搭建GlusterFS文件系统
(1)环境准备
创建两个虚拟机配置如下
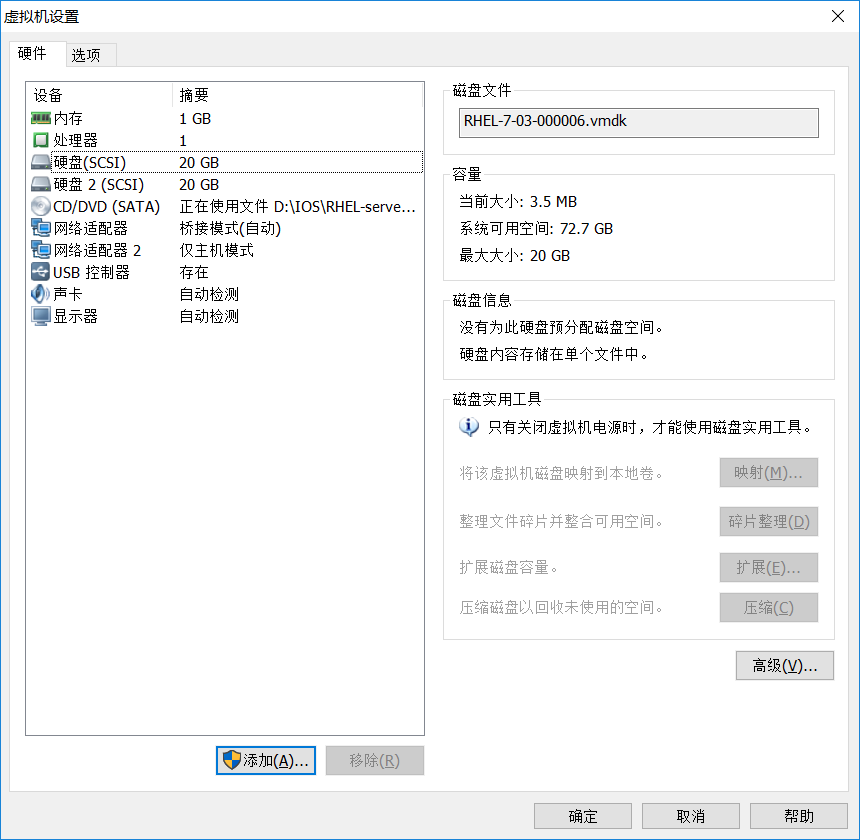
把仅主机第二张网卡配置如下:

GlusterFS1
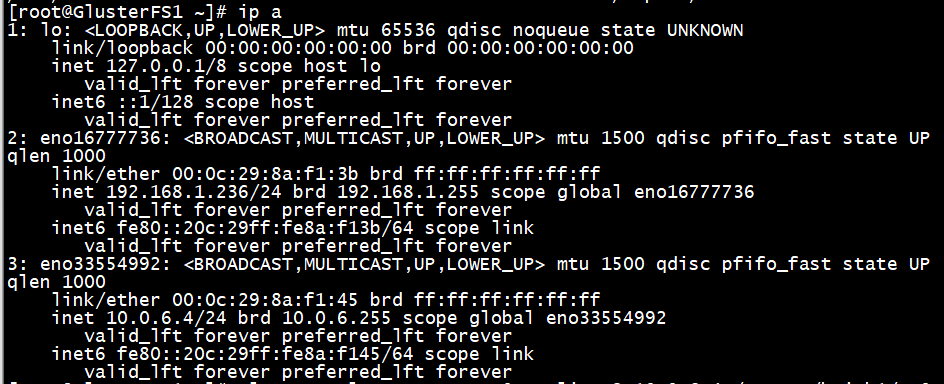
GlusterFS2
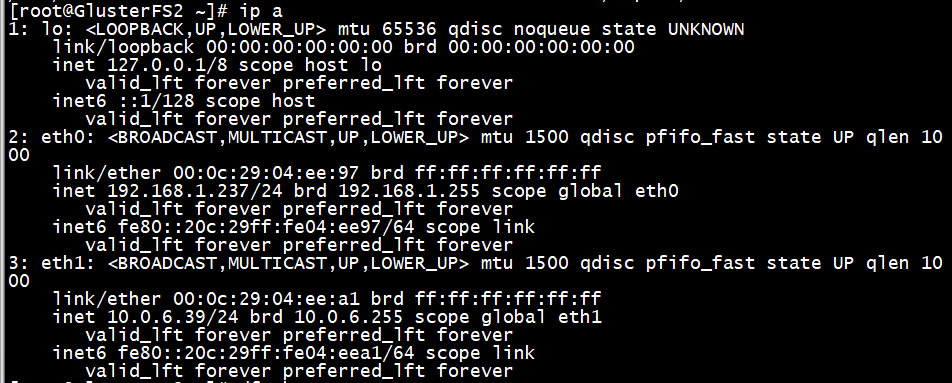
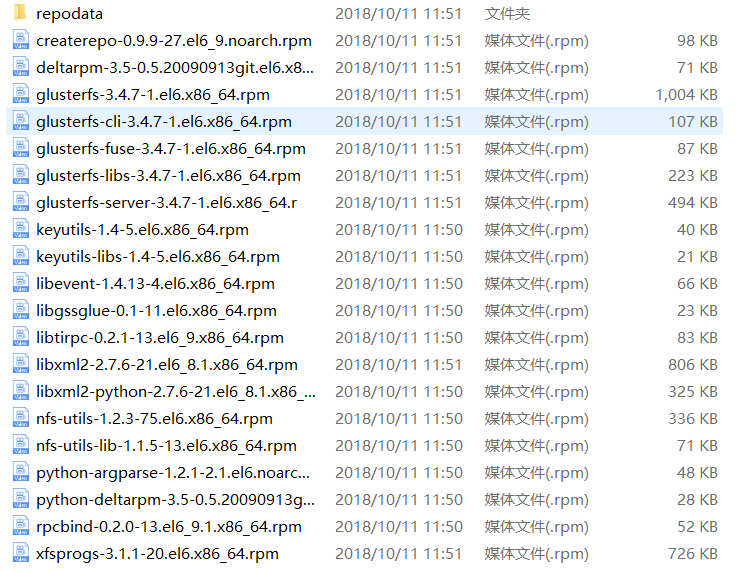
上传文件到opt目录下

文件内容如下
(2)GlusterFS安装配置
1、安装GlusterFS软件包。
配置YUM源
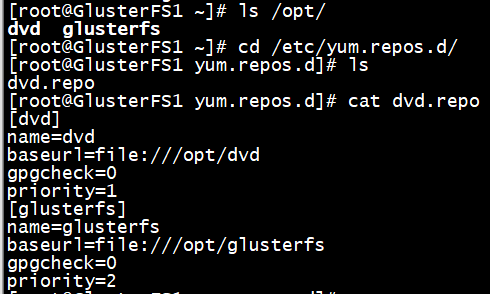
[dvd]
name=dvd
baseurl=file:///opt/dvd
gpgcheck=
priority=
[glusterfs]
name=glusterfs
baseurl=file:///opt/glusterfs
gpgcheck=
priority=
配置DNS服务。
# vi /etc/resolv.conf


在两个节点中安装GlusterFS需要的包。
# yum install -y glusterfs-server xfsprogs
安装完之后,启动服务并设置开机启动。

添加节点到GlusterFS集群。
[root@GlusterFS1 ~]# gluster peer probe 10.0.6.4
peer probe: success: on localhost not needed
[root@GlusterFS1 ~]# gluster peer probe 10.0.6.39
peer probe: success
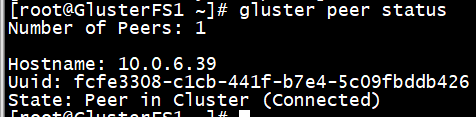
2、查询状态。
查看各个节点的状态。
# gluster peer status

3、创建目录。
创建数据存储目录(两个节点都要执行)。
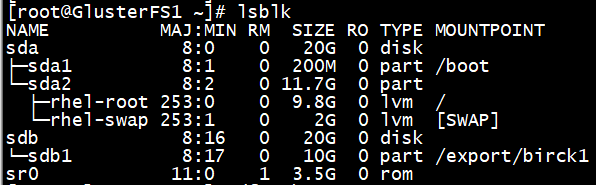
先使用fdisk分区工具将硬盘分出一个10 G的分区。然后使用lsblk命令查看。
# fdisk /dev/sdb
#lsblk

使用XFS文件系统对分区进行格式化。
# mkfs.xfs /dev/sdb1
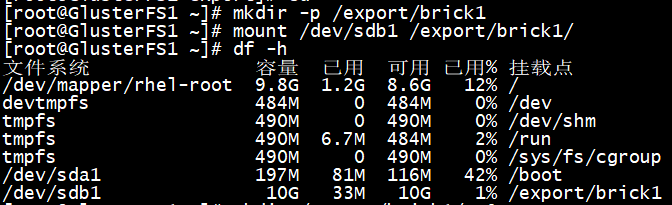
创建挂载目录并挂载查看
# mkdir -p /export/brick1
# mount /dev/sdb1 /export/brick1/
# df -h
创建存储目录。
# mkdir /export/brick1/gv0
GlusterFS 2节点重复上述的操作,分区、格式化、挂载、创建存储目录。
4、创建磁盘卷。
创建GlusterFS磁盘卷。
创建系统卷gv 0(副本卷)。
# gluster volume create gv0 replica 2 10.0.6.4:/export/brick1/gv0 10.0.6.39:/export/brick1/gv0

启动系统卷gv 0。
# gluster volume start gv0

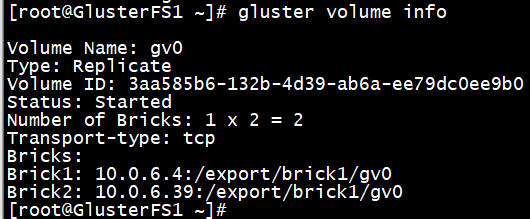
查看系统卷信息。
# gluster volume info
5、挂载文件系统。
安装客户端并挂载GlusterFS文件系统,使用GlusterFS 2节点作为客户端,在客户端挂载GlusterFS文件系统。
# mount -t glusterfs 10.0.6.4:/gv0 /mnt/
# df -h
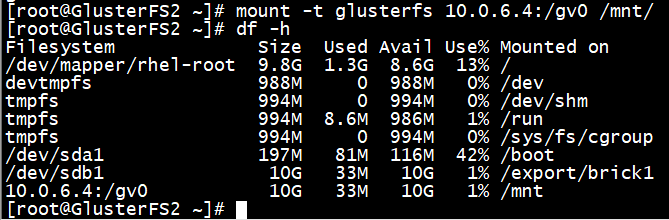
验证成功,副本卷gv 0的大小是10 G,因为GlusterFS的副本数为2,存储空间有一半冗余。
(3)运维操作
添加节点(将节点server ip添加到存储池中)。
# gluster peer probe server ip
删除节点。
# gluster peers detach server ip
注意:将节点server从存储池中移除,移除节点是要保证节点上没有Brick。如果节点上有Brick,需要提前移除Brick。
查看卷信息。
# gluster volume info
查看卷状态。
# gluster volume status
启动,停止卷。
# gluster volume start/stop VOLUME
删除卷。
# gluster volume delete VOLUME
修复卷。
# gluster volume heal mamm-volume #只修复有问题的文件
# gluster volume heal mamm-volume full #修复所有文件
# gluster volume heal mamm-volume info #查看自愈详情
(4)Brick管理
添加Brick。
# gluster peer probe 10.0.6.41
# gluster peer probe 10.0.6.42
# gluster volume add-brick gv0 10.0.6.41:/export/brick1/gv0 10.0.6.42:/export/brick1/gv0
注意:添加两个Brick到gv 0,副本卷则要一次添加的Bricks数是Replica的整数倍,Stripe同样要求。
移除Brick。
# gluster volume remove-brick gv0 10.0.6.41:/export/brick1/gv0 10.0.6.42:/export/brick1/gv0 start
注意:若是副本卷,则要移除的Brick是Replica的整数倍,Stripe具有同样的要求,副本卷要移除一对Brick,在执行移除操作时,数据会移到其他节点。
在执行移除操作后,可以使用status命令对task状态进行查看。
# gluster volume remove-brick gv0 10.0.6.41:/export/brick1/gv0 10.0.6.42:/export/brick1/gv0 status
使用commit命令执行Brick移除,则不会进行数据迁移而直接删除Brick,符合不需要数据迁移的用户需求。
# gluster volume remove-brick gv0 10.0.6.41:/export/brick1/gv010.0.6.42:/export/brick1/gv0 commit
搭建GlusterFS文件系统的更多相关文章
- centos7 搭建GlusterFS
centos7 搭建GlusterFS 转载http://zhaijunming5.blog.51cto.com/10668883/1704535 实验需求:4台机器安装GlusterFS组成一个集群 ...
- IPFS搭建分布式文件系统 - 访问控制
IPFS 一个内容可寻址.对等的超媒体分发协议. IPFS网络中的节点形成分布式文件系统. 为什么要用IPFS? “IPFS and the Blockchain are a perfect matc ...
- FastDFS搭建分布式文件系统
FastDFS搭建分布式文件系统 1. 什么是分布式文件系统 分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网 ...
- 实战:docker搭建FastDFS文件系统并集成SpringBoot
实战:docker搭建FastDFS文件系统并集成SpringBoot 前言 15年的时候,那时候云存储还远远没有现在使用的这么广泛,归根结底就是成本和安全问题,记得那时候我待的公司是做建站开发的,前 ...
- Ubuntu 搭建 GlusterFS 过程笔记
https://download.gluster.org/pub/gluster/ #要安装的东西 ---- ``` apt install -y build-essential gcc make c ...
- 【云计算】Ubuntu14.04 搭建GlusterFS集群
1.修改 /etc/hosts 所有服务节点执行(如果集群中没有DNS,可忽略此步骤): 10.5.25.37 glusterfs-1-5-25-3710.5.25.38 glusterfs-2-5- ...
- 使用buildroot搭建linux文件系统【转】
本文转载自:http://blog.csdn.net/metalseed/article/details/45423061 (文件系统搭建,强烈建议直接用buildroot,官网上有使用教程非常详细b ...
- 使用docker搭建FastDFS文件系统
1.首先下载FastDFS文件系统的docker镜像 docker search fastdfs 2.使用docker镜像构建tracker容器(跟踪服务器,起到调度的作用): docker run ...
- CentOS7 GlusterFS文件系统部署
一.GlusterFS简介 GlusterFS(GNU ClusterFile System)是一种全对称的开源分布式文件系统,所谓全对称是指GlusterFS采用弹性哈希算法,没有中心节点,所有节点 ...
随机推荐
- 使用Arduino模块实施无线信号的重放攻击
无线电已经存在使用了很长一段时间,在这很长的一段时间里诞生了一个名叫火腿族的集体(小编:嗯 对 就是整天吃火腿的那些人^_^ CQ CQ ).无线电和互联网一样:同样存在一些安全隐患,比如:在无线信 ...
- 可远程定位、解锁并启动汽车的黑客设备OwnStar
GM告诉WIRED,OnStar用户不必担心之前存在的问题,现在已经修复了之前可被利用的漏洞,. 然而,Kamkar表示问题还是没有被解决,并且已经由GM汇报了该问题. 在任何已经连接的汽车上,GM的 ...
- Python 动态传参
def chi(zhushi, cai, fushi, tang, tiandian): print(zhushi,cai,fushi,tang,tiandian) chi("大碗大米饭&q ...
- 不使用ref
为什么 尽量避免ref? 使用ref原因:react功能来访问DOM元素,这种功能的需求往往来自于提交表单的操作,再提交表单的时候,需要读取当前表单中input元素的值 而react的产生就是为了避免 ...
- WEB接口测试之Jmeter接口测试自动化 (三)
接口测试与数据驱动 1简介 数据驱动测试,即是分离测试逻辑与测试数据,通过如excel表格的形式来保存测试数据,用测试脚本读取并执行测试的过程. 2 数据驱动与jmeter接口测试 我们已经简单介绍了 ...
- torch7 安装 并安装 hdf5模块 torch模块 nn模块 (系统平台为 ubuntu18.04 版本)
今年的CCF A会又要开始投稿了,实验室的师弟还在玩命的加实验,虽然我属于特殊情况是该从靠边站被老板扶正但是实验室的事情我也尽力的去帮助大家,所以师弟在做实验的时候遇到了问题也会来问问我,这次遇到的一 ...
- mac 搭建Vue开发环境
1: 使用的各个工具的版本为: Homebrew 1node.js npm webpack Vue 2: 安装brew 打开终端运行一下命令 /usr/bin/ruby -e "$(cur ...
- Mac OS 基于 VirtualEnv 的安装 tensorflow 1.3.0
如果不行的话,就用conda装吧 https://www.jianshu.com/p/d54546ab315e 推荐使用 virtualenv 创建一个隔离的容器, 来安装 TensorFlow. 这 ...
- HBulider打包
1. manifest配置 按照Manifest.json文档说明 manifest配置把工程中的manifest.json文件配置好,下面以我的项目为例进行配置. (1).应用信息 (2).图标配置 ...
- python3 获取当前调用函数名
import sys funcName = sys._getframe().f_back.f_code.co_name #获取调用函数名lineNumber = sys._getframe().f_b ...