solr入门之权重排序方法初探之使用edismax改变权重
做搜索引擎避免不了排序问题,当排序没有要求时,solr有自己的排序打分机制及sorce字段
1.无特殊排序要求时,根据查询相关度来进行排序(solr自身规则)
2.当涉及到一个字段来进行相关度排序时,可以直接使用solr的sort功能来实现
3.对多个字段进行维度的综合打分排序(这个应该才是重点,内容)
使用Solr搭建搜索引擎很容易,但是如何制定合理的打分规则(boost)做排序却是一个很头痛的事情。Solr本身的排序打分规则是继承自 Lucene的文本相关度的打分即boost,这一套算法对于通用的提供全文检索的服务来讲,已经够用了,但是对于一些专门领域的搜索来讲,文本相关度的 打分是不合适的。
如何来定制适合自身业务的排序打分规则(boost)呢?经过这段时间的思考与实践,想到了如下三个方法
- 1、定制Lucene的boost算法,加入自己希望的业务规则;
- 2、使用Solr的edismax实现的方法,通过bf查询配置来影响boost打分。
- 3、在建索引的schema时设置一个字段做排序字段,通过它来影响文档的总体boost打分。
上面每一种方法都有其优劣,下面分析一下各自的优劣。
- 第一种方法技术难度要求较高,需要读懂Lucene的boost打分算法,在代码层做定制.
- 第二种方式就简单不少,不过因为受限于edismax提供的方法,所以有些局限性。
- 第三种排序可完全消除文本相关性打分的影响,文本检索匹配逻辑只负责打到匹配的项,排序由自定义字段处理。
上面是从网上收集的资料,可能还有别的解决办法,这里就不再说了.相对而言,我们付出成本最低的解决办法就是使用solr自身提供的权重计算方法 :
dismax和edismax来进行重新的权重计算排序.下面我们重点收集相关信息和对其进行真正的项目实践!
下面讲下dismax的主要参数qf,因为其他的参数没有去分析。不能乱讲。
qf 例如:qf=fieldOne^2.3 fieldTwo fieldThree^0.4, qf 参数时指定solr从哪些field中搜索。像下面的话就只会在fieldOne,fieldTwo fieldThree这三个field中搜索。如果你还指定了q参数,比如q=“hadoop”,那么solr会认为是到 fieldOne,fieldTwo, fieldThree这三个field中搜索hadoop,这三个是并集的关系。生成的query为:fieldOne:hadoop^2.3 | fieldTwo:hadoop | fieldThree:hadoop^0.4 所以你定义了dismax的话,你的查询参数q就不要写成类似q=“title:hadoop”这样了。因为这样的话最终的查询 为:fieldOne:title:hadoop^2.3 | fieldTwo:title:hadoop | fieldThree:title:hadoop^0.4 除非你的这几个field里有“title:hadoop”这样的词存在,否则是查不到结果的。
http://blog.csdn.net/qing419925094/article/details/40924465
Solr 支持多种查询解析,给搜索引擎开发人员提供灵活的查询解析。Solr 中主要包含这几个查询解析器:标准查询解析器、DisMax 查询解析器,扩展 DisMax 查询解析器(eDisMax)
Dismax
Dismax handler比standard handler多如下功能:
- 以不同的权值来搜索多个field。
- 限制查询语法为一个小的集合并且用无语法错误。该特性是强制的并是不可配置的
- 整个搜索查询的自动的短语boosting
- 便利的查询boosting参数,通常同函数查询一块使用
- 能指定单词匹配的最少个数,这取决于查询串中的单词数.
Dismax query parser
这里提到的所有应用于dismax的也都适用于edismax,除非明确说明不适用。其实edismax就是打算在未来的发布版本中替代dismax的。
Lucene DisjunctionMaxQuery
dismax可以查询多个field,并且每个field使用不同的boost。这个功能是由lucene的DisjunctionMaxQuery查询 类型来支持。以下的讨论都是高级内容,不用刻意理解。只是记住dismax针对多个字段的查询会设置tie参数为0.1,这也是合理的选择。
举个例子。如果有一个简单查询rock。dismax可能会将它配置为DisjunctionMaxQuery为fieldA:rock2 fieldB:rock1.2 fieldC:rock0.5, 如果是boolean查询的话会跟这个查询有些不同,不同的地方也就是得分。类似的boolean查询的得分会基于这三个条文的总和,也就是 DisjunctionMaxQuery会使用每一个的最大值。针对多个字段查询同一个term的情况,并且有些字段相对于另一些字段更重要,那么 dismax应该更好的处理得分。API文档中的一个例子对这个特征的解释是,如果用户查询albino elephant,那么假如有一种情况是albino匹配一个字段,elephant匹配另一个字段,另一种情况是albino匹配两个字段,但是 elephant没有一个匹配,那么dismax保证第一种情况的得分高于第二种情况。 另一个dismax得分的难题就是tie参数,tie的取值是0-1,默认是0,在实践中设置为0.1效果最好。
Boosting:Automatic phrase boosting
dismax会把phrase查询也就是引号引起来的查询进行转换,来改进得分。例如查询billy joel 会转换为+(billy joel) "billy joel"也就是说,如果一个文档包含billy joel,那么它不仅匹配原始term而且还匹配billy和joel,也就是匹配三个term,如果另一个文档不匹配短语billy joel,只是含有两个单词,那么lucene的得分算法会给第一个文档更高的得分。
Configuring automatic phrase boosting
automatic phrase boosting默认是不启用的。要使用的话可以使用pf参数,就是phrase fields的缩写。语法与qf相同。用相同的值作为开始并做相应的调整,从qf到pf变化通常的原因有以下几点:
- 使用不同的boost因素让短语增强的影响没有压倒性。一些经验可以来引导你做这些调整。
- 忽略那些只有一个term的字段。比如唯一标识字段。
- 忽略那些含有太大的文本值的字段,因为它可能全使查询效率大大降低。
- 使用一个具体相同值,但是使用不同analyzed的字段来替换这个字段
同样的强烈推荐使用common-grams和shingling来提高执行效率。
Phrase slop configuration
phrase slop就是短语后跟一个波浪线和一个数字,就像这样"billy joel"~1 对于所有明确指定的短语查询dismax会自动添加两个参数来设置slop:qs和phrase boosting:ps,如果slop没有指定那么就相当于是0。 10
Partial phrase boosting
如果查询的是两个单词,那么edismax支持增强为连续的单词对,如果是三个单词,那么可以增强三倍。例如查询how now brown cow 会变为: +(how now brown cow) "how now brown cow" "how now" "now brown" "brown cow" "how now brown" "now brown cow" 这个特征不会被ps参数影响,ps只应用于entire phrase boost。
Boosting:boost queries
dismax的bq参数可以用来指定多个查询,类似于automatic phrase boost。以类似的方式被添加到用户的查询中。记住一点,boosting只是用来影响q参数指定的用户查询所匹配到的那些文档的scoring。如果 匹配的结果还匹配bq查询,那么这个文档的得分会更高。 (: -r_type:aaa)2增强所有文档得分,但是除了aaa。 boost queries不如boost functions有用。
Boosting:boost functions
boost functions提供一个强大的功能就是使用用户设置的公式来对文档的score进行计算。这里所说的公式也就是solr的function queries,使用bf参数来操作score。edismax支持boost参数来进行function query。可以使用bf或boost多次。
<str name="boost">recip(map(rord(r_event_date),0,0,99000),1,95000,95000)</str>
函数中不能有空格。bf和boost两个参数其实并没有以相同的方式解析。bf参数允许多种boost functions使用相同的参数,以空格分开,二者选一的话还是使用bf参数。还可以在bf参数中乘以因子在函数的结尾。比如100
Demo
搜索功能中比较复杂的是文档的打分排序,solr中的打分规则继承了lucene中的相关的打分规则,这里通过solr的dismax查询解析器来支持复杂的打分
在打分的时候,会考虑以下因素,
搜索关键字匹配某些字段的打分比其他的字段要高(qf^)
对于某些字段,搜索字符串的密集度(phrase)的打分中占的比重(pf^)
其他复杂规则计算,比如销售量、价格、卖家等级等等都可以作为考虑的因素,影响打分(bf)
http://10.1.1.58:8080/solr/select?defType=dismax&qf=name^100 subject ^1 &q=sony mp3&pf=name^100 subjec ^1&q.op=OR&bf=sum(recip(ms(NOW,last_modified),3.16e-11,1,1),div(1000,price))^100
这个查询的含义是,在name和subject中搜索关键字sony mp3,name和subject在字段查询中的比重分别为100、1(qf=name^100subject ^1);并且这两个字段phrase的打分为
pf=name^100 subject ^1,也就是name占的比重大一些;其他还参考产品的价格和商品更新时间(bf=sum(recip(ms(NOW,last_modified),3.16e-11,1,1),div(1000,price))^100)
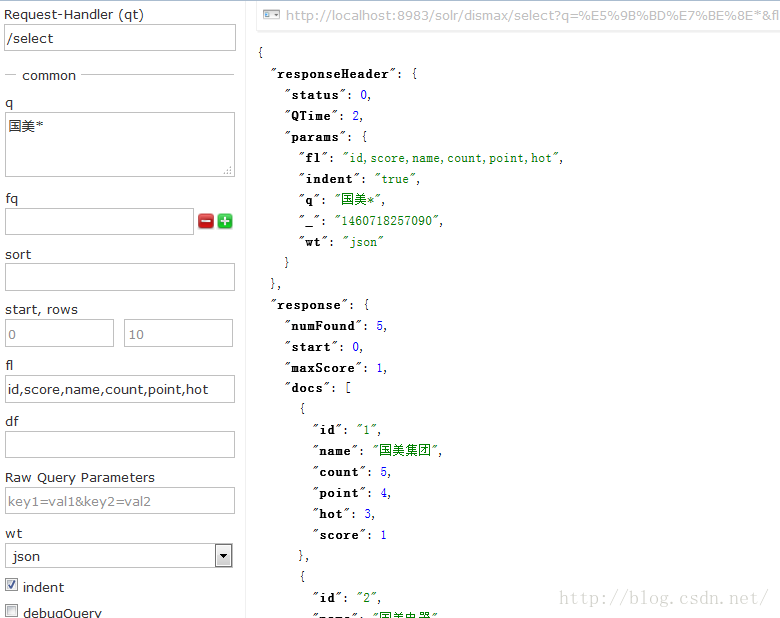
按照sort条件排序
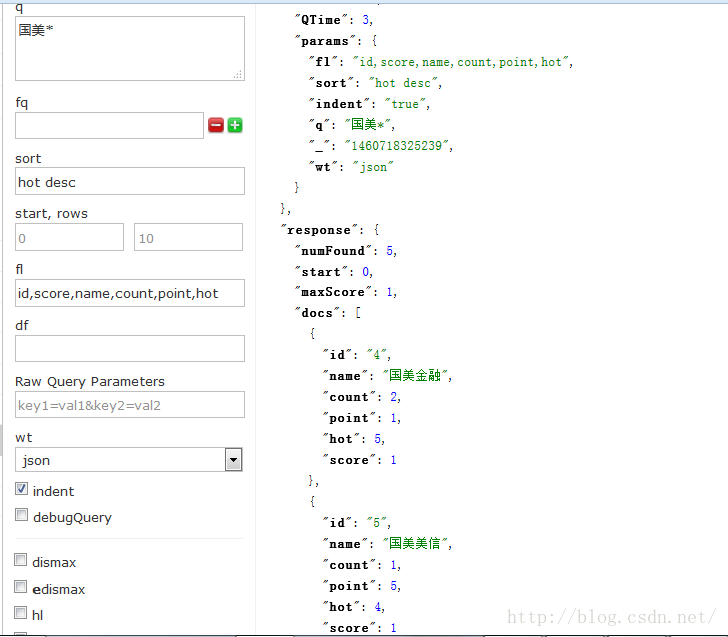
第三:按照eidsmax设置的的公式计算出来的score结果来进行排序
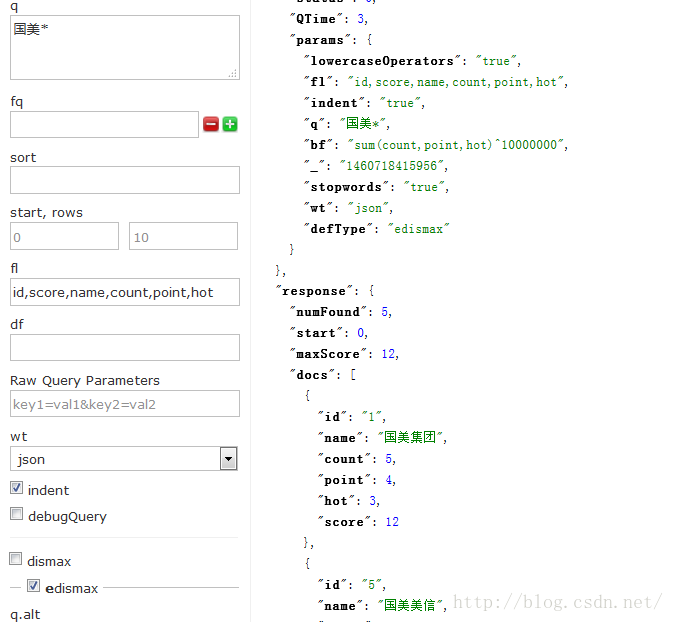

搜索关键字匹配某些字段的打分比其他的字段要高(qf^)
对于某些字段,搜索字符串的密集度(phrase)的打分中占的比重(pf^)
bf部分是用来解决比较复杂的权重问题了,其中需要用到solr的查询函数
solr入门之权重排序方法初探之使用edismax改变权重的更多相关文章
- dede:list及dede:arclist 按权重排序的方法
有时我们需要做文章排名,比如指定第一名到第三名在前面,这样就用到这个权重排序方法.稍改下就可以完美支持.. dede:list 的方法 1 找到"根目录\include\arc.listvi ...
- dedecms 按权重排序不准或BUG的处理方法
dede:list 的方法 1.找到"根目录\include\arc.listview.class.php"文件. 2.修改代码:在文件第727行处添加按weight排序判断代码( ...
- 深入理解苹果系统(Unicode)字符串的排序方法
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由iminder发表于云+社区专栏 Unicode编码 我们知道计算机是不能直接处理文本的,而是和数字打交道.因此,为了表示文本,就建立 ...
- Spring入门(9)-AOP初探
Spring入门(9)-AOP初探 0. 目录 什么是面向切面编程 AOP常见术语 AOP实例 参考资料 1. 什么是面向切面编程 Aspect Oriented Programming(AOP),即 ...
- DEDECMS5.7 首页和栏目页调用文章按权重排序
dedecms 5.7版本已增加按权重排序功能: [arclist]标签增加按权重排序,在后台管理DEDE里找到以下目录\include\taglib中的arclist.lib.php文件并打开 大约 ...
- Solr入门之SolrServer实例化方式
随着solr版本的不断升级, 差异越来越大, 从以前的 solr1.2 到现在的 solr4.3, 无论是类还是功能都有很大的变换, 为了能及时跟上新版本的步伐, 在此将新版本的使用做一个简单的入门说 ...
- Java几种常见的排序方法
日常操作中常见的排序方法有:冒泡排序.快速排序.选择排序.插入排序.希尔排序,甚至还有基数排序.鸡尾酒排序.桶排序.鸽巢排序.归并排序等. 冒泡排序是一种简单的排序算法.它重复地走访过要排序的数列,一 ...
- Solr入门(一)
一丶Solr入门1.Solr的启动Solr各版本下载老版本的时候,需要将war包放到tomcat中,现在只需解压,由于自带jetty容器,可以直接启动 [root@aaa bin]# ./solr s ...
- dede按照权重排序dede:list和得的:arclist
dede:list 的方法 1.找到"根目录\include\arc.listview.class.php"文件. 2.修改代码:在文件第727行处添加按weight排序判断代码( ...
随机推荐
- C语言基础:函数指针 分类: iOS学习 c语言基础 2015-06-10 21:55 15人阅读 评论(0) 收藏
函数指针:指向函数的指针变量. 函数名相当于首地址. 函数指针定义:返回值类型 (*函数指针变量名)(参数类型1,参数类型2,....)=初始值 函数指针类型:返回值类型 (*)(参数类型1,参数 ...
- length()
在MATLAB中: size:获取数组的行数和列数 length:数组长度(即行数或列数中的较大值) numel:元素总数. s=size(A),当只有一个输出参数时,返回一个行向量,该行向量的第一个 ...
- opencv-learnopencv-Facial Landmark Detection
re: 1.facial-landmark-detection; https://www.learnopencv.com/facial-landmark-detection/ 2.landmark h ...
- No.01——配置编程环境
======由于很喜欢Android编程,所以买来了安卓权威指南来学习.为了应用费曼技巧——把知识输出出去以检验和巩固,在此写下学习笔记======= 1. 配置编程环境 Java的JDK(Java ...
- 转:如何解决VC "应用程序无法启动,因为应用程序的并行配置不正确 sxstrace.exe"问题
如何解决VC "应用程序无法启动,因为应用程序的并行配置不正确 sxstrace.exe"问题 引用链接 http://blog.csdn.net/pizi0475/artic ...
- git中的标签
/*游戏或者运动才能让我短暂的忘记心痛,现如今感觉学习比游戏和运动还重要——曾少锋*/ 1.创建标签: 对于标签来说大家都很熟悉,简单说就是将一个很长的门牌号用另外一个名字来取代,并且好记. 其实利 ...
- explain结果字段说明
Explain命令在解决数据库性能上是第一推荐使用命令,大部分的性能问题可以通过此命令来简单的解决,Explain可以用来查看SQL语句的执行效 果,可以帮助选择更好的索引和优化查询语句,写出更好的优 ...
- 设置tab标签页 遮挡部分
效果如下: 主要代码: <div class="need-detail"> <div class="top-title"> <sp ...
- stenciljs 学习十一 pwa 支持
stenciljs 对于pwa 的支持是自动注入的,我们只需要简单的配置,stenciljs使用workbox 配置 默认配置 { skipWaiting: true, clientsClaim: t ...
- 打开Visual Studio 2012的解决方案 连接 Dynamics CRM 2011 的Connect to Dynamics CRM Server 在其工具下没有显示
一.使用TFS 代码管理,发现Visual Studio 2012 菜单栏 工具下的Connect to Dynamics CRM Server 没有显示. 平常打开VS下的工具都会出现Connect ...