第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
elasticsearch(搜索引擎)基本的索引和文档CRUD操作
也就是基本的索引和文档、增、删、改、查、操作
注意:以下操作都是在kibana里操作的
elasticsearch(搜索引擎)都是基于http方法来操作的
GET 请求指定的页面信息,并且返回实体主体
POST 向指定资源提交数据进行处理请求,数据被包含在请求体中,POST请求可能会导致新的资源的建立和/或已有资源的修改
PUT 向服务器传送的数据取代指定的文档的内容
DELETE 请求服务器删除指定的页面
1、索引初始化,相当于创建一个数据库
用kibana创建
代码说明
# 初始化索引(也就是创建数据库)
# PUT 索引名称
"""
PUT jobbole #设置索引名称
{
"settings": { #设置
"index": { #索引
"number_of_shards":5, #设置分片数
"number_of_replicas":1 #设置副本数
}
}
}
"""
代码
# 初始化索引(也就是创建数据库)
# PUT 索引名称 PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
}
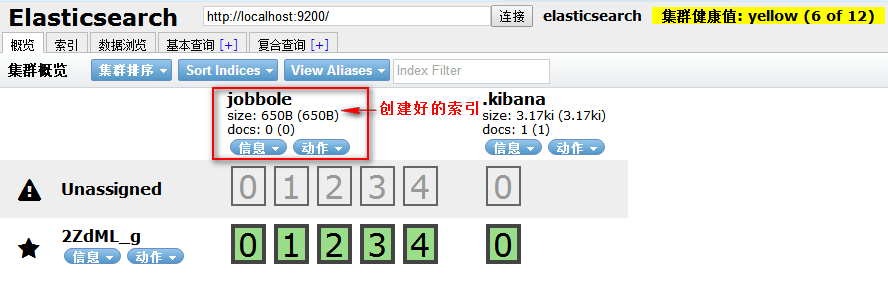
我们也可以使用可视化根据创建索引
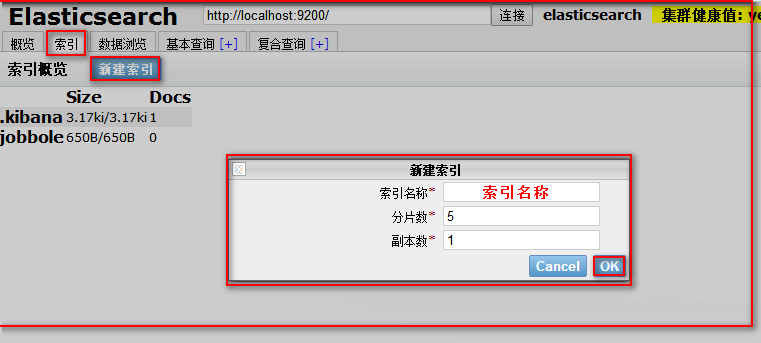
注意:索引一旦创建,分片数量不可修改,副本数量可以修改的
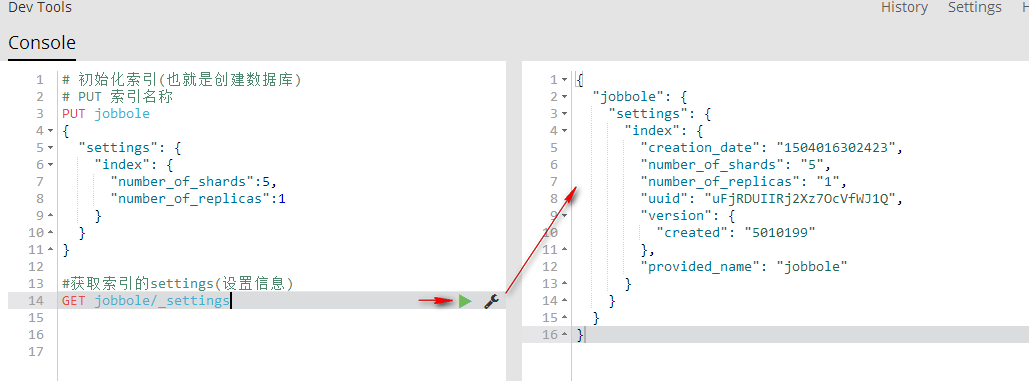
2、获取索引的settings(设置信息)
GET 索引名称/_settings 获取指定索引的settings(设置信息)
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取指定索引的settings(设置信息)
GET jobbole/_settings
GET _all/_settings 获取所有索引的settings(设置信息)
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取索引的settings(设置信息)
#GET jobbole/_settings #获取所有索引的settings(设置信息)
GET _all/_settings
GET .索引名称,索引名称/_settings 获取多个索引的settings(设置信息)
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取索引的settings(设置信息)
#GET jobbole/_settings #获取所有索引的settings(设置信息)
#GET _all/_settings
GET .kibana,jobbole/_settings
3、更新索引的settings(设置信息)
PUT 索引名称/_settings 更新指定索引的设置信息
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
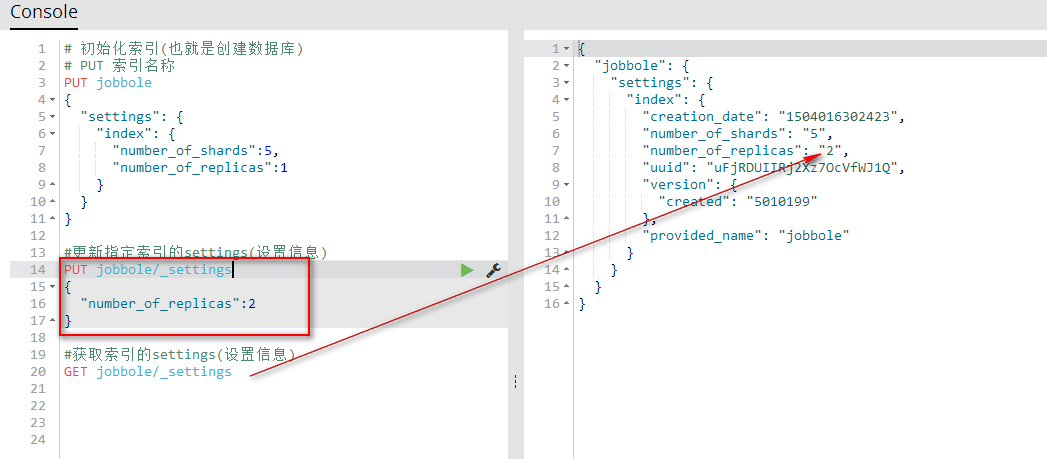
} #更新指定索引的settings(设置信息)
PUT jobbole/_settings
{
"number_of_replicas":2
} #获取索引的settings(设置信息)
GET jobbole/_settings
4、获取索引的(索引信息)
GET _all 获取所有索引的索引信息
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取索引的settings(设置信息)
#GET jobbole/_settings GET _all
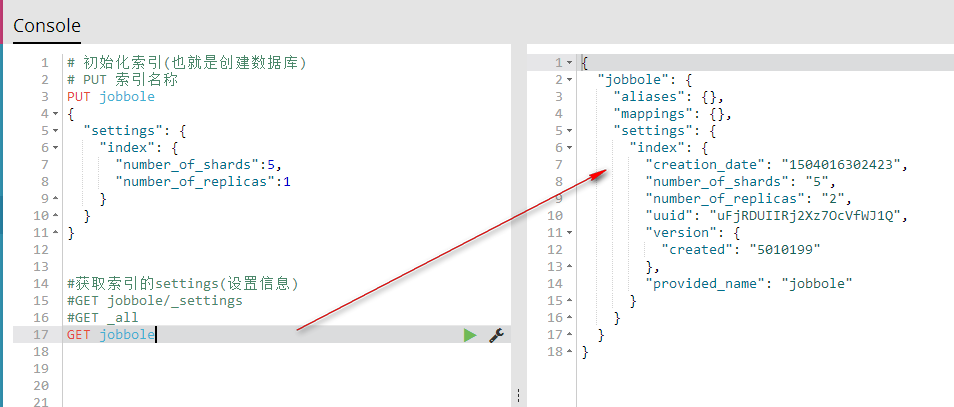
GET 索引名称 获取指定的索引信息
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取索引的settings(设置信息)
#GET jobbole/_settings
#GET _all
GET jobbole
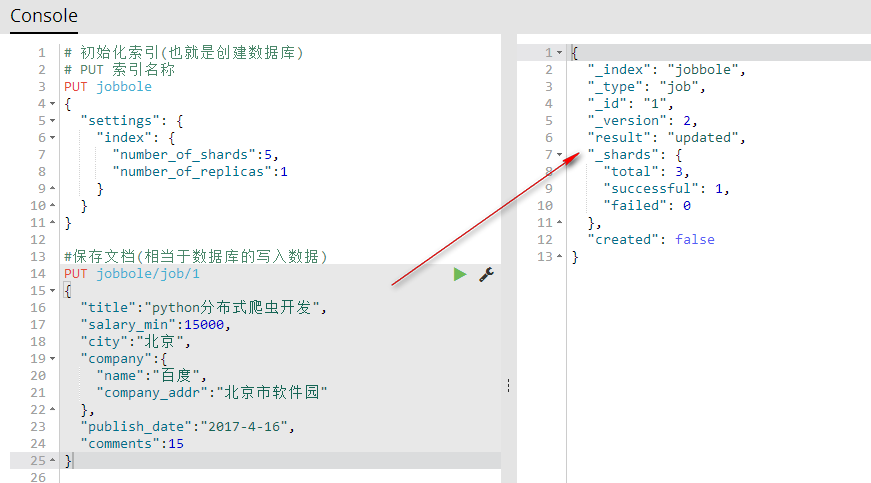
5、保存文档(相当于数据库的写入数据)
PUT index(索引名称)/type(相当于表名称)/1(相当于id){字段:值} 保存文档自定义id(相当于数据库的写入数据)
#保存文档(相当于数据库的写入数据)
PUT jobbole/job/1
{
"title":"python分布式爬虫开发",
"salary_min":15000,
"city":"北京",
"company":{
"name":"百度",
"company_addr":"北京市软件园"
},
"publish_date":"2017-4-16",
"comments":15
}
可视化查看

POST index(索引名称)/type(相当于表名称)/{字段:值} 保存文档自动生成id(相当于数据库的写入数据)
注意:自动生成id需要用POST方法
#保存文档(相当于数据库的写入数据)
POST jobbole/job
{
"title":"html开发",
"salary_min":15000,
"city":"上海",
"company":{
"name":"微软",
"company_addr":"上海市软件园"
},
"publish_date":"2017-4-16",
"comments":15
}

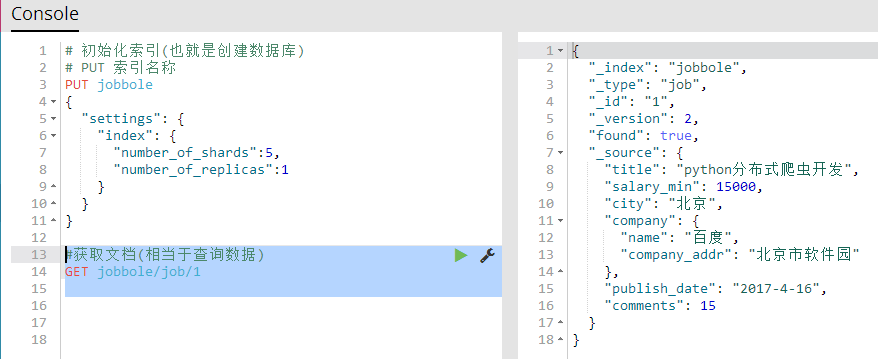
6、获取文档(相当于查询数据)
GET 索引名称/表名称/id 获取指定的文档所有信息
#获取文档(相当于查询数据)
GET jobbole/job/1
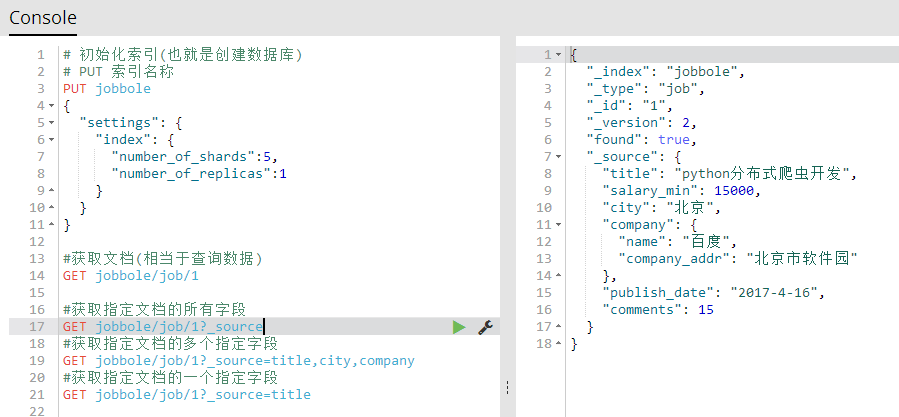
GET 索引名称/表名称/id?_source 获取指定文档的所有字段
GET 索引名称/表名称/id?_source=字段名称,字段名称,字段名称 获取指定文档的多个指定字段
GET 索引名称/表名称/id?_source=字段名称 获取指定文档的一个指定字段
#获取指定文档的所有字段
GET jobbole/job/1?_source
#获取指定文档的多个指定字段
GET jobbole/job/1?_source=title,city,company
#获取指定文档的一个指定字段
GET jobbole/job/1?_source=title
7、修改文档(相当于修改数据)
修改文档(用保存文档的方式,进行覆盖来修改文档)原有数据全部被覆盖
#修改文档(用保存文档的方式,进行覆盖来修改文档)
PUT jobbole/job/1
{
"title":"python分布式爬虫开发",
"salary_min":15000,
"city":"北京",
"company":{
"name":"百度",
"company_addr":"北京市软件园"
},
"publish_date":"2017-4-16",
"comments":20
}
修改文档(增量修改,没修改的原数据不变)【推荐】
POST 索引名称/表/id/_update
{
"doc": {
"字段":值,
"字段":值
}
}
#修改文档(增量修改,没修改的原数据不变)
POST jobbole/job/1/_update
{
"doc": {
"comments":20,
"city":"天津"
}
}
8、删除索引,删除文档
DELETE 索引名称/表/id 删除索引里的一个指定文档
DELETE 索引名称 删除一个指定索引
#删除索引里的一个指定文档
DELETE jobbole/job/1
#删除一个指定索引
DELETE jobbole
第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查的更多相关文章
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引
第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引 倒排索引 倒排索引源于实际应用中需要根据属性的值来查找记录.这种索引表中的每一项都包 ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
- 第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
随机推荐
- angular.js测试框架protracotr自带的webdriver-manager启动问题“Invalid or corrupt jarfile”
按照官网安装完protractor. 升级webdriver-manager,获取selenium-server-standalone库文件以及各种浏览器驱动文件. webdriver-manager ...
- [DIOCP3/MyBean/QDAC开源项目] DataModule-DB例子基于MyBean的插件实例<三层数据库方案>
[说明] 这个例子答应大家很久了,一直没有时间弄,现在正式结合MyBean插件可以很方便的在客户端共享操作连接,执行数据库的各项工作,屏蔽了底层的通信解码器编码等工作,直接传递Variant,给了开发 ...
- Asp.Net上传大文件带进度条swfupload
Asp.Net基于swfupload上传大文件带进度条百分比显示,漂亮大气上档次,大文件无压力,先看效果 一.上传效果图 1.上传前界面:图片不喜欢可以自己换 2.上传中界面:百分比显示 3.上传后返 ...
- 06-老马jQuery教程-jQuery高级
1.jQuery原型对象解密 jQuery里面的大部分API都是在jQuery的原型对象上定义的.jQuery源码中对原型对象做了简写的处理.也就是说:jQuery.fn === jQuery.pro ...
- C#正则表达式提取HTML中IMG标签的SRC地址
一般来说一个 HTML 文档有很多标签,比如“<html>”.“<body>”.“<table>”等,想把文档中的 img 标签提取出来并不是一件容易的事.由于 i ...
- 遍历目录下的所有文件-os.walk
#coding:utf-8 import os for root,dirs,files in os.walk("D:"): for fileItem in files: print ...
- 【转】如何使用visual studio将你的程序打包成安装包
原文地址:https://www.cnblogs.com/SolarWings/p/6132310.html 很久很久以前,我一直有一个梦想,那就是做出一个自己的游戏,这个游戏很像模像样,除了拥有一个 ...
- Thinkphp动态切换主题
'DEFAULT_THEME' => '2014', 'TMPL_DETECT_THEME' => true, // 自动侦测模板主题 'THEME_LIST' => '2012,2 ...
- html页面布局总结篇
1. 使用float布局 注意点:使用浮动布局要注意清除浮动.使用伪类清除 浮动层:给元素的float属性赋值后,就是脱离文档流,进行左右浮动,紧贴着父元素(默认为body文本区域)的左右边框. 而此 ...
- Winform鼠标滑轮控制自定义滚动条
场景:类似QQ聊天的窗体中,需要添加自定义滚动条vScroll.主窗体中panel存放空间,右边有垂直的滚动条vScroll. 问题:已经实现vScroll和Panel.VerticalScroll滚 ...