简单的爬虫例子——爬取豆瓣Top250的电影的排名、名字、评分、评论数
爬取思路:
url从网页上把代码搞下来
bytes decode ---> utf-8 网页内容就是我的待匹配的字符串
ret = re.findall(正则,待匹配的字符串), ret 是所有匹配到的内容组成的列表
import re
import json
from urllib.request import urlopen # (1)re.compile——爬取到文件中 def getPage(url):
response = urlopen(url)
return response.read().decode('utf-8') def parsePage(s):
com = re.compile(
'<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',re.S
)
ret = com.finditer(s)
for i in ret:
yield {
"id":i.group("id"),
"title":i.group("title"),
"rating_num":i.group("rating_num"),
"comment_num":i.group("comment_num"),
} def main(num):
url = 'https://movie.douban.com/top250?start=%s&filter=' % num
response_html = getPage(url)
ret = parsePage(response_html)
print(ret)
f = open("movie_info","a",encoding="utf-8") for obj in ret:
print(obj)
data = str(obj)
f.write(data + "\n")
f.close() count = 0
for i in range(10): # 10页
main(count)
count += 25
import re
import json
from urllib.request import urlopen
# (2)re.findall——打印输出 import re
import json
from urllib.request import urlopen def getPage(url):
response = urlopen(url)
return response.read().decode('utf-8') def parsePage(s):
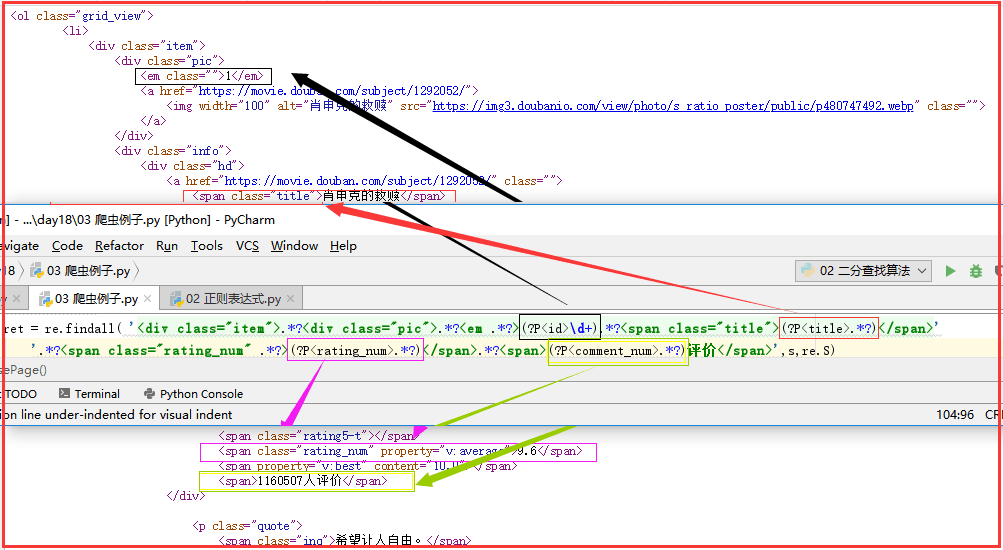
ret = re.findall( '<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',s,re.S)
return ret def main(num):
url = 'https://movie.douban.com/top250?start=%s&filter=' % num
response_html = getPage(url)
ret = parsePage(response_html)
print(ret) count = 0
for i in range(10): #10页
main(count)
count += 25
正则表达式详解:
简单的爬虫例子——爬取豆瓣Top250的电影的排名、名字、评分、评论数的更多相关文章
- 爬虫之爬取豆瓣top250电影排行榜及爬取斗图啦表情包解读及爬虫知识点补充
今日内容概要 如何将爬取的数据直接导入Excel表格 #如何通过Python代码操作Excel表格 #前戏 import requests import time from openpyxl impo ...
- python爬取豆瓣top250的电影数据并存入excle
爬取网址: https://movie.douban.com/top250 一:爬取思路(新手可以看一下) : 1:定义两个函数,一个get_page函数爬取数据,一个save函数保存数据,mian中 ...
- 零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习.话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的. python环境:pytho ...
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- 第一个nodejs爬虫:爬取豆瓣电影图片
第一个nodejs爬虫:爬取豆瓣电影图片存入本地: 首先在命令行下 npm install request cheerio express -save; 代码: var http = require( ...
- requests爬取豆瓣top250电影信息
''' 1.爬取豆瓣top250电影信息 - 第一页: https://movie.douban.com/top250?start=0&filter= - 第二页: https://movie ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python-爬虫实战 简单爬取豆瓣top250电影保存到本地
爬虫原理 发送数据 获取数据 解析数据 保存数据 requests请求库 res = requests.get(url="目标网站地址") 获取二进制流方法:res.content ...
随机推荐
- 开启turbine收集hystrix指标功能
使用turbine收集hystrix指标 1.pom中引入对turbin的依赖,并增加dashboard图形界面的展示 <dependencies> <dependency> ...
- 067——VUE中vue-router之使用transition设置酷炫的路由组件过渡动画效果
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Openwrt Export Gpio Configure (7)
1 Scope of Document This document describes how to export gpio interface under gpio-export driv ...
- Oracle11g 查询长时间运行的SQL
一.大量的查询 某些时候,因为SQL的问题,导致数据库的session大量积压,服务器的磁盘读增大,CPU使用率剧增.一般这种SQL,都是一些全表扫描.多表关联.报表或者排序类的SQL.这中情况很有可 ...
- 返回值为record类型的函 初始化 内存泄漏 复制
1.函数需要初始化,否则下次调用函数时,Result还是上次的值,可能会引起误判.但是不会有内存泄漏,即使包含string类型的成员. 2.如果record包含的都是值类型的成员,比如integer, ...
- python随机数,随机选择……random
import random from random import random, uniform, randint, randrange, choice, sample, shuffle list = ...
- Android中检测字符编码(GB2312,ASCII,UTF8,UNICODE,TOTAL——ENCODINGS)方法(一)
package com.android.filebrowser; import java.io.*; import java.net.*; public class FileEncodingD ...
- tensorflow训练打游戏ai
python3,所需模块请自行补齐 # coding=utf8 import pygame import random from pygame.locals import * import numpy ...
- HDU 1853
http://acm.hdu.edu.cn/showproblem.php?pid=1853 和下题一模一样,求一个图环的并,此题的题干说的非常之裸露 http://www.cnblogs.com/x ...
- chapter02 三种决策树模型:单一决策树、随机森林、GBDT(梯度提升决策树) 预测泰坦尼克号乘客生还情况
单一标准的决策树:会根每维特征对预测结果的影响程度进行排序,进而决定不同特征从上至下构建分类节点的顺序.Random Forest Classifier:使用相同的训练样本同时搭建多个独立的分类模型, ...