ELK + kafka 日志方案
概述
详细
本文介绍使用ELK(elasticsearch、logstash、kibana) + kafka来搭建一个日志系统。主要演示使用spring aop进行日志收集,然后通过kafka将日志发送给logstash,logstash再将日志写入elasticsearch,这样elasticsearch就有了日志数据了,最后,则使用kibana将存放在elasticsearch中的日志数据显示出来,并且可以做实时的数据图表分析等等。
为什么用ELK
以前不用ELK的做法
最开始我些项目的时候,都习惯用log4j来把日志写到log文件中,后来项目有了高可用的要求,我们就进行了分布式部署web,这样我们还是用log4j这样的方式来记录log的话,那么就有N台机子的N个log目录,这个时候查找log起来非常麻烦,不知道问题用户出错log是写在哪一台服务器上的,后来,想到一个办法,干脆把log直接写到数据库中去,这样做,虽然解决了查找异常信息便利性的问题了,但存在两个缺陷:
1,log记录好多,表不够用啊,又得分库分表了,
2,连接db,如果是数据库异常,那边log就丢失了,那么为了解决log丢失的问题,那么还得先将log写在本地,然后等db连通了后,再将log同步到db,这样的处理办法,感觉是越搞越复杂。
现在ELK的做法
好在现在有了ELK这样的方案,可以解决以上存在的烦恼,首先是,使用elasticsearch来存储日志信息,对一般系统来说可以理解为可以存储无限条数据,因为elasticsearch有良好的扩展性,然后是有一个logstash,可以把理解为数据接口,为elasticsearch对接外面过来的log数据,它对接的渠道,有kafka,有log文件,有redis等等,足够兼容N多log形式,最后还有一个部分就是kibana,它主要用来做数据展现,log那么多数据都存放在elasticsearch中,我们得看看log是什么样子的吧,这个kibana就是为了让我们看log数据的,但还有一个更重要的功能是,可以编辑N种图表形式,什么柱状图,折线图等等,来对log数据进行直观的展现。
ELK职能分工
logstash做日志对接,接受应用系统的log,然后将其写入到elasticsearch中,logstash可以支持N种log渠道,kafka渠道写进来的、和log目录对接的方式、也可以对reids中的log数据进行监控读取,等等。
elasticsearch存储日志数据,方便的扩展特效,可以存储足够多的日志数据。
kibana则是对存放在elasticsearch中的log数据进行:数据展现、报表展现,并且是实时的。
怎样用ELK
首先说明一点,使用ELK是不需要开发的,只需要搭建环境使用即可。搭建环境,可以理解为,下载XX软件,然后配置下XX端口啊,XX地址啊,XX日志转发规则啊等等,当配置完毕后,然后点击XX bat文件,然后启动。
Logstash配置
可以配置接入N多种log渠道,现状我配置的只是接入kafka渠道。
配置文件在\logstash-2.3.4\config目录下
要配置的是如下两个参数体:
input:数据来源。
output:数据存储到哪里。
input {
kafka {
zk_connect => "127.0.0.1:2181"
topic_id => "mylog_topic"
}
}
filter {
#Only matched data are send to output.
}
output {
#stdout{}
# For detail config for elasticsearch as output,
# See: https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html
elasticsearch {
action => "index" #The operation on ES
hosts => "127.0.0.1:9200" #ElasticSearch host, can be array.
index => "my_logs" #The index to write data to.
}
}
Elasticsearch配置
配置文件在\elasticsearch-2.3.3\config目录下的elasticsearch.yml,可以配置允许访问的IP地址,端口等,但我这里是采取默认配置。
Kibana配置
配置文件在\kibana-4.5.4-windows\config目录下的kibana.yml,可以配置允许访问的IP地址,端口等,但我这里是采取默认配置。
这里有一个需要注意的配置,就是指定访问elasticsearch的地址。我这里是同一台机子做测试,所以也是采取默认值了。
# The Elasticsearch instance to use for all your queries.
# elasticsearch.url: "http://localhost:9200"
关于ELK的配置大致上,就这样就可以了,当然其实还有N多配置项可供配置的,具体可以google。这里就不展开说了。
具体的配置请下载运行环境,里面有具体的配置。
和spring aop日志对接
elk环境搭建完毕后,需要在应用系统做日志的aop实现。
部分spring配置
<aop:aspectj-autoproxy />
<aop:aspectj-autoproxy proxy-target-class="true" /> <!-- 扫描web包,应用Spring的注解 -->
<context:component-scan base-package="com.demodashi">
<context:include-filter type="annotation" expression="org.springframework.stereotype.Controller" />
<context:exclude-filter type="annotation" expression="javax.inject.Named" />
<context:exclude-filter type="annotation" expression="javax.inject.Inject" />
</context:component-scan>
部分java代码
package com.demodashi.aop.annotation;
import java.lang.annotation.*; /**
*自定义注解 拦截service
*/ @Target({ElementType.PARAMETER, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface ServiceLogAnnotation { String description() default "";
}
package com.demodashi.aop.annotation;
import java.lang.annotation.*; /**
*自定义注解 拦截Controller
*/ @Target({ElementType.PARAMETER, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface ControllerLogAnnotation { String description() default "";
}
代码截图
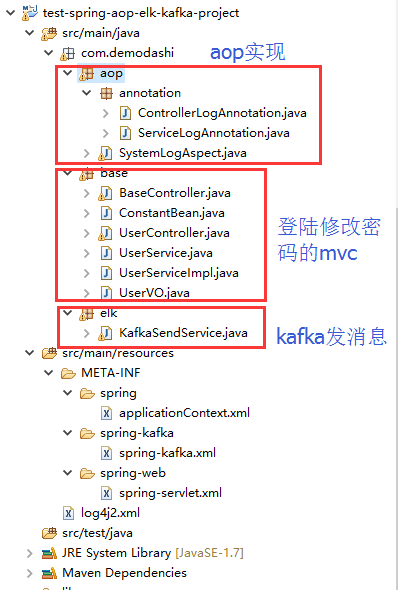
日志和kafka、和logstash、elasticsearch、kibana直接的关系
ELK,kafka、aop之间的关系
1、aop对日志进行收集,然后通过kafka发送出去,发送的时候,指定了topic(在spring配置文件中配置为 topic="mylog_topic")
2、logstash指定接手topic为 mylog_topic的kafka消息(在config目录下的配置文件中,有一个input的配置)
3、然后logstash还定义了将接收到的kafka消息,写入到索引为my_logs的库中(output中有定义)
4、再在kibana配置中,指定要连接那个elasticsearch(kibana.yml中有配置,默认为本机)
5、最后是访问kibana,在kibana的控制台中,设置要访问elasticsearch中的哪个index。
部署ELK + kafka环境
我本机的环境是jdk8.0,我记得测试的过程中,elasticsearch对jdk有特别的要求,必须是jdk7或者以上。
下载运行环境附件,并解压后,看到如下:

这些运行环境,在每个软件里面,都有具体的启动说明,如kafka的目录下,这样:
按照启动说明的命令来执行,即可启动。
这里需要说明一点,最先启动,应该是zookeeper,然后才是其他的,其他几个没有严格区分启动顺序。
直接在window下面,同一台机子启动即可。除了kibana-4.5.4-windows外,其他几个也是可以在linux下运行的。
运行效果
项目导入到eclipse后,启动,然后访问如下地址:

用户名为 1001 密码为 123
登陆后能看到如下:
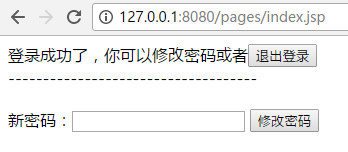
本例子是对修改密码做了日志拦截。所以修改密码的动作,能看到打印如下信息:

然后是观察一下aop日志拦截,是否被kafka发送给logstash了,是否被写入了elasticsearch了。
访问elasticsearch,http://127.0.0.1:9200/_plugin/head/ 如下:
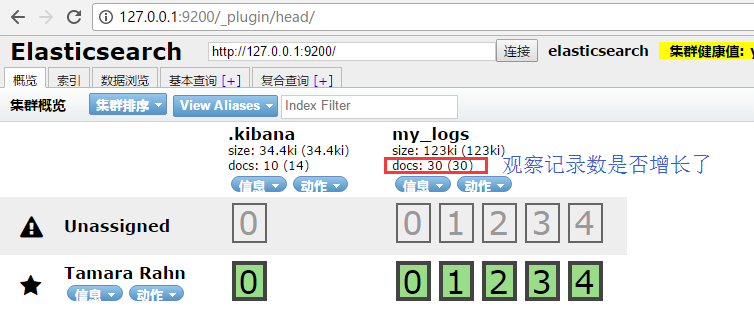
注意观察我们定义的my_logs这个索引库是否增加记录了。
访问kibana:
http://127.0.0.1:5601/app/kibana
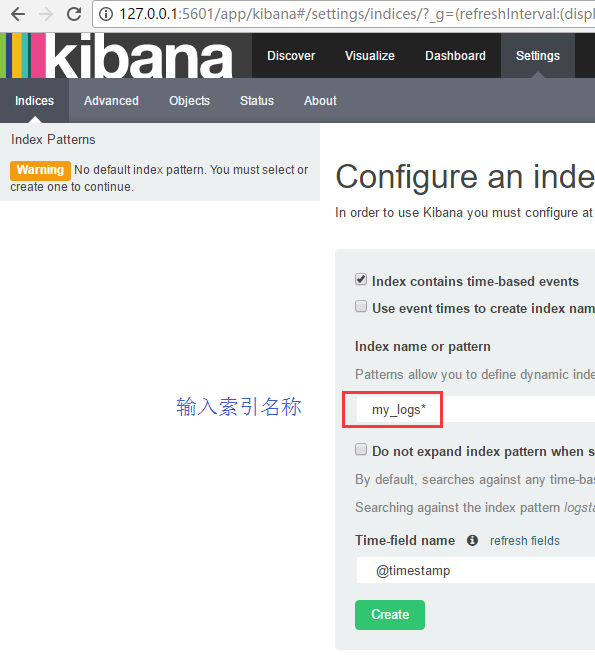
在输入索引名称后,再点击 create按钮,即可得到如下界面:
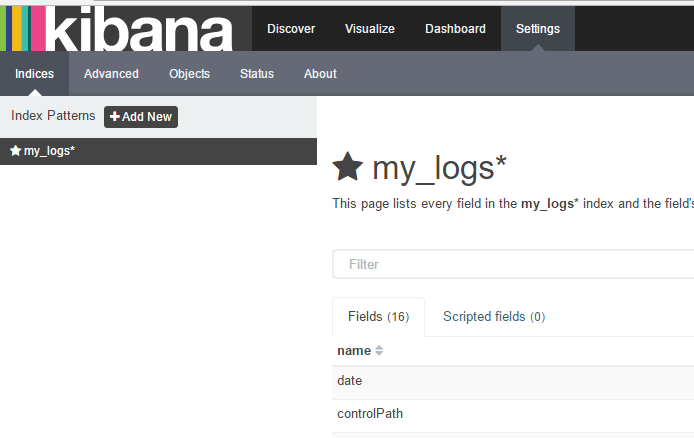
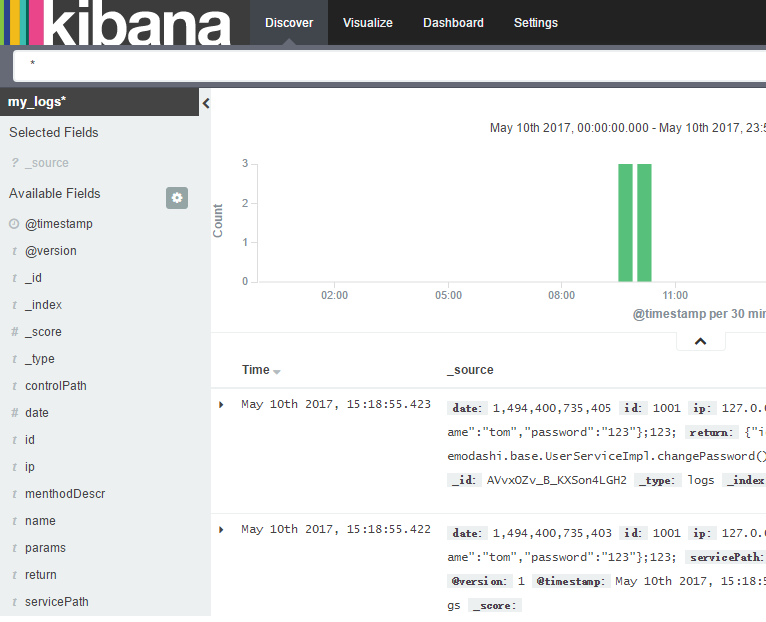
然后再点击Discover,界面如下:
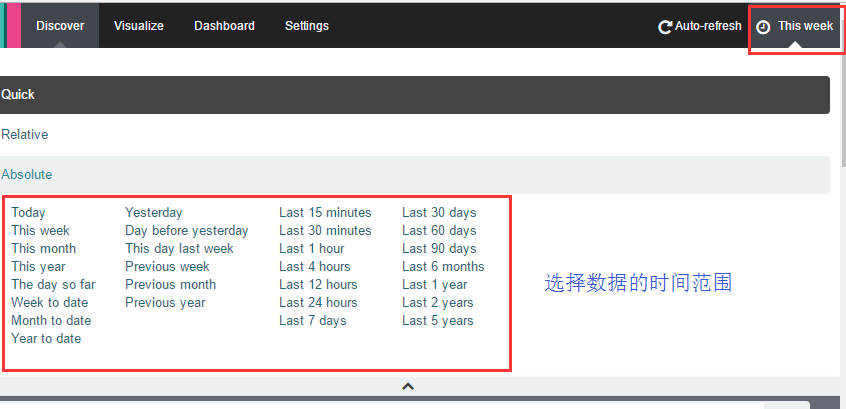
如果你看不到数据,记得点击右上角的按钮来选择数据的时间范围:
到这里就完成了,日志的AOP收集,日志的流转,并写入到elasticsearch,并用kibana看数据。
当然kibana还有很重要的一个功能是数据分析图表的配置,主要是通过向导来完成。
高可用实现
现在实现的是一个最基本的日志收集,日志传输,日志存储以及日志展示的一条链路的功能,如果系统上线,还需要做一定的集群,如kafka集群,zookeeper集群,还有elasticsearch集群
注:本文著作权归作者,由demo大师发表,拒绝转载,转载需要作者授权
ELK + kafka 日志方案的更多相关文章
- 离线部署ELK+kafka日志管理系统【转】
转自 离线部署ELK+kafka日志管理系统 - xiaoxiaozhou - 51CTO技术博客http://xiaoxiaozhou.blog.51cto.com/4681537/1854684 ...
- ELK+Kafka学习笔记之搭建ELK+Kafka日志收集系统集群
0x00 概述 关于如何搭建ELK部分,请参考这篇文章,https://www.cnblogs.com/JetpropelledSnake/p/9893566.html. 该篇用户为非root,使用用 ...
- ELK+kafka日志收集分析系统
环境: 服务器IP 软件 版本 192.168.0.156 zookeeper+kafka zk:3.4.14 kafka:2.11-2.2.0 192.168.0.42 zookeeper+kaf ...
- ELK+kafka日志收集
一.服务器信息 版本 部署服务器 用途 备注 JDK jdk1.8.0_102 使用ELK5的服务器 Logstash 5.1.1 安装Tomcat的服务器 发送日志 Kafka降插件版本 Log ...
- .Net Core 商城微服务项目系列(十三):搭建Log4net+ELK+Kafka日志框架
之前是使用NLog直接将日志发送到了ELK,本篇将会使用Docker搭建ELK和kafka,同时替换NLog为Log4net. 一.搭建kafka 1.拉取镜像 //下载zookeeper docke ...
- ELK+kafka日志处理
此次使用kafka代替redis,elk集群搭建过程请参考:https://www.cnblogs.com/dmjx/p/9120474.html kafka名词解释: 1.话题(Topic):是特定 ...
- ELK+Kafka日志收集环境搭建
1.搭建Elasticsearch环境并测试: (1)删除es的容器 (2)删除es的镜像 (3)宿主机调内存: 执行命令:sudo sysctl -w vm.max_map_count=655360 ...
- ELK+Kafka
kafka:接收java程序投递的消息的日志队列 logstash:日志解析,格式化数据为json并输出到es中 elasticsearch:实时搜索搜索引擎,存储数据 kibana:基于es的数据可 ...
- ELK + kafka 分布式日志解决方案
概述 本文介绍使用ELK(elasticsearch.logstash.kibana) + kafka来搭建一个日志系统.主要演示使用spring aop进行日志收集,然后通过kafka将日志发送给l ...
随机推荐
- source insight 4.0.086破解
source insight 4.0.093 破解: 1. 安装原版软件:Source Insight Version 4.0.0093 - March 20, 2018 2. 替换原主程序:sou ...
- CSS-设置Footer始终在页面底部
Footer顾名思义页脚,如果内容多的时候在底部时感官很好,但是当内容变少(无法撑开一屏的时候)footer不固定在底部,影响美观,对于已经从事前端工作的工作的来说应该是比价工作中入门级别的问题了,由 ...
- 微信公众号网页授权获取用户openid
最近一个项目是在微信公众号内二次开发,涉及到微信公众号支付,根据文档要求想要支付就必须要获取到用户的openid. 这是微信官方文档https://mp.weixin.qq.com/wiki?t=re ...
- android 微信听筒无声
Dual talk项目sim卡插在卡2时.微信听筒无声: 第三方APP在听筒接听语音时会固定去设audio_mode为incall,而不会去管以下是sim1还是sim2在位. 而speechdrive ...
- Spark:java api实现word count统计
方案一:使用reduceByKey 数据word.txt 张三 李四 王五 李四 王五 李四 王五 李四 王五 王五 李四 李四 李四 李四 李四 代码: import org.apache.spar ...
- 转:写的不错的eclipse配置cdt的文章
http://jingpin.jikexueyuan.com/article/22803.html
- Eclipse中GitLab的配置和使用入门
一.Eclipse中配置GitLab的前提条件 1.1:安装Git客户端 去官网https://git-scm.com/downloads下载合适的版本即可,一般开发环境是windows的就下载win ...
- OpenNebula学习第一节OpenNebula Front-end Installation
一.说说情怀 随着公司硬件开发资源的不足,构建一个云平台似乎重要了起来.当然,也不是这个平台搭建的主力,出于工作的需求和个人兴趣爱好,接下来就来学习一下OpenNebula相关的东西,这是第一节课,先 ...
- 全国第二届Revit开发实战训练营在北京圆满落幕
由北京橄榄山软件公司与筑城网校中国BIM培训网共同举办的"全国第二届Revit开发实战训练营于1月1日在筑城网校培训教室如期开班. 參加此次培训的有上海同济大学建筑设计研究院(集团)有限公司 ...
- Google想出了一个决定人员晋升的算法,然后就没有然后了......
Google 有点跑偏了,逗死我了~实践一下也好~ Prasad Setty 是 Google People Analytics 团队的副总裁.7 年前 Google 成立的这支团队的职责是收集和利用 ...