【大数据系列】HDFS初识
一、HDFS介绍
HDFS为了做到可靠性(reliability)创建了多分数据块(data blocks)的复制(replicas),并将它们放置在服务集群的计算节点中(compute nodes),MapReduce就可以在他么所在的节点上处理这些数据了。
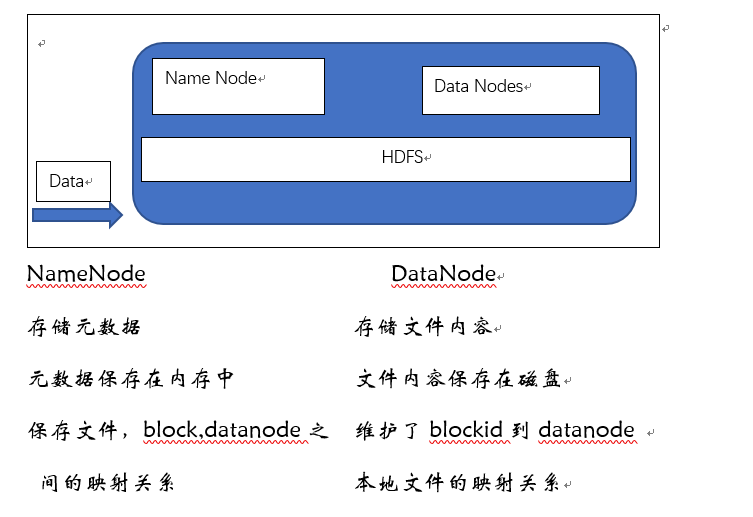
二、HDFS运行机制
一个名字节点和多个数据节点
数据复制(冗余机制)
存放的位置(机架感和策略)
故障检测
数据节点
心跳包(检测是否宕机)
块报告(安全模式下检测)
数据完整性检测(校验和比较)
名字节点(日志文件,镜像文件)
空间回收机制
shell命令
Ls lsr
Mkdir rm cp
Chmod chown
Cat mv put get tail
三、 HDFS优点:
高容错性:
数据自动保存多个副本,副本丢失后自动恢复
适合批处理:
移动计算而非数据,数据位置暴露给计算框架
适合大数据处理:
GB TB 甚至TB级数据,百万规模以上的文件数量,10K+节点
可构建在廉价机器上:
通过多副本提高可靠性,提供了容错和恢复机制
四、 HDFS缺点
低延迟数据访问:
比如毫秒级,低延迟与高吞吐率
小文件存取:
占用NameNode大量内存,寻道时间超过读取时间
并发写入、文件随机修改:
一个文件只能有一个写者。仅支持append.
五、 HDFS架构

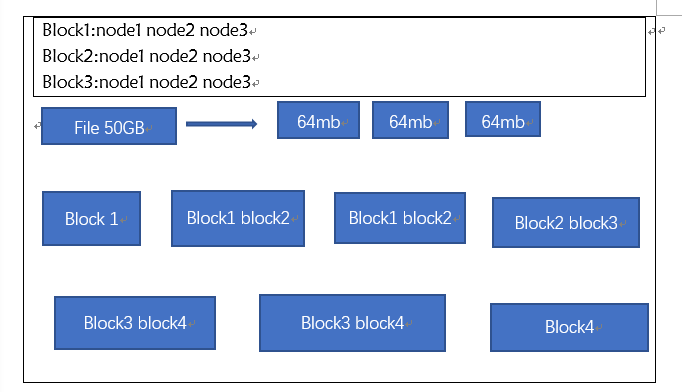
六、HDFS数据存储单元(block)
文件被切分成固定大小的数据块
默认数据块大小是64MB,可配置
若文件大小不到64MB,则单独存成一个block
一个文件存储方式
按大小被切分成若干个block,存储到不同节点上
默认情况下每个block都有个副本
Block大小和副本数通过Client端上传文件时设置,文件上传成功后副本数可以变更,Block Size不可变更
七、HDFS设计思想
NameNode(NN):
--NameNode主要功能:接受客户端的读写服务
--NameNode保存metadate信息包括
文件ownership和permissions
文件包含哪些块
Block保存在哪个DataNode(由DataNode启动时上报)
--NameNode的metadate信息在启动后会加载到内存
Metadata存储到磁盘文件名为fsimage
Block的位置信息不会保存到fsimage
Edit记录对metadata的操作日志
DataNode(DN):
--存储数据(Block)
--启动DN线程的时候会向NN汇报block信息
--通过向NN发送心跳保持与其一致(3秒一次),如果NN10分钟没有收到DN的心跳,则认为其已经lost,并copy其上的block到其他DN
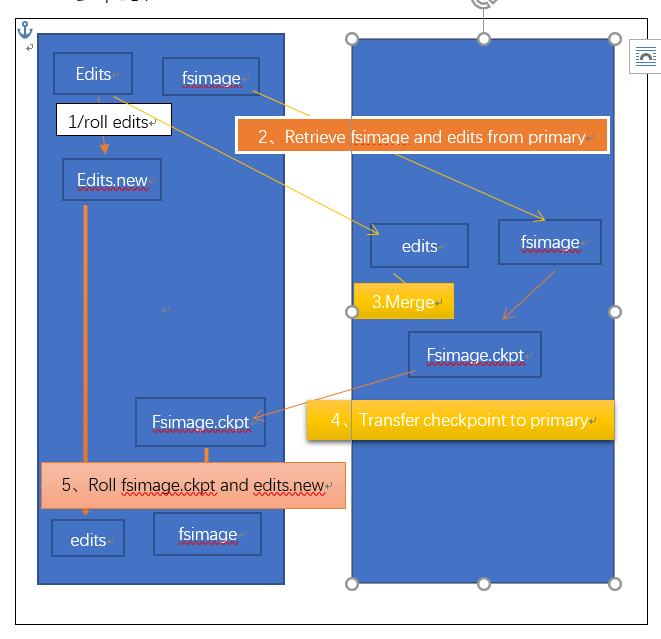
SecondaryNameNode(SNN):
--它不是NN的备份(但可以做备份),它的主要工作是帮助NN合并editslog,减少NN启动时间
--SNN执行合并时机
根据配置文件设置的时间间隔fs.checkpoint.peroid默认为3600秒
根据配置文件设置editslog大小fs.checkpoint.size规定edits文件的最大值默认是64MB
Block的副本放置策略:
第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
第二个副本:放置在于第一个副本不同的机架的节点上
第三个副本:与第二个副本相同机架的节点
更多副本:随机节点
八、SNN合并流程
九、HDFS对数据的管理
(1)文件写入
1)Client 向NameNode发起文件写入的请求
2)NameNode根据文件大小和文件块配置情况,返回给Client所管理的DataNode的信息
3)Client将文件划分为多个Block,根据DataNode的地址信息,按顺序将其写入到每一个DataNode块中
(2)文件读取
1)Client向NameNode发起文件读取的请求
2)NameNode返回文件存储的DataNode信息
3)Client读取文件信息
(3)文件块(Block)复制
1)NameNode发现部分文件的Block不符合最小复制数这一要求或部分DataNode失效
2)通知DataNode相互复制Block
3)DataNode开始相互复制
九、HDFS在数据管理方面值得借鉴的功能
(1)文件块的位置
一个Block会有三份备份,一份放在NameNode指定的DataNode上。另一份放在与指定DataNode不在同一机器上的DataNode上,最后一份放在与指定DataNode同一Rack的DataNode上,备份的目的是为了数据安全,采用这种配置方式主要是考虑同一Rack失败的情况,以及不同Rack之间进行数据复制会带来的性能问题。
(2)心跳检测
用心跳检测DataNode的健康状况,如果发现问题就采取数据备份的方式来保证数据的安全性。
(3)数据复制
使用Hadoop时可以用HDFS的balance命令配置Threshold来平衡每一个DataNode的磁盘利用率,假设使用了Threshold为10%,那么执行balancer命令时,首先会统计所有DataNode的磁盘利用率的平均值,然后判断如果某一个DataNode的磁盘利用率超过这个平均值,那么将会把这个DataNode的Block转移到磁盘利用率低的DataNode上,这对于新节点的加入会十分有用。
(4)数据校验
采用CRC32做数据校验,在写入文件块的时候,除了会写入数据外还会写入校验信息,在读取的时候则需要先校验后读入。
(5)单个NameNode
如果单个NameNode失败,任务处理信息将会记录在本地文件系统和远端的文件系统中。
(6)数据管道性的写入
当客户端要写入文件到DataNode上时,首先会读取一个Block,然后将其写入第一个DataNode上,接着由第一个DataNode将其传递到备份的DataNode上,直到所有需要写入这个Block的DataNode都成功写入后,哭护短才会开始写下一个Block.
(7)安全模式
分布式文件系统启动时会进入安全模式,当分布式文件系统处于安全模式时,文件系统中的内二不允许修改也不允许删除,直到安全模式结束。安全模式主要是为了在系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略进行必要的复制或删除部分数据块。在实际使用中,如果在系统启动时修改和删除文件会出现安全模式不允许修改的错误提示,只需要等待一会儿即可。
【大数据系列】HDFS初识的更多相关文章
- 大数据系列2:Hdfs的读写操作
在前文大数据系列1:一文初识Hdfs中,我们对Hdfs有了简单的认识. 在本文中,我们将会简单的介绍一下Hdfs文件的读写流程,为后续追踪读写流程的源码做准备. Hdfs 架构 首先来个Hdfs的架构 ...
- 大数据系列4:Yarn以及MapReduce 2
系列文章: 大数据系列:一文初识Hdfs 大数据系列2:Hdfs的读写操作 大数据谢列3:Hdfs的HA实现 通过前文,我们对Hdfs的已经有了一定的了解,本文将继续之前的内容,介绍Yarn与Yarn ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- 大数据系列之并行计算引擎Spark部署及应用
相关博文: 大数据系列之并行计算引擎Spark介绍 之前介绍过关于Spark的程序运行模式有三种: 1.Local模式: 2.standalone(独立模式) 3.Yarn/mesos模式 本文将介绍 ...
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive原理
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之分布式计算批处理引擎MapReduce实践
关于MR的工作原理不做过多叙述,本文将对MapReduce的实例WordCount(单词计数程序)做实践,从而理解MapReduce的工作机制. WordCount: 1.应用场景,在大量文件中存储了 ...
随机推荐
- 多媒体开发之rtmp---rtmp client 编译
静态库连接编译问题: assert 原来在c编译器下没定义 ceill 没连接没加 -lm http://blog.chinaunix.net/uid-20681545-id-3786786.html ...
- js jquery 按钮点击后 60秒之后才能点击 60秒倒计时
var wait = 60; function time(o) { if (wait == 0) { $(o).attr("disabled", false); $(o).val( ...
- MyBatis批量增删改的另外一种思路(推荐)
零.传统拼接SQL语句的弊端 传统上利用Mybatis进行批量操作的方式本质来说是拼接SQL语句,然后交给底层执行,如之前博文而言. 其实这种方式是存在弊端的: 1. SQL语句可能会过长,DB的引擎 ...
- xshell使用xftp传输文件 使用pure-ftpd搭建ftp服务
xshell使用xftp传输文件 下载xftp5 https://www.baidu.com/link?url=8rtxgX3JRIbUFO1Samzv5aXhfwRG7Cf8i4vi573QexoH ...
- USBWebServer 中文便携版 快速搭建 PHP/MySQL 网站服务器环境
如果你是一位 WEB 开发者,或正在学习网页编程,你一定会发现,每到一台新电脑上想要在本地调试测试/运行网站代码都得搭建配置一遍 WAMP (Win.Apache.PHP.MySQL) 环境简直烦透了 ...
- TXT文件用法大全【荐】--------按键精灵
来源:全文链接 (3)读取TXT文件指定某一行的第?到第?个字 UserVar t=2 "读出txt第几行文本" UserVar i=5 "从第几个字开始读取" ...
- .net的session详解 存储模式 存到数据库中 使用范围与大小限制 生命周期
Session又称为会话状态,是Web系统中最常用的状态,用于维护和当前浏览器实例相关的一些信息.举个例子来说,我们可以把已登录用户的用户名放在Session中,这样就能通过判断Session中的某个 ...
- Lua 中 number 转换各种进制,以及string串转number
原文地址:http://blog.csdn.net/david_dai_1108/article/details/71699449 --region : NumConvert.lua --Date : ...
- BarTender个别条码的前缀知识讲解
BarTender条码前缀可以强制其根据您选择的行业标准(如 GS1 或 AIM)向条形码的开头添加一个或多个字符.支持的符号体系仅包括2D-Pharmacode.Data Matri.GS1 Dat ...
- Faulty Odometer(九进制数)
Faulty Odometer Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 9301 Accepted: 5759 D ...