print(s1 & s2) # 交运算
print(s2)
# 普通集合(set类型)的内置函数:
# add(): 增加新元素
# update(seq): 用序列更新集合,序列的每个元素都被添加到集合中
# remove(element): 删除元素
# 集合(set类型)的内置函数的示例:
mylist = [4, 6, -1.1, 'English', 0, 'python']
sample1 = set(mylist)
sample1.add('China')
print(sample1)
sample1.update('France')
print(sample1)
sample1.remove(-1.1)
print(sample1)
集合的操作符及常用操作
集合的操作符及常用操作
补充内容:
1. 切片
切片是Python序列的重要操作之一,适用于列表、元组、字符串、range对象
语法: start:stop:step 第一个数字表示切片开始位置(默认为0),第二个参数表示切片停止位置(默认为列表长度且不包括),第三个数字表示切片的步长,当步长省略时可以顺便省略最后一个冒号与使用下标访问列表元素的方法不同,切片操作不会因为下标越界而抛出异常,而是简单地在列表尾部截断或返回一个空列表,代码具有更强的健壮性
以列表为示例:
>>> list = [3, 4, 5, 6, 7, 8, 9, 10, 11, 12] >>> list[::] # 从头到尾全部输出 [3, 4, 5, 6, 7, 8, 9, 10, 11, 12] >>> list[::-1] # 从尾到头全部输出 [12, 11, 10, 9, 8, 7, 6, 5, 4, 3] >>> list[::2] # 从头到尾每隔2个就输出 [3, 5, 7, 9, 11] >>> list[1::2] # 从第二个元素开始一直到结尾每隔2个就输出 [4, 6, 8, 10, 12] >>> list[3::] # 从第四个到结尾全部输出 [6, 7, 8, 9, 10, 11, 12] >>> list[3:6] # 从第四个到第六个全部输出 [6, 7, 8] >>> list[3:6:1] # 从第四个到第六个全部输出 [6, 7, 8] >>> list[0:100:1] # 从头到尾全部输出 [3, 4, 5, 6, 7, 8, 9, 10, 11, 12] >>> list[100:] # 下标越界返回空列表 []
2.用于序列操作的常用内置函数
(1)len(): 返回列表、元组、字典、集合、字符串、range对象等各种可迭代对象的元素个数
(2)max(), min(): 返回列表、元组、字符串、集合、range对象、字典等的最大或最小元素,要求所有元素之间可以进行大小比较,另外对字典进行操作时默认是对字典的键进行计算,要对字典值进行计算,则需要使用字典对象的values()方法明确说明
(3)sum(): 对数值型列表、数值型元组、集合、range对象、字典等进行计算求和
# __author__ = "wyb" # date: 2018/3/12 s = [1, 2, 3, 6, 9, 8] print(len(s)) # s中元素的个数 print(max(s)) # s中元素的最大值 print(min(s)) # s中元素的最小值 print(sum(s)) # s中元素的和 print(sum(s)/len(s)) # s的平均值
(4)zip(列表1, 列表2, 、、、): 将多个列表或元组对应位置的元素组合为元组,并返回包含这些元组的列表(python2)或zip对象(python3)
>>> a = [1, 2, 3] >>> b = [4, 5, 6] >>> c = [7, 8, 9] >>> d = zip(a, b, c) >>> d <zip object at 0x04BA7940> >>> list(d) [(1, 4, 7), (2, 5, 8), (3, 6, 9)]
(5)enumerate(列表): 枚举列表、元组、字符串、字典或其他可迭代对象的元素,返回枚举对象,枚举对象中每个元素是包含下标和元素值的元组
>>> for index, value in enumerate("python"):
... print(index, value)
...
0 p
1 y
2 t
3 h
4 o
5 n
>>> for i, v in enumerate({1:"d", 2:"s", 3:"k"}):
... print(i, v)
...
0 1
1 2
2 3
>>> for i, v in enumerate({1:"d", 2:"s", 3:"k"}.values()):
... print(i, v)
...
0 d
1 s
2 k
(6)sorted(): 对列表、元组、字典进行排序,并借助其key参数来实现更复杂的排序
内置函数sorted()返回新的列表、元组或字典,不对原来的列表、元组或字典做任何修改
sorted()原型:
sorted(iterable, key=None, reverse=False)
sorted函数排序默认升序, 可以设置key值来解决一些特殊的需求,reverse=False表示升序排列,reverse=True表示降序排列
3.列表推导式
列表推导式使用非常简洁的方式来快速生成满足特定需求的列表,代码具有非常强的可读性,例如:
a = [x*x for x in range(10)]
上面的代码等价于:
a = []
for x in range(10):
a.append(x*x)
列表推导式:
# __author__ = "wyb" # date: 2018/3/12 # # 以下3段代码等价: # f = [' banana ', ' loganberry ', ' passion fruit '] # a = [w.strip() for w in f] # print(a) # # f = [' banana ', ' loganberry ', ' passion fruit '] # for i, v in enumerate(f): # f[i] = v.strip() # print(a) # # f = [' banana ', ' loganberry ', ' passion fruit '] # f = list(map(str.strip, f)) # print(a)
4.序列解包
在实际开发中,序列解包是非常重要和常用的一个语法,可以使用非常简洁的形式完成复杂的功能,大幅度提高了代码的可读性,并且减少了程序员的代码输入量。
例如可以使用序列解包功能对多个变量同时赋值:
>>> x,y,z = 1,2,3 >>> print(x,y,z) 3 1 2 3
列表与字典的序列解包:
>>> a = [1, 2, 3]
>>> b, c, d = a
>>> print(b, c, d)
1 2 3
>>> s = {1:'a', 2:'b', 3:'c'}
>>> b, c, d = s # 对键进行操作
>>> print(b, c, d)
1 2 3
>>> b, c, d = s.values() # 对值进行操作
>>> print(b, c, d)
a b c
>>> b, c, d = s.items() # 对键和值操作
>>> print(b, c, d)
(1, 'a') (2, 'b') (3, 'c')
使用序列解包可以同时遍历多个序列:
>>> keys = [1, 2, 3, 4] >>> values = ['a', 'b', 'c', 'd'] >>> for k, v in zip(keys, values): ... print(k, v) ... 1 a 2 b 3 c 4 d
参考资料:http://www.cnblogs.com/wyb666/p/8515686.html
Python 基本数据类型(2)的更多相关文章
- python 基本数据类型分析
在python中,一切都是对象!对象由类创建而来,对象所拥有的功能都来自于类.在本节中,我们了解一下python基本数据类型对象具有哪些功能,我们平常是怎么使用的. 对于python,一切事物都是对象 ...
- python常用数据类型内置方法介绍
熟练掌握python常用数据类型内置方法是每个初学者必须具备的内功. 下面介绍了python常用的集中数据类型及其方法,点开源代码,其中对主要方法都进行了中文注释. 一.整型 a = 100 a.xx ...
- 闲聊之Python的数据类型 - 零基础入门学习Python005
闲聊之Python的数据类型 让编程改变世界 Change the world by program Python的数据类型 闲聊之Python的数据类型所谓闲聊,goosip,就是屁大点事可以咱聊上 ...
- python自学笔记(二)python基本数据类型之字符串处理
一.数据类型的组成分3部分:身份.类型.值 身份:id方法来看它的唯一标识符,内存地址靠这个查看 类型:type方法查看 值:数据项 二.常用基本数据类型 int 整型 boolean 布尔型 str ...
- Python入门-数据类型
一.变量 1)变量定义 name = 100(name是变量名 = 号是赋值号100是变量的值) 2)变量赋值 直接赋值 a=1 链式赋值 a=b=c=1 序列解包赋值 a,b,c = 1,2,3 ...
- Python基础:八、python基本数据类型
一.什么是数据类型? 我们人类可以很容易的分清数字与字符的区别,但是计算机并不能,计算机虽然很强大,但从某种角度上来看又很傻,除非你明确告诉它,"1"是数字,"壹&quo ...
- python之数据类型详解
python之数据类型详解 二.列表list (可以存储多个值)(列表内数字不需要加引号) sort s1=[','!'] # s1.sort() # print(s1) -->['!', ' ...
- Python特色数据类型(列表)(上)
Python从零开始系列连载(9)——Python特色数据类型(列表)(上) 原创 2017-10-07 王大伟 Python爱好者社区 列表 列表,可以是这样的: 分享了一波我的网易云音乐列表 今天 ...
- 【Python】-NO.97.Note.2.Python -【Python 基本数据类型】
1.0.0 Summary Tittle:[Python]-NO.97.Note.2.Python -[Python 基本数据类型] Style:Python Series:Python Since: ...
- python基本数据类型之集合
python基本数据类型之集合 集合是一种容器,用来存放不同元素. 集合有3大特点: 集合的元素必须是不可变类型(字符串.数字.元组): 集合中的元素不能重复: 集合是无序的. 在集合中直接存入lis ...
随机推荐
- CentOS系统下docker的安装与卸载
Docker简介 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化.容器是完全使用沙箱机制, ...
- 在eclipse中编辑linux上的项目
以前在linux的上接口自动化项目都是使用notepad++或SVN下载到本地后再上传来完成功做,但在调试时非常麻烦. 查看了下在eclipse中有一个非常好用的插件Remote Systems,可以 ...
- ThinkPHP widge使用示例
1.widge一般用于公用模块的设计与使用,以便加强软件模块的复用性与重用性 一般使用include方法设计公共模块,比如<include file="home:header" ...
- 查询ip
ifconfig | grep "inet " | grep -v 127.0.0.1
- 如何在Ubuntu 14.10 上安装WordPress?
http://codex.wordpress.org/zh-cn:安装WordPress 介绍 如果你想快捷.简单.免费的创建个人网站的话,WordPress 是你最佳的选择. WordPress 是 ...
- [Error] 'for' loop initial declarations are only allowed in C99 or C11 mode
#include <stdio.h> #include <stdlib.h> #define LIST_INIT_SIZE 100 //线性表存储空间的初始分配量 #defin ...
- 涉及不同实例不同数据库的同一条sql语句
exec sp_configure 'show advanced options',1 reconfigure exec sp_configure 'Ad Hoc Distributed Querie ...
- javaScript高级教程(三) javaScript不支持关联数组,只是语法上像关联数组
1.在js中所有要素都是继承自Object对象的,任何对象都能通过obj['name'] = something的形式来添加属性,相当于obj.name=something. 之所以设计中括号这种存取 ...
- sql优化 性能快速定位
sql server sql性能快速定位 简介 对于写出实现功能的SQL语句和既能实现功能又能保证性能的SQL语句的差别是巨大的.很多时候开发人员仅仅是把精力放在实现所需的功能上,而忽略了其所写代码的 ...
- MySQL管理之道:性能调优、高可用与监控》迷你书
MySQL管理之道:性能调优.高可用与监控>迷你书 MYSQL5.5.X主要改进 1.默认使用innodb存储引擎2.充分利用CPU多核处理能力3.提高刷写脏页数量和合并插入数量,改善I/O4. ...