基础 | batchnorm原理及代码详解
https://blog.csdn.net/qq_25737169/article/details/79048516
https://www.cnblogs.com/bonelee/p/8528722.html
Notes on Batch Normalization
Notes on Batch Normalization
在训练深层神经网络的过程中, 由于输入层的参数在不停的变化, 因此, 导致了当前层的分布在不停的变化, 这就导致了在训练的过程中, 要求 learning rate 要设置的非常小, 另外, 对参数的初始化的要求也很高. 作者把这种现象称为 internal convariate shift. Batch Normalization 的提出就是为了解决这个问题的. BN 在每一个 training mini-batch 中对每一个 feature 进行 normalize. 通过这种方法, 使得网络可以使用较大的 learning rate, 而且, BN 具有一定的 regularization 作用.
为什么需要 Batch Normalization
在神经网络的优化中最常用最进本的方法是 SGD, 其目标是寻找最小化 loss function 的参数:
[Math Processing Error]θ=argminθ1N∑i=1NL(xi,θ)
在求解的过程中, 一般是使用 minibatch 的方法, 简单来说, 就是计算下面的梯度:
[Math Processing Error]1m∑∂L(xi,θ)∂θ
使用 minibatch 的方法有两个好处:
- minibatch 计算出来的 loss 可以看做是整个 trainset 的 loss 的近似值.
- minibatch 中, 可以并行地计算 m 各样本, 因此, 使用 minibatch 的方法比原始的 SGD 方法速度更快.
然而, SGD 算法有其固有缺点:
- 对初始值要求很高, 如果参数的初始化不好, 经常不能收敛
- 学习率比较难设置, 由于每一层 input 数据的 scale 不同, 导致 backward 的梯度的 scale 也不同, 为了保证不会 gradient vanish, 只能设置较小的 learning rate, 而, 较小的 learning rate 使得整个学习过程很慢
- 第 N 层的输入受前面 N-1 层的影响, 在深度学习中, 网络层数很多, 因此, 及时前面 layer 的很小的影响, 当到达第 N 层的时候, 会被放大很多倍.
在深度神经网络中, 每一层输入数据的分布都不同, 因此, 每一层的参数都要去学习不同的分布. 而主要由于上述 #3 的原因, 使得这个过程比较困难. 为了说明这个问题, 使用一个简单的例子. 考虑如下的一个两层的神经网络:
[Math Processing Error]F2(F1(θ1,x),θ2)
[Math Processing Error]F1 的输出作为 [Math Processing Error]F2 的输入, 因此, 在学习的过程中, 当 [Math Processing Error]F1 的输入 [Math Processing Error]x 的分布变化的时候 (在选择 minibatch 的使用根本无法保证每次选择的 minibatch 的分布是相同的), [Math Processing Error]F2 的参数在向最优解收敛的过程中就会产生偏差, 因此, 导致了收敛速度变慢. 而 BN 就是要解决这个问题.
想象一下, 如果 [Math Processing Error]F2 的学习不受 [Math Processing Error]F1 的输入 [Math Processing Error]x 的影响, 即不管 [Math Processing Error]x 输入的是什么, [Math Processing Error]F2 的输入都是相同的分布, 这样, [Math Processing Error]F2 就不用调整去适应由于 [Math Processing Error]x 输入变化带来的影响, 那么, 是否就可以解决这个问题了呢? 因此, 这就是 BN 的提出.
Batch Normalization 是什么
Input: Values of [Math Processing Error]x over a mini-batch, [Math Processing Error]B=x1…m
Output: [Math Processing Error]γ,β
[Math Processing Error](1)μβ=1m∑i=1mxi(2)σβ2=1m∑i=1m(xi−μβ)2(3)x^i=xi−μβσβ2+ϵ(4)yi=γx^i+β
为什么 Batch Normalization 可以加速训练
- 允许网络使用较高的 learning rate. 在传统的深度网络训练中, 如果使用较大的 learning rate 很容易导致 gradient vanish 或者 gradient explode. 通过在整个网络中 normalize activations, 可以防止参数的较小的改变被应用到较大的或者次优的 activation 中. 另一方面, BN 使得网络对于 parameter 的 scale 更加鲁棒. 通常情况下, large learning rate 会 increase the scale of layer parameters, 进而会放大 BP 的梯度, 导致了 model explosion. BN 的使用使得网络在 BP 的时候不会受到 parameter scale 的影响. 这是因为: [Math Processing Error](5)BN(Wu)=BN((aW)u)(6)(7)∂BN((aW)u)∂u=∂Wu∂u(8)(9)∂BN((aW)u)∂aW=1a⋅∂Wu∂W
- 具有一定的 regularization 作用, 可以减少 Dropout 的使用. dropout 的作用是方法 overfitting, 实验发现, BN 可以 reduce overfitting.
- 降低 [Math Processing Error]L2 权重衰减系数.
- 取消 LRN(Local Response Normalization).
- Reduce the photomatric distortions. 因为 BN 使得训练过程更快, 能 observe 到的 sample 次数变少, 所以, 减少 distorting 使得网络 focus 在真实的图片上面.
- BN 不仅仅限定在 ReLU 上, 而且, 对其它的 activation 也同样适用.
基础 | batchnorm原理及代码详解
前言:Batchnorm是深度网络中经常用到的加速神经网络训练,加速收敛速度及稳定性的算法,可以说是目前深度网络必不可少的一部分。
本文旨在用通俗易懂的语言,对深度学习的常用算法–batchnorm的原理及其代码实现做一个详细的解读。本文主要包括以下几个部分。
- Batchnorm主要解决的问题
- Batchnorm原理解读
- Batchnorm的优点
- Batchnorm的源码解读
第一节:Batchnorm主要解决的问题
首先,此部分也即是讲为什么深度网络会需要batchnormbatchnorm,我们都知道,深度学习的话尤其是在CV上都需要对数据做归一化,因为深度神经网络主要就是为了学习训练数据的分布,并在测试集上达到很好的泛化效果,但是,如果我们每一个batch输入的数据都具有不同的分布,显然会给网络的训练带来困难。另一方面,数据经过一层层网络计算后,其数据分布也在发生着变化,此现象称为InternalInternal CovariateCovariate ShiftShift,接下来会详细解释,会给下一层的网络学习带来困难。batchnormbatchnorm直译过来就是批规范化,就是为了解决这个分布变化问题。
1.1 Internal Covariate Shift
InternalInternal CovariateCovariate ShiftShift :此术语是google小组在论文BatchBatch NormalizatoinNormalizatoin 中提出来的,其主要描述的是:训练深度网络的时候经常发生训练困难的问题,因为,每一次参数迭代更新后,上一层网络的输出数据经过这一层网络计算后,数据的分布会发生变化,为下一层网络的学习带来困难(神经网络本来就是要学习数据的分布,要是分布一直在变,学习就很难了),此现象称之为InternalInternal CovariateCovariate ShiftShift。
BatchBatch NormalizatoinNormalizatoin 之前的解决方案就是使用较小的学习率,和小心的初始化参数,对数据做白化处理,但是显然治标不治本。
1.2 covariate shift
InternalInternal CovariateCovariate ShiftShift 和CovariateCovariate ShiftShift具有相似性,但并不是一个东西,前者发生在神经网络的内部,所以是InternalInternal,后者发生在输入数据上。CovariateCovariate ShiftShift主要描述的是由于训练数据和测试数据存在分布的差异性,给网络的泛化性和训练速度带来了影响,我们经常使用的方法是做归一化或者白化。想要直观感受的话,看下图:
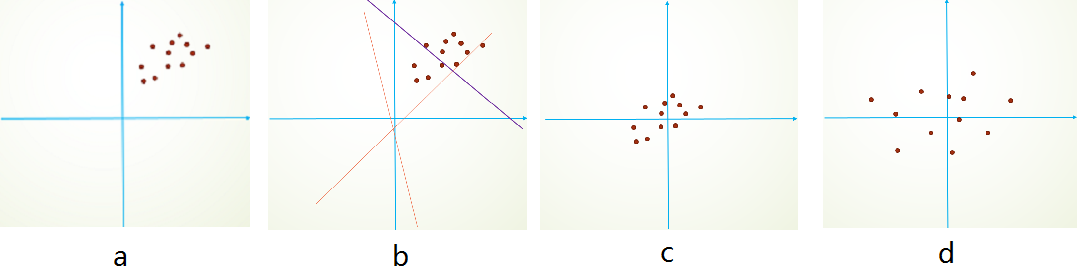
举个简单线性分类栗子,假设我们的数据分布如a所示,参数初始化一般是0均值,和较小的方差,此时拟合的y=wx+by=wx+b如b图中的橘色线,经过多次迭代后,达到紫色线,此时具有很好的分类效果,但是如果我们将其归一化到0点附近,显然会加快训练速度,如此我们更进一步的通过变换拉大数据之间的相对差异性,那么就更容易区分了。
CovariateCovariate ShiftShift 就是描述的输入数据分布不一致的现象,对数据做归一化当然可以加快训练速度,能对数据做去相关性,突出它们之间的分布相对差异就更好了。BatchnormBatchnorm做到了,前文已说过,BatchnormBatchnorm是归一化的一种手段,极限来说,这种方式会减小图像之间的绝对差异,突出相对差异,加快训练速度。所以说,并不是在深度学习的所有领域都可以使用BatchNormBatchNorm,下文会写到其不适用的情况。
第二节:Batchnorm 原理解读
本部分主要结合原论文部分,排除一些复杂的数学公式,对BatchNormBatchNorm的原理做尽可能详细的解释。
之前就说过,为了减小InternalInternal CovariateCovariate ShiftShift,对神经网络的每一层做归一化不就可以了,假设将每一层输出后的数据都归一化到0均值,1方差,满足正太分布,但是,此时有一个问题,每一层的数据分布都是标准正太分布,导致其完全学习不到输入数据的特征,因为,费劲心思学习到的特征分布被归一化了,因此,直接对每一层做归一化显然是不合理的。
但是如果稍作修改,加入可训练的参数做归一化,那就是BatchNormBatchNorm实现的了,接下来结合下图的伪代码做详细的分析:

之所以称之为batchnorm是因为所norm的数据是一个batch的,假设输入数据是β=x1...mβ=x1...m共m个数据,输出是yi=BN(x)yi=BN(x),batchnormbatchnorm的步骤如下:
1.先求出此次批量数据xx的均值,μβ=1m∑mi=1xiμβ=1m∑i=1mxi
2.求出此次batch的方差,σ2β=1m∑i=1m(xi−μβ)2σβ2=1m∑i=1m(xi−μβ)2
3.接下来就是对xx做归一化,得到x−ixi−
4.最重要的一步,引入缩放和平移变量γγ和ββ ,计算归一化后的值,yi=γx−iyi=γxi− +β+β
接下来详细介绍一下这额外的两个参数,之前也说过如果直接做归一化不做其他处理,神经网络是学不到任何东西的,但是加入这两个参数后,事情就不一样了,先考虑特殊情况下,如果γγ和ββ分别等于此batch的方差和均值,那么yiyi不就还原到归一化前的xx了吗,也即是缩放平移到了归一化前的分布,相当于batchnormbatchnorm没有起作用,ββ 和γγ分别称之为 平移参数和缩放参数 。这样就保证了每一次数据经过归一化后还保留的有学习来的特征,同时又能完成归一化这个操作,加速训练。
先用一个简单的代码举个小栗子:
def Batchnorm_simple_for_train(x, gamma, beta, bn_param):
"""
param:x : 输入数据,设shape(B,L)
param:gama : 缩放因子 γ
param:beta : 平移因子 β
param:bn_param : batchnorm所需要的一些参数
eps : 接近0的数,防止分母出现0
momentum : 动量参数,一般为0.9, 0.99, 0.999
running_mean :滑动平均的方式计算新的均值,训练时计算,为测试数据做准备
running_var : 滑动平均的方式计算新的方差,训练时计算,为测试数据做准备
"""
running_mean = bn_param['running_mean'] #shape = [B]
running_var = bn_param['running_var'] #shape = [B]
results = 0. # 建立一个新的变量
x_mean=x.mean(axis=0) # 计算x的均值
x_var=x.var(axis=0) # 计算方差
x_normalized=(x-x_mean)/np.sqrt(x_var+eps) # 归一化
results = gamma * x_normalized + beta # 缩放平移
running_mean = momentum * running_mean + (1 - momentum) * x_mean
running_var = momentum * running_var + (1 - momentum) * x_var
#记录新的值
bn_param['running_mean'] = running_mean
bn_param['running_var'] = running_var
return results , bn_param看完这个代码是不是对batchnorm有了一个清晰的理解,首先计算均值和方差,然后归一化,然后缩放和平移,完事!但是这是在训练中完成的任务,每次训练给一个批量,然后计算批量的均值方差,但是在测试的时候可不是这样,测试的时候每次只输入一张图片,这怎么计算批量的均值和方差,于是,就有了代码中下面两行,在训练的时候实现计算好meanmean varvar测试的时候直接拿来用就可以了,不用计算均值和方差。
running_mean = momentum * running_mean + (1 - momentum) * x_mean
running_var = momentum * running_var + (1 - momentum) * x_var所以,测试的时候是这样的:
def Batchnorm_simple_for_test(x, gamma, beta, bn_param):
"""
param:x : 输入数据,设shape(B,L)
param:gama : 缩放因子 γ
param:beta : 平移因子 β
param:bn_param : batchnorm所需要的一些参数
eps : 接近0的数,防止分母出现0
momentum : 动量参数,一般为0.9, 0.99, 0.999
running_mean :滑动平均的方式计算新的均值,训练时计算,为测试数据做准备
running_var : 滑动平均的方式计算新的方差,训练时计算,为测试数据做准备
"""
running_mean = bn_param['running_mean'] #shape = [B]
running_var = bn_param['running_var'] #shape = [B]
results = 0. # 建立一个新的变量
x_normalized=(x-running_mean )/np.sqrt(running_var +eps) # 归一化
results = gamma * x_normalized + beta # 缩放平移
return results , bn_param你是否理解了呢?如果还没有理解的话,欢迎再多看几遍。
第三节:Batchnorm源码解读
本节主要讲解一段tensorflow中BatchnormBatchnorm的可以使用的代码33,如下:
代码来自知乎,这里加入注释帮助阅读。
def batch_norm_layer(x, train_phase, scope_bn):
with tf.variable_scope(scope_bn):
# 新建两个变量,平移、缩放因子
beta = tf.Variable(tf.constant(0.0, shape=[x.shape[-1]]), name='beta', trainable=True)
gamma = tf.Variable(tf.constant(1.0, shape=[x.shape[-1]]), name='gamma', trainable=True)
# 计算此次批量的均值和方差
axises = np.arange(len(x.shape) - 1)
batch_mean, batch_var = tf.nn.moments(x, axises, name='moments')
# 滑动平均做衰减
ema = tf.train.ExponentialMovingAverage(decay=0.5)
def mean_var_with_update():
ema_apply_op = ema.apply([batch_mean, batch_var])
with tf.control_dependencies([ema_apply_op]):
return tf.identity(batch_mean), tf.identity(batch_var)
# train_phase 训练还是测试的flag
# 训练阶段计算runing_mean和runing_var,使用mean_var_with_update()函数
# 测试的时候直接把之前计算的拿去用 ema.average(batch_mean)
mean, var = tf.cond(train_phase, mean_var_with_update,
lambda: (ema.average(batch_mean), ema.average(batch_var)))
normed = tf.nn.batch_normalization(x, mean, var, beta, gamma, 1e-3)
return normed至于此行代码tf.nn.batch_normalization()就是简单的计算batchnorm过程啦,代码如下:
这个函数所实现的功能就如此公式:γ(x−μ)σ+βγ(x−μ)σ+β
def batch_normalization(x,
mean,
variance,
offset,
scale,
variance_epsilon,
name=None):
with ops.name_scope(name, "batchnorm", [x, mean, variance, scale, offset]):
inv = math_ops.rsqrt(variance + variance_epsilon)
if scale is not None:
inv *= scale
return x * inv + (offset - mean * inv
if offset is not None else -mean * inv)第四节:Batchnorm的优点
主要部分说完了,接下来对BatchNorm做一个总结:
- 没有它之前,需要小心的调整学习率和权重初始化,但是有了BN可以放心的使用大学习率,但是使用了BN,就不用小心的调参了,较大的学习率极大的提高了学习速度,
- Batchnorm本身上也是一种正则的方式,可以代替其他正则方式如dropout等
- 另外,个人认为,batchnorm降低了数据之间的绝对差异,有一个去相关的性质,更多的考虑相对差异性,因此在分类任务上具有更好的效果。
注:或许大家都知道了,韩国团队在2017NTIRE图像超分辨率中取得了top1的成绩,主要原因竟是去掉了网络中的batchnorm层,由此可见,BN并不是适用于所有任务的,在image-to-image这样的任务中,尤其是超分辨率上,图像的绝对差异显得尤为重要,所以batchnorm的scale并不适合。
参考文献:
【1】http://blog.csdn.net/zhikangfu/article/details/53391840
【2】http://geek.csdn.net/news/detail/160906
【3】 https://www.zhihu.com/question/53133249
http://shuokay.com/2016/05/28/batch-norm/
Notes on Batch Normalization
在训练深层神经网络的过程中, 由于输入层的参数在不停的变化, 因此, 导致了当前层的分布在不停的变化, 这就导致了在训练的过程中, 要求 learning rate 要设置的非常小, 另外, 对参数的初始化的要求也很高. 作者把这种现象称为 internal convariate shift. Batch Normalization 的提出就是为了解决这个问题的. BN 在每一个 training mini-batch 中对每一个 feature 进行 normalize. 通过这种方法, 使得网络可以使用较大的 learning rate, 而且, BN 具有一定的 regularization 作用.
为什么需要 Batch Normalization
在神经网络的优化中最常用最进本的方法是 SGD, 其目标是寻找最小化 loss function 的参数:
在求解的过程中, 一般是使用 minibatch 的方法, 简单来说, 就是计算下面的梯度:
使用 minibatch 的方法有两个好处:
- minibatch 计算出来的 loss 可以看做是整个 trainset 的 loss 的近似值.
- minibatch 中, 可以并行地计算 m 各样本, 因此, 使用 minibatch 的方法比原始的 SGD 方法速度更快.
然而, SGD 算法有其固有缺点:
- 对初始值要求很高, 如果参数的初始化不好, 经常不能收敛
- 学习率比较难设置, 由于每一层 input 数据的 scale 不同, 导致 backward 的梯度的 scale 也不同, 为了保证不会 gradient vanish, 只能设置较小的 learning rate, 而, 较小的 learning rate 使得整个学习过程很慢
- 第 N 层的输入受前面 N-1 层的影响, 在深度学习中, 网络层数很多, 因此, 及时前面 layer 的很小的影响, 当到达第 N 层的时候, 会被放大很多倍.
在深度神经网络中, 每一层输入数据的分布都不同, 因此, 每一层的参数都要去学习不同的分布. 而主要由于上述 #3 的原因, 使得这个过程比较困难. 为了说明这个问题, 使用一个简单的例子. 考虑如下的一个两层的神经网络:
F1F1 的输出作为 F2F2 的输入, 因此, 在学习的过程中, 当 F1F1 的输入 xx 的分布变化的时候 (在选择 minibatch 的使用根本无法保证每次选择的 minibatch 的分布是相同的), F2F2 的参数在向最优解收敛的过程中就会产生偏差, 因此, 导致了收敛速度变慢. 而 BN 就是要解决这个问题.
想象一下, 如果 F2F2 的学习不受 F1F1 的输入 xx 的影响, 即不管 xx 输入的是什么, F2F2 的输入都是相同的分布, 这样, F2F2 就不用调整去适应由于 xx 输入变化带来的影响, 那么, 是否就可以解决这个问题了呢? 因此, 这就是 BN 的提出.
Batch Normalization 是什么
Input: Values of xx over a mini-batch, B=x1…mB=x1…m
Output: γ,βγ,β
为什么 Batch Normalization 可以加速训练
- 允许网络使用较高的 learning rate. 在传统的深度网络训练中, 如果使用较大的 learning rate 很容易导致 gradient vanish 或者 gradient explode. 通过在整个网络中 normalize activations, 可以防止参数的较小的改变被应用到较大的或者次优的 activation 中. 另一方面, BN 使得网络对于 parameter 的 scale 更加鲁棒. 通常情况下, large learning rate 会 increase the scale of layer parameters, 进而会放大 BP 的梯度, 导致了 model explosion. BN 的使用使得网络在 BP 的时候不会受到 parameter scale 的影响. 这是因为:
BN(Wu)=BN((aW)u)∂BN((aW)u)∂u=∂Wu∂u∂BN((aW)u)∂aW=1a⋅∂Wu∂W(5)(6)(7)(8)(9)(5)BN(Wu)=BN((aW)u)(6)(7)∂BN((aW)u)∂u=∂Wu∂u(8)(9)∂BN((aW)u)∂aW=1a⋅∂Wu∂W
- 具有一定的 regularization 作用, 可以减少 Dropout 的使用. dropout 的作用是方法 overfitting, 实验发现, BN 可以 reduce overfitting.
- 降低 L2L2 权重衰减系数.
- 取消 LRN(Local Response Normalization).
- Reduce the photomatric distortions. 因为 BN 使得训练过程更快, 能 observe 到的 sample 次数变少, 所以, 减少 distorting 使得网络 focus 在真实的图片上面.
- BN 不仅仅限定在 ReLU 上, 而且, 对其它的 activation 也同样适用.
基础 | batchnorm原理及代码详解的更多相关文章
- DeepLearning tutorial(3)MLP多层感知机原理简介+代码详解
本文介绍多层感知机算法,特别是详细解读其代码实现,基于python theano,代码来自:Multilayer Perceptron,如果你想详细了解多层感知机算法,可以参考:UFLDL教程,或者参 ...
- 非极大值抑制(NMS,Non-Maximum Suppression)的原理与代码详解
1.NMS的原理 NMS(Non-Maximum Suppression)算法本质是搜索局部极大值,抑制非极大值元素.NMS就是需要根据score矩阵和region的坐标信息,从中找到置信度比较高的b ...
- Spring之IOC原理及代码详解
一.什么是IOC 引用 Spring 官方原文:This chapter covers the Spring Framework implementation of the Inversion of ...
- [ZigBee] 5、ZigBee基础实验——图文与代码详解定时器1(16位定时器)(长文)
1.定时器1概述 定时器1 是一个支持典型的定时/计数功能的独立16 位定时器,支持输入捕获,输出比较和PWM等功能.定时器有五个独立的捕获/比较通道.每个通道定时器要使用一个I/O 引脚.定时器用于 ...
- Go语言备忘录:反射的原理与使用详解
目录: 预备知识 reflect.Typeof.reflect.ValueOf Value.Type 动态调用 通过反射可以修改原对象 实现类似“泛型”的功能 1.预备知识: Go的变量都是静态类 ...
- Java中String的intern方法,javap&cfr.jar反编译,javap反编译后二进制指令代码详解,Java8常量池的位置
一个例子 public class TestString{ public static void main(String[] args){ String a = "a"; Stri ...
- Spring学习 6- Spring MVC (Spring MVC原理及配置详解)
百度的面试官问:Web容器,Servlet容器,SpringMVC容器的区别: 我还写了个文章,说明web容器与servlet容器的联系,参考:servlet单实例多线程模式 这个文章有web容器与s ...
- Go语言备忘录(2):反射的原理与使用详解
本文内容是本人对Go语言的反射原理与使用的备忘录,记录了关键的相关知识点,以供翻查. 文中如有错误的地方请大家指出,以免误导!转摘本文也请注明出处:Go语言备忘录(2):反射的原理与使用详解,多谢! ...
- 开胃小菜——impress.js代码详解
README 友情提醒,下面有大量代码,由于网页上代码显示都是同一个颜色,所以推荐大家复制到自己的代码编辑器中看. 今天闲来无事,研究了一番impress.js的源码.由于之前研究过jQuery,看i ...
随机推荐
- [nginx]盗链和防盗链场景模拟实现
盗链环境模拟 http://www.daolian.com/index.html 这个页面盗用http://www.maotai.com/qq.jpg这个站点页面的图. <!doctype ht ...
- hibernate中的saveOrUpdate()报错
最近使用hibernate保存数据的时候,没有使用id自增主键,而是使用了一种调用seq以后手动赋值的方式生成主键,然后使用saveorupdate()报错.上网查看终于知道了问题所在,记录一下: 在 ...
- redis 指定IP访问
配置IPTABLES -A INPUT -s 10.100.0.5 -p tcp --dport 6379 -j ACCEPT -A INPUT -s 10.100.0.219 -p tcp --dp ...
- Pycharm 2017.1 激活服务器
最近发现pycharm激活异常困难 原来的激活码 都不能用了 so 根据网上 教程 自己建了激活服务器 尝试可用服务器 20170504 测试发现 给需要域名 http://www.05nb.com: ...
- 手动分析linux是否中毒的几个考虑点
linux服务器在不允许安装任何杀毒软件的时候,手动分析有没有中病毒可以从以下几个特征点来考虑. 特征一:查看系统里会产生多余的不明的用户cat /etc/passwd 特征二:查看开机是否启动一些不 ...
- Spark-shell引入第三方包
Spark-shell引入第三方包 如何引入 spark-shell --jars path/nscala-time_2.10-2.12.0.jar 若有多个jar包需要导入,中间用逗号隔开即可. s ...
- SQL Server 2008 R2升级到SQL Server 2012 SP1
1.建议对生产环境对的数据库升级之前做好备份,以防不测. 2.从SQL Server 2008 R2 升级到SQL Server 2012 SP1,需要先安装SQL Server 2008 R2 的S ...
- JSP怎么将表单提交到对应的servlet
昨天学习了这些内容,今天做一下分享吧,个人感觉挺乱的....呵呵,其实没事,慢慢就好了.难的不会,会的不难嘛!努力+认真就可以了,相信大家都可以的!加油!!! 下面的图是我用myeclipse建立的项 ...
- Mysql 替换字段的一部分内容
UPDATE 表名 SET 字段名= REPLACE( 替换前的字段值, '替换前关键字', '替换后关键字' ) WHERE 字段名 REGEXP "替换前的字段值"; 例子: ...
- Cacti的库表结构-Data
cacti 的数据都是存放在rrdtool 中的,数据库存放的其实只是配置数据,cacti 的逻辑对象主要分为三种,data (数据).graph (图片).host (设备),这在它的表设计中也能很 ...